
¡Hola, Habr! Más recientemente, escribimos sobre un conjunto de datos abiertos reunidos por un equipo de estudiantes graduados de Data Science de NUST MISIS y Zavtra.Online (departamento universitario de SkillFactory) como parte del primer Dataton educativo. Y hoy les presentaremos hasta 3 conjuntos de datos de equipos que también llegaron a la final.
Todos son diferentes: algunos han investigado el mercado de la música, algunos han investigado el mercado laboral de los especialistas en TI y algunos han estudiado a los gatos domésticos. Cada uno de estos proyectos es relevante en su propia área y se puede utilizar para mejorar algo en el curso habitual del trabajo. Un conjunto de datos con gatos, por ejemplo, ayudará a los jueces en las exposiciones. Los conjuntos de datos que los estudiantes tenían que recopilar tenían que ser MVP (estructura de tabla, json o directorio), los datos tenían que limpiarse y analizarse. Veamos qué hicieron.
Conjunto de datos 1: Deslízate sobre ondas musicales con Data Surfers
Póngase en fila:
- Plotnikov Kirill - director de proyectos, desarrollo, documentación.
- Dmitry Tarasov: desarrollo, recopilación de datos, documentación.
- Shadrin Yaroslav: desarrollo, recopilación de datos.
- Merzlikin Artyom - gerente de producto, presentación.
- Ksenia Kolesnichenko - análisis de datos preliminares.
Como parte de su participación en el hackathon, los miembros del equipo propusieron varias ideas interesantes diferentes, pero decidimos centrarnos en recopilar datos sobre artistas musicales rusos y sus mejores pistas de Spotify y MusicBrainz.
Spotify es una plataforma de música que llegó a Rusia no hace mucho tiempo, pero que ya está ganando popularidad activamente en el mercado. Además, en términos de análisis de datos, Spotify proporciona una API muy conveniente con la capacidad de consultar una gran cantidad de datos, incluidas sus propias métricas, como "capacidad de baile", una puntuación de 0 a 1 que describe qué tan buena es una pista. para bailar.
MusicBrainzEs una enciclopedia musical que contiene la información más completa sobre grupos musicales existentes y existentes. Una especie de "wikipedia musical". Necesitábamos datos de este recurso para obtener una lista de todos los artistas de Rusia.
Recopilar datos de artistas
Hemos compilado una tabla completa que contiene 14363 entradas únicas para varios artistas. Para que sea más cómodo navegar en él, hay una descripción de los campos de la tabla debajo del spoiler.
Descripción de los campos de la tabla
artist – ;
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .
musicbrainz_id – Musicbrainz;
spotify_id – Spotify, ;
type – , Person, Group, Other, Orchestra, Choir Character;
followers – Spotify;
genres – ;
popularity – Spotify 0 100, .

Ejemplo de Record
Fields artist, musicbrainz_id y type se recuperan de la base de datos de música Musicbrainz, ya que existe la oportunidad de obtener una lista de artistas asociados con un país. Hay dos formas de recuperar estos datos:
- Analice la sección Artistas en la página con información sobre Rusia.
- Obtenga datos a través de API.
Documentación de la API de MusicBrainz Ejemplo de búsqueda de
documentación de la API de MusicBrainz Solicitud GET en musicbrainz.org
En el curso del trabajo, resultó que la API de MusicBrainz no responde correctamente a una solicitud con el parámetro Área: Rusia, ocultándonos a aquellos artistas que tienen un Área especificada, por ejemplo, Izhevsk o Moskva. Por lo tanto, los datos de MusicBrainz fueron tomados por el analizador directamente del sitio. A continuación se muestra un ejemplo de la página desde donde se analizaron los datos.
Los datos obtenidos sobre los artistas de Musicbrainz.
El resto de los campos se obtienen como resultado de solicitudes GET al punto final . Al enviar una solicitud, especifique el nombre del artista en el valor del parámetro q, y especifique artista en el valor del parámetro de tipo.
Recopilar datos sobre pistas populares
La tabla contiene 44473 registros de las pistas más populares de artistas rusos, presentados en la tabla anterior. Debajo del spoiler hay una descripción de los campos de la tabla.
Descripción de los campos de la tabla
artist – ;
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
artist_spotify_id – Spotify ( , spotify_id );
name – ;
spotify_id – Spotify;
duration_ms – ;
explicit – , true false;
popularity – Spotify *;
album_type – , album, single compilation;
album_name – ;
album_spotify_id – Spotify;
release_date – ;
album_popularity – Spotify.
Funciones de audio
key – , , 0 = C, 1 = C♯/D♭, 2 = D ..;
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
mode – , – 1, – 0;
time_signature – ;
acousticness – 0,0 1,0 , ;
danceability – , 0,0 1,0;
energy – 0,0 1,0;
instrumentalness – , , 0,0 1.0;
liveness – , 0,0 1,0;
loudness – , -60 0 ;
speechiness – , 0,0 1,0;
valence – «», , 0,0 1,0;
tempo – .
Puede leer más sobre cada parámetro aquí .

Un ejemplo de un registro Los
campos nombre, spotify_id, duración_ms, explícito, popularidad, album_type, album_name, album_spotify_id, release_date se obtienen usando una solicitud GET para
https://api.spotify.com/v1//v1/artists/{id}/top-tracks
, especificando la identificación de Spotify del artista que recibimos anteriormente, y en el valor del parámetro de mercado especificamos RU. Documentación .
El campo album_popularity se puede obtener haciendo una solicitud GET
https://api.spotify.com/v1/albums/{id}
, especificando el album_spotify_id obtenido anteriormente como valor para el parámetro id. Documentación .
Como resultado, obtenemos los datossobre las mejores pistas de los artistas de Spotify. Ahora el desafío es conseguir las funciones de audio. Esto se puede hacer de dos formas:
- Para obtener datos sobre una pista, debe realizar una solicitud GET
https://api.spotify.com/v1/audio-features/{id}
, especificando su ID de Spotify como el valor del parámetro id. Documentación .
- Para obtener datos sobre varias pistas a la vez, debe enviar una solicitud GET a
https://api.spotify.com/v1/audio-features
, pasando el ID de Spotify de estas pistas separadas por comas como el valor del parámetro ids. Documentación .
Todos los scripts están en el repositorio en este enlace .
Luego de recolectar los datos, realizamos un análisis preliminar, que se visualiza a continuación.
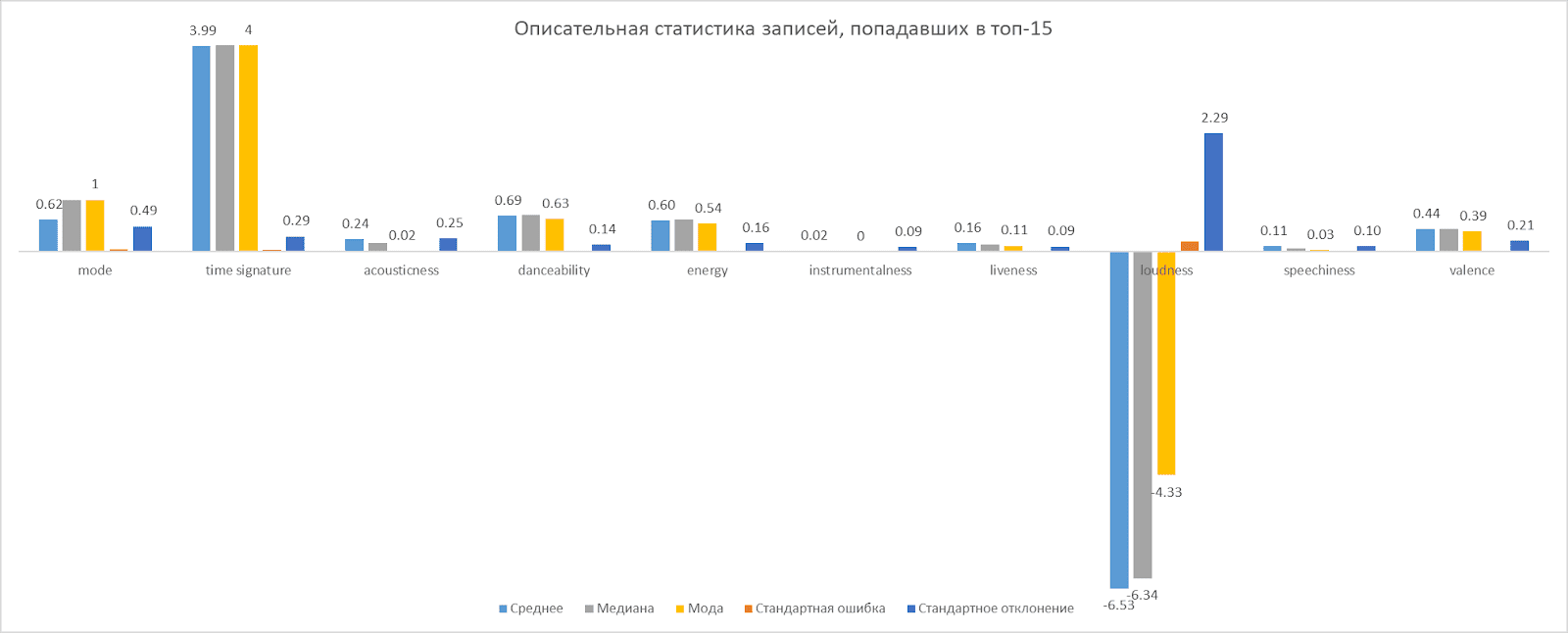
Salir
Como resultado, logramos recopilar datos sobre 14363 artistas y 44473 pistas. Al combinar datos de MusicBrainz y Spotify, hemos obtenido el conjunto de datos más completo hasta la fecha de todos los artistas musicales rusos representados en la plataforma Spotify.
Dicho conjunto de datos permitirá crear productos B2B y B2C en el campo de la música. Por ejemplo, sistemas para recomendar a los artistas intérpretes o ejecutantes a los promotores cuyos conciertos se pueden organizar o sistemas para ayudar a los artistas jóvenes a escribir temas que tienen más probabilidades de volverse populares. Además, con la reposición regular del conjunto de datos con datos nuevos, puede analizar varias tendencias en la industria de la música, como la formación y el crecimiento de la popularidad de ciertas tendencias en la música, o analizar artistas individuales. El conjunto de datos en sí se puede ver en GitHub .
Conjunto de datos 2: investigamos el mercado laboral e identificamos habilidades clave con "Hedgehog is clear"
Póngase en fila:
- Andrey Pshenichny: recopila y procesa datos, escribe una nota analítica en el conjunto de datos.
- Pavel Kondratenok - Product Manager, recopilación de datos y descripción de su proceso, GitHub.
- Svetlana Shcherbakova: recopilación y procesamiento de datos.
- Evseeva Oksana - preparación de la presentación final del proyecto.
- Elfimova Anna - Directora de proyectos.
Para nuestro conjunto de datos, elegimos la idea de recopilar datos sobre vacantes en Rusia de la esfera de TI y telecomunicaciones del sitio hh.ru para octubre de 2020.
Recopilación de datos de habilidades
La métrica más importante para todas las categorías de usuarios son las habilidades clave. Sin embargo, al analizarlos, encontramos dificultades: al completar los datos de vacantes, los RR.HH. seleccionan habilidades clave de la lista y también pueden ingresarlas manualmente y, por lo tanto, una gran cantidad de habilidades duplicadas y habilidades incorrectas ingresaron en nuestro conjunto de datos (por ejemplo , encontramos el nombre de la habilidad clave "0.4 Kb"). Existe una dificultad más que causó problemas al analizar el conjunto de datos resultante: solo aproximadamente la mitad de las vacantes contienen datos sobre salarios, pero podemos usar indicadores de salario promedio de otro recurso (por ejemplo, de los recursos My Circle o Habr.Career).
Comenzamos con la adquisición de datos y el análisis en profundidad. A continuación, muestreamos los datos, es decir, seleccionamos características (características o, en otras palabras, predictores) y objetos, teniendo en cuenta su relevancia para fines de Data Mining, restricciones de calidad y técnicas (volumen y tipo).
Aquí nos ayudó el análisis de la frecuencia de mención de habilidades en las etiquetas de habilidades requeridas en la descripción del puesto, qué características de la vacante afectan la recompensa propuesta. Al mismo tiempo, se identificaron 8915 habilidades clave. A continuación se muestra un cuadro que muestra las 10 habilidades clave principales y la frecuencia con la que se mencionan.
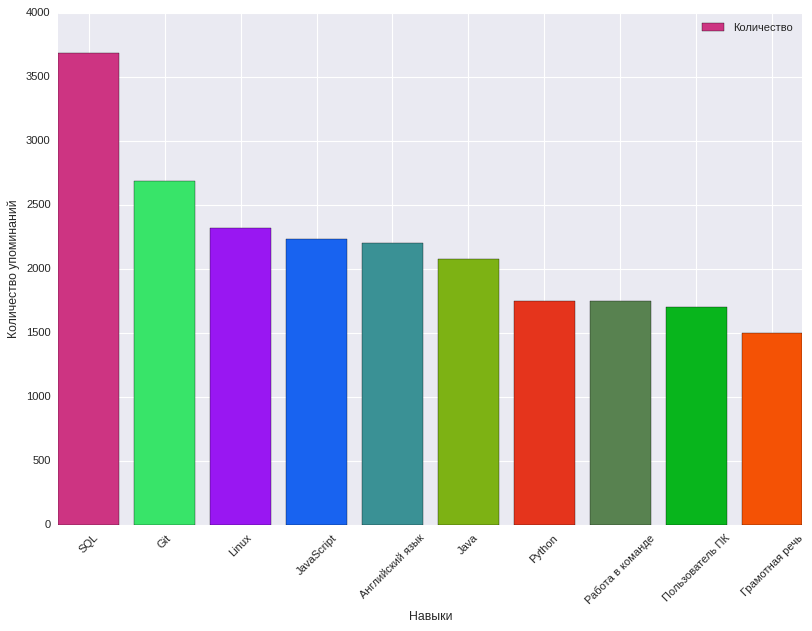
Las habilidades clave más comunes en las vacantes de TI, Telecom
Data, se obtuvieron del sitio web hh.ru utilizando su API. El código para cargar datos se puede encontrar aquí . Hemos seleccionado manualmente las características que necesitamos para el conjunto de datos. La estructura y el tipo de datos recopilados se pueden ver en la descripción de la documentación del conjunto de datos.
Después de estas manipulaciones, obtuvimos un conjunto de datos con un tamaño de 34,513 líneas. Puede ver una muestra de los datos recopilados a continuación y también encontrar el enlace .

Datos de muestra recopilados
Salir
El resultado es un conjunto de datos con el que puede averiguar qué habilidades son más demandadas entre los especialistas en TI en diferentes áreas, y puede ser útil para quienes buscan empleo (tanto principiantes como experimentados), empleadores, especialistas en recursos humanos, organizaciones educativas y organizadores. de conferencias. En el proceso de recolección de datos también hubo dificultades: hay demasiados letreros y están escritos en un lenguaje poco formalizado (descripción de habilidades para el candidato), la mitad de las vacantes no tienen datos abiertos sobre salarios. El conjunto de datos en sí se puede ver en GitHub .
Conjunto de datos 3: disfruta de la variedad de gatos con Team AA
Póngase en fila:
- Evgeny Ivanov - desarrollo de web scraping.
- Sergey Gurylev: gerente de producto, descripción del proceso de desarrollo, GitHub.
- Yulia Cherganova - preparación de la presentación del proyecto, análisis de datos.
- Elena Tereshchenko - preparación de datos, análisis de datos.
- Yuri Kotelenko - director de proyectos, documentación, presentación de proyectos.
¿Un conjunto de datos dedicado a los gatos? Por qué no, pensamos. Nuestro catset contiene imágenes de muestra de gatos de varias razas.
Recopilar datos de gatos
Inicialmente, elegimos catfishes.ru para recopilar datos , tiene todas las ventajas que necesitamos: es una fuente gratuita con una estructura HTML simple e imágenes de alta calidad. A pesar de las ventajas de este sitio, tenía un inconveniente importante: una pequeña cantidad de fotos en general (alrededor de 500 para todas las razas) y una pequeña cantidad de imágenes de cada raza. Por lo tanto, elegimos otro sitio: lapkins.ru .

Debido a la estructura HTML ligeramente más compleja, raspar el segundo sitio fue un poco más difícil que el primero, pero la estructura HTML fue fácil de entender. Como resultado, logramos recopilar ya 2600 fotos de todas las razas del segundo sitio.
Ni siquiera necesitamos filtrar los datos, ya que las fotos de los gatos en el sitio son de buena calidad y corresponden a las razas.
Para recopilar imágenes del sitio, escribimos un raspador web. El sitio contiene una página lapkins.ru/cat con una lista de todas las razas. Después de analizar esta página, obtuvimos los nombres de todas las razas y enlaces a la página de cada raza. Después de recorrer iterativamente cada una de las rocas, obtuvimos todas las imágenes y las colocamos en las carpetas correspondientes. El código scraper se implementó en Python utilizando las siguientes bibliotecas:
- urllib : funciones para trabajar con URL;
- html : funciones para procesar XML y HTML;
- Shutil : funciones de alto nivel para manejar archivos, grupos de archivos y carpetas;
- SO : funciones para trabajar con el sistema operativo.
Usamos XPath para trabajar con etiquetas.
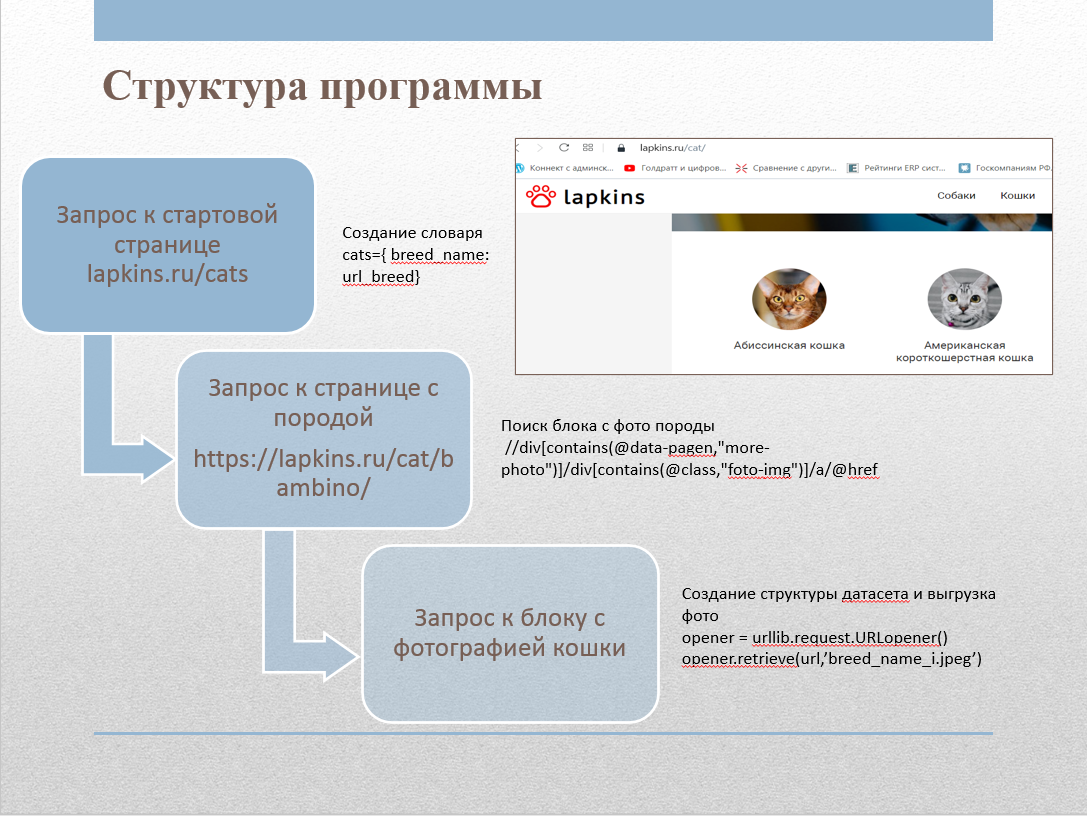
El directorio Cats_lapkins contiene carpetas cuyos nombres corresponden a los nombres de las razas de gatos. El repositorio contiene 64 directorios para cada raza. En total, el conjunto de datos contiene 2600 imágenes. Todas las imágenes están en formato .jpg. Formato de nombre de archivo: por ejemplo, "gato abisinio 2.jpg", primero aparece el nombre de la raza, luego el número, el número de serie de la muestra.

Salir
Este conjunto de datos se puede utilizar, por ejemplo, para entrenar modelos que clasifiquen a los gatos domésticos por raza. Los datos recopilados se pueden utilizar para los siguientes fines: determinar las características del cuidado de un gato, seleccionar una dieta adecuada para gatos de determinadas razas, así como optimizar la identificación primaria de la raza en las ferias y al juzgar. Cotoset también puede ser utilizado por empresas: clínicas veterinarias y fabricantes de piensos. El cotconjunto en sí está disponible gratuitamente en GitHub .
Epílogo
Según los resultados del dataton, nuestros estudiantes recibieron el primer caso en su cartera de científicos de datos y comentarios sobre el trabajo de mentores de empresas como Huawei, Kaspersky Lab, Align Technology, Auriga, Intellivision, Wrike, Merlin AI. Dataton también fue útil porque inmediatamente aumentó el perfil de las habilidades duras y blandas que los futuros científicos de datos necesitarán cuando ya trabajarán en equipos reales. También es una buena oportunidad para el "intercambio de conocimientos" mutuo, ya que cada alumno tiene una formación diferente y, en consecuencia, su propia visión del problema y su posible solución. Podemos decir con confianza que sin ese trabajo práctico, similar a algunas tareas comerciales ya existentes, la formación de especialistas en el mundo moderno es simplemente impensable.
Puede obtener más información sobre nuestro programa de maestría en el sitio web data.misis.ru y en el canal de Telegram .
Bueno, y, por supuesto, ¡ni una sola maestría! Si desea obtener más información sobre ciencia de datos , aprendizaje automático y aprendizaje profundo , eche un vistazo a nuestros cursos correspondientes, será difícil, pero emocionante. Y el código de promoción HABR lo ayudará a aprender cosas nuevas al agregar un 10% al descuento en el banner.

Otras profesiones y cursos