Nuestros lectores no pudieron evitar notar nuestro creciente interés en el idioma Go. Junto con el libro de la publicación anterior , tenemos muchas cosas interesantes sobre este tema . Hoy queremos ofrecerte una traducción del material "para los profesionales", que demuestra aspectos interesantes de la gestión manual de memoria en Go, así como la ejecución simultánea de operaciones de memoria en Go y C ++.
En el lenguaje de Dgraph Labs , Go se utiliza desde su creación en 2015. Después de cinco años o 200 000 líneas de código sobre la marcha, listo para anunciar felizmente que no está mal ir. Este lenguaje inspira no solo como una herramienta para crear nuevos sistemas, sino que incluso anima a escribir en Go los scripts que tradicionalmente se escribían en Bash o Python. Resulta que Go te permite crear una base de código limpio, legible y fácil de mantener que, lo que es más importante, es eficiente y fácil de manejar al mismo tiempo.
Sin embargo, hay un problema con Go, que se manifiesta ya en las primeras etapas del trabajo: la gestión de la memoria.... No hemos tenido ninguna queja sobre el recolector de basura Go, pero, además, cuánto simplifica la vida de los desarrolladores, tiene los mismos problemas que otros recolectores de basura: simplemente no puede competir en eficiencia con la gestión manual de memoria .
Administrar la memoria manualmente da como resultado un menor uso de la memoria, un uso predecible de la memoria y evita picos locos en el uso de la memoria cuando se asigna una gran cantidad de memoria de forma precisa. Todos los problemas anteriores con la gestión automática de la memoria se han detectado al utilizar la memoria en Go.
Los lenguajes como Rust pueden hacerse un hueco en parte porque proporcionan una gestión manual segura de la memoria. Esto es bienvenido.
En mi experiencia, asignar memoria manualmente y rastrear posibles fugas de memoria es más fácil que tratar de optimizar el uso de la memoria con herramientas de recolección de basura. La recolección de basura manual bien vale la molestia de crear bases de datos que ofrecen una escalabilidad prácticamente ilimitada.
Por amor a Go y por la necesidad de evitar la recolección de basura con Go GC, tuvimos que encontrar formas innovadoras de administrar manualmente la memoria en Go. Por supuesto, la mayoría de los usuarios de Go nunca necesitarán administrar la memoria manualmente, y le recomendamos que evite hacerlo a menos que realmente lo necesite. Y cuando lo necesite - lo que necesita saber cómo hacerlo .
Construyendo memoria con Cgo
Esta sección se basa en el artículo de la wiki de Cgo sobre la conversión de matrices C en segmentos Go. Podríamos usar malloc para asignar memoria en C y usar unsafe para pasarla a Go, sin requerir ninguna intervención del recolector de basura de Go.
import "C"
import "unsafe"
...
var theCArray *C.YourType = C.getTheArray()
length := C.getTheArrayLength()
slice := (*[1 << 28]C.YourType)(unsafe.Pointer(theCArray))[:length:length]
Sin embargo, lo anterior es posible con la advertencia que se indica en golang.org/cmd/cgo.
: . Go nil C ( Go) C, , C Go. , C Go, Go . C, Go.
Por lo tanto, en lugar de malloc, usaremos su contraparte
calloc
ligeramente más pesada.
calloc
funciona exactamente así
malloc
, con la salvedad de que restablece la memoria a cero antes de devolverla a la persona que llama.
Para comenzar, implementamos en su forma más simple las funciones Calloc y Free que asignan y liberan segmentos de bytes para Go a través de Cgo. Para probar estas funciones, se desarrolló y probó una prueba de uso continuo de la memoria . ... Esta prueba, en forma de bucle sin fin, repitió un ciclo de asignación / liberación de memoria, en el que primero se asignaron fragmentos de memoria de tamaño aleatorio hasta que la memoria total asignada alcanzó los 16 GB, y luego estos fragmentos se liberaron gradualmente hasta que solo se asignó 1 GB de memoria .
El programa C equivalente funcionó como se esperaba. Vimos
htop
cómo la cantidad de memoria asignada al proceso (RSS) llega primero a 16 GB, luego baja a 1 GB, luego vuelve a crecer a 16 GB, y así sucesivamente. Sin embargo, un programa Go usaba
Calloc
y
Free
usaba cada vez más memoria después de cada ciclo (vea el diagrama a continuación).
Se ha sugerido que esto se debe a la fragmentación de la memoria debido a la falta de "conciencia de subprocesos" en las llamadas
C.calloc
predeterminadas. Para evitar esto, se decidió intentarlo
jemalloc
.
Jemalloc
jemalloc
Es una implementación genéricamalloc
que se enfoca en prevenir la fragmentación y mantener la concurrencia escalable.jemalloc
se utilizó por primera vez en FreeBSD en 2005 como asignadorlibc
y desde entonces ha encontrado uso en muchas aplicaciones debido a su comportamiento predecible. - jemalloc.net
Cambiamos nuestras API para usarlas
jemalloc
con llamadas
calloc
y
free
. Además, esta opción funcionó a la perfección:
jemalloc
admite de forma nativa transmisiones casi sin fragmentación de la memoria. La prueba de memoria, que probó los ciclos de asignación y desasignación de memoria, se mantuvo dentro de lo razonable, aparte de la pequeña sobrecarga involucrada en la ejecución de la prueba.
Solo para reforzar que estamos usando jemalloc y evitar conflictos de nombres, agregamos un prefijo al instalar
je_
para que nuestras API ahora llamen
je_calloc
y
je_free
, no
calloc
y
free
.
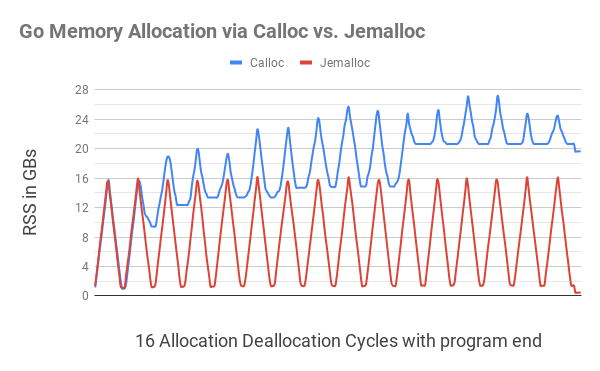
Esta ilustración muestra que la asignación de memoria Go con
C.calloc
conduce a una grave fragmentación de la memoria, lo que hace que el programa consuma hasta 20 GB de memoria en el undécimo ciclo. El código equivalente
jemalloc
no dio ninguna fragmentación notable, encajando en cada ciclo cerca de 1GB.
Más cerca del final del programa (una pequeña ondulación en el borde derecho), después de que se liberó toda la memoria asignada, el programa
C.calloc
aún consumía un poco menos de 20 GB de memoria, mientras que
jemalloc
costaba solo 400 MB de memoria.
Para instalar jemalloc, descárguelo desde aquí y luego ejecute los siguientes comandos:
./configure --with-jemalloc-prefix='je_' --with-malloc-conf='background_thread:true,metadata_thp:auto' make sudo make install
Todo el código se
Calloc
parece a esto:
ptr := C.je_calloc(C.size_t(n), 1)
if ptr == nil {
// NB: throw panic, ,
// . , – , Go,
// .
throw("out of memory")
}
uptr := unsafe.Pointer(ptr)
atomic.AddInt64(&numBytes, int64(n))
// C Go, .
return (*[MaxArrayLen]byte)(uptr)[:n:n]
Este código está incluido en el paquete de Ristretto . Se ha agregado una etiqueta de ensamblaje para permitir que el código resultante cambie a jemalloc para la asignación de bloques de bytes
jemalloc
. Para simplificar aún más las operaciones de implementación, la biblioteca se vinculó estáticamente
jemalloc
a cualquier binario de Go resultante estableciendo los indicadores LDFLAGS apropiados.
Descomposición de estructuras Go en segmentos de bytes
Ahora tenemos una forma de asignar y liberar un segmento de bytes, y luego lo usaremos para diseñar nuestras estructuras en Go. Puede comenzar con el ejemplo más simple (código completo).
type node struct {
val int
next *node
}
var nodeSz = int(unsafe.Sizeof(node{}))
func newNode(val int) *node {
b := z.Calloc(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = val
return n
}
func freeNode(n *node) {
buf := (*[z.MaxArrayLen]byte)(unsafe.Pointer(n))[:nodeSz:nodeSz]
z.Free(buf)
}
En el ejemplo anterior, presentamos la estructura Go en la memoria asignada en C usando
newNode
. Hemos creado una función adecuada
freeNode
que nos permite liberar memoria tan pronto como hayamos terminado con la estructura. La estructura en el lenguaje Go contiene el tipo de datos más simple
int
y un puntero a la siguiente estructura de nodo, todo esto se puede configurar en el programa y luego se puede acceder a estas entidades. Hemos seleccionado objetos de nodo 2M y hemos creado una lista vinculada a partir de ellos para demostrar que jemalloc funciona como se esperaba.
Con la asignación de memoria predeterminada de Go, puede ver que 31 MiB del montón se asignan a una lista vinculada con 2M de objetos, pero no se asigna nada
jemalloc
.
$ go run . Allocated memory: 0 Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 31 MiB
Usando la etiqueta de ensamblaje
jemalloc
, vemos que se asignan 30 MiB bytes de memoria
jemalloc
, y después de que se libera la lista vinculada, este valor cae a cero. Go solo asigna 399 KiB de la memoria, lo que probablemente se deba a la sobrecarga de ejecutar el programa.
$ go run -tags=jemalloc . Allocated memory: 30 MiB Objects: 2000001 node: 0 ... node: 2000000 After freeing. Allocated memory: 0 HeapAlloc: 399 KiB
Amortización de costos de Calloc con Allocator
El código anterior hace un gran trabajo de asignación de memoria en Go. Pero esto se hace a expensas de la degradación del rendimiento . Habiendo manejado ambas copias con
time
, vemos que sin el
jemalloc
programa las arregló en 1,15 segundos. Ya
jemalloc
que lo hizo 5 veces más lento, con más de 5.29.
$ time go run . go run . 1.15s user 0.25s system 162% cpu 0.861 total $ time go run -tags=jemalloc . go run -tags=jemalloc . 5.29s user 0.36s system 108% cpu 5.200 total
Esta desaceleración se puede atribuir al hecho de que se realizaron llamadas Cgo para cada asignación de memoria, y cada llamada Cgo incurre en algunos gastos generales. Para hacer frente a estos, se escribió la biblioteca Allocator , también incluida en el paquete ristretto / z . Esta biblioteca asigna segmentos de memoria más grandes en una llamada, cada uno de los cuales puede acomodar muchos objetos pequeños, lo que elimina la necesidad de costosas llamadas Cgo .
El Allocator comienza con un búfer y, tan pronto como se agota, crea un nuevo búfer dos veces mayor que el primero. Mantiene una lista interna de todos los búferes asignados. Finalmente, cuando el usuario haya terminado con los datos, podemos llamar a Release para liberar todos estos búferes de una sola vez. Nota: Allocator no mueve la memoria en absoluto. Esto asegura que todos los punteros que tenemos a la estructura continúen funcionando.
Aunque la gestión de memoria tal puede parecer torpe y en comparación con la forma de operar
tcmalloc
y
jemalloc
, este enfoque es mucho más simple. Una vez que asigna memoria, no puede liberar una sola estructura. Solo puede liberar toda la memoria utilizada por el asignador a la vez.
En lo que Allocator es realmente bueno es en asignar millones de estructuras a bajo costo y luego liberarlas cuando el trabajo está terminado sin tener que involucrar a un grupo de Go para hacer el trabajo . La ejecución del programa anterior con la nueva etiqueta de compilación del asignador se ejecutará incluso más rápido que la versión de memoria Go.
$ time go run -tags="jemalloc,allocator" . go run -tags="jemalloc,allocator" . 1.09s user 0.29s system 143% cpu 0.956 total
En Go 1.14 y posteriores, la bandera
-race
habilita las comprobaciones de alineación de estructuras en la memoria. Allocator tiene un método
AllocateAligned
que devuelve memoria y el puntero debe estar alineado correctamente para pasar estas comprobaciones. Si la estructura es grande, es posible que se pierda algo de memoria, pero las instrucciones de la CPU comienzan a funcionar de manera más eficiente debido a la delimitación correcta de palabras.
Hubo otro problema con la gestión de la memoria. Sucede que la memoria se asigna en un lugar y se libera en un lugar completamente diferente. Toda la comunicación entre estos dos puntos se puede realizar a través de estructuras, y solo se pueden distinguir transfiriendo un objeto específico
Allocator
. Para lidiar con esto, asignamos una identificación única a cada objeto.
Allocator
que estos objetos almacenan en la referencia
uint64
. Cada nuevo objeto
Allocator
se almacena en el diccionario global con referencia a una referencia a sí mismo. Los objetos del asignador se pueden recuperar utilizando esta referencia y liberarlos cuando los datos ya no sean necesarios.
Organizar enlaces de manera competente
NO haga referencia a la memoria asignada Go desde la memoria asignada manualmente.
Al asignar una estructura a mano como se muestra arriba, es importante asegurarse de que no haya referencias a la memoria asignada por Go dentro de esa estructura. Modifiquemos un poco la estructura anterior:
type node struct {
val int
next *node
buf []byte
}
Usemos la función
root := newNode(val)
definida anteriormente para seleccionar manualmente un nodo. Si luego instalamos
root.next = &node{val: val}
, asignando así todos los demás nodos en la lista vinculada a través de la memoria Go, inevitablemente obtenemos el siguiente error de fragmentación:
$ go run -race -tags="jemalloc" . Allocated memory: 16 B Objects: 2000001 unexpected fault address 0x1cccb0 fatal error: fault [signal SIGSEGV: segmentation violation code=0x1 addr=0x1cccb0 pc=0x55a48b]
La memoria asignada por Go está sujeta a la recolección de basura porque ninguna estructura Go válida apunta a ella. Las referencias son solo de la memoria asignada en C, y el montón de Go no contiene ninguna referencia adecuada, lo que provoca el error anterior. Por lo tanto, si crea una estructura y le asigna memoria manualmente, es importante asegurarse de que todos los campos accesibles de forma recursiva también se asignen manualmente.
Por ejemplo, si la estructura anterior usó un segmento de bytes, entonces asignamos ese segmento usando un Asignador y también evitamos mezclar la memoria Go con la memoria C.
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = -1
n.buf = allocator.Allocate(16) // 16
rand.Read(n.buf)
Cómo lidiar con gigabytes de memoria dedicada
Allocator
bueno para seleccionar manualmente millones de estructuras. Pero también hay casos en los que necesita crear miles de millones de objetos pequeños y ordenarlos. Para hacer esto en Go, incluso con ayuda
Allocator
, necesita escribir un código como este:
var nodes []*node
for i := 0; i < 1e9; i++ {
b := allocator.AllocateAligned(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
nodes = append(nodes, n)
}
sort.Slice(nodes, func(i, j int) bool {
return nodes[i].val < nodes[j].val
})
// .
Todos estos nodos 1B se asignan manualmente
Allocator
, lo que es caro. También tienes que gastar dinero en cada segmento de memoria en Go, lo cual es bastante caro en sí mismo, ya que necesitamos 8 GB de memoria (8 bytes por puntero de nodo).
Para hacer frente a estas situaciones prácticas,
z.Buffer
se ha creado un archivo mapeado en memoria, lo que permite a Linux intercambiar y vaciar páginas de memoria según lo requiera el sistema. Implementa
io.Writer
y nos permite no depender
bytes.Buffer
.
Más importante aún,
z.Buffer
proporciona una nueva forma de resaltar segmentos de datos más pequeños. Cuando se llama
SliceAllocate(n)
,
z.Buffer
registrará la longitud del segmento que se seleccionará
(n)
y, a continuación, seleccionará ese segmento. Esto hace
z.Buffer
que sea más fácil comprender los límites de los segmentos e iterar sobre los segmentos correctamente con
SliceIterate
.
Clasificación de datos de longitud variable
Para ordenar, inicialmente tratamos de obtener compensaciones de segmento de
z.Buffer
, referirnos a segmentos para comparar, pero ordenar solo las compensaciones. Una vez recibido el desplazamiento,
z.Buffer
puede leerlo, encontrar la longitud del segmento y devolver este segmento. Por lo tanto, un sistema de este tipo le permite devolver los segmentos en una forma ordenada sin recurrir a ninguna mezcla de memoria. A pesar de lo innovador que es, este mecanismo ejerce una presión significativa sobre la memoria, ya que todavía tenemos que pagar una penalización de memoria de 8 GB solo para impulsar las compensaciones de interés a la memoria Go.
El factor más importante que limita nuestro trabajo fue que los tamaños no eran los mismos para todos los segmentos. Además, podríamos acceder a estos segmentos solo en orden secuencial, y no al revés o al azar, no pudiendo calcular y almacenar compensaciones por adelantado. La mayoría de los algoritmos para ordenar en el lugar asumen que todos los valores son del mismo tamaño, se puede acceder a ellos en cualquier orden y nada impide que se intercambien.
sort.Slice
en Go funciona de manera similar y, por lo tanto, no era adecuado para
z.Buffer
.
Dadas estas limitaciones, se concluyó que el algoritmo de ordenación por combinación es el más adecuado para la tarea en cuestión. Con la ordenación por combinación, puede trabajar en un búfer, realizando operaciones en orden secuencial, con la sobrecarga de memoria adicional siendo solo la mitad del tamaño del búfer. Resultó no solo más barato que mover la sangría a la memoria, sino que también mejora significativamente la previsibilidad en términos de sobrecarga de memoria (la mitad del tamaño del búfer). Mejor aún, la sobrecarga requerida para realizar la ordenación por combinación se asigna a la memoria.
Hay un efecto muy positivo más de usar la ordenación por combinación. La clasificación de compensaciones tiene que mantener las compensaciones en la memoria mientras iteramos sobre ellas y procesamos el búfer, lo que solo aumenta la presión sobre la memoria. Con la ordenación por combinación, toda la memoria adicional que necesitábamos se libera para cuando comienza la enumeración, lo que significa que tendremos más memoria para procesar el búfer.
z.Buffer también admite la asignación de memoria
Calloc
, así como la asignación automática de memoria después de exceder un cierto límite especificado por el usuario. Por lo tanto, la herramienta funciona bien con datos de cualquier tamaño.
buffer := z.NewBuffer(256<<20) // 256MB Calloc.
buffer.AutoMmapAfter(1<<30) // mmap 1GB.
for i := 0; i < 1e9; i++ {
b := buffer.SliceAllocate(nodeSz)
n := (*node)(unsafe.Pointer(&b[0]))
n.val = rand.Int63()
}
buffer.SortSlice(func(left, right []byte) bool {
nl := (*node)(unsafe.Pointer(&left[0]))
nr := (*node)(unsafe.Pointer(&right[0]))
return nl.val < nr.val
})
// .
buffer.SliceIterate(func(b []byte) error {
n := (*node)(unsafe.Pointer(&b[0]))
_ = n.val
return nil
})
Detectando pérdidas de memoria
Toda esta discusión estaría incompleta sin tocar el tema de las pérdidas de memoria. Después de todo, si asignamos memoria manualmente, las pérdidas de memoria serán inevitables en todos aquellos casos en los que nos olvidemos de liberar memoria. ¿Cómo puedes atraparlos?
Durante mucho tiempo hemos usado una solución simple: usamos un contador atómico que realiza un seguimiento de la cantidad de bytes asignados durante tales llamadas. En este caso, puede averiguar rápidamente cuánta memoria hemos asignado manualmente en el programa utilizando
z.NumAllocBytes()
. Si al final de la prueba de memoria todavía nos quedaba algo de memoria adicional, significaba una fuga.
Cuando logramos encontrar una fuga, primero intentamos usar el generador de perfiles de memoria jemalloc. Pero pronto quedó claro que esto no ayudó: no vio toda la pila de llamadas, ya que estaba chocando con el límite de Cgo. Todo lo que ve el generador de perfiles es la asignación de memoria y los actos de liberación de las mismas llamadas
z.Calloc
y
z.Free
.
Gracias al tiempo de ejecución de Go, pudimos construir rápidamente un sistema simple para captar a las personas que llaman
z.Calloc
y asignarlas a las llamadas
z.Free
. Este sistema requiere bloqueos mutex, por lo que decidimos no habilitarlo de forma predeterminada. En su lugar, usamos la bandera de compilación
leak
para habilitar mensajes de depuración para fugas en ensamblajes de desarrollador. Por lo tanto, las fugas se detectan automáticamente y se muestran en la consola exactamente donde se originaron.
// .
pc, _, l, ok := runtime.Caller(1)
if ok {
dallocsMu.Lock()
dallocs[uptr] = &dalloc{
pc: pc,
no: l,
sz: n,
}
dallocsMu.Unlock()
}
// , , .
// ,
// , .
$ go test -v -tags="jemalloc leak" -run=TestCalloc
...
LEAK: 128 at func: github.com/dgraph-io/ristretto/z.TestCalloc 91
Producción
Con la ayuda de las técnicas descritas, se logra una media dorada. Podemos asignar memoria manualmente en rutas de código críticas que dependen en gran medida de la memoria disponible. Al mismo tiempo, podemos aprovechar la recolección automática de basura de formas menos críticas. Incluso si no es muy bueno manejando Cgo o jemalloc, puede utilizar estas técnicas con fragmentos de memoria relativamente grandes en Go; el efecto será comparable.
Todas las bibliotecas mencionadas anteriormente están disponibles bajo la licencia Apache 2.0 en el paquete Ristretto / z . La prueba de memoria y el código de demostración se encuentran en la carpeta contrib .