23 veces
más correos electrónicos dirigidos que utilizan una red neuronal en comparación con un activador
8.5 veces
más ingresos del marketing por correo electrónico por atribución al último clic
2 veces
menos suscripciones
17 veces
más oportunidades
A continuación compartiremos nuestra experiencia y te contamos:
- por qué decidimos utilizar el modelo de red neuronal LSTM para predecir la fecha de envío del correo electrónico en lugar del algoritmo de aumento de gradiente;
- cómo funciona el LSTM;
- qué datos utiliza la red neuronal para el entrenamiento;
- qué arquitectura de la red neuronal se utilizó y qué dificultades encontraron;
- qué resultados se obtuvieron y cómo se evaluaron.
¿Por qué decidió abandonar el algoritmo de aumento de gradiente a favor de LSTM?
Los boletines informativos por correo electrónico ayudan a informar a los clientes sobre nuevos productos, reactivar a los clientes que se agitan o mostrar recomendaciones personalizadas. Para cada cliente, la fecha del mejor envío es diferente: alguien hace compras el fin de semana, por lo que es mejor enviar un correo el sábado; y alguien recientemente compró una casa para un gato, y vale la pena enviarle una carta lo antes posible y aconsejarle sobre la comida. Una red neuronal nos ayudó a determinar la mejor fecha para enviar un correo electrónico y adivinar la necesidad del cliente.
Al principio usamos algoritmos estándar. Durante todo un año, creamos letreros a partir del historial de acciones de los clientes y realizamos un gradiente capacitado para predecir la mejor fecha para enviar correos electrónicos. Por ejemplo:
- calculó cuántos días pasarán desde la fecha de compra hasta la próxima compra;
- intentó hacer una clasificación de signos y predecir la probabilidad de enviar una carta en un día determinado;
- trató de determinar los intereses del usuario en función del lugar de residencia con el fin de aumentar la probabilidad de ver la carta y los clics.
Pero este modelo no dio un resultado positivo estable para todos los proyectos, no pudo encontrar patrones complejos en el comportamiento de los usuarios y no aportó suficiente dinero.
Cuando ya estábamos pensando en abandonar el algoritmo y la idea de predecir la fecha de envío del correo electrónico, decidimos probar algo exótico y entrenar el modelo LSTM de la red neuronal para esta tarea. Por lo general, se usa para el análisis de texto, con menos frecuencia para analizar los precios de las acciones en los mercados financieros, pero nunca con fines de marketing. Y el LSTM funcionó.
Que es LSTM
LSTM (Long Short Term Memory) es una arquitectura de red neuronal que proviene del análisis del lenguaje natural.
Analicemos cómo funciona LSTM usando la traducción automática como ejemplo. Todas las letras del texto se alimentan a su vez a la entrada de la red neuronal, y en la salida queremos obtener una traducción a otro idioma. Para traducir texto, la red debe almacenar información no solo sobre la letra actual, sino también sobre las que estaban delante de ella. Una red neuronal ordinaria no recuerda lo que se mostró antes y no puede traducir una palabra o un texto completos. LSTM, por otro lado, tiene celdas de memoria especiales donde se almacena información útil, por lo tanto, produce un resultado en base a los datos totales y traduce el texto teniendo en cuenta todas las letras en palabras. Con el tiempo, la red neuronal puede borrar las células y olvidar información que ya no es necesaria.
El mismo principio resultó ser importante para predecir las acciones del usuario. La red neuronal tuvo en cuenta todo el historial de acciones y produjo resultados relevantes; por ejemplo, determinó la mejor fecha para enviar un correo electrónico.
Estructura interna de una capa LSTM

La capa interna del LSTM consta de las operaciones de suma + , multiplicación × , sigmoide σ y tangente hiperbólica tanh
Qué datos utiliza la red neuronal
Para aprender a predecir la mejor fecha de envío de correo electrónico, la red neuronal analiza un conjunto de datos históricos. Pasamos en la secuencia el tiempo transcurrido entre acciones y 9 tipos de tokens:
- comprando un producto barato,
- comprar un producto de precio medio,
- comprar un producto caro,
- ver un producto barato,
- ver un producto de precio medio,
- ver un producto caro,
- recibir una carta,
- abriendo una carta,
- haga clic en cualquier objeto dentro de la letra.
Así es como se ve un ejemplo típico de una secuencia de entrada:
(view_medium, 0.5, view_cheap, 24, buy_cheap) Un
usuario con esta secuencia miró un producto de precio promedio, miró un producto barato en media hora y decidió comprar un producto barato un día después.
Las últimas cinco acciones del usuario son la variable objetivo. Su red neuronal ha aprendido a predecir.
Qué arquitectura de la red neuronal se utilizó
Los primeros intentos de entrenar la red neuronal fueron infructuosos: se volvió a entrenar y siempre predijo solo el envío de una carta, y no otras acciones, por ejemplo, la probabilidad de abrir una carta o comprar. Dado que es más probable que los clientes reciban correos electrónicos que abrirlos o comprar algo, "recibir correo electrónico" es el token más frecuente. La red neuronal obtuvo buenos resultados en cuanto a métricas, aunque el resultado real fue negativo. Después de todo, no tiene sentido un algoritmo que siempre dice que el cliente recibirá una carta, y nada más.
Por ejemplo, hay una secuencia de entrada de tres fichas "recibir una carta" y una "compra de bienes". La red neuronal lo procesa y predice una secuencia con cuatro tokens de "recepción de correo". En 3 de cada 4 casos, adivinará, y el cliente recibirá una carta, pero tal predicción no tiene sentido. La tarea principal es predecir cuándo un cliente abrirá un correo electrónico y realizará una compra.
Después de probar varias arquitecturas y rutas de aprendizaje, encontramos lo que funcionó.
Como es habitual en los modelos Seq2Seq, la red consta de dos partes: un codificador y un decodificador. El codificador es pequeño y consta de LSTM y capas de incrustación, pero el decodificador también utiliza la atención propia y la deserción. En el entrenamiento, usamos la fuerza del maestro; a veces damos una predicción de red como entrada para la próxima predicción.
El codificador codifica la secuencia de entrada en un vector que contiene información importante, en opinión de la red, sobre las acciones del usuario. El decodificador, por el contrario, decodifica el vector resultante en una secuencia: esta es la predicción de la red.
Obtener una predicción usando una red LSTM

Tiempo de entrenamiento: el modelo se entrenó durante aproximadamente un día en Tesla V100 y al finalizar el entrenamiento recibió ROC-AUC 0,74.
Cómo funciona el modelo LSTM con datos reales (inferencia)
Para aplicar el modelo a algún usuario y averiguar si merece la pena enviarle una carta, recogeremos un vector de sus últimas acciones y lo ejecutaremos a través de la red neuronal. Supongamos que la respuesta de la red neuronal fuera así:
(email_show, 10, email_open, 0.5, view_cheap, 0.5 view_medium, 15 buy_medium)
El modelo predice no solo acciones, sino también cuánto tiempo pasará entre ellas. Cortemos todos los eventos que sucedan más tarde de un día después. Los procesaremos al día siguiente, pues durante este tiempo puede aparecer nueva información sobre las acciones del cliente, que será necesario tener en cuenta. Obtenemos la siguiente secuencia:
(email_show, 10, email_open, 0.5, view_cheap, 0.5 )
Hay un token de visualización en la secuencia, por lo que se enviará un correo electrónico al usuario hoy.
Es importante enviar un correo electrónico solo si hay un token de visualización o compra y no recibe un correo electrónico, para que la red no repita los correos de activación que recordaba anteriormente. Por ejemplo, si no tiene en cuenta la visualización y las compras, podemos obtener una secuencia solo con tokens para recibir una carta. Y luego, la red duplicará la configuración de activación del comercializador en lugar de predecir la apertura de un correo electrónico o una compra:
Cómo se evaluó el resultado
Para comprobar el rendimiento del modelo, realizamos pruebas AB. Como línea de base, utilizamos un algoritmo que calcula el tiempo promedio entre compras de un usuario y envía un correo electrónico cuando pasa este tiempo. La mitad de los usuarios recibió correos electrónicos basados en las decisiones de referencia, la otra, de acuerdo con las predicciones del modelo. Las pruebas AB se realizaron con la base de clientes de las tiendas de animales Beethoven y Staraya Farm .
La prueba duró dos semanas y alcanzó significación estadística. La red neuronal ha aprendido a encontrar 23 veces más usuarios que deberían enviar un correo electrónico, mientras que en términos porcentuales la tasa de apertura bajó solo un 5%, y el número de aperturas en números absolutos aumentó 17 veces.
Resultado de la prueba AB para el modelo de red neuronal LSTM y conclusiones
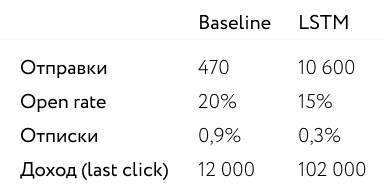
Entonces, el experimento con una red neuronal en lugar de un algoritmo resultó ser exitoso. El modelo de red neuronal LSTM se ha convertido en una herramienta adecuada para predecir la mejor fecha de envío de correo electrónico. Hemos aprendido de nuestra propia experiencia que no hay que tener miedo de utilizar modelos no estándar para resolver problemas triviales.
Sergey Yudin, desarrollador de ML, autor