En cierto modo, este artículo es una continuación de nuestro artículo sobre tallas en Habré . Pero aquí aparecieron ejemplos de la vida real, por lo que si es necesario algún tipo de continuidad, comience con ese artículo y luego vuelva aquí. Todos los detalles están debajo del corte.
Este artículo se basa en Benchmarking y dimensionamiento de su clúster de Elasticsearch para registros y métricas en el blog de Elastic. Lo modificamos un poco y eliminamos los ejemplos con Elastic basado en la nube.
Recursos de hardware del clúster de Elasticsearch
El rendimiento de un clúster de Elasticsearch depende principalmente de cómo lo use y qué se ejecuta debajo de él (en el sentido del hardware). El hardware se caracteriza por lo siguiente:
Bóveda
El proveedor recomienda usar SSD siempre que sea posible. Pero, obviamente, este puede no ser el caso en todas partes, por lo que la arquitectura caliente-caliente-fría y la Gestión del ciclo de vida del índice (ILM) están a su servicio.
Elasticsearch no requiere almacenamiento redundante (puede prescindir de RAID 1/5/10), los escenarios de almacenamiento de registros o métricas generalmente tienen al menos una réplica para una tolerancia mínima a fallas.
Memoria
La memoria en el servidor se divide en:
JVM Heap. Almacena metadatos sobre clústeres, índices, segmentos, segmentos y datos de campo del documento. Idealmente, debería asignar el 50% de la RAM disponible para esto.
Caché del sistema operativo. Elasticsearch utilizará la memoria disponible restante para almacenar en caché los datos, lo que mejorará drásticamente el rendimiento al evitar las lecturas de disco durante las búsquedas de texto completo, la agregación de valores de documentos y la clasificación. Y no olvide deshabilitar el intercambio (archivo de intercambio) para evitar descargar el contenido de la RAM en el disco y luego leerlo (¡esto es lento!).
UPC
Los nodos de Elasticsearch tienen los llamados. grupos de subprocesos y colas de subprocesos que utilizan los recursos informáticos disponibles. La cantidad y el rendimiento de los núcleos de la CPU determinan la velocidad promedio y el rendimiento máximo de las operaciones de datos en Elasticsearch. La mayoría de las veces se trata de 8-16 núcleos.
La red
Rendimiento de la red: tanto el ancho de banda como la latencia pueden afectar significativamente la comunicación entre los nodos de Elasticsearch y la comunicación entre los clústeres de Elasticsearch. Tenga en cuenta que, de forma predeterminada, se realiza una verificación de disponibilidad de nodos cada segundo y si un nodo no hace ping en 30 segundos, se marca como no disponible y se cierra desde el clúster.
Dimensionamiento de un clúster de Elasticsearch por volumen de almacenamiento
El almacenamiento de registros y métricas generalmente requiere una cantidad significativa de espacio en disco, por lo que vale la pena usar la cantidad de estos datos para determinar inicialmente el tamaño de nuestro clúster Elasticsearch. A continuación, se presentan algunas preguntas para comprender la estructura de datos que se debe administrar en un clúster:
- ¿Cuántos datos brutos (GB) indexaremos por día?
- ¿Cuántos días conservaremos los datos?
- ¿Cuántos días hay en la zona caliente?
- ¿Cuántos días hay en la zona cálida?
- ¿Cuántas réplicas se utilizarán?
Es recomendable poner un 5% o un 10% en la parte superior para que el 15% del espacio total en disco siempre quede en stock. Ahora intentemos contar este caso.
Tamaño total de datos (GB) = Número de datos brutos por día (GB) * Número de días de almacenamiento * (Número de réplicas + 1).
Almacenamiento total (GB) = Datos totales (GB) * (1 + 0,15 espacio de almacenamiento + 0,1 almacenamiento adicional).
Número total de nodos de datos = OKRVVERH (Tamaño total de datos (GB) / Tamaño de memoria por nodo de datos / Memoria: relación de datos). En el caso de una instalación grande, es mejor tener un nodo adicional en stock.
Elastic recomienda las siguientes proporciones de memoria: datos para diferentes tipos de nodos: caliente → 1:30 (30 GB de espacio en disco por gigabyte de memoria), caliente → 1: 160, frío → 1: 500). OKRVVERKH - envolvente al entero superior más cercano.
Ejemplo de cálculo de grupo pequeño
Supongamos que llega ~ 1 GB de datos todos los días, que deben almacenarse durante 9 meses.
Datos totales (GB) = 1 GB x (9 meses x 30 días) x 2 = 540 GB
Almacenamiento total (GB) = 540 GB x (1 + 0,15 + 0,1) = 675 GB
Número total de nodos de datos = 675 GB / 8 GB RAM / 30 = 3 nodos.
Ejemplo de cálculo de un gran clúster
Obtienes 100 GB por día y almacenarás estos datos durante 30 días en la zona caliente y 12 meses en la zona cálida. Tiene 64 GB de memoria por nodo, de los cuales 30 GB se asignan para el montón de JVM y el resto para la caché del sistema operativo. La proporción recomendada de memoria: datos para la zona activa es 1:30, para la zona cálida - 1: 160.
Por lo tanto, si obtiene 100 GB por día y necesita almacenar estos datos durante 30 días, obtenemos:
Cantidad total de datos (GB) en la zona activa = (100 GB x 30 días * 2) = 6000 GB
Almacenamiento total de zona activa (GB) = 6000 GB x (1 + 0,15 + 0,1) = 7500 GB
Total de nodos de datos de zona activa = OKRVUPH ( 7500/64/30) + 1 = 5 nodos
Datos totales (GB) en la zona cálida= (100 GB x 365 días * 2) = 73,000 GB
Almacenamiento total (GB) en la zona cálida = 73,000 GB x (1 + 0.15 + 0.1) = 91,250 GB
Número total de nodos de datos en la zona cálida = OKRVVERKH (91250 / 64/160) + 1 = 10 nudos
Por lo tanto, obtuvimos 5 nudos para la zona caliente y 10 nudos para la fruta tibia. Para la zona fría, cálculos similares, pero la relación de memoria: los datos ya serán 1: 500.
Pruebas de rendimiento
Una vez que se ha determinado el tamaño del clúster, es necesario confirmar que las matemáticas funcionan en la vida real.
Esta prueba utiliza la misma herramienta que utilizan los ingenieros de Elasticsearch, Rally . Es fácil de implementar y ejecutar y es totalmente personalizable, por lo que se pueden probar múltiples escenarios (pistas).
Para facilitar el análisis de los resultados, la prueba se divide en dos secciones: indexación y consultas de búsqueda. Las pruebas utilizarán datos de las pistas Metricbeat y los registros del servidor web .
Indexación
La prueba responde las siguientes preguntas:
- ¿Cuál es el rendimiento máximo para indexar clústeres?
- ¿Cuántos datos se pueden indexar por día?
- ¿Es el grupo más grande o más pequeño que el tamaño apropiado?
Esta prueba utiliza un clúster de 3 nodos con la siguiente configuración para cada nodo:
- 8 vCPU;
- HDD;
- Pila de 32GB / 16.
Prueba de indexación n. ° 1
El conjunto de datos utilizado para la prueba son datos de Metricbeat con las siguientes características:
- 1.079.600 documentos;
- Volumen de datos: 1,2 GB;
- Tamaño medio del documento: 1,17 KB.
A continuación, habrá varias pruebas para determinar el tamaño de paquete óptimo y el número óptimo de subprocesos.
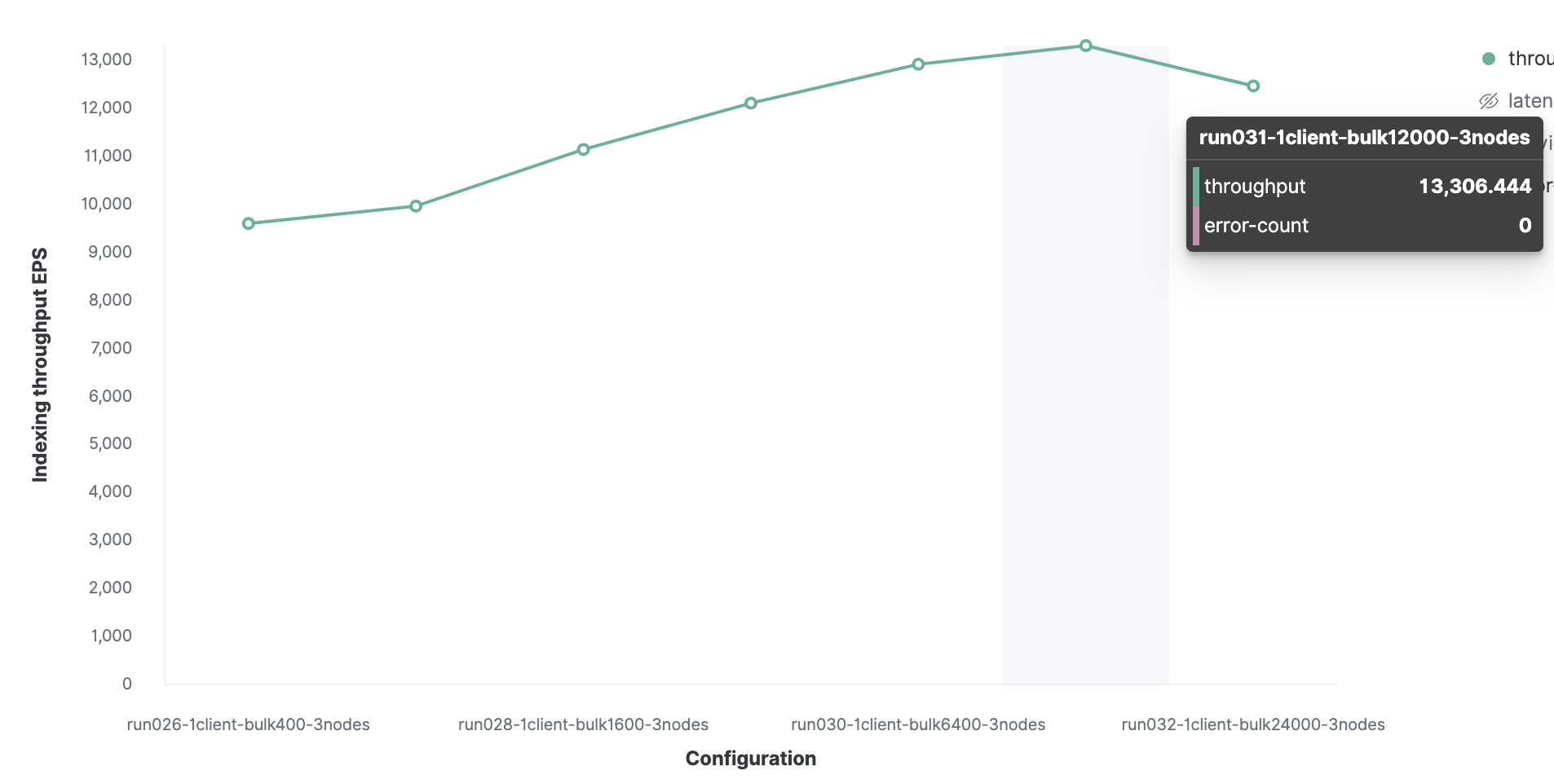
Todo comienza con 1 cliente de Rally para encontrar el tamaño de paquete óptimo. Inicialmente, se cargan 100 documentos, luego su número se duplica en lanzamientos posteriores. El resultado será un tamaño de lote óptimo de 12.000 documentos (aproximadamente 13,7 MB). A medida que aumenta el tamaño del paquete, el rendimiento comienza a disminuir.
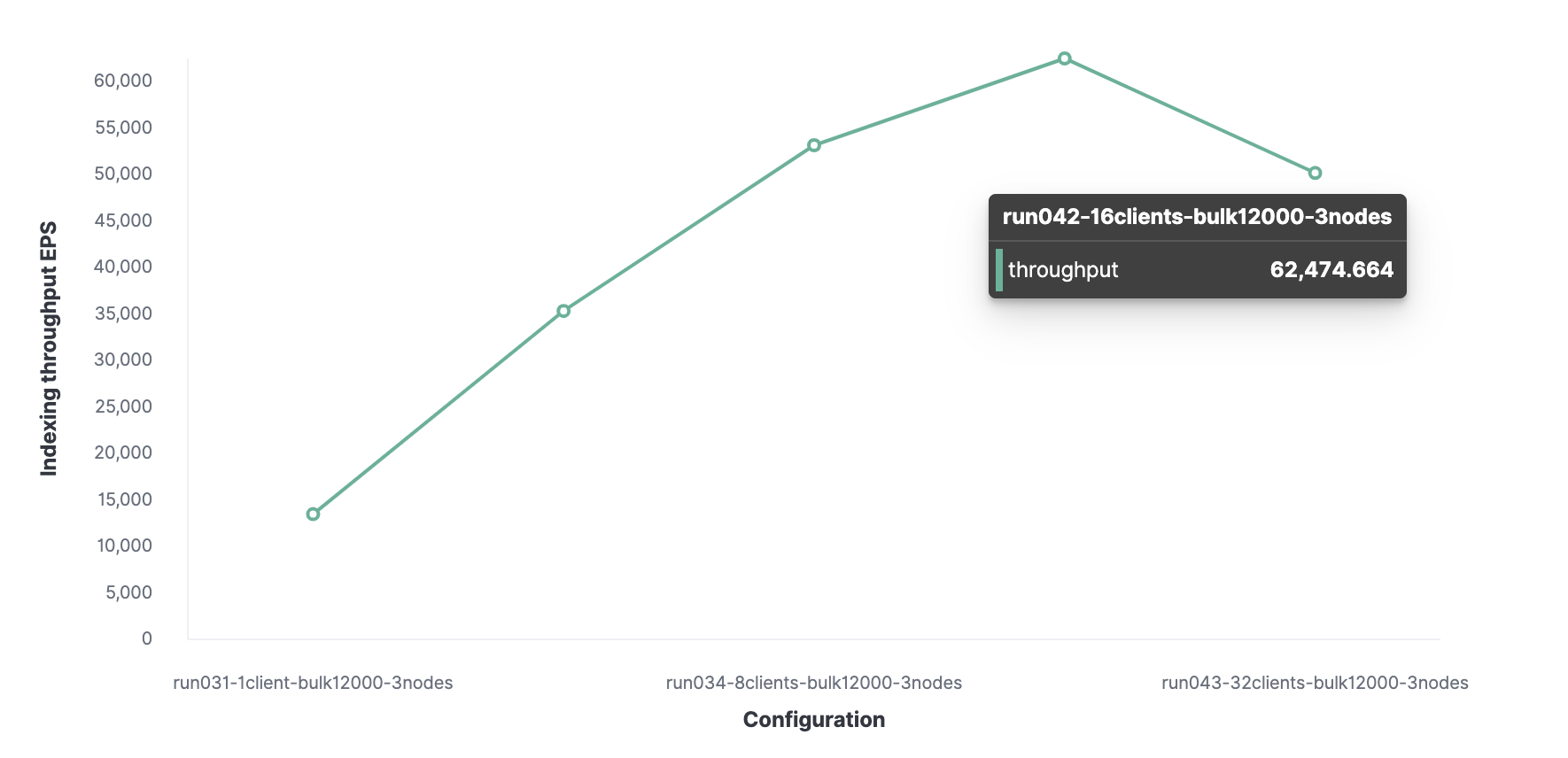
Luego, usando un método similar, 16 es el número óptimo de clientes para lograr 62,000 eventos indexados por segundo.
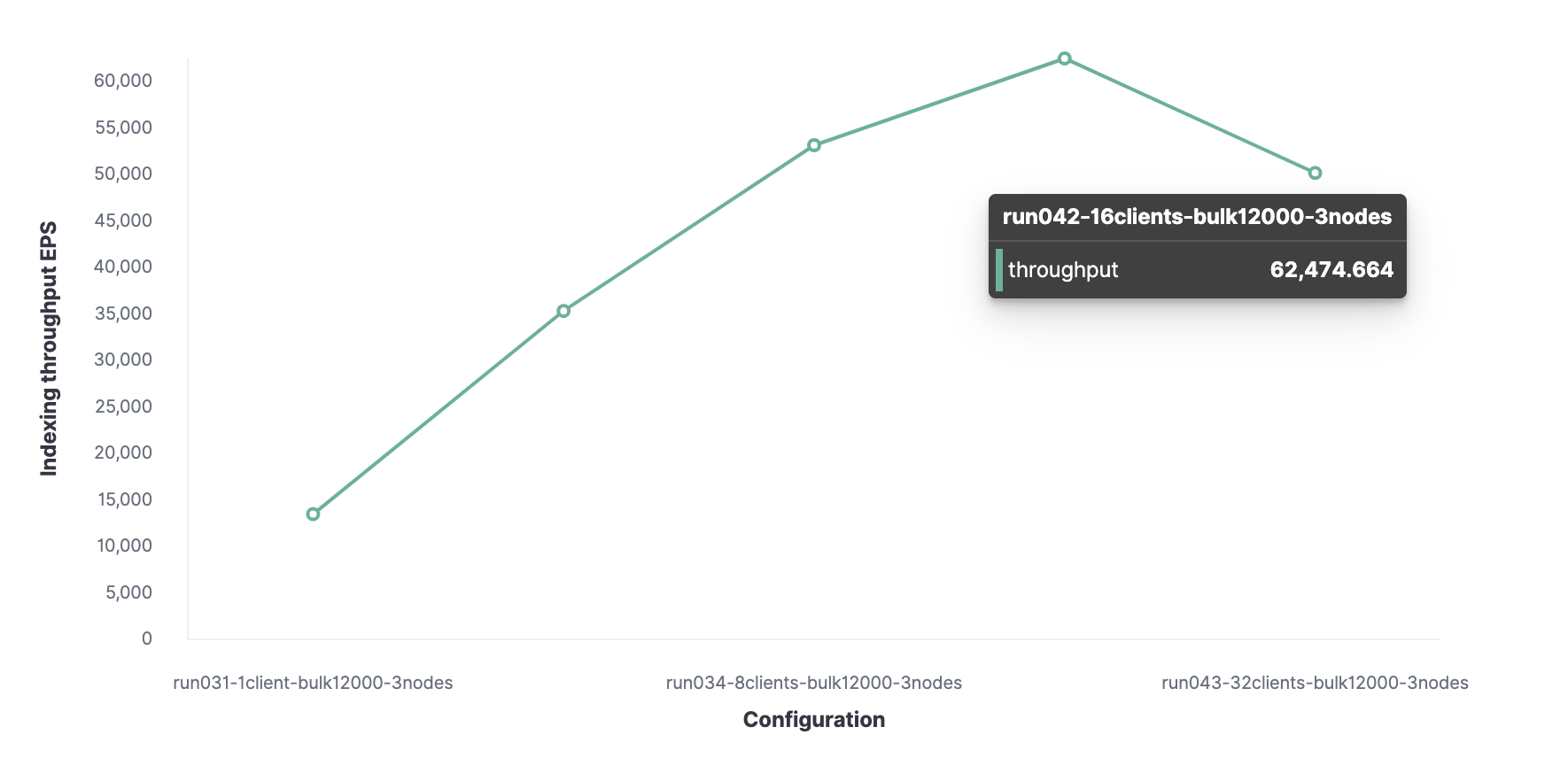
En total, el clúster puede procesar un máximo de 62.000 eventos por segundo sin sacrificar el rendimiento. Para aumentar este número, deberá agregar un nuevo nodo.
A continuación se muestra la misma prueba con un paquete de 12.000 eventos, pero a modo de comparación, los datos de ancho de banda se dan para 1 nodo, 2 y 3 nodos.
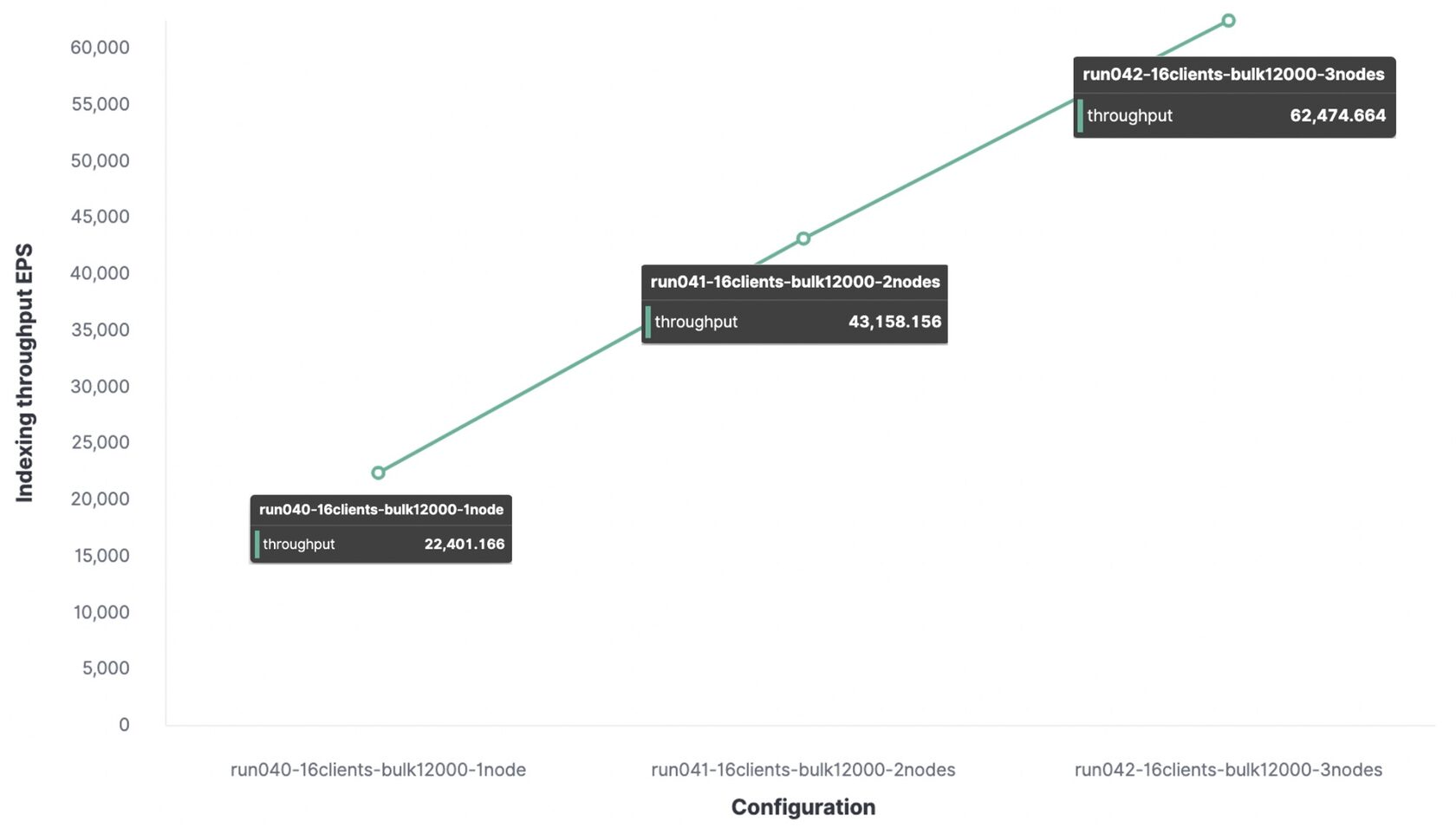
Para un entorno de prueba, el rendimiento máximo de indexación será:
- Con 1 nodo y 1 fragmento, se indexaron 22 000 eventos por segundo;
- Con 2 nodos y 2 fragmentos, se indexaron 43.000 eventos por segundo;
- Con 3 nodos y 3 fragmentos, se indexaron 62.000 eventos por segundo.
Cualquier solicitud de índice adicional se pondrá en cola y cuando esté llena, el nodo responderá rechazando la solicitud de índice.
Tenga en cuenta que el conjunto de datos afecta el rendimiento del clúster, por lo que es importante ejecutar pistas de Rally con sus propios datos.
Prueba de indexación n. ° 2
Para el siguiente paso, se utilizarán las pistas de datos de registro del servidor HTTP con la siguiente configuración:
- 247 249 096 documentos;
- Volumen de datos: 31,1 GB;
- Tamaño medio del documento: 0,8 KB.
El tamaño de paquete óptimo es de 16.000 documentos.
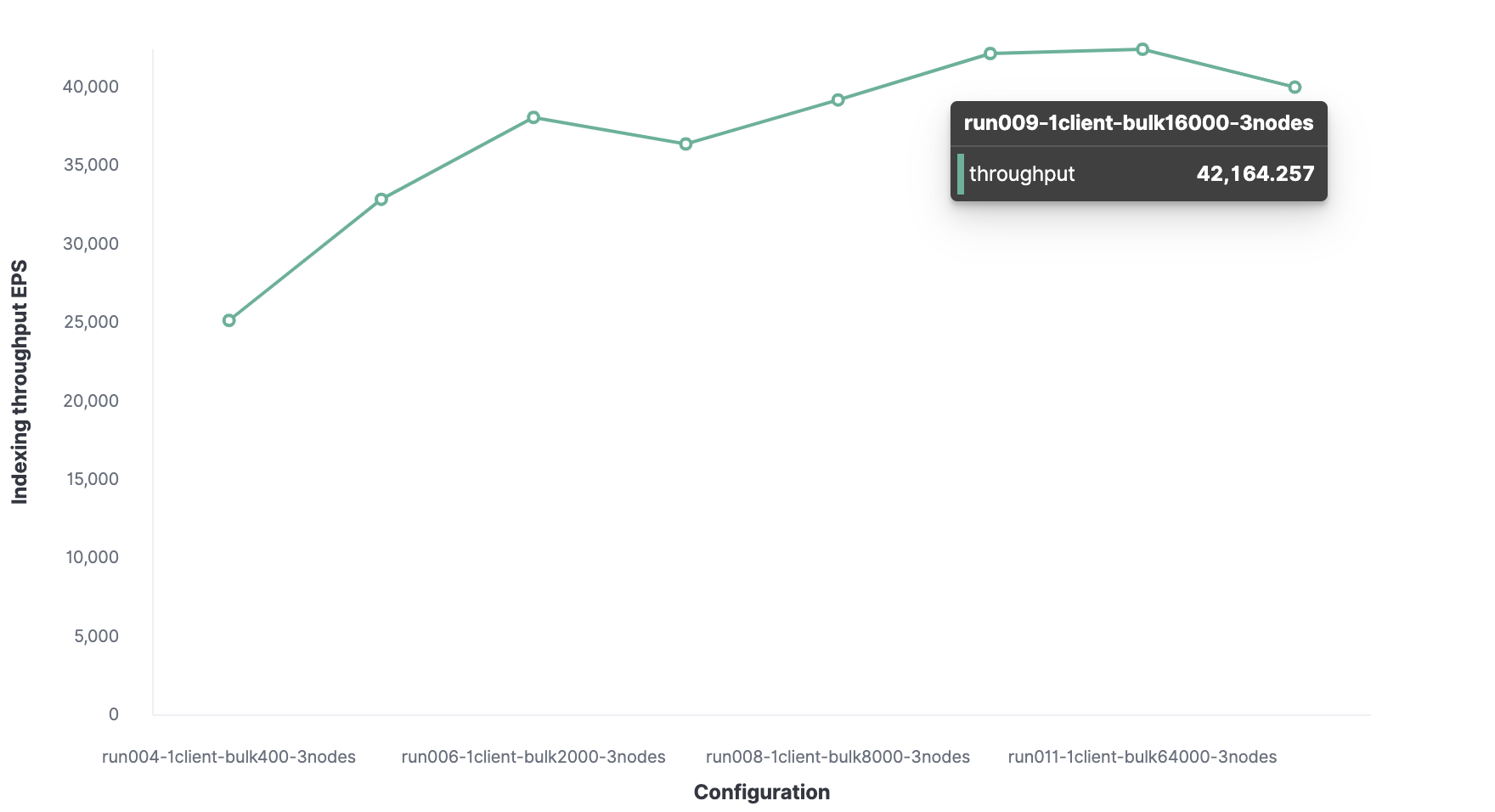
El número óptimo de clientes es 32. En
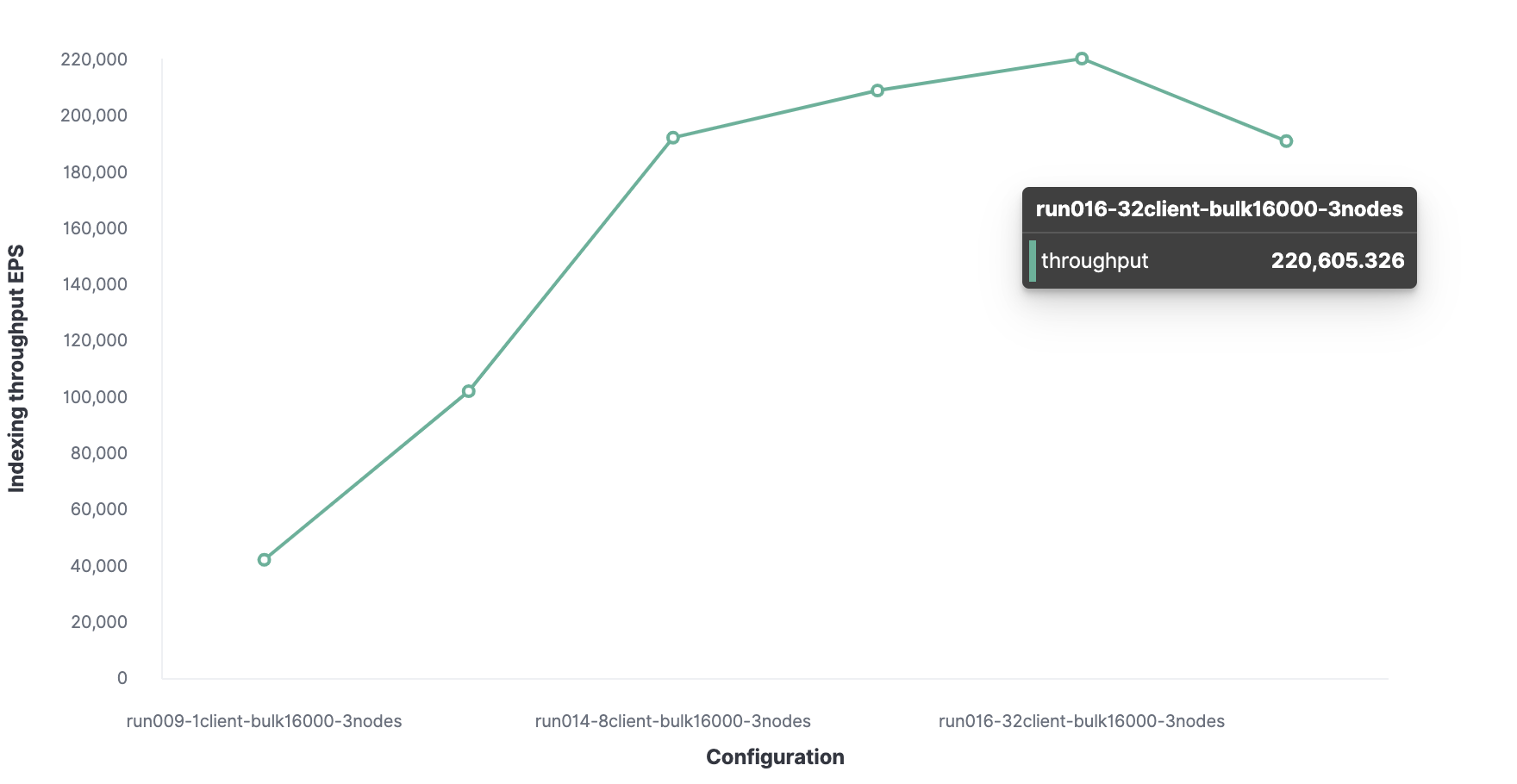
consecuencia, el rendimiento máximo de indexación en Elasticsearch es 220.000 eventos por segundo.
Buscar
El rendimiento de la búsqueda se estimará en base a 20 clientes y 1000 operaciones por segundo. Se realizarán tres pruebas para la búsqueda.
Prueba de búsqueda n. ° 1
Compara el tiempo de servicio (o más bien el percentil 90) para un conjunto de consultas.
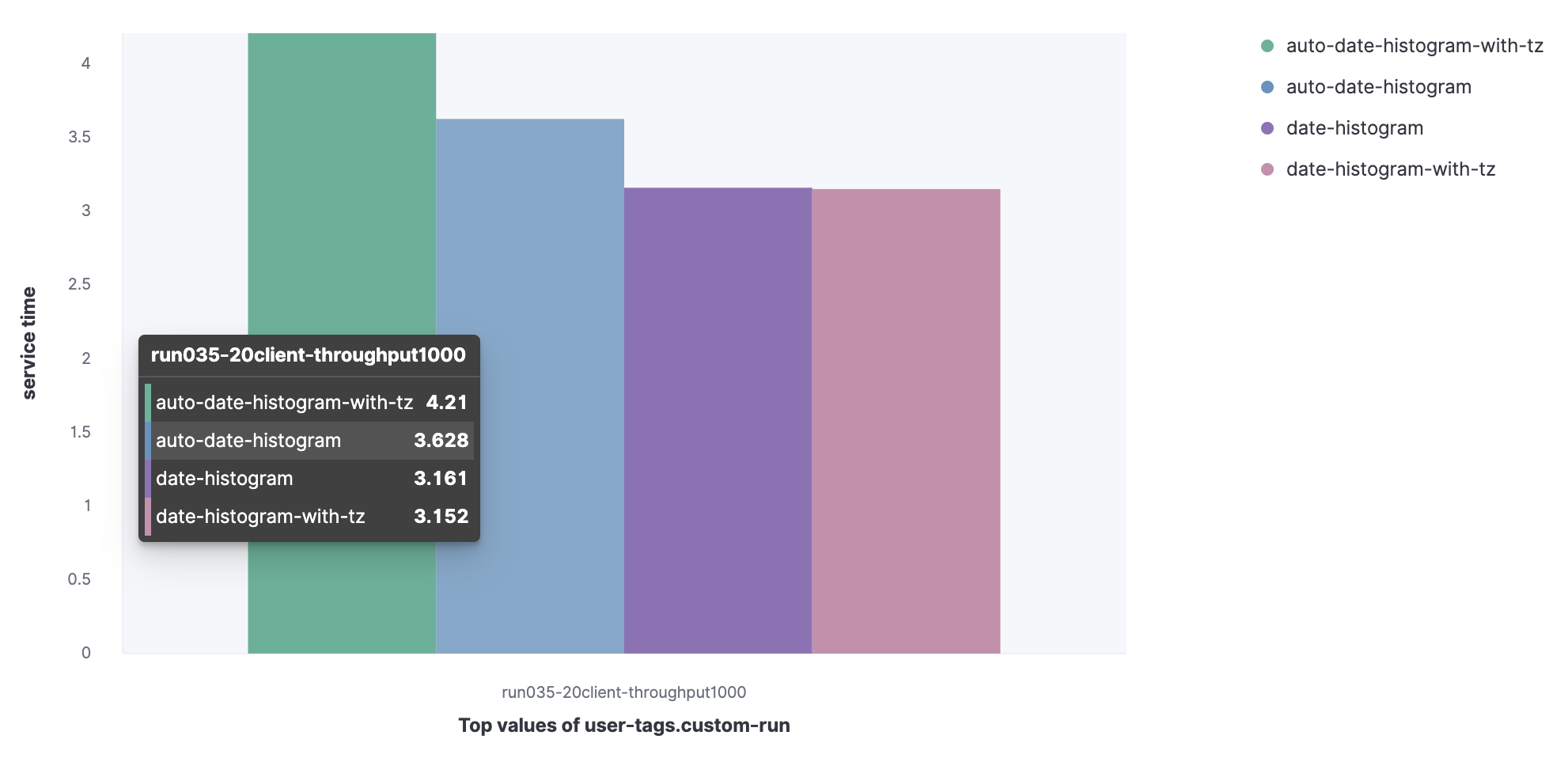
Conjunto de datos de Metricbeat:
- Histograma de fechas agregadas con intervalo automático (historial automático de fechas);
- Histograma de fecha agregada con zona horaria con intervalo automático (auto-date-histogram-with-tz);
- Histograma de fecha agregada (histograma de fecha);
- Histograma de fecha agregada con zona horaria (date-histogram-with-tz).
Puede ver que la solicitud auto-date-histogram-with-tz tiene el tiempo de servicio más largo del clúster.
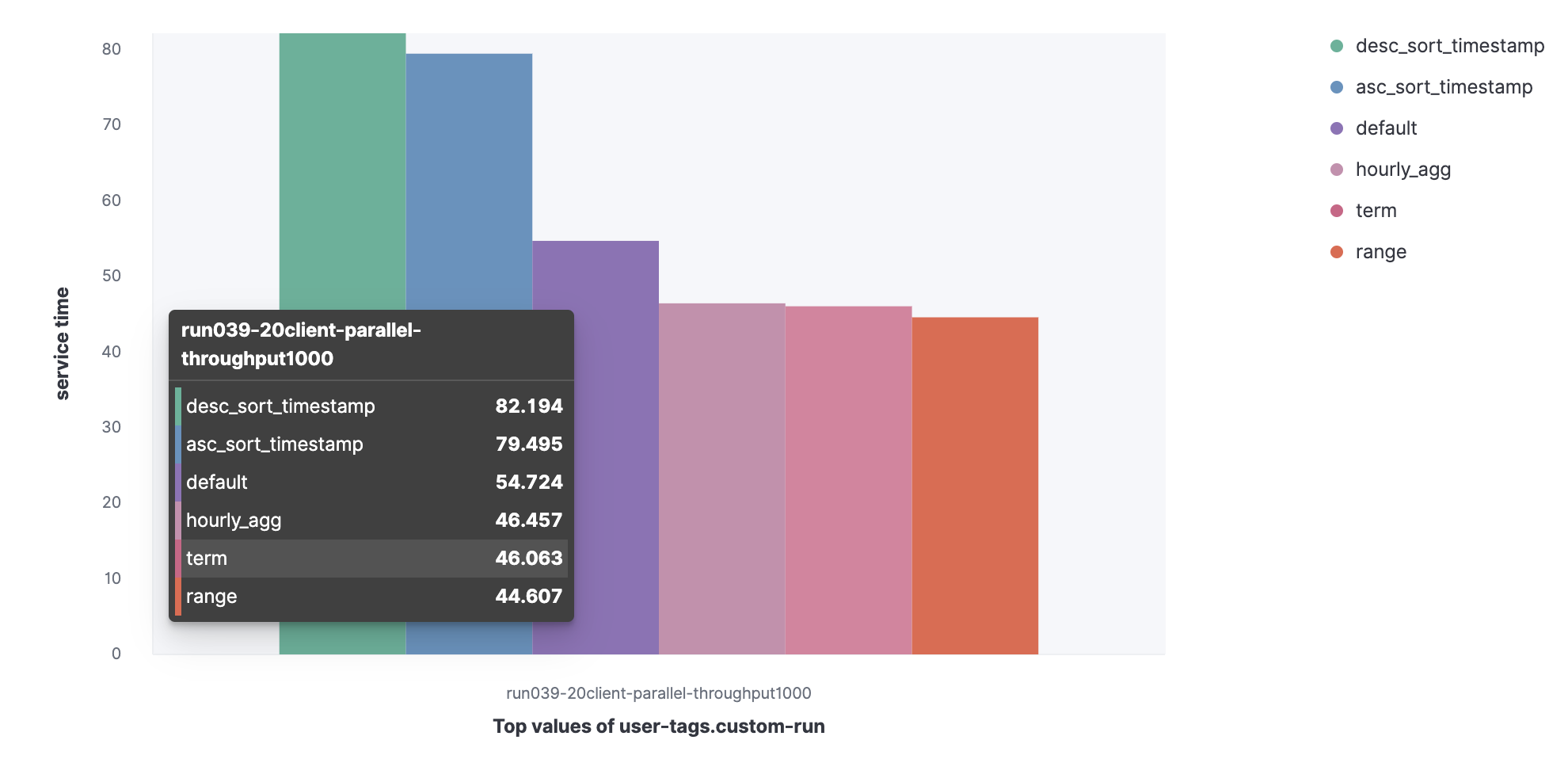
Conjunto de datos del registro del servidor HTTP:
- Defecto;
- Término;
- Abarcar;
- Hourly_agg;
- Desc_sort_timestamp;
- Asc_sort_timestamp.
Puede ver que las solicitudes desc_sort_timestamp y desc_sort_timestamp tienen una vida útil más larga.

Prueba de búsqueda nº 2
Ahora veamos las consultas paralelas. Veamos cómo aumenta el tiempo de servicio del percentil 90 si las consultas se ejecutan en paralelo.
Prueba de búsqueda n. ° 3
Considere la velocidad de indexación y el tiempo de servicio de las consultas de búsqueda en presencia de indexación paralela.
Ejecutemos una tarea de búsqueda e indexación paralela para ver la velocidad de indexación y el tiempo del servicio de consulta.

Veamos cómo ha aumentado el tiempo de servicio de consultas del percentil 90 al realizar búsquedas en paralelo con las operaciones de indexación.

En total, tener 32 clientes para indexar y 20 usuarios para buscar:
- El rendimiento de indexación es de 173.000 eventos por segundo, que es menos de 220.000 obtenidos en experimentos anteriores;
- El ancho de banda de búsqueda es de 1000 eventos por segundo.
Rally es una poderosa herramienta de evaluación comparativa, pero debe usarla solo con datos que también se utilizarán en producción en el futuro.
Un par de anuncios:
Hemos desarrollado un curso de formación sobre los conceptos básicos del trabajo con Elastic Stack , que se adapta a las necesidades específicas del cliente. Programa de formación detallado a petición.
Lo invitamos a registrarse para Elastic Day en Rusia y el CIS 2021, que se llevará a cabo en línea el 3 de marzo de 10 am a 1 pm.
Lea nuestros otros artículos:
- Dimensionamiento Elasticsearch
- Cómo se licencian las licencias de Elastic Stack (Elasticsearch) y cómo se diferencian
- Comprensión del aprendizaje automático en Elastic Stack (también conocido como Elasticsearch, también conocido como ELK)
- Elastic under the lock: habilitación de opciones de seguridad para el clúster Elasticsearch para acceder desde adentro y desde afuera
Si está interesado en los servicios de administración y soporte para su instalación de Elasticsearch, puede dejar una solicitud en el formulario de comentarios en una página especial.
Suscríbete a nuestro grupo de Facebook y canal de Youtube .