Nuestra traducción de hoy es sobre ciencia de datos. Un analista de datos de Dublín contó cómo estaba buscando vivienda en un mercado con alta demanda y baja oferta.
Siempre he envidiado a aquellos profesionales que pueden aplicar sus habilidades laborales en su vida diaria . Tomemos a un plomero, dentista o chef, por ejemplo: sus habilidades no solo son útiles en el trabajo.
Para el analista de datos y el ingeniero de software, estos beneficios suelen ser menos tangibles. Por supuesto, soy un experto en tecnología, pero en el trabajo me ocupo principalmente del sector empresarial, por lo que es difícil encontrar casos de uso interesantes de mis habilidades para resolver problemas familiares.
Cuando mi esposa y yo decidimos comprar una nueva casa en Dublín, ¡inmediatamente vi la oportunidad de usar el conocimiento!
El contenido del artículo:
- Alta demanda, baja oferta
- Buscando datos
- De la idea a la herramienta
- Datos básicos
- Mejorando la calidad de los datos
- Estudio de datos de Google
- Algunos detalles de implementación (y luego pasar a la parte divertida)
- Direcciones de codificación geográfica
- Cálculo del tiempo que la propiedad está en el mercado
- Análisis
- recomendaciones
- Conclusión
Los datos siguientes no se extrajeron, sino que se generaron con este script .
Alta demanda, baja oferta
Para comprender cómo comenzó todo, puede leer mi experiencia personal al comprar bienes raíces en Dublín. Debo admitir que no fue fácil: el mercado tiene una demanda muy alta (gracias al excelente desempeño económico de Irlanda en los últimos años), y la vivienda es extremadamente cara. Irlanda tuvo los costos de vivienda más altos en comparación con la UE en 2019, según un informe de Eurostat (77% por encima de la media de la UE).

¿Qué significa este diagrama?
1. Hay muy pocas casas que se ajusten a nuestro presupuesto , y en las zonas de la ciudad con mucha demanda hay incluso menos (con una infraestructura de transporte más o menos normal).
2. El estado de la vivienda secundaria es a veces muy precario, ya que no es rentable para los propietarios invertir en reparaciones antes de vender. Las casas en venta a menudo tienen calificaciones de eficiencia energética bajas, plomería y equipos eléctricos deficientes, lo que significa que los compradores tendrán que agregar costos de renovación a un precio ya alto.
3. Las ventas se basan en un sistema de subasta y, en la mayoría de los casos, las ofertas de los compradores superan el precio inicial. Por lo que tengo entendido, esto no se aplica a los edificios nuevos, pero estaban significativamente más allá de nuestro presupuesto, por lo que no consideramos este segmento en absoluto.
Creo que mucha gente en todo el mundo está familiarizada con esta situación, ya que lo más probable es que las cosas sean iguales en las grandes ciudades.
Como todos los demás en nuestra búsqueda de propiedades, queríamos encontrar la casa perfecta en el área perfecta a un precio asequible. ¡Veamos cómo el análisis de datos nos ayudó a hacer esto!
Buscando datos
En cualquier proyecto de Data Science hay una etapa de recolección de datos, y para este caso en particular, buscaba una fuente que contenga información sobre todas las viviendas disponibles en el mercado. En Irlanda hay dos tipos de sitios:
- sitios web de agencias inmobiliarias,
- agregadores.
Ambas opciones son muy útiles y facilitan mucho la vida a vendedores y compradores. Desafortunadamente, la interfaz de usuario y los filtros sugeridos no siempre brindan la forma más eficiente de extraer la información requerida y comparar diferentes propiedades. Aquí hay algunas preguntas que son difíciles de responder con motores de búsqueda como Google:
1. ¿Cuánto tiempo se tarda en llegar al trabajo?
2. ¿Cuántas propiedades hay en una zona u otra? Es posible comparar distritos de ciudades en sitios web clásicos, pero generalmente cubren varios kilómetros cuadrados. Esto no es suficiente detalle para entender, por ejemplo, que una oración demasiado alta en una calle en particular indica algún tipo de truco. La mayoría de los sitios especializados tienen mapas, pero no son tan informativos como nos gustaría.
3. ¿Qué instalaciones hay cerca de la casa?
4. ¿Cuál es el precio medio de venta de un grupo de propiedades?
5. ¿Cuánto tiempo ha estado a la venta la propiedad? Incluso si esta información está disponible, no siempre es confiable, ya que la inmobiliaria podría eliminar el anuncio y volver a colocarlo.
El rediseño de la interfaz de usuario para que sea más amigable para el consumidor y la mejora de la calidad de los datos facilitó mucho la búsqueda de un hogar y nos permitió obtener información muy interesante.
De la idea a la herramienta
Datos básicos
El primer paso fue escribir un raspador para recopilar información básica:
- dirección sin procesar de la propiedad,
- precio de vendedor actual,
- enlace a la página con la propiedad,
- características básicas como número de habitaciones, número de baños, clasificación de eficiencia energética,
- número de visualizaciones de anuncios (si está disponible),
- tipo de inmueble (casa, apartamento, obra nueva).
Estos son, de hecho, todos los datos que pude encontrar en Internet. Para un análisis más profundo, necesitaba mejorar este conjunto de datos.
Mejorando la calidad de los datos
A la hora de elegir una vivienda, mi principal argumento a favor de la compra es un camino cómodo al trabajo, para mí no son más de 50 minutos para todo el trayecto de puerta a puerta. Para estos cálculos, decidí usar Google Cloud Platform:
1. Usando la API de codificación geográfica, obtuve las coordenadas de latitud y longitud usando la dirección de la propiedad.
2. Utilizando la API de direcciones, calculé el tiempo que se tarda en llegar de casa al trabajo a pie y en transporte público. Nota: el ciclismo es aproximadamente 3 veces más rápido que caminar.
3. Uso de asientos de API (API de Places)He recibido información sobre las comodidades de cada propiedad. En particular, estábamos interesados en farmacias, supermercados y restaurantes. Nota: Las API de Places son muy caras: con una base de datos de 4.000 propiedades, necesitaría ejecutar 12.000 consultas para encontrar información sobre tres tipos de servicios. Por lo tanto, excluí estos datos del tablero final.
Además de la ubicación geográfica, me interesaba otra pregunta: ¿cuánto tiempo lleva la propiedad en el mercado? Si la propiedad no se ha vendido por mucho tiempo, esto es una llamada de atención: tal vez algo esté mal en el área o en la casa en sí, o el precio de venta es demasiado alto.
Por el contrario, si la propiedad acaba de ponerse a la venta, hay que tener en cuenta que los propietarios no estarán de acuerdo con la primera oferta recibida. Desafortunadamente, esta información es bastante fácil de ocultar. Utilizando el aprendizaje automático básico, calculé este aspecto mediante el recuento de visualizaciones de anuncios y algunas otras métricas.
Finalmente, mejoré el conjunto de datos con algunos campos de servicio para facilitar el filtrado (por ejemplo, agregando una columna con un rango de precios).
Estudio de datos de Google
Con un conjunto de datos mejorado que estaba bien para mí, iba a crear un panel de control poderoso . Elegí Google Data Studio como herramienta de visualización de datos para esta tarea. Este servicio tiene algunas desventajas (sus capacidades son muy, muy limitadas), pero también tiene ventajas: es gratuito, tiene una versión web y puede leer datos de Google Sheets. A continuación se muestra un diagrama que describe todo el flujo de trabajo.

Algunos detalles de implementación
Para ser honesto, la implementación fue bastante sencilla y no hay nada nuevo o especial aquí: solo un montón de scripts para recopilar datos y algunas transformaciones básicas de Pandas. Salvo que cabe destacar la interacción con la API de Google y el cálculo del tiempo durante el cual la propiedad estuvo en el mercado.
Los datos siguientes no se extrajeron, sino que se generaron con este script .
Echemos un vistazo a los datos sin procesar.
Como esperaba, el archivo contiene las siguientes columnas:
id
: ID de anuncio._address
: Dirección de la propiedad._d_code
: . D<>. <> , (, ), — ._link
: , ._price
: .type
: (, , )._bedrooms
: ()._bathrooms
: ._ber_code
: , : «», ._views
: ( )._latest_update
: ( ).days_listed
: — , ,_last_update
.
El punto es llevar todo esto al mapa y aprovechar el poder de los datos geolocalizados. Para hacer esto, veamos cómo obtener la latitud y la longitud usando la API de Google.
Para hacer esto, necesita una cuenta con Google Cloud Platform, y luego puede seguir el tutorial en el enlace para obtener una clave API y habilitar la API correspondiente. Como escribí anteriormente, para este proyecto utilicé la API de codificación geográfica, la API de direcciones y la API de lugares (por lo que deberá habilitar estas API específicas al crear la clave de API). A continuación, se muestra un fragmento de código para interactuar con Google Cloud Platform.
# The Google Maps library
import googlemaps
# Date time for easy computations between dates
from datetime import datetime
# JSON handling
import json
# Pandas
import pandas as pd
# Regular expressions
import re
# TQDM for fancy loading bars
from tqdm import tqdm
import time
import random
# !!! Define the main access point to the Google APIs.
# !!! This object will contain all the functions needed
geolocator = googlemaps.Client(key="<YOUR API KEY>")
WORK_LAT_LNG = (<LATITUDE>, <LONGITUDE>)
# You can set this parameter to decide the time from which
# Google needs to calculate the directions
# Different times affect public transport
DEPARTURE_TIME = datetime.now
# Load the source data
data = pd.read_csv("/path/to/raw/data/data.csv")
# Define the columns that we want in the geocoded dataframe
geo_columns = [
"_link",
"lat",
"lng",
"_time_to_work_seconds_transit",
"_time_to_work_seconds_walking"
]
# Create an array where we'll store the geocoded data
geo_data = []
# For each element of the raw dataframe, start the geocoding
for index,
in tqdm(data.iterrows()):
# Google Geo coding
_location = ""
_location_json = ""
try:
# Try to retrieve the base location,
# i.e. the Latitude and Longitude given the address
_location = geolocator.geocode(row._address)
_location_json = json.dumps(_location[0])
except:
pass
_time_to_work_seconds_transit = 0
_directions_json = ""
_lat_lon = {"lat": 0, "lng": 0}
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the distance with PUBLIC TRANSPORT (`mode=transit`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG,
(_lat_lon["lat"], _lat_lon["lng"]), mode="transit")
_time_to_work_seconds_transit = _directions[0]["legs"][0]["duration"]["value"]
_directions_json = json.dumps(_directions[0])
except:
pass
_time_to_work_seconds_walking = 0
try:
# Given the work latitude and longitude, plus the property latitude and longitude,
# retrieve the WALKING distance (`mode=walking`)
_lat_lon = _location[0]["geometry"]["location"]
_directions = geolocator.directions(WORK_LAT_LNG, (_lat_lon["lat"], _lat_lon["lng"]), mode="walking")
_time_to_work_seconds_walking = _directions[0]["legs"][0]["duration"]["value"]
except:
pass
# This block retrieves the number of SUPERMARKETS arount the property
'''
_supermarket_nr = 0
_supermarket = ""
try:
# _supermarket = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="supermarket")
_supermarket_nr = len(_supermarket["results"])
except:
pass
'''
# This block retrieves the number of PHARMACIES arount the property
'''
_pharmacy_nr = 0
_pharmacy = ""
try:
# _pharmacy = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="pharmacy")
_pharmacy_nr = len(_pharmacy["results"])
except:
pass
'''
# This block retrieves the number of RESTAURANTS arount the property
'''
_restaurant_nr = 0
_restaurant = ""
try:
# _restaurant = geolocator.places_nearby((_lat_lon["lat"],_lat_lon["lng"]), radius=750, type="restaurant")
_restaurant_nr = len(_restaurant["results"])
except:
pass
'''
geo_data.append([row._link, _lat_lon["lat"], _lat_lon["lng"], _time_to_work_seconds_transit,
_time_to_work_seconds_walking])
geo_data_df = pd.DataFrame(geo_data)
geo_data_df.columns = geo_columns
geo_data_df.to_csv("geo_data_houses.csv", index=False)
Cálculo del tiempo que la propiedad está en el mercado
Echemos un vistazo más de cerca a los datos :
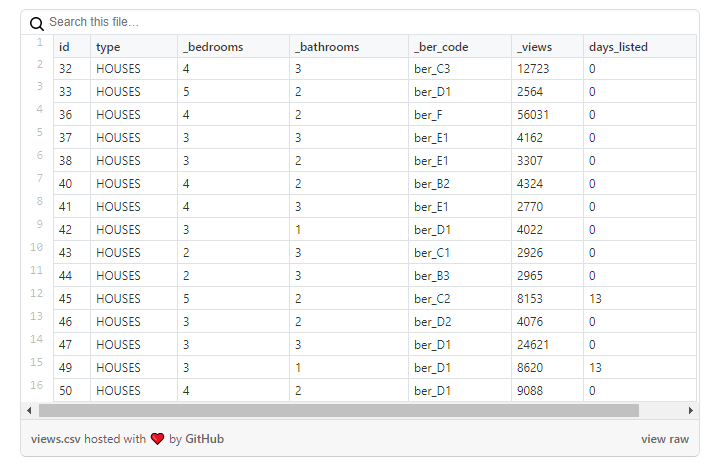
como puede ver en esta muestra, la cantidad de vistas de propiedades no se refleja en la cantidad de días durante los cuales el anuncio estuvo activo: por ejemplo, una casa con id = 47 tiene ~ 25 mil visitas, pero apareció ese día, cuando cargué datos.
Sin embargo, este problema no es común para todas las propiedades. En el siguiente ejemplo , la cantidad de vistas es más comparable a la cantidad de días que el anuncio estuvo activo:

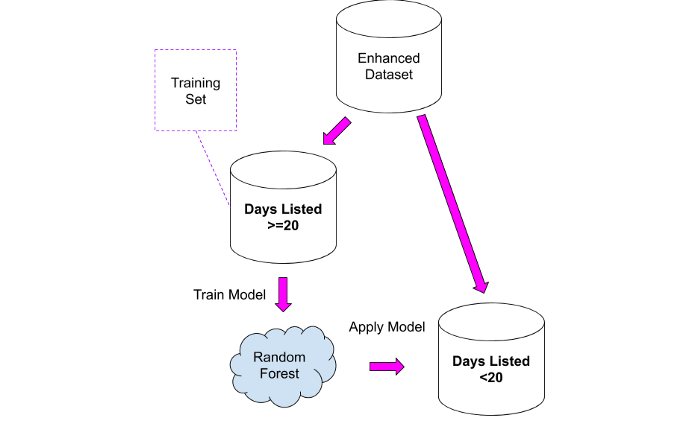
¿Cómo podemos utilizar la información anterior? ¡Fácilmente! Podemos usar el segundo conjunto de datos como un conjunto de entrenamiento para el modelo, que luego podemos aplicar al primer conjunto de datos.
Probé dos enfoques:
1. Tomar un conjunto de datos "comparable" y calcular el número promedio de vistas por día, luego aplicar ese valor al primer conjunto de datos. Este enfoque no carece de sentido común, pero tiene el siguiente problema: todas las propiedades se combinan en un solo grupo, y es probable que un anuncio de venta de una casa por valor de 10 millones de euros reciba menos visitas por día, ya que tal el presupuesto está disponible para un grupo reducido de personas.
2. Entrene el modelo de bosque aleatorio en el segundo conjunto de datos y luego aplíquelo al primer conjunto de datos.
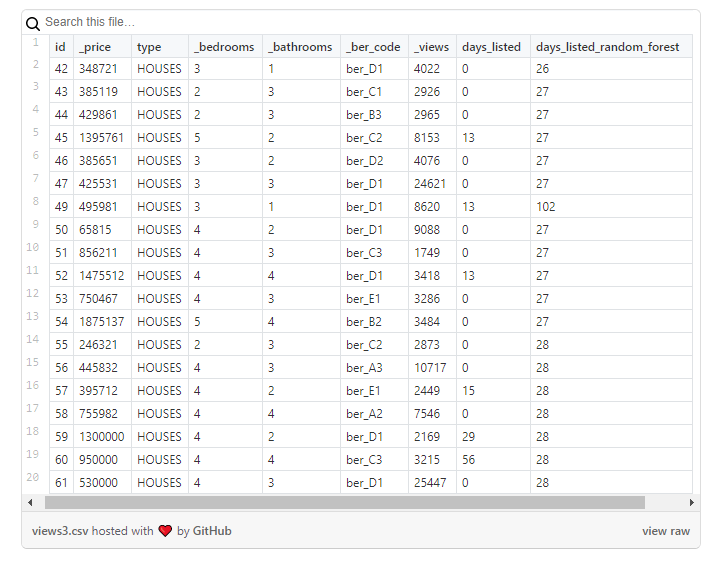
Los resultados deben verse con mucho cuidado, teniendo en cuenta que la nueva columna solo contendrá valores aproximados: los usé como punto de partida para analizar con más detalle las propiedades donde algo parecía extraño.
Análisis
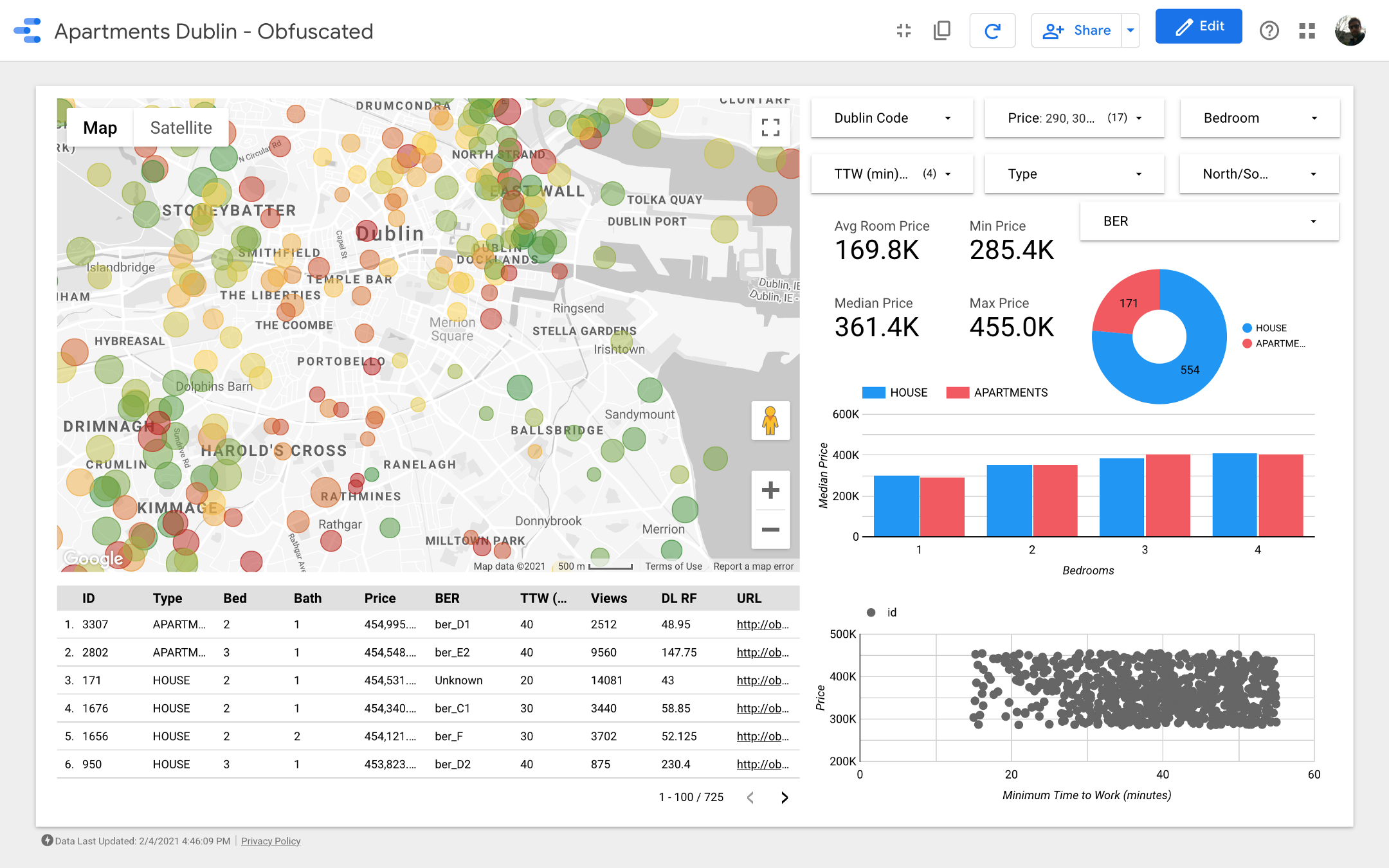
Señoras y señores, les presento el tablero final . Si quieres profundizar en él, sigue el enlace .
Nota: Desafortunadamente, el módulo de Google Maps no funciona cuando está integrado en un artículo, así que tuve que usar capturas de pantalla.
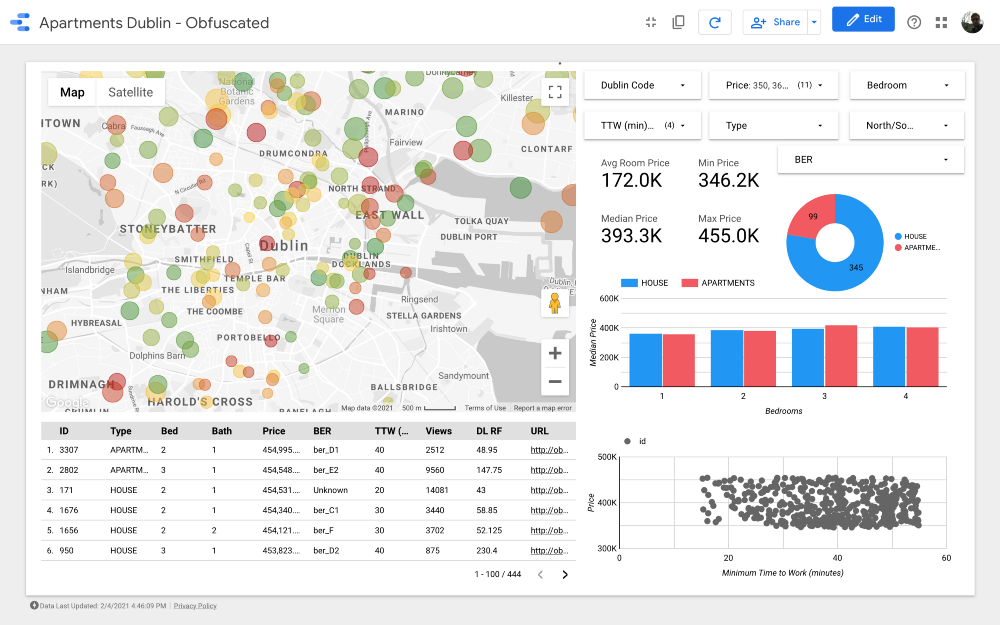
https://datastudio.google.com/s/qKDxt8i2ezE El
mapa es la parte más importante del tablero. El color de las burbujas depende del precio de la casa / apartamento, y el color solo tiene en cuenta las propiedades disponibles (correspondientes a la configuración del filtro en la esquina superior derecha); el tamaño de las burbujas indica la distancia a trabajar: cuanto más pequeña es, más corta la carretera.
Los gráficos le permiten analizar cómo cambia el precio de venta según algunas características (por ejemplo, el tipo de edificio o el número de habitaciones), y el gráfico de dispersión compara la distancia al trabajo y el precio de venta.
Por último, la tabla de datos sin procesar (
DL RF
corresponde a Days Listed Random Forest y muestra el número de días que el anuncio estuvo activo, el modelo Random Forest).
recomendaciones
Profundicemos en el análisis y veamos qué conclusiones podemos sacar del panel.
El conjunto de datos incluye alrededor de 4.000 casas y apartamentos: por supuesto, no podemos verlos todos, por lo que nuestra tarea es identificar un subconjunto de registros que contengan una o más propiedades que estamos listos para considerar comprar.
Primero, necesitamos aclarar los criterios de búsqueda. Por ejemplo, digamos que buscamos un inmueble que reúna las siguientes características:
1. Tipo de inmueble: Vivienda.
2. Número de habitaciones (dormitorios): 3.
3. Distancia al trabajo: menos de 60 minutos.
4. Calificación de eficiencia energética: A, B, C o D.
5. Precio: de 250 a 540 miles de euros.
Apliquemos todos los filtros menos el precio y miremos el mapa (filtrando solo aquellos que sean más caros que 1 millón y menos de 200 mil euros).
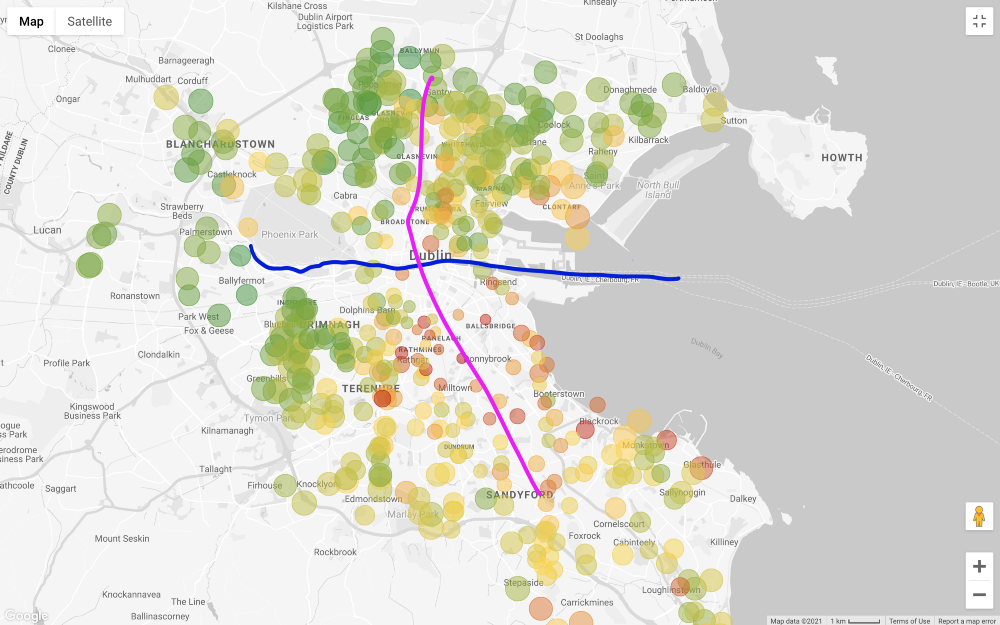
En general, el precio de venta de las propiedades en el sur de Liffey es mucho más alto que en el norte, con algunas excepciones en el suroeste de la ciudad. Incluso las "áreas exteriores" del norte, es decir, el noreste y el noroeste, parecen menos costosas que el norte del centro de la ciudad. Una de las razones de este precio es que la línea principal de tranvía de Dublín (LUAS) cruza la ciudad de norte a sur en línea recta (hay otra línea que va de oeste a este, pero no atraviesa todos los distritos comerciales).
Tenga en cuenta que estas consideraciones se basan únicamente en una inspección visual. Un enfoque más completo requiere probar la correlación entre el precio de una casa y su distancia a las rutas de transporte público, pero no estamos interesados en probar esta conexión.
La situación se vuelve aún más interesante, si establece los precios del filtro en línea con nuestro presupuesto (no olvide que en el mapa de arriba se muestra la casa con 3 dormitorios, y se pone a trabajar en menos de 60 minutos, y en el mapa de abajo se agrega solo filtrar por precio):
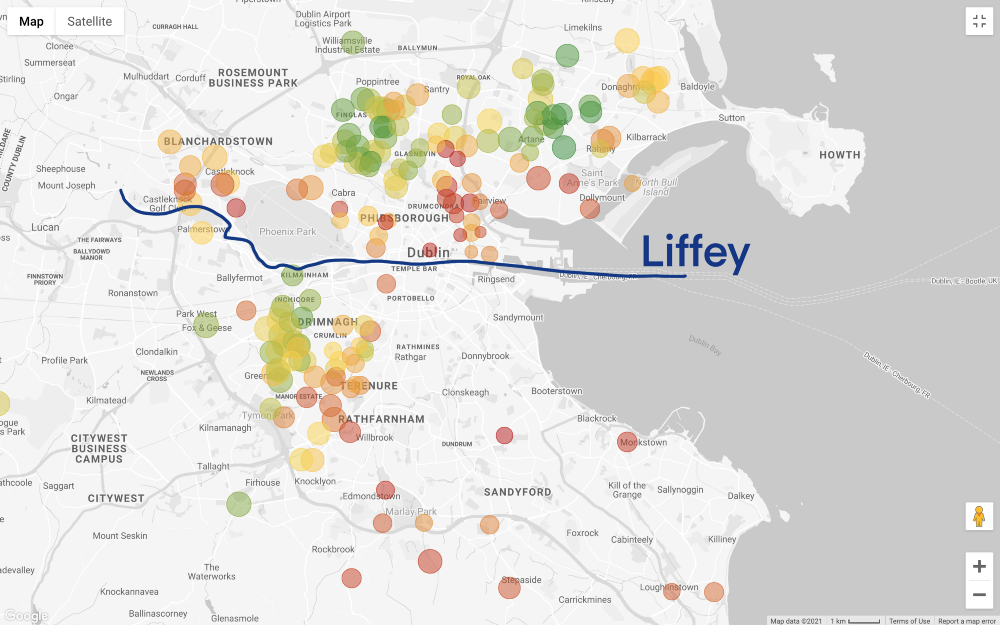
Retrocedamos un paso. Tenemos una idea general de las áreas que podemos permitirnos, pero ahora lo más difícil está por delante: la búsqueda de compromisos.! ¿Queremos encontrar una opción más económica? ¿O consideramos la mejor casa que pueden comprar nuestros ahorros ganados con tanto esfuerzo? Desafortunadamente, el análisis de datos no puede responder a estas preguntas, esta es una decisión comercial (y muy personal).
Supongamos que elegimos la segunda opción: priorizamos la calidad de la vivienda o área sobre el precio más bajo.
En este caso, debemos considerar las siguientes opciones:
1. Áreas con baja concentración de propuestas - una casa aislada en el mapa puede indicar que no hay muchas ofertas en el área, lo que significa que los propietarios no tienen prisa por parte con su casa en tan buena zona ...
2. Una casa ubicada en un grupo de propiedades caras: si todas las demás propiedades cercanas a una casa en particular son caras, esto puede significar que el área tiene una gran demanda. Esta es solo una nota adicional, pero podríamos cuantificar este fenómeno usando la autocorrelación espacial (por ejemplo, calculando el I de Moran ).
Aunque la primera opción parezca atractiva, hay que tener en cuenta que el precio bajísimo del inmueble en comparación con otras ofertas en la misma zona puede implicar algún tipo de pillaje en la propia casa (por ejemplo, habitaciones pequeñas o costes de reforma muy elevados ). Por ello, continuaremos nuestro análisis enfocándonos en la segunda opción, que, en mi opinión, es la más prometedora dado nuestro objetivo.
Echemos un vistazo más de cerca a las propuestas que hay en el área:

ya hemos reducido nuestras opciones de 4.000 a menos de 200, y ahora necesitamos romper mejor los puntos y comparar los grupos.
La automatización de la búsqueda de clústeres no agregará mucho a este análisis, pero apliquemos el algoritmo DBSCAN de todos modos.... Usamos DBSCAN porque algunos de los grupos pueden ser no globulares (por ejemplo, k-means no funcionará correctamente en esta base de datos). En teoría, necesitamos calcular la distancia geográfica entre los puntos, pero usaremos el sistema euclidiano, ya que da una buena aproximación:
import pandas as pd
from sklearn.cluster import DBSCAN
data = pd.read_csv("data.csv")
data["labels"] = DBSCAN(eps=0.01, min_samples=3).fit(data[["lat","lng"]].values).labels_
print(data["labels"].unique())
data.to_csv("out.csv")

El algoritmo mostró un resultado bastante bueno, pero revisaría los clústeres de la siguiente manera (teniendo en cuenta el conocimiento de los distritos comerciales de Dublín):

Rechazamos áreas con precios más bajos, ya que priorizamos la máxima calidad de vivienda y un camino cómodo para trabajar dentro nuestro presupuesto para que puedan excluirse los Clusters 2, 3, 4, 6 y 9. Tenga en cuenta que los Clusters 2, 3 y 4 están ubicados en algunas de las áreas más económicas del norte de Dublín (probablemente debido a una infraestructura de transporte público menos desarrollada). El clúster 11 presenta opciones costosas ubicadas lejos del trabajo, por lo que también podemos excluirlo.
En cuanto a los clústeres más caros, el número 7 es uno de los mejores en términos de distancia al trabajo. eso Drumcondra , una hermosa zona residencial en el norte de Dublín; a pesar de que su ubicación no es muy conveniente en relación con la línea de tranvía, por ella pasan rutas de autobús; en el grupo 8, los precios de la vivienda y la distancia al trabajo son los mismos que en Drumkondra. Otro conglomerado que vale la pena analizar es el número 10: parece estar en un área con menor oferta, lo que significa que la gente aquí probablemente rara vez vende viviendas, y el área también está muy convenientemente ubicada para las rutas públicas. Transporte (siempre que todas las áreas tengan el mismo densidad de población).
Finalmente, los grupos 1 y 5, ubicados junto al Phoenix Park, el parque público vallado más grande .
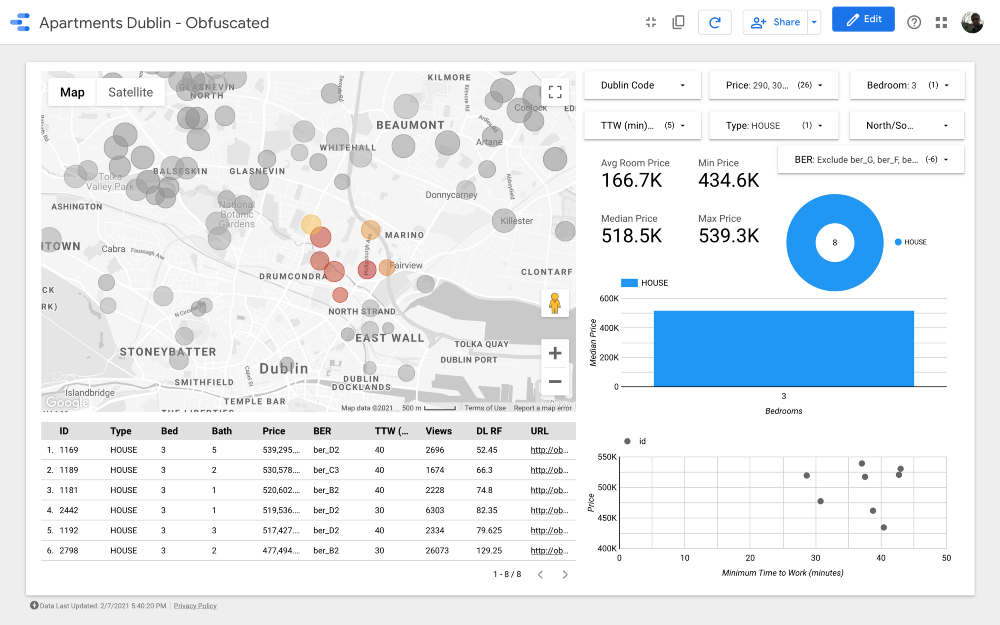
Grupo 7

Grupo 8
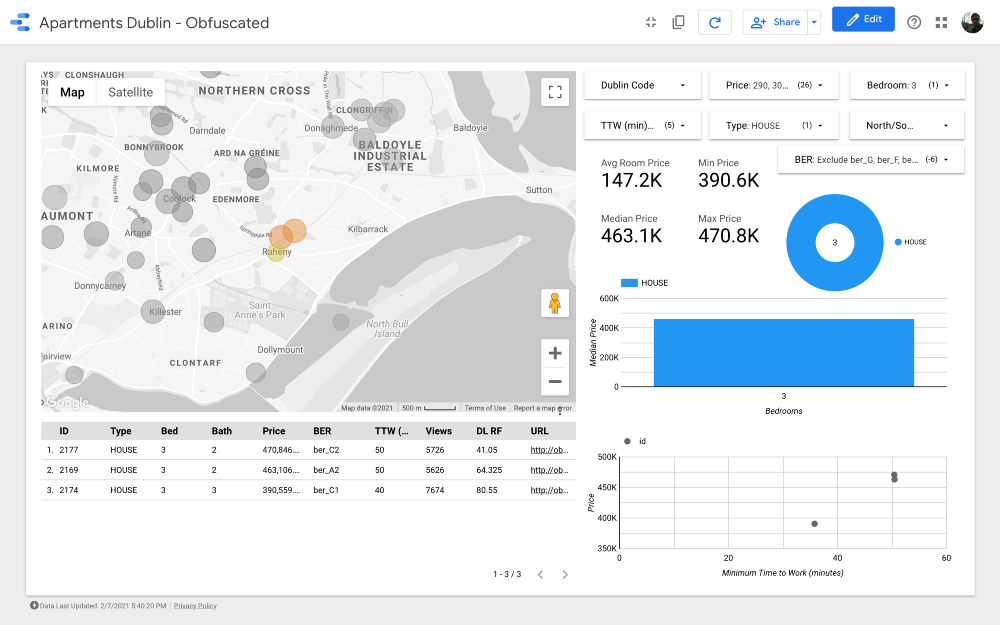
Grupo 10
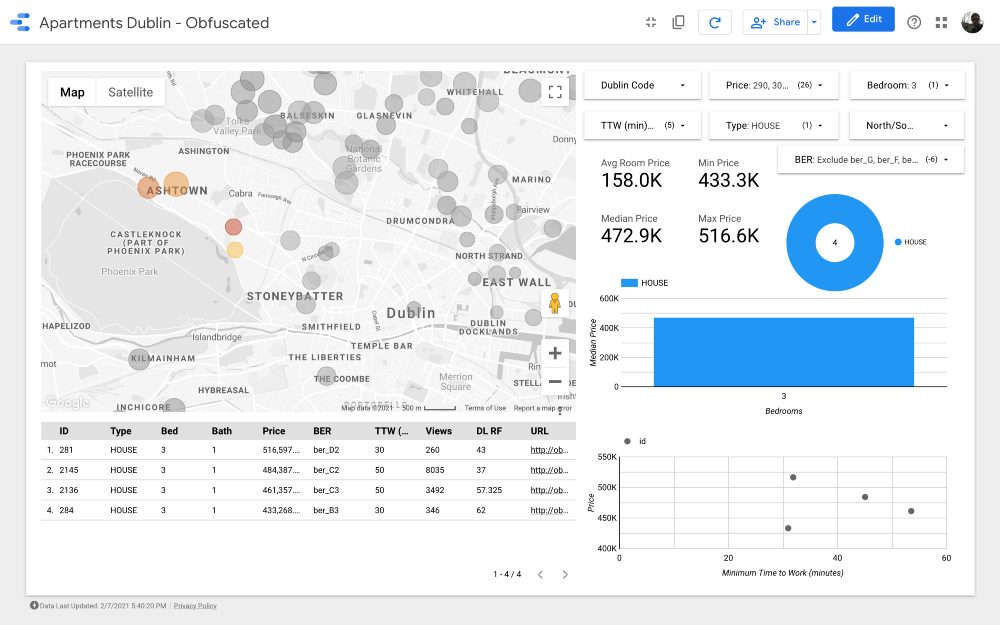
Grupo 1

Grupo 5
¡Excelente! Hemos encontrado 26 propiedades que vale la pena ver primero. ¡Ahora podemos analizar cuidadosamente cada oferta y, en última instancia, concertar una visita con un agente inmobiliario!
Conclusión
Comenzamos nuestra búsqueda, sin saber prácticamente nada sobre Dublín, y al final logramos un buen conocimiento de qué áreas de la ciudad son especialmente demandadas a la hora de comprar una vivienda.
Tenga en cuenta que ni siquiera miramos las fotos de estas casas y no leímos nada sobre ellas. ¡Con solo mirar un tablero bien organizado, llegamos a algunas conclusiones útiles a las que no podríamos haber llegado al principio!
Estos datos ya no son útiles y se pueden realizar algunas integraciones para mejorar el análisis. Algunas reflexiones:
1. No integramos el conjunto de datos de servicios (el que compilamos con la API de Places) en el estudio. Con un presupuesto mayor para servicios en la nube, podríamos agregar fácilmente esta información al tablero.
2. En Irlanda, se publican muchos datos interesantes en el sitio web de la oficina de estadística : por ejemplo, puede encontrar información sobre el número de llamadas a cada comisaría por trimestre y por tipo de delito. Así, podríamos averiguar en qué zonas hay más robos. Dado que es posible obtener datos censales para cada mesa de votación, también podríamos calcular la tasa de criminalidad per cápita. Tenga en cuenta que para estas funciones avanzadas, necesitamos un sistema de información geográfica apropiado (por ejemplo, QGIS ) o una base de datos que pueda manejar datos geográficos (por ejemplo, PostGIS ).
3. Irlanda tiene una base de datos de precios de viviendas anteriores denominada Registro de la propiedad residencial . Su sitio web contiene información sobre todas las propiedades residenciales compradas en Irlanda desde el 1 de enero de 2010, incluida la fecha de venta, el precio y la dirección. Al comparar los precios actuales de las viviendas con los precios anteriores de las viviendas, puede ver cómo ha cambiado la demanda a lo largo del tiempo.
4. Los precios del seguro de hogar dependen en gran medida de la ubicación de la vivienda. Con un poco de esfuerzo, podríamos eliminar los sitios de las compañías de seguros para integrar su "modelo de factor de riesgo" en nuestro tablero.
En un mercado como Dublín, encontrar un nuevo hogar puede ser una tarea abrumadora, especialmente para alguien que se acaba de mudar a la ciudad y no la conoce muy bien.
Gracias a esta herramienta, mi esposa y yo nos ahorramos tiempo (y al agente inmobiliario): fuimos a ver 4 veces, ofrecimos su precio a 3 vendedores y uno de ellos aceptó nuestra oferta.