Red neuronal profunda de alto rendimiento para datos tabulares TabNet
Introducción
Las redes neuronales profundas (GNN) se han convertido en una de las herramientas más atractivas para la creación de sistemas de inteligencia artificial (SRI), por ejemplo, reconocimiento de voz, comunicación natural, visión por computadora [2-3], etc. En particular, debido a la selección automática de GNS características importantes, definitorias, conexiones de datos. Se están desarrollando arquitecturas de redes neuronales (neocognitrónicas, convolucionales, de confianza profunda, etc.), modelos y algoritmos para el aprendizaje de GNS (autoencoders, máquinas de Boltzmann, recurrentes controlados, etc.). Los GNS son difíciles de entrenar, principalmente debido a los problemas de gradiente que desaparecen.
El artículo analiza la nueva arquitectura canónica de GNS para datos tabulares (TabNet), diseñada para mostrar un "árbol de decisiones". El objetivo es heredar las ventajas de los métodos jerárquicos (interpretabilidad, selección de características dispersas) y los métodos basados en GNS (aprendizaje paso a paso y de principio a fin). Específicamente, TabNet aborda dos necesidades clave: alto rendimiento e interpretabilidad. El alto rendimiento a menudo no es suficiente: GNS debe interpretar y reemplazar los métodos en forma de árbol.
TabNet es una red neuronal de capas completamente conectadas con un mecanismo de atención secuencial que:
utiliza una escasa selección de objetos por instancias, obtenidos del conjunto de datos de entrenamiento;
crea una arquitectura secuencial de varias etapas en la que cada paso de decisión puede contribuir a la parte de la decisión que se basa en las funciones seleccionadas;
mejora la capacidad de aprendizaje a través de transformaciones no lineales de funciones seleccionadas;
simula un conjunto, lo que implica mediciones más precisas y más pasos de mejora.
Cada capa de una arquitectura dada (Fig. 1) es un paso de solución que contiene un bloque con capas completamente conectadas para transformar características: un transformador de características y un mecanismo de atención para determinar la importancia de las características originales de entrada.

1. Convertidor de funciones
1.1. Normalización por lotes
- . . , (, ), , . (covariate shift).
. , — . ( ) , . , , , .
. , — , . , , ( , – ) . . - (batch normalization), 2015 [4].
- .
1. d: x = (x1, . . . , xd). k- x ( ):

2. . , . , , (

[−1, 1] ).
, :

γ, β .
3. , , -,


4. .
-:
, , ;
, ;
, ;
.
1.2. GLU
[5] Gated Linear Unit, , , LSTM-.
GLU
, , , . H = [h0 ,..., hN] w0, ... ,wN, P (wi |hi). f H hi = f(hi - 1 , wi - 1) , i ( , ).
f H = f * w , , , , , . . , , [5] , , .
. 2 . , D |V| x e, |V| - ( ), e - . w0, … , wN, E = [Dw0, … , DwN]. h0 , …hL

m, n – , , k - , X ∈ R N×m - hl ( , ),
, σ - ⊗ .
, hi . , . , k-1, , - , , k - .

X * W + b, σ(X * V + c). LSTM, X * W + b , . (GLU). E H = hL◦. . .◦h0 (E).
(GLU) , .
3.3 LSTM
LSTM (long short-term memory, – ) — , . LSTM , , [5].
LSTM . — , !
. , , tanh.
LSTM
LSTM .
LSTM , . , « ». h x 0 1 C. 1 « », 0 — « ».
. , . , . , .
, . . , « », , . tanh - C, . .
, .
C. , .
f, , . i*C. , , .
, .
, , . . , , . tanh ( [-1, 1]) .
, , , . , , ( ) .
TabNet

3.4. Split:
Feature Transformer , . , , Attentive Transformer , . (backpropagation) , «» , ( ). , . , Attentive Transformer . , "" , , .
SPLIT
: (. . 1) .
, , ( ), , .
. 3 . FC BN (GLU) , . √0.5 , , . . BN, , , BN BV mB. , , BN. , , . 3,
:
. softmax ( argmax ).
4.
. (), ( ) Softmax, , , : , - , — .
, , ht, t=1 …m, d , .
C d di−1 .
s — hi « ».
, s softmax. e=softmax(s)
softmax :
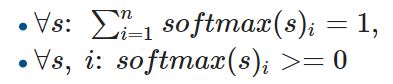
:

cc , hi ei.
. , , , , , . Softmax, Sparsemax. , , - , Softmax , . «» «» , - .
5. SPARSEMAX
, z z, . :

τ(z) S(z), p. softmax , , , softmax .
, . softmax , sparsemax :
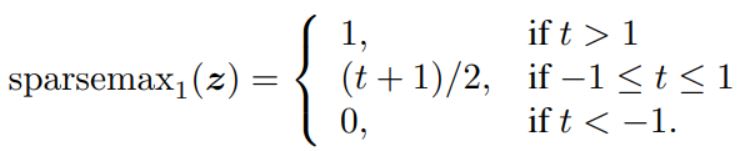
, :

, sparsemax , , :

|S(z)| - S(z).
, , , , Sparsemax.
,
6.
, , , , - . . , , . ( ), () , , , .
:
. , , , , . : M[i] · f. (. . 1) , , a[i − 1]:
Sparsemax [6] , .
,
h[i] - , . 4., FC, BN, P[i] - , , :

γ - : γ = 1, γ, . P[0] ,
- . ( ), P[0] , . :
ϵ - . λ, , .
, , . , , , - . , [5] , .
TabNet - . TabNet . , () , .
, , , .
.. // . : . 2017. .6, №3. .28–59. DOI: 10.14529/cmse170303
LeCun Y., Bengio Y., Hinton G. Deep Learning // Nature. 2015. Vol.521. Pp.436–444. DOI: 10.1038/nature14539.
Rav`ı D., Wong Ch., Deligianni F., et al. Deep Learning for Health Informatics // IEEE Journal of Biomedical and Health Informatics. 2017. Vol.21, No.1. PP.4–21. DOI: 10.1109/JBHI.2016.2636665.
Sergey Ioffe, Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal // Proceedings of The 32nd International Conference on Machine Learning (2015), pp.448-456.
Sercan O. Arik, Tomas Pfister. TabNet: Attentive Interpretable Tabular Learning // ICLR 2020 Conference Blind Submission 25 Sept 2019 (modified: 24 Dec 2019). URL:https://drive.google.com/file/d/1oLQRgKygAEVRRmqCZTPwno7gyTq22wbb/view?usp=sharing
Andre F. T. Martins and Ram´on Fern´andez Astudillo. 2016. From Softmax´ to Sparsemax: A Sparse Model of Attention and Multi-Label Classification. arXiv:1602.02068.