
Ya hay bastantes publicaciones sobre el coprocesador Apple Matrix (AMX). Pero la mayoría no son muy claros para todos. Intentaré explicar los matices del coprocesador en un lenguaje comprensible.
¿Por qué Apple no habla demasiado de este coprocesador? ¿Qué tiene de secreto? Y si ha leído sobre el motor neuronal en SoC M1, es posible que le resulte difícil comprender qué es tan inusual en AMX.
Pero primero, recordemos las cosas básicas ( si sabes bien qué son las matrices, y estoy seguro de que hay la mayoría de estos lectores en Habré, entonces puedes saltarte la primera sección, aprox. Transl. ).
¿Qué es una matriz?
En pocas palabras, esta es una tabla con números. Si ha trabajado en Microsoft Excel, significa que se ha ocupado de la similitud de matrices. La diferencia clave entre matrices y tablas ordinarias con números está en las operaciones que se pueden realizar con ellas, así como en su esencia específica. Se puede pensar en la matriz de muchas formas diferentes. Por ejemplo, como cadenas, entonces es un vector de fila. O como columna, entonces, lógicamente, es un vector de columna.

Podemos sumar, restar, escalar y multiplicar matrices. La suma es la operación más simple. Simplemente agregue cada elemento por separado. La multiplicación es un poco más complicada. He aquí un ejemplo sencillo.
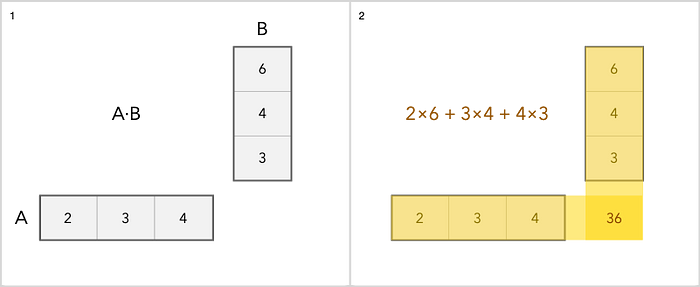
En cuanto a otras operaciones con matrices, puede leerlo aquí .
¿Por qué estamos hablando de matrices?
El caso es que se utilizan mucho en:
• Procesado de imágenes.
• Aprendizaje automático.
• Escritura a mano y reconocimiento de voz.
• Compresión.
• Trabajar con audio y video.
Cuando se trata de aprendizaje automático, esta tecnología requiere procesadores potentes. Y simplemente agregar algunos núcleos al chip no es una opción. Ahora los núcleos están "afilados" para determinadas tareas.

La cantidad de transistores en el procesador es limitada, por lo que la cantidad de tareas / módulos que se pueden agregar al chip también es limitada. En general, podría simplemente agregar más núcleos al procesador, pero eso solo acelerará los cálculos estándar que ya son rápidos. Así que Apple decidió tomar una ruta diferente y resaltar módulos para tareas de procesamiento de imágenes, decodificación de video y aprendizaje automático. Estos módulos son coprocesadores y aceleradores.
¿Cuál es la diferencia entre el coprocesador Apple Matrix y el motor neuronal?
Si estaba interesado en Neural Engine, probablemente sepa que también realiza operaciones matriciales para trabajar con problemas de aprendizaje automático. Pero si es así, ¿por qué también necesita el coprocesador Matrix? ¿Quizás es lo mismo? ¿Estoy confundiendo algo? Permítanme aclarar la situación y decirles cuál es la diferencia, explicando por qué se necesitan ambas tecnologías.
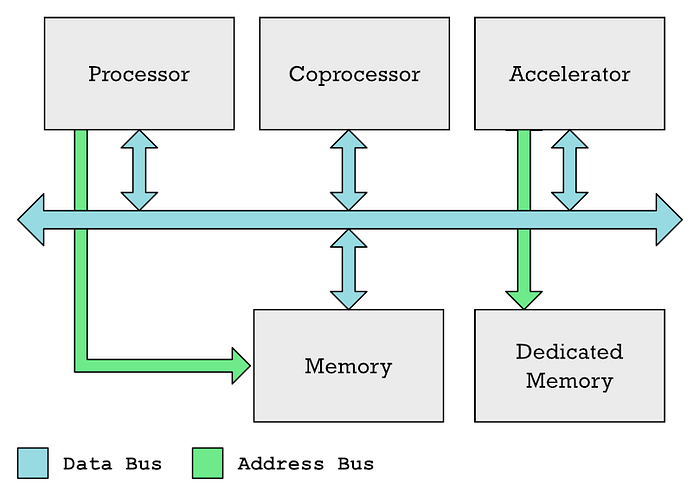
La unidad de procesamiento principal (CPU), los coprocesadores y los aceleradores generalmente pueden comunicarse a través de un bus de datos común. La CPU generalmente controla el acceso a la memoria, mientras que un acelerador como una GPU a menudo tiene su propia memoria dedicada.
Admito que en mis artículos anteriores he usado los términos "coprocesador" y "aceleradores" indistintamente, aunque no son lo mismo. Entonces, GPU y Neural Engine son diferentes tipos de aceleradores.
En ambos casos, tienes áreas especiales de memoria que la CPU debe llenar con los datos que quiere procesar, más otra área de memoria que la CPU llena con una lista de instrucciones que el acelerador debe ejecutar. El procesador necesita tiempo para completar estas tareas. Tienes que coordinar todo esto, completar los datos y luego esperar a que se reciban los resultados.
Y tal mecanismo es adecuado para tareas a gran escala, pero para tareas pequeñas es excesivo.

Ésta es la ventaja de los coprocesadores sobre los aceleradores. Los coprocesadores se sientan y observan el flujo de instrucciones de código de máquina que vienen de la memoria (o en particular de la caché) a la CPU. El coprocesador se ve obligado a responder a las instrucciones específicas que se vieron obligados a procesar. Mientras tanto, la CPU ignora en su mayoría estas instrucciones o ayuda a que el coprocesador las maneje más fácilmente.
La ventaja es que las instrucciones ejecutadas por el coprocesador pueden incluirse en código regular. En el caso de la GPU, todo es diferente: los programas de sombreado se colocan en búferes de memoria separados, que luego deben transferirse explícitamente a la GPU. No podrá utilizar código normal para esto. Y es por eso que AMX es ideal para tareas simples de procesamiento de matrices.
El truco aquí es que necesita definir instrucciones en la arquitectura del conjunto de instrucciones (ISA) de su microprocesador. Por lo tanto, cuando se usa un coprocesador, hay una integración más estrecha con el procesador que cuando se usa un acelerador.
Los creadores de ARM, por cierto, se han resistido durante mucho tiempo a agregar instrucciones personalizadas a ISA. Y esta es una de las ventajas de RISC-V. Pero en 2019, los desarrolladores se rindieron, sin embargo, declarando lo siguiente: “Las nuevas instrucciones se combinan con las instrucciones ARM estándar. Para evitar la fragmentación del software y mantener un entorno de desarrollo de software coherente, ARM espera que los clientes utilicen instrucciones personalizadas principalmente en las llamadas a la biblioteca ".
Esta podría ser una buena explicación para la falta de descripción de las instrucciones AMX en la documentación oficial. ARM simplemente espera que Apple incluya instrucciones en las bibliotecas proporcionadas por el cliente (en este caso Apple).
¿Cuál es la diferencia entre un coprocesador matricial y un SIMD vectorial?
En general, no es tan difícil confundir un coprocesador matricial con la tecnología vector SIMD, que se encuentra en la mayoría de los procesadores modernos, incluido ARM. SIMD son las siglas de Single Instruction Multiple Data.

SIMD le permite aumentar el rendimiento del sistema cuando necesita realizar la misma operación en varios elementos, lo cual está estrechamente relacionado con las matrices. En general, las instrucciones SIMD, incluidas las instrucciones ARM Neon o Intel x86 SSE o AVX, se utilizan a menudo para acelerar la multiplicación de matrices.
Pero el motor vectorial SIMD es parte del núcleo del microprocesador, al igual que ALU (Unidad Aritmética Lógica) y FPU (Unidad de Punto Flotante) son parte de la CPU. Bueno, ya el decodificador de instrucciones en el microprocesador "decide" qué bloque funcional activar.

Pero el coprocesador es un módulo físico separado y no forma parte del núcleo del microprocesador. Anteriormente, por ejemplo, el 8087 de Intel era un chip separado que estaba destinado a acelerar las operaciones de punto flotante.

Puede resultarle extraño que alguien desarrolle un sistema tan complejo, con un chip separado que procesa los datos que van de la memoria al procesador para detectar una instrucción de punto flotante.
Pero el cofre se abre simplemente. El hecho es que el procesador 8086 original tenía solo 29.000 transistores. El 8087 ya tenía 45 000. Al final, las tecnologías permitieron integrar FPU en el chip principal, deshaciéndose de los coprocesadores.
Pero no está del todo claro por qué AMX no es parte del núcleo M1 Firestorm. Quizás Apple simplemente decidió mover elementos ARM no estándar fuera del procesador principal.
Pero, ¿por qué no se habla mucho de AMX?
Si AMX no está descrito en la documentación oficial, ¿cómo podríamos saberlo? Gracias al desarrollador Dougall Johnson, quien hizo una maravillosa ingeniería inversa del M1 y descubrió el coprocesador. Su trabajo se describe aquí . Al final resultó que, Apple creó bibliotecas especializadas y / o marcos como Accelerate para operaciones matemáticas relacionadas con matrices . Todo esto incluye los siguientes elementos:
• vImage : procesamiento de imágenes de mayor nivel, como convertir entre formatos, manipular imágenes.
• BLASEs una especie de estándar industrial para el álgebra lineal (lo que llamamos matemáticas que tratan con matrices y vectores).
• BNNS : se utiliza para ejecutar redes neuronales y entrenar.
• vDSP : procesamiento de señales digitales. Transformadas de Fourier, convolución. Estas son operaciones matemáticas que se realizan al procesar una imagen o cualquier señal que contenga sonido.
• LAPACK : funciones de álgebra lineal de nivel superior , como la resolución de ecuaciones lineales.
Johnson entendió que estas bibliotecas utilizarían el coprocesador AMX para acelerar los cálculos. Por ello, desarrolló un software especializado para el análisis y seguimiento de las acciones de la biblioteca. Finalmente, pudo localizar instrucciones de código de máquina AMX indocumentadas.
Y Apple no documenta todo esto porque ARM LTD. intenta no publicitar demasiada información. El hecho es que si las funciones personalizadas se utilizan mucho, esto puede conducir a la fragmentación del ecosistema ARM, como se discutió anteriormente.
Apple tiene la oportunidad, sin realmente anunciar todo esto, de cambiar el funcionamiento de los sistemas si es necesario, por ejemplo, eliminar o agregar instrucciones AMX. Para los desarrolladores, la plataforma Accelerate es suficiente, el sistema hará el resto por sí mismo. En consecuencia, Apple puede controlar tanto el hardware como el software.
Beneficios del coprocesador Apple Matrix
Hay mucho aquí, Nod Labs, que se especializa en aprendizaje automático, inteligencia y percepción, realizó una excelente descripción general de las capacidades del elemento. En particular, realizaron pruebas de rendimiento comparativas entre AMX2 y NEON.
Al final resultó que, AMX realiza las operaciones necesarias para realizar operaciones con matrices dos veces más rápido. Esto no significa, por supuesto, que AMX sea el mejor, pero sí para el aprendizaje automático y la informática de alto rendimiento.
La conclusión es que el coprocesador de Apple es una tecnología impresionante que le da a Apple ARM una ventaja en aprendizaje automático y computación de alto rendimiento.
