
¿Cómo asegurarse de que cualquier desarrollador pueda ofrecer rápidamente una solución a su problema y garantizar que la entregará a producción? La implementación de la aplicación es sencilla. Convertirlo en un producto completo para que una docena de equipos lo utilicen en cien instancias es más difícil. Y si estamos hablando de un sistema maestro de varios terabytes, entonces el nivel de ansiedad aumenta, las manos sudan y la base está a punto de estallar (tal vez).
Quiero compartir una forma de implementar sin tiempo de inactividad y sin denegación de servicio. Pipeline de Jenkins, cero intermediarios, 500 instancias en un entorno de producción en 60 minutos. Todo esto es de código abierto. Para más detalles te invito debajo del gato.
Mi nombre es Roman Proskin, creo y apoyo sistemas de alta carga basados en Tarantool en Mail.ru Group. Te diré cómo nuestro equipo construyó una implementación de la aplicación Tarantool, que actualiza el código en un entorno de producción sin tiempo de inactividad ni denegación de servicio. Describiré los problemas que encontramos en el proceso y las soluciones que elegimos al final. Espero que nuestra experiencia sea útil para desarrollar su despliegue.
Implementar una aplicación es fácil. Tarantool tiene una utilidad de cartucho-cli ( github). Con él, la aplicación agrupada se implementará en algún lugar de Docker en un par de minutos. Es mucho más difícil convertir una solución de la rodilla en un producto completo. Debería manejar fácilmente cientos de instancias. Al mismo tiempo, es necesario tener demanda en decenas de equipos de diferentes niveles de formación.
La idea detrás de nuestra implementación es muy simple:
- Toma dos servidores de hierro.
- En cada uno lanza una instancia.
- Combínalos en un solo juego de réplicas.
- Actualiza uno por uno.
Pero cuando se trata de un sistema maestro con varios terabytes de datos, el nivel de ansiedad aumenta, las manos sudan y la base está a punto de estallar (tal vez).
Estableciendo las condiciones iniciales
El sistema tiene un SLA estricto: es necesario asegurar una disponibilidad del 99%, teniendo en cuenta el trabajo planificado. Esto significa que hay un total de 87 horas al año en las que podemos permitirnos no responder a las consultas. Parece que 87 horas es mucho, pero ...
El proyecto está diseñado para un volumen de datos de aproximadamente 1,8 TB. ¡Solo te llevará 40 minutos reiniciar! La actualización en sí, si los cambios se implementan manualmente, agregará más desde arriba. Hacemos tres actualizaciones por semana: un total de 40 * 3 * 52/60 = 104 horas - Se viola el SLA . Y estos son solo trabajos planificados sin tener en cuenta los accidentes que seguramente ocurrirán.
La aplicación fue desarrollada para una gran carga de usuarios, lo que significa que tenía que cumplir con los requisitos de estabilidad. Para no perder datos en caso de falla de un nodo, decidimos dividir geográficamente nuestro clúster en dos centros de datos. Así que decidimos un mecanismo de implementación que no violaría el SLA. Deje que las instancias se actualicen no de inmediato, sino en lotes en los centros de datos.
La carga se puede transferir al segundo centro de datos, luego el clúster estará disponible para su registro durante toda la actualización. Este es un despliegue de hombro clásico y una de las prácticas estándar de recuperación ante desastres .
La capacidad de actualizar en todos los centros de datos es uno de los elementos clave de una implementación sin tiempo de inactividad. Les contaré más sobre el proceso al final del artículo, pero por ahora me detendré en las características de nuestro despliegue inhumano y las dificultades que encontramos.
Problemas
Transferimos el tráfico a través de la carretera
Hay varios centros de datos y las solicitudes pueden dirigirse a cualquiera de ellos. Un viaje a un centro de datos cercano para obtener datos aumentará el tiempo de respuesta en 1-100 ms. Para evitar el tráfico cruzado, dimos a nuestros centros de datos etiquetas activas y en espera . El equilibrador (nginx) está configurado para que el tráfico siempre fluya hacia el centro de datos activo. Si Tarantool falla o deja de estar disponible en el centro de datos activo, cambia automáticamente a la reserva.
Cada solicitud de usuario es importante, por lo que necesita una forma de garantizar que se mantengan las conexiones. Para esto, escribimos un libro de jugadas ansible separado que cambia el tráfico entre centros de datos. El cambio se implementa mediante una directiva
backup
en la descripción
upstream
para el servidor. Las aguas arriba son seleccionadas por el límite, que se activará. El resto está prescrito
backup
: nginx permitirá el tráfico en ellos solo si todos los activos no están disponibles. Al cambiar la configuración, las conexiones abiertas no se cierran y las nuevas solicitudes irán a los enrutadores que no están sujetos a reiniciarse.
¿Qué se puede hacer si la infraestructura no tiene un balanceador de carga externo? Escriba su propio mini equilibrador en Java que supervisará la disponibilidad de las instancias de Tarantool. Pero este subsistema separado también requerirá su propio despliegue. Otra opción es construir un mecanismo de conmutación dentro de los enrutadores. Una cosa permanece sin cambios: es necesario controlar el tráfico HTTP.
Lo solucionamos con nginx, pero los problemas no terminaron ahí. El cambio también debe realizarse para los maestros en conjuntos de réplicas. Como mencioné, los datos deben mantenerse cerca de los enrutadores para evitar viajes de red innecesarios. Además, cuando el maestro actual (es decir, una instancia de almacenamiento con acceso de escritura) falla, el mecanismo de conmutación por error no funciona de inmediato. Si bien el clúster toma una decisión general sobre la indisponibilidad de la instancia, todas las solicitudes de los datos afectados serán erróneas. Para resolver este problema, también necesitábamos compilar un libro de jugadas, donde usamos consultas GraphQL para la API del clúster.
Los mecanismos para cambiar asistentes y cambiar el tráfico de usuarios son los últimos elementos clave de una implementación sin tiempo de inactividad. Un equilibrador de carga controlado evita la pérdida de conexiones y los errores en el procesamiento de las solicitudes de los usuarios y el cambio de maestros: errores con el acceso a los datos. Junto con la actualización sobre los hombros de estos tres pilares, se obtiene una implementación tolerante a fallas, que automatizamos aún más.
Lucha contra el legado
El cliente ya tenía un mecanismo de implementación listo para usar: roles que implementaban y configuraban instancias paso a paso. Luego vinimos con el cartucho ansible mágico ( github) que resolverá todos los problemas. No tomamos en cuenta solo que el cartucho ansible en sí es un monolito: un papel importante, cuyas diferentes etapas están separadas por etiquetas y tareas separadas. Para utilizarlo por completo, fue necesario cambiar el proceso de entrega del artefacto, revisar la estructura de directorios en las máquinas de destino, cambiar el orquestador y mucho más. Pasé un mes refinando la implementación usando ansible-cartucho. El papel monolítico simplemente no encajaba en los libros de jugadas terminados. No funcionó de esta forma, y me detuvo una pregunta justa de un colega: "¿Lo necesitamos?"
No nos dimos por vencidos: separamos la configuración del clúster de una sola pieza, a saber:
- combinar instancias de almacenamiento en conjuntos de réplicas;
- bootstrap vshard (mecanismo de fragmentación de datos de clúster);
- configuración de conmutación por error (conmutación automática de maestros en caso de caída).
Estas son las etapas finales de la implementación, cuando todas las instancias están en funcionamiento. Desafortunadamente, todos los demás pasos tuvieron que dejarse como están.
Elegir un orquestador
El código en los servidores es inútil si no se puede ejecutar. Necesitamos una utilidad para iniciar y detener instancias de Tarantool. El cartucho ansible incluye tareas para crear archivos de servicio systemctl y trabajar con paquetes rpm. Pero la especificidad de nuestra tarea fue la presencia de un circuito cerrado en el cliente y la ausencia de privilegios de sudo. Esto significa que no pudimos usar systemctl.
Pronto encontramos un orquestador que no requiere privilegios de root permanentes - supervisord... Primero tuve que instalarlo en todos los servidores y también resolver problemas locales con el acceso al archivo de socket. Ha aparecido un nuevo rol ansible que funciona con supervisor: incluye tareas para crear archivos de configuración, actualizar la configuración, iniciar y detener instancias. Eso fue suficiente para ponerlo en producción.
Por el bien del experimento, agregamos la capacidad de ejecutar la aplicación usando supervisord en ansible-cartucho. Este método resultó ser menos flexible y aún está pendiente de completarse en una rama separada.
Reducir los tiempos de carga
Independientemente del orquestador que usemos, no podemos esperar una hora para que se inicie la instancia. El umbral es de 20 minutos. Si la instancia no está disponible por más tiempo que este umbral, se activará un bloqueo automático y se registrará en el sistema de contabilidad. Los accidentes frecuentes afectan el desempeño clave de los equipos y pueden socavar los planes para el desarrollo del sistema. No quiero perder la prima en absoluto debido al despliegue banalmente necesario. Por supuesto, debe mantenerse dentro de los 20 minutos.
Hecho: El tiempo de descarga depende directamente de la cantidad de datos. Cuanto más necesite subir de los registros a la RAM, más tiempo se iniciará la instancia después de la actualización. También debe tener en cuenta que las instancias de almacenamiento en la misma máquina competirán por los recursos: Tarantool usa todos los núcleos del procesador para crear índices.
Según nuestras observaciones, el tamaño
memtx_memory
por instancia no debe exceder los 40 GB. Este valor es óptimo, por ejemplo, para que la recuperación tarde menos de 20 minutos. El número de instancias en un servidor se calcula por separado y está estrechamente relacionado con la infraestructura del proyecto.
Conectamos monitorización
Cualquier sistema necesita ser monitoreado y Tarantool no es una excepción. Nuestro seguimiento no apareció de inmediato. Se dedicó todo un bloque a obtener el acceso necesario, la aprobación y la configuración del entorno.
En el proceso de desarrollo de la aplicación y redacción de guías, modificamos ligeramente el módulo de métricas ( github ). Ahora puede dividir las métricas por el nombre de la instancia desde la que volaron: etiquetas globales hechas. Como resultado de la integración con los sistemas de monitoreo, ha surgido un rol completo para las aplicaciones de clúster. El nuevo tipo de métricas cuantílicas también surgió de la generalización de los requisitos de nuestro sistema.
Ahora vemos el número actual de solicitudes al sistema, el tamaño de la memoria utilizada, el retraso de replicación y muchas otras métricas clave. Además, se configuran con notificaciones en chats. Los problemas más críticos caen dentro del sistema general de accidentes automovilísticos y tienen un SLA claro para su eliminación.
Un poco sobre las herramientas. Se recopila una descripción detallada de dónde, qué y cómo obtener en etcd , desde donde el agente de telegraf recibe sus instrucciones. Las métricas con formato JSON se almacenan en InfluxDB . Usamos Grafana como visualizador , para lo cual incluso escribimos un tablero de plantilla . Y finalmente, las alertas se configuran mediante kapacitor .
Por supuesto, esta está lejos de ser la única opción para implementar el monitoreo. Puede usar Prometheus , y las métricas simplemente saben cómo dar valores en el formato requerido. Para las alertas, zabbix también puede ser útil , por ejemplo.
Mi colega me contó más sobre la configuración de la monitorización de Tarantool en el artículo " Monitorización de Tarantool: registros, métricas y su procesamiento ".
Configurar el registro
No puede limitarse a monitorear. Para obtener una imagen completa de lo que está sucediendo con el sistema, se deben recopilar todos los diagnósticos, y esto también incluye los registros. Además, cuanto mayor sea el nivel de registro, más información de depuración y mayores serán los archivos de registro.
El espacio en disco no es infinito. Nuestra aplicación podría generar hasta 1 TB de registros por día en la carga máxima. En tal situación, puede agregar discos, pero tarde o temprano se agotará el espacio libre o el presupuesto del proyecto. ¡Pero tampoco quiere perder información de depuración sin dejar rastro! ¿Qué hacer?
Una de las etapas de implementación, agregamos la configuración de logrotate: mantenga un par de archivos de 100 MB sin procesar y comprima un par más. En funcionamiento normal, esto es suficiente para detectar un problema local en 24 horas. Los registros se almacenan en un directorio estrictamente definido en formato JSON. Todos los servidores ejecutan el demonio filebeat , que recopila los registros de la aplicación y los envía para su almacenamiento a largo plazo a ElasticSearch . Este enfoque le evita errores de desbordamiento del disco y le permite analizar el rendimiento del sistema en caso de problemas a largo plazo. Y este enfoque encaja bien en la implementación.
Escalamos la solución
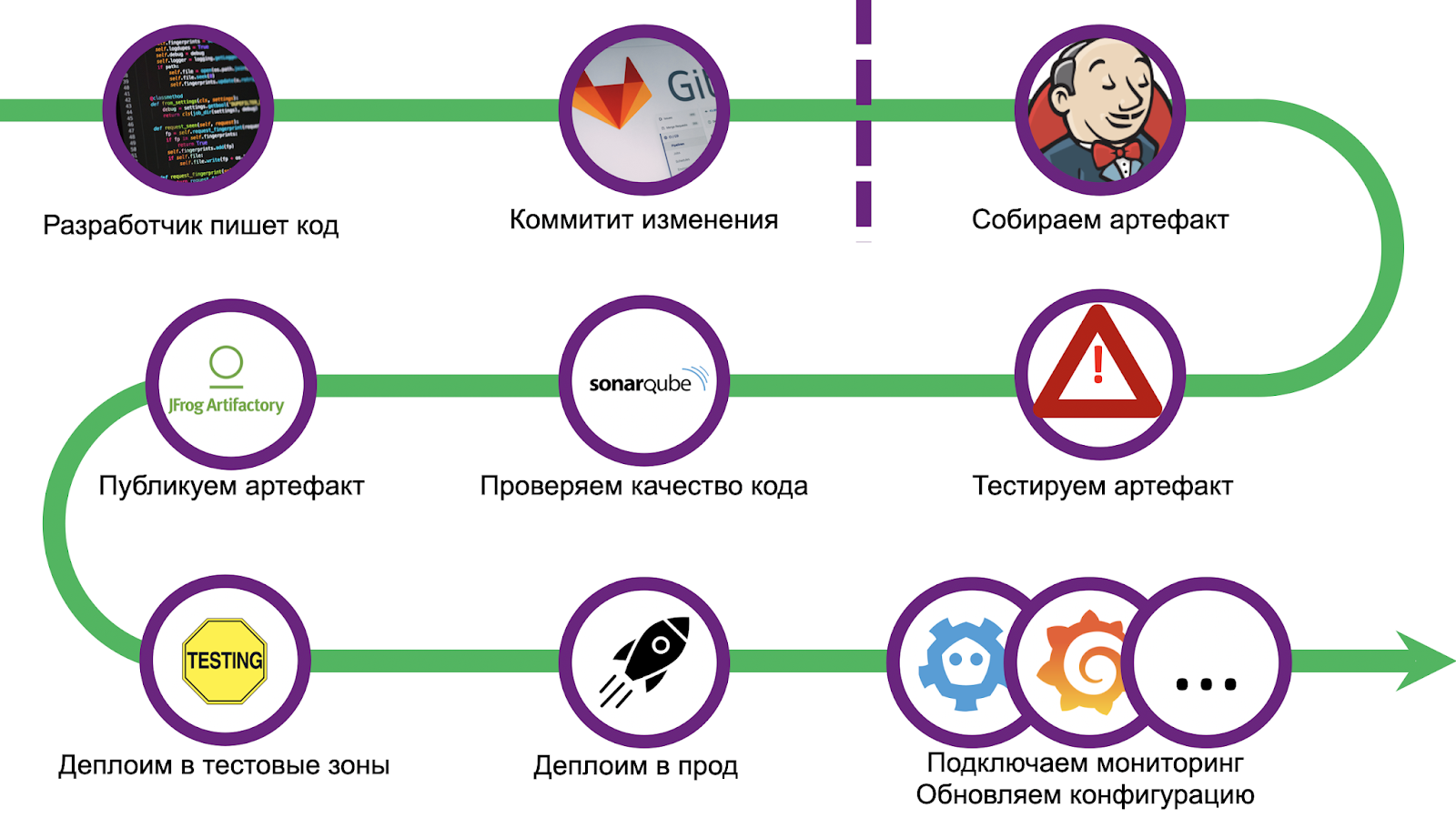
El camino era largo y espinoso, conseguimos una buena cantidad de conos. Para no repetir errores, estandarizamos la implementación y usamos el paquete CI / CD: Gitlab + Jenkins. El escalado también causó una serie de problemas, la depuración de la solución llevó más de un mes. Pero lo hemos superado y ahora estamos listos para compartir nuestra experiencia con usted. Caminemos por los pasos.
¿Cómo asegurarse de que cualquier desarrollador pueda ofrecer rápidamente una solución a su problema y garantizar que la entregará a producción? ¡Quítenle Jenkinsfile! Es necesario delinear límites audaces, ir más allá de lo que significa la imposibilidad de implementación, y dirigir al desarrollador por este camino.
Hicimos una aplicación de muestra en toda regla, que se implementó de la misma manera y que es un punto de partida exhaustivo. Pero fuimos aún más lejos con el cliente: escribimos una utilidad para crear automáticamente una plantilla que configura un repositorio de git y tareas de Jenkins. El desarrollador necesitará menos de una hora para todo y el proyecto estará en producción.
La canalización comienza con una verificación de código estándar y una configuración del entorno. Además, colocamos inventario para su posterior implementación en varias zonas de prueba funcional y prod. Luego viene la fase de prueba unitaria.
El marco de prueba estándar de Tarantool luatest ( github). Puede escribir tanto pruebas de unidad como de integración en él, hay módulos auxiliares para ejecutar y configurar Tarantool Cartridge . También en versiones recientes puede habilitar la cobertura . Lo comenzamos con un simple comando:
.rocks/bin/luatest --coverage
Al final de las pruebas, las estadísticas recopiladas se envían a SonarQube , software para evaluar la calidad y seguridad del código. En el interior, ya hemos configurado el Quality Gate. Se valida cualquier código de la aplicación, independientemente del idioma (Lua, Python, SQL, etc.). Sin embargo, no hay un controlador integrado para Lua, por lo que para representar la cobertura en formato genérico, tenemos complementos que se instalan antes de que comiencen las pruebas.
tarantoolctl rocks install luacov 0.13.0-1 # coverage
tarantoolctl rocks install luacov-reporters 0.1.0-1 #
Una versión de consola simple se puede ver así:
.rocks/bin/luacov -r summary . && cat ./luacov.report.out
El informe de SonarQube se genera mediante el comando:
.rocks/bin/luacov -r sonar
Después de la cobertura viene la etapa de linter. Estamos usando luacheck ( github ), que también es uno de los complementos de Tarantool.
tarantoolctl rocks install luacheck 0.26.0-1
Los resultados de Linter también se envían a SonarQube:
.rocks/bin/luacheck --config .luacheckrc --formatter sonar *.lua
Las estadísticas de cobertura de código y los linters se cuentan juntos. Para pasar el Quality Gate, se deben cumplir todas las condiciones:
- la cobertura del código por las pruebas debe ser al menos del 80%;
- los cambios no deben introducir nuevos olores;
- el número total de problemas críticos es 0;
- el número total de poblaciones no críticas es inferior a 5.
Después de pasar Quality Gate, debes hornear el artefacto. Dado que decidimos que todas las aplicaciones usarán Tarantool Cartridge, usamos cartucho-cli ( github ) para la construcción . Se trata de una pequeña utilidad para ejecutar (de hecho, desarrollar) aplicaciones Tarantool agrupadas en clúster localmente. También sabe cómo crear imágenes y archivos Docker con código de aplicación, tanto localmente como en Docker (por ejemplo, si necesita construir un artefacto para una arquitectura diferente). El montaje
tar.gz
se realiza mediante el comando:
cartridge pack tgz --name <nme> --version <vrsion>
El archivo resultante se carga luego en cualquier repositorio, por ejemplo, en Artifactory o Mail.ru Cloud Storage .
Implementar sin tiempo de inactividad
Y el paso final de la tubería es la implementación en sí. Dependiendo del estado de las ediciones, la transferencia se realiza en diferentes zonas de prueba. Se asigna una zona para cualquier estornudo: cada empuje al repositorio lanza la canalización completa. También hay varias áreas funcionales donde puede probar la interacción con sistemas externos, para esto necesita crear una solicitud de fusión en la rama maestra del repositorio. Pero en producción, el rodaje se inicia solo después de que se aceptan los cambios y se presiona el botón de combinación.
Permítame recordarle los elementos clave de nuestra implementación sin tiempo de inactividad:
- actualización para centros de datos;
- cambiar maestros en conjuntos de réplicas;
- configurar el equilibrador para un centro de datos activo.
Al actualizar, debe controlar la compatibilidad de las versiones y el esquema de datos. La actualización se detendrá si ocurre un error en cualquiera de los pasos.
La actualización se puede representar esquemáticamente de la siguiente manera:
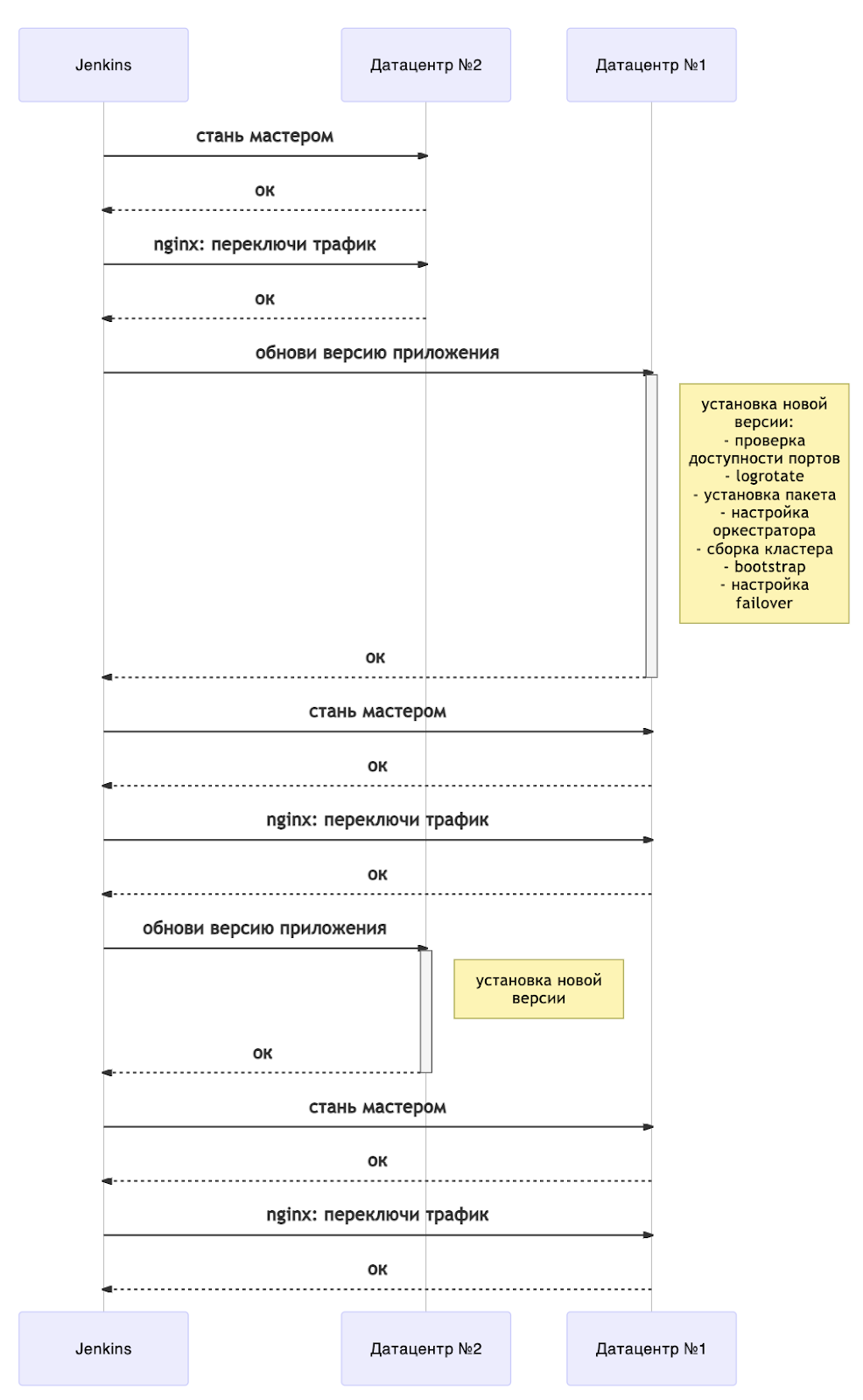
Ahora, cualquier actualización va acompañada de un reinicio del servidor. Para comprender cuándo puede continuar con la implementación, tenemos un libro de jugadas separado para esperar el estado de las instancias. Tarantool Cartridge tiene una máquina de estado y estamos esperando el estado RolesConfigured , lo que significa que la instancia está completamente configurada (y para nosotros, está lista para aceptar solicitudes). Si la aplicación se implementa por primera vez, debe esperar al estado Sin configurar .
En general, el diagrama muestra una descripción general de una implementación sin tiempo de inactividad. Es fácilmente escalable a más centros de datos. Dependiendo de sus necesidades, puede actualizar todos los "brazos" de respaldo inmediatamente después de cambiar los maestros (es decir, junto con el centro de datos # 1) o uno por uno.
Por supuesto, no pudimos evitar llevar nuestros desarrollos al código abierto. Hasta ahora, están disponibles en mi bifurcación de cartucho ansible ( opomuc / ansible-cartucho ), pero hay planes para mover esto a la rama maestra del repositorio principal.
Puede encontrar un ejemplo aquí ( ejemplo ). Para que funcione correctamente, el servidor debe estar configurado
supervisord
para el usuario
tarantool
. Los comandos de configuración se pueden encontrar aquí . El archivo con la aplicación también debe contener un binar
tarantool
.
La secuencia de comandos para iniciar el despliegue del hombro:
# ( )
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.0.0-0.tar.gz' \
--extra-vars 'app_version=1.0.0' \
--tags supervisor
# 1.2.0
# dc2
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc2
# — dc1
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc1
# dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
# — dc2
ansible-playbook -i hosts.yml playbook.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--extra-vars 'app_version=1.2.0' \
--tags supervisor \
--limit dc2
# , dc1
ansible-playbook -i hosts.yml master.yml \
-b --become-user tarantool \
--extra-vars 'base_dir=/data/tarantool' \
--extra-vars 'cartridge_package_path=./getting-started-app-1.2.0-0.tar.gz' \
--limit dc1
El parámetro
base_dir
indica la ruta al directorio "de inicio" del proyecto. Después de la implementación, se crearán subdirectorios:
<base_dir>/run
- para controlar sockets y archivos pid;<base_dir>/data
- para archivos .snap y .xlog, así como para la configuración de Tarantool Cartridge;<base_dir>/conf
- para configuraciones de aplicaciones e instancias específicas;<base_dir>/releases
- para control de versiones y código fuente;<base_dir>/instances
- para enlaces a la versión actual para cada instancia de la aplicación.
El parámetro
cartridge_package_path
habla por sí solo, pero hay una peculiaridad:
- si la ruta comienza con
http://
ohttps://
, entonces el artefacto se precargará desde la red (por ejemplo, desde el artefacto que aparece junto a él). - en otros casos, el archivo se busca localmente
El parámetro
app_version
se utilizará para el control de versiones en la carpeta
<base_dir>/releases
. El valor predeterminado es
latest
.
La etiqueta
supervisor
significa que se utilizará como orquestador
supervisord
.
Hay muchas opciones para iniciar una implementación, pero la más confiable es la antigua
Makefile
. El comando condicional
make deploy
se puede incluir en cualquier CI \ CD y todo funcionará exactamente igual.
Salir
¡Eso es todo! Ahora tenemos una canalización lista para usar en Jenkins, nos deshicimos de los intermediarios y la velocidad de entrega de los cambios se ha vuelto loca. El número de usuarios está creciendo, en el entorno de producción ya hay 500 instancias desplegadas utilizando exclusivamente nuestra solución. Tenemos espacio para crecer.
Y aunque el proceso de implementación en sí está lejos de ser ideal, proporciona una base sólida para un mayor desarrollo de los procesos de DevOps. Puede tomar nuestra implementación de manera segura para entregar rápidamente el sistema a producción y no tener miedo de realizar ediciones frecuentes.
Y también será una lección para nosotros que es imposible traer un monolito y esperar su uso generalizado: necesitamos una descomposición de los playbooks, la asignación de roles para cada etapa de la instalación, una forma flexible de presentar el inventario. Algún día nuestros desarrollos estarán incluidos en master, ¡y todo será aún mejor!
Enlaces
- Una guía paso a paso para ansible-cartucho:
- Puede leer sobre Tarantool Cartridge aquí .
- Acerca de la implementación en Kubernetes:
- Monitorización de Tarantool: logs, métricas y su procesamiento .
- Para obtener ayuda, comuníquese con el chat de Telegram .