
GTA Online es conocido por su baja velocidad de carga. Habiendo lanzado recientemente el juego para completar nuevas misiones de incursión, me sorprendió descubrir que se cargaba tan lentamente como lo hizo cuando se lanzó hace siete años.
El tiempo ha llegado. Por ahora, averigüe las razones de esto.
Servicio de inteligencia
Para empezar, quería comprobar si alguien ya había resuelto este problema. La mayoría de los resultados encontrados consistieron en datos anecdóticos sobre lo difícil que era el juego , que tuvo que cargarse durante tanto tiempo, historias sobre la falta de convicción de la arquitectura de red p2p (y esto es cierto), formas complejas de cargar en modo historia y luego en una sola sesión y empareja mods que te permitieron saltarte el video de apertura con el logo R *. Algunas fuentes informaron que cuando todos estos métodos se usan juntos, ¡puede ahorrar hasta 10-30 segundos!
Mientras tanto, en mi PC ...
Punto de referencia
: 1 10
-: 6
, R* ( social club ).
, : AMD FX-8350
SSD: KINGSTON SA400S37120G
: 2 Kingston 8192 (DDR3-1337) 99U5471
GPU: NVIDIA GeForce GTX 1070
Sé que mi auto está desactualizado, pero ¿por qué diablos el modo en línea se carga seis veces más lento? No pude encontrar ninguna diferencia en la técnica de carga de "la historia primero, luego en línea", como lo han hecho otros antes que yo . Pero incluso si funcionara, los resultados estarían dentro del margen de error.
no estoy solo
Según esta encuesta , el problema está tan extendido que enfurece ligeramente a más del 80% de la base de jugadores. ¡Chicos de R *, en realidad han pasado siete años!

El 18,8% de los jugadores tienen las computadoras o consolas más potentes, el 81,2% están bastante tristes, el 35,1% están bastante tristes.
Después de buscar el 20% de los afortunados cuya carga demora menos de tres minutos, encontré una serie de puntos de referencia con potentes PC para juegos y un tiempo de carga en línea de aproximadamente dos minutos. ¡Para conseguir un tiempo de carga de dos minutos
¿Cómo es que las personas que realizan estos puntos de referencia todavía tardan aproximadamente un minuto en cargar el modo historia? (Por cierto, el benchmark con M.2 no tiene en cuenta el tiempo de visualización de los logotipos al principio). Además, cargar del modo historia al modo online les lleva solo un minuto, mientras que el mío tarda más de cinco. Sé que su técnica es mucho mejor que la mía, pero definitivamente no cinco veces.
Medidas muy precisas
Armado con herramientas poderosas como el Administrador de tareas , comencé a investigar para averiguar qué recursos podrían ser el cuello de botella.
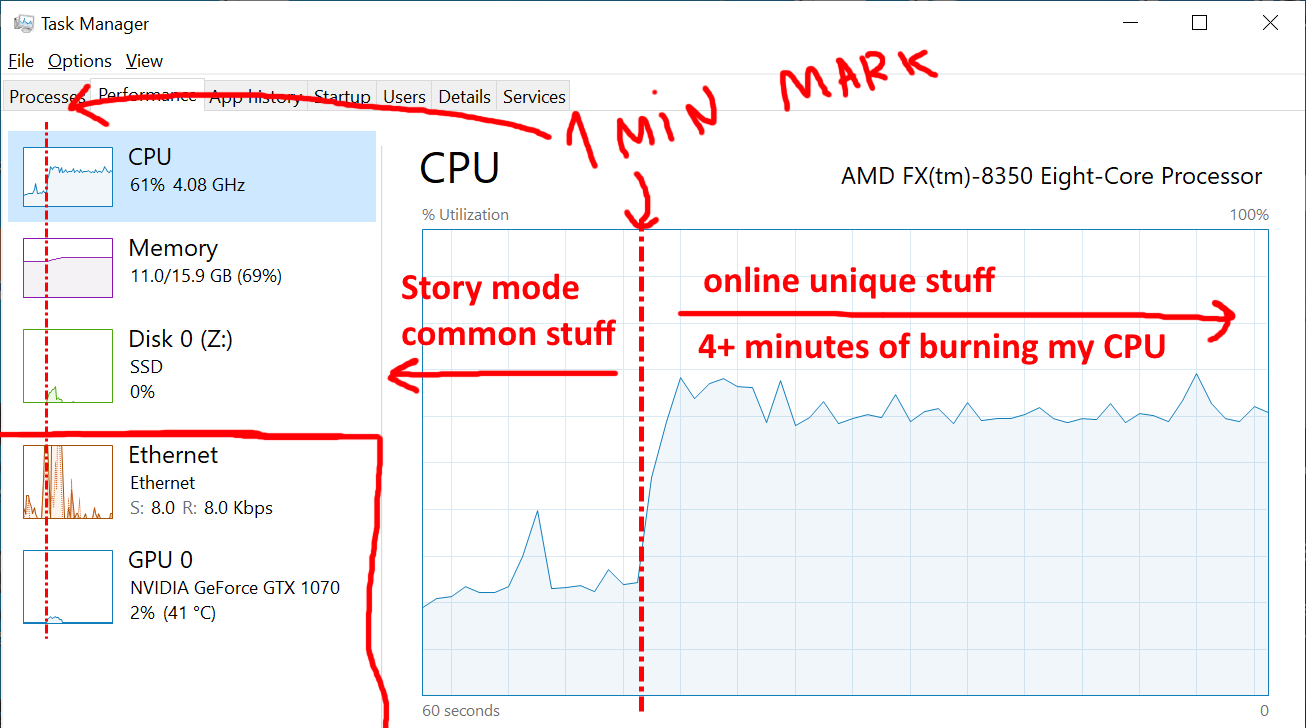
En un minuto, se cargan los recursos estándar del modo historia, después de lo cual el juego carga el procesador durante más de cuatro minutos.
Después de un minuto de cargar los recursos compartidos utilizados en los modos historia y en línea (un indicador casi igual a los puntos de referencia de las PC potentes), GTA decide cargar un núcleo de mi máquina tanto como sea posible durante cuatro minutos y no hacer nada más.
¿Acceso al disco? ¡No está ahí! ¿Uso de la red? No son muchos, pero a los pocos segundos el tráfico cae casi a cero (salvo la carga de pancartas giratorias con información). ¿Uso de GPU? Por ceros. ¿Uso de memoria? Gráfico perfectamente plano ...
¿Qué está pasando ? ¿El juego está extrayendo una criptografía o algo así? Empieza a oler a código. Código muy malo .
Limitando una secuencia
Aunque mi antigua CPU AMD tiene ocho núcleos y aún puede funcionar bien, fue construida en los viejos tiempos. En aquel entonces, el rendimiento de un solo subproceso de los procesadores AMD estaba muy por detrás del de los procesadores Intel. Es posible que esto no explique toda la diferencia en los tiempos de carga, pero debería explicar lo más importante.
Lo extraño es que el juego solo usa la CPU. Esperaba una gran cantidad de recursos cargados desde el disco o un montón de solicitudes de red para crear una sesión en la red p2p. ¿Pero esto? Lo más probable es que se trate de un error.
Perfilado
Los perfiladores son una excelente manera de encontrar cuellos de botella en la CPU. Solo hay un problema: la mayoría de ellos usa el código fuente para obtener una imagen perfecta de lo que está sucediendo en el proceso. Y no lo tengo. Pero tampoco necesito lecturas precisas en microsegundos: el cuello de botella dura cuatro minutos.
El muestreo de pila entra en escena: esta es la única forma de explorar aplicaciones de código cerrado. Realizamos un volcado de pila del proceso en ejecución y la ubicación del puntero de comando actual para construir un árbol de llamadas a intervalos específicos. Luego los sumamos para obtener estadísticas sobre lo que está sucediendo. Solo conozco un generador de perfiles (podría estar equivocado aquí) que puede hacer esto en Windows. Y no se ha actualizado durante más de diez años. Este es Luke Stackwalker! Deje que alguien entregue su amor a este proyecto.

Los culpables # 1 y # 2.
Luke generalmente agrupa las mismas funciones, pero como no tengo símbolos de depuración, necesito mirar las direcciones más cercanas con los ojos para comprender que están en el mismo lugar. Y ¿qué vemos? ¡No uno, sino dos cuellos de botella!
Por la madriguera del conejo
Habiendo tomado prestada una copia perfectamente legítima del popular desensamblador de un amigo (no, no puedo pagarlo ... tendré que aprender ghidra de alguna manera ), comencé a desensamblar el GTA.
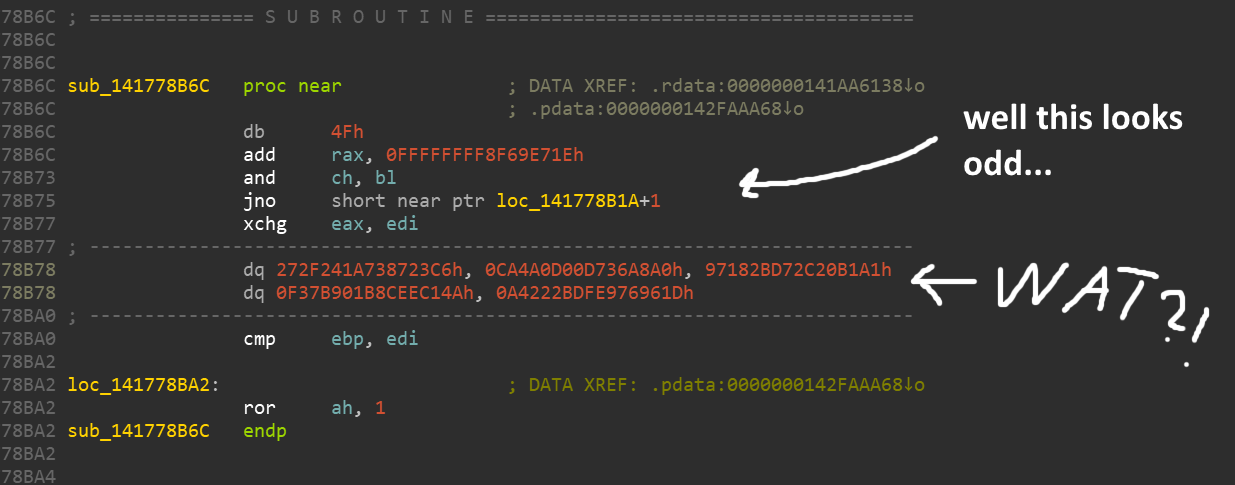
Todo parece completamente incorrecto. Muchos juegos de alto presupuesto tienen protección de ingeniería inversa incorporada para protegerse contra piratas, tramposos y modders (por no decir que alguna vez los detiene).
Parece que aquí se utiliza algún tipo de ofuscación / cifrado, por lo que la mayoría de los comandos se reemplazan por galimatías. Pero no te preocupes, solo necesitamos volcar la memoria del juego cuando ejecutamos la parte que queremos aprender. Antes de su ejecución, los comandos deben desofuscarse de una forma u otra. Tenía Process Dump a mano , pero hay muchas otras herramientas que pueden hacer cosas similares.
Problema n. ° 1: ¿esto es ... strlen?
¡Desmontar el volcado ahora menos ofuscado revela que una de las direcciones tiene una etiqueta tomada de la nada! ¿Lo es
strlen
? El siguiente en la pila de llamadas está marcado como
vscan_fn
, después de lo cual las etiquetas se agotan, sin embargo, estoy bastante seguro de que lo es
sscanf
.
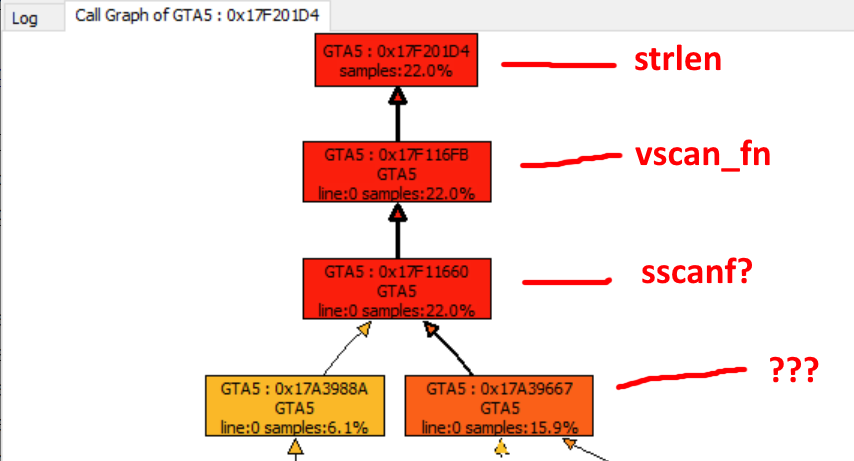
Raspan algo. ¿Pero que? Analizar el código desensamblado tomaría infinito, así que decidí volcar algunas muestras del proceso en ejecución usando x64dbg . Después de un poco de depuración, descubrí que esto es ... ¡JSON! Analizan JSON. La friolera de 10 megabytes de datos JSON con casi 63 mil elementos .
...,
{
"key": "WP_WCT_TINT_21_t2_v9_n2",
"price": 45000,
"statName": "CHAR_KIT_FM_PURCHASE20",
"storageType": "BITFIELD",
"bitShift": 7,
"bitSize": 1,
"category": ["CATEGORY_WEAPON_MOD"]
},
...
¿Qué es? Según algunas fuentes, esto parece un dato de "directorio de tiendas en línea". Asumiré que contienen una lista de todos los posibles elementos y actualizaciones que se pueden comprar en GTA Online.
Aclaración: creo que estos son artículos comprados con dinero del juego y no están directamente relacionados con las microtransacciones .
¡Pero 10 megabytes es una bagatela! ¿Y el uso
sscanf
puede no ser óptimo, pero no puede ser tan malo? Bien ...

10 megabytes de cadenas C en memoria. 1. Mueva el puntero unos bytes al siguiente valor. 2. Llamamos
sscanf(p, "%d", ...)
. 3. Leemos cada carácter en 10 megabytes mientras leemos cada valor pequeño (!?). 4. Devuelve el valor escaneado.
Sí, tomará mucho tiempo ... Para ser honesto, no tenía idea de cómo están
sscanf
llamando la mayoría de las implementaciones
strlen
, así que no puedo culpar al desarrollador que escribió esto. Sugeriría que estos datos simplemente se escanean byte a byte y el procesamiento puede detenerse en
NULL
.
Problema n. ° 2: ¿Vamos a usar una matriz hash ...?
Resultó que se llama al segundo culpable directamente al lado del primero. Ambos incluso se llaman en la misma declaración
if
, como se puede entender en esta desagradable descompilación:

Ambos problemas se encuentran dentro de un gran ciclo de análisis de todos los elementos. El problema n. ° 1 es el análisis sintáctico, el problema n. ° 2 es el ahorro.
Todas las etiquetas son especificadas por mí, no tengo idea de cómo se llaman realmente las funciones y los parámetros.
¿Cuál es el segundo problema? Inmediatamente después de analizar el elemento, se guarda en una matriz (¿o en una lista incrustada de C ++? No del todo claro) Cada elemento se parece a esto:
struct {
uint64_t *hash;
item_t *item;
} entry;
Pero, ¿qué pasa antes de ahorrar? El código verifica toda la matriz, elemento por elemento, comparando el hash del elemento para ver si está en la lista. Si mis cálculos son correctos, entonces con alrededor de 63 mil elementos esto da
(n^2+n)/2 = (63000^2+63000)/2 = 1984531500
verificaciones. La mayoría de ellos son inútiles. Tenemos hashes únicos , así que ¿por qué no utilizar un mapa hash ?

El generador de perfiles muestra que las dos primeras líneas están cargando el procesador. La declaración
if
se ejecuta solo al final. La penúltima línea inserta el sujeto.
En ingeniería inversa, llamé a esta estructura
hashmap
, pero es obvio que lo es
not_a_hashmap
. Y luego todo mejora. Este hash / matriz / lista está vacío antes de cargar JSON. ¡Y todos los elementos de JSON son únicos! ¡El código ni siquiera necesita verificar si el artículo está en la lista! Incluso hay una función para insertar elementos directamente, ¡solo úsala! En serio, ¿¡qué carajo !?
Prueba de concepto
Todo esto es genial, por supuesto, pero nadie me tomará en serio hasta que lo pruebe para poder escribir un título de clickbait para una publicación.
¿Cuál es el plan? Escribe
.dll
, inyecta su GTA, intercepta varias funciones, ???, ¡BENEFICIO!
El problema de JSON es confuso y reemplazar el analizador requeriría mucho tiempo. Es mucho más realista intentar sustituirlo
sscanf
por una función de la que no dependa
strlen
. Pero hay una forma aún más sencilla.
- interceptar strlen
- espera una larga cola
- "Caché" su inicio y duración
- si se vuelve a llamar dentro de la cadena, devuelve el valor almacenado en caché
Algo como esto:
size_t strlen_cacher(char* str)
{
static char* start;
static char* end;
size_t len;
const size_t cap = 20000;
// if we have a "cached" string and current pointer is within it
if (start && str >= start && str <= end) {
// calculate the new strlen
len = end - str;
// if we're near the end, unload self
// we don't want to mess something else up
if (len < cap / 2)
MH_DisableHook((LPVOID)strlen_addr);
// super-fast return!
return len;
}
// count the actual length
// we need at least one measurement of the large JSON
// or normal strlen for other strings
len = builtin_strlen(str);
// if it was the really long string
// save it's start and end addresses
if (len > cap) {
start = str;
end = str + len;
}
// slow, boring return
return len;
}
En cuanto al problema de la matriz hash, es más fácil de resolver: puede omitir por completo las comprobaciones duplicadas e insertar elementos directamente, porque sabemos que los valores son únicos.
char __fastcall netcat_insert_dedupe_hooked(uint64_t catalog, uint64_t* key, uint64_t* item)
{
// didn't bother reversing the structure
uint64_t not_a_hashmap = catalog + 88;
// no idea what this does, but repeat what the original did
if (!(*(uint8_t(__fastcall**)(uint64_t*))(*item + 48))(item))
return 0;
// insert directly
netcat_insert_direct(not_a_hashmap, key, &item);
// remove hooks when the last item's hash is hit
// and unload the .dll, we are done here :)
if (*key == 0x7FFFD6BE) {
MH_DisableHook((LPVOID)netcat_insert_dedupe_addr);
unload();
}
return 1;
}
Las fuentes completas de prueba de concepto se pueden encontrar aquí .
resultados
Entonces, ¿como funcionó?
Tiempo de carga inicial para el modo en línea: aproximadamente 6 minutos Tiempo con solo comprobaciones duplicadas parcheadas: 4 minutos 30 segundos
Tiempo solo con parche del analizador JSON: 2 minutos 50 segundos
Tiempo con parches de ambos problemas: 1 minuto 50 segundos
(6 * 60 - (1 * 60 + 50)) / (6 * 60) = tiempo de carga reducido en un 69,4% (¡genial!)
¡Oh, sí, cómo funcionó!
Lo más probable es que esto no disminuya el tiempo de carga para todos los jugadores; puede haber otros cuellos de botella en otros sistemas, pero este es un problema tan obvio que no entiendo cómo R * no lo ha notado en todos estos años.
tl; dr
- Hay un cuello de botella en la CPU al iniciar GTA Online debido a la ejecución de un solo subproceso
- Resulta que GTA está luchando contra el análisis de un archivo JSON de 10 MB en este momento.
- El analizador JSON en sí está mal escrito / implementado de manera ingenua y
- Después del análisis, se realiza un procedimiento lento para comprobar que no hay elementos duplicados.
R * por favor resuelve el problema
Por favor, si este artículo llega de alguna manera a Rockstar, un desarrollador no tardará más de un día en solucionar estos problemas. Por favor haz algo respecto a eso.
Puede cambiar a hashmap para eliminar duplicados u omitir esta verificación por completo, lo que será más rápido. En el analizador JSON, reemplace la biblioteca por una más eficiente. No creo que haya una solución más fácil aquí.
Agradecer.