
El manejo de duplicados es uno de los temas más dolorosos en el trabajo de un analista. En nuestra plataforma, tratamos de automatizar al máximo este proceso para reducir la carga de los expertos de NSI y aumentar la productividad de los colegas con el procesamiento de datos. Hoy veremos cómo la plataforma ayuda a formar un único registro de oro usando el ejemplo de uno de los libros de referencia más comunes y básicos: el directorio de “contrapartes”.
Consideremos uno de los escenarios típicos. Suponga que un gran distribuidor B2B recibe bienes de diferentes proveedores y los vende a clientes: entidad legal. personas. Si en la práctica todo va más o menos bien con el mantenimiento por parte del proveedor, entonces el procesamiento de la base de clientes a veces requiere todo un equipo dedicado de expertos. Esto se debe a que habitualmente las empresas utilizan varios sistemas-fuentes de datos de clientes: ERP, CRM, fuentes abiertas, etc. El trabajo es especialmente difícil cuando hay varios departamentos en la empresa, cada uno de los cuales mantiene su propia base de clientes dentro el mismo territorio ... En este caso, parte de los datos del cliente se duplica en la redistribución de una base y también se cruza implícitamente entre diferentes bases de clientes. En un sistema ERP, se requiere un procesamiento serio de registros duplicados para obtener el llamado registro maestro,con el que podrás trabajar en el futuro. La plataforma Unidata tiene un mecanismo especial para encontrar y procesar registros duplicados, que hace frente con éxito a tales tareas.
Empecemos
La plataforma se basa en el metamodelo del dominio utilizado. El dominio es un conjunto estructurado de registros, directorios. sus atributos y las relaciones entre ellos, que en conjunto describen la estructura de datos del dominio. Hablaremos sobre el metamodelo en sí más adelante, pero ahora veremos cómo la plataforma le permite trabajar con registros duplicados en un modelo de datos existente. En nuestro ejemplo, existe un registro de "contrapartes", donde los principales atributos son: el nombre de la contraparte (generalmente abreviado y completo), TIN, KPP, direcciones legales y reales, dirección de registro de la persona jurídica, etc.
La plataforma utiliza un mecanismo de consolidación para manejar duplicados. La esencia de la consolidación es que establecemos ciertas reglas para encontrar duplicados, definimos fuentes de datos y para cada fuente de datos establecemos pesos especiales que son responsables del nivel de confianza de la información recibida del sistema fuente, y luego los duplicados encontrados por el sistema se fusiona en un solo registro de referencia. En este caso, los registros duplicados desaparecen de los resultados de la búsqueda, pero permanecen en el historial del registro de referencia. Todos los ajustes se realizan en la interfaz del administrador de la plataforma y no requieren programación. Si la combinación de registros se realiza por error, siempre existe la posibilidad de deshacer la combinación. Por tanto, la mayor parte del trabajo con duplicados es asumido por el propio sistema, el usuario solo puede controlar este proceso.Consideremos la aplicación del mecanismo de consolidación en los casos del ejemplo indicado.
Digamos que se ha introducido la plataforma Unidata en el bus de integración de la empresa, que recibe datos de contrapartes del sistema CRM, sistema ERP y sistema de venta móvil. La plataforma elimina duplicados, enriquece y armoniza los datos y luego transfiere los registros de referencia a los sistemas receptores.
Caso 1. TIN y KPP coincidentes
La forma más fácil de encontrar contrapartes duplicadas es compararlas por TIN y KPP; en la mayoría de los casos, incluso un TIN es suficiente. Para implementar una regla de este tipo para la búsqueda de registros duplicados, es suficiente establecer una regla de coincidencia exacta para los atributos INN y KPP.
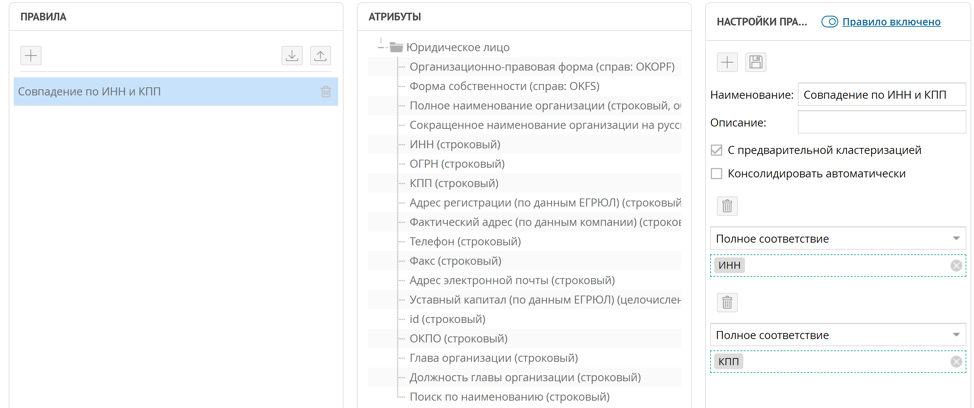
Según esta regla, cuando llega un nuevo registro a la plataforma, la regla de búsqueda de duplicados configurada se lanza automáticamente si la regla está configurada como "pre-agrupamiento". Todas las tuplas de registros encontradas por coincidencia de DCI y KPP se recopilan en grupos duplicados. En la ventana del clúster duplicado, Unidata le permite crear un registro maestro a partir de registros duplicados.
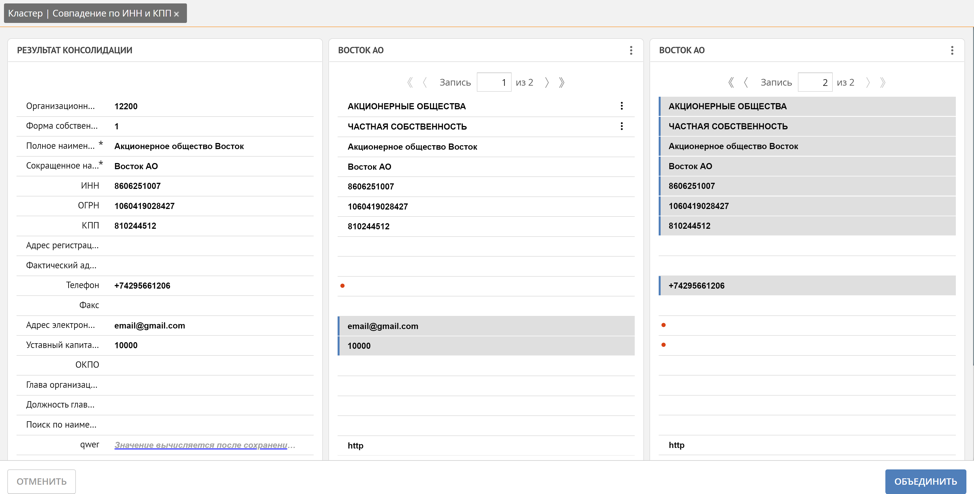
Aquí el usuario puede rastrear manualmente qué registro se convierte automáticamente en una referencia y, si es necesario, corregirlo marcando manualmente los valores de los atributos de los registros duplicados que deben incluirse en el registro de referencia, o marcando el registro completo. Además, Unidata admite un mecanismo para enriquecer los valores perdidos basándose en registros similares. Por ejemplo, el teléfono, el correo y el capital social se obtuvieron automáticamente de 2 registros duplicados diferentes.
Como ya hemos señalado, la plataforma, al formar un grupo de duplicados, determina automáticamente cómo se formará el registro de referencia. Esto se debe a los pesos de confianza mencionados anteriormente de los sistemas de origen. Cuanto mayor sea el peso del sistema de donde proviene el registro, más significativos serán los valores de sus atributos para el registro de referencia. Pero a menudo hay situaciones en las que los valores de ciertos atributos para un determinado sistema de origen deben prevalecer sobre todos los demás, por ejemplo, confiamos la dirección de entrega real del cliente sobre todo en el agente que negocia directamente en el territorio del cliente y conoce la dirección exactamente, lo que significa en nuestro ejemplo de sistema de ventas móvil. Para resolver estos problemas, la plataforma tiene la capacidad de establecer ponderaciones no solo para las fuentes de datos, sino también para los atributos de registro en el contexto de cada fuente de datos.Esta combinación de pesos le permite configurar de manera flexible las reglas para generar un registro de referencia.

Caso 2. Correspondencia borrosa por el nombre de la entidad jurídica
Si bien el NIF es un atributo obligatorio, supongamos que la información del cliente hace tiempo que no se actualiza, ha cambiado de forma organizativa y jurídica. En este caso, una entrada con un TIN diferente ya llegará a la plataforma y la coincidencia de TIN no funcionará. En este caso, la plataforma le permite formar una regla de coincidencia aproximada por el valor de los atributos, en este caso por el nombre de la entidad legal.

La búsqueda aproximada no tiene agrupamiento preliminar, ya que esta operación consume muchos recursos, lo que significa que esta regla no funcionará inmediatamente cuando se agregue un nuevo registro. Para iniciar las reglas de búsqueda aproximada, se utiliza una operación especial de búsqueda de duplicados, que es iniciada manualmente por el administrador o por el sistema en un horario. Una vez que se encuentran los duplicados, los grupos formados se pueden ver en una sección especial de la interfaz del operador de datos.

La búsqueda de duplicados difusos funciona de tal manera que determinamos valores de cadenas similares que difieren en 1-2 caracteres o no requieren más de dos permutaciones (distancia de Levenshtein), también existe la posibilidad de buscar por n-gramas. Este enfoque le permite encontrar registros similares con alta precisión, sin cargar recursos para calcular todas las posibles manipulaciones de cadenas si las cadenas son muy diferentes entre sí.
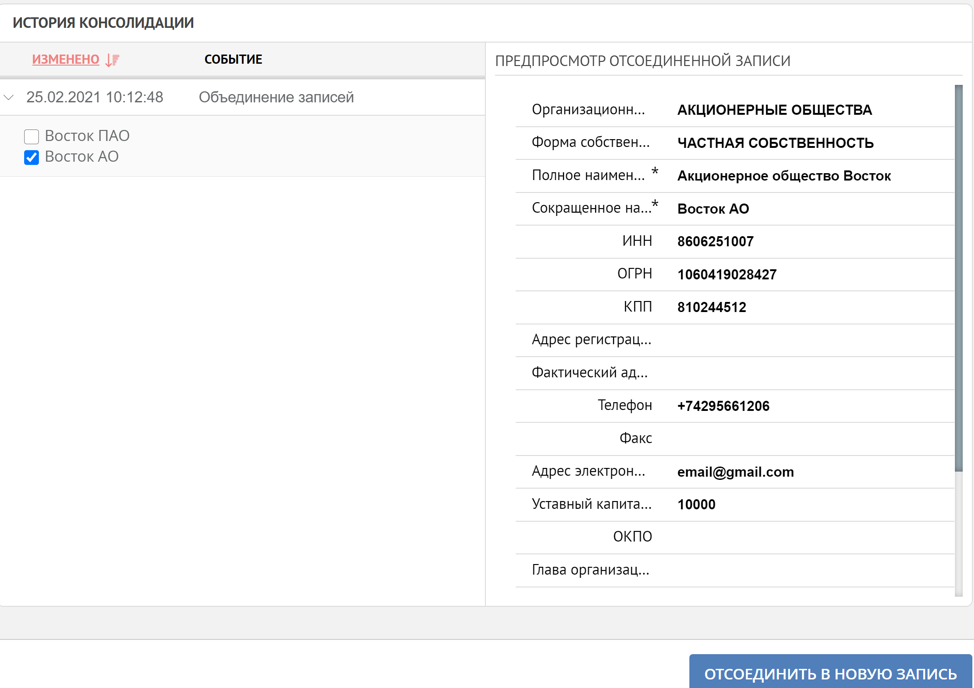
Así, hemos demostrado en casos típicos simples los principios de la plataforma al trabajar con registros duplicados. El procesamiento duplicado se puede realizar completamente bajo el control del usuario o automáticamente. Si la consolidación de datos se ha producido por error, entonces, como se mencionó al principio, el sistema siempre tiene la oportunidad de ver el historial de la formación del registro de referencia y, si es necesario, iniciar el proceso inverso.
No nos detenemos ahí, investigamos nuevos algoritmos y enfoques cuando trabajamos con duplicados, nos esforzamos por garantizar la máxima calidad de datos en una variedad de sistemas empresariales.