
Los problemas que resuelve el aprendizaje automático en la actualidad suelen ser complejos e incluyen una gran cantidad de funciones (funciones). Debido a la complejidad y diversidad de los datos iniciales, el uso de modelos simples de aprendizaje automático muchas veces no permite lograr los resultados necesarios, por lo que se utilizan modelos complejos y no lineales en casos de negocios reales. Tales modelos tienen un inconveniente importante: debido a su complejidad, es casi imposible ver la lógica por la cual el modelo asignó esta clase particular a la operación de la cuenta. La interpretabilidad del modelo es especialmente importante cuando los resultados de su trabajo deben presentarse al cliente; lo más probable es que él quiera saber sobre la base de qué criterios se toman decisiones para su negocio.
, sklearn, xgboost, lightGBM (). , . , , ? ? , . SHAP. SHAP . , .
. , . 213 , .
kaggle .
:
%%time
# LOAD TRAIN
X_train=pd.read_csv('train_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols+['isFraud'])
train_id= pd.read_csv('train_identity.csv',index_col='TransactionID', dtype=dtypes)
X_train = X_train.merge(train_id, how='left', left_index=True, right_index=True)
# LOAD TEST
X_test=pd.read_csv('test_transaction.csv',index_col='TransactionID', dtype=dtypes, usecols=cols)
test_id = pd.read_csv('test_identity.csv',index_col='TransactionID', dtype=dtypes)
fix = {o:n for o, n in zip(test_id.columns, train_id.columns)}
test_id.rename(columns=fix, inplace=True)
X_test = X_test.merge(test_id, how='left', left_index=True, right_index=True)
# TARGET
y_train = X_train['isFraud'].copy()
del train_id, test_id, X_train['isFraud']; x = gc.collect()
# PRINT STATUS
print('Train shape',X_train.shape,'test shape',X_test.shape)
X_train.head()

, , , , .
, () , , . , , , .
.
:
if BUILD95:
feature_imp=pd.DataFrame(sorted(zip(clf.feature_importances_,cols)), columns=['Value','Feature'])
plt.figure(figsize=(20, 10))
sns.barplot(x="Value", y="Feature", data=feature_imp.sort_values(by="Value", ascending=False).iloc[:50])
plt.title('XGB95 Most Important Features')
plt.tight_layout()
plt.show()
del clf, h; x=gc.collect()

, , . : ? . , , . , , SHAP. , , : 20 . 50 .
:
import shap
shap.initjs()
shap_test = shap.TreeExplainer(h).shap_values(X_train.loc[idxT,cols])
shap.summary_plot(shap_test, X_train.loc[idxT,cols],
max_display=25, auto_size_plot=True)
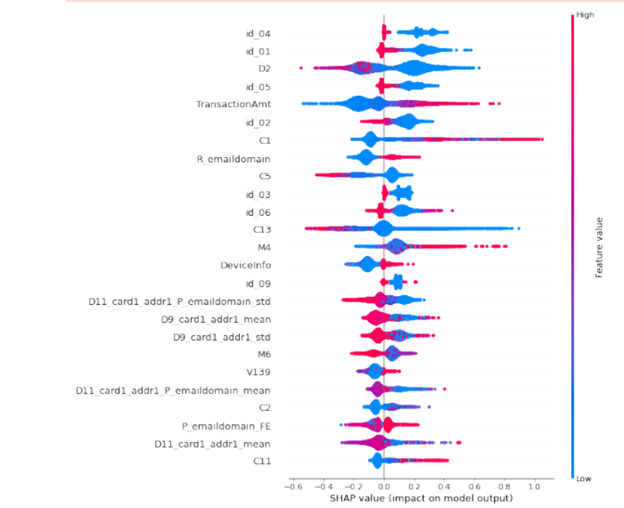
, . 2 . «0», «1». , . , . , , , : , , . , email.
A partir de los datos obtenidos, es posible aligerar el modelo, es decir, dejar solo los parámetros que tienen un impacto significativo en los resultados de predicción de nuestro modelo. Además, es posible evaluar la importancia de las características para ciertos subgrupos de datos, por ejemplo, clientes de diferentes regiones, transacciones en diferentes momentos del día, etc. Además, esta herramienta se puede utilizar para analizar casos individuales, por ejemplo, para analizar "valores atípicos" y valores extremos. SHAP también puede ayudar a encontrar zonas de caída al clasificar fenómenos negativos. Esta herramienta, en combinación con otros enfoques, hará que los modelos sean más ligeros, de mejor calidad y los resultados sean interpretables.