
¿Cómo actualizo el valor del atributo para todos los registros en una tabla? ¿Cómo agrego una clave principal o única a una tabla? ¿Cómo divido una mesa en dos? Cómo ...
Si es posible que la aplicación no esté disponible durante algún tiempo para las migraciones, las respuestas a estas preguntas no son difíciles. Pero, ¿qué sucede si necesita migrar en caliente, sin detener la base de datos y sin molestar a otros para que trabajen con ella?
Intentaremos responder a estas y otras preguntas que surgen durante las migraciones de esquemas y datos en PostgreSQL en forma de consejos prácticos.
Este artículo: rendimiento de decodificación en la conferencia SmartDataConf ( aquí puede encontrar la presentación, el video aparecerá a su debido tiempo). Había mucho texto, por lo que el material se dividirá en 2 artículos:
- migraciones basicas
- enfoques para actualizar tablas grandes.
Al final hay un resumen de todo el artículo en forma de una hoja de trucos de tabla dinámica.
Contenido
El meollo del problema
Agregar una columna
Agregar una
columna predeterminada Eliminar una columna
Crear un índice
Crear un índice en una tabla particionada
Crear una restricción NOT NULL
Crear una clave externa
Crear una restricción única
Crear una clave primaria Hoja de referencia de
migración rápida
La esencia del problema
Supongamos que tenemos una aplicación que funciona con una base de datos. En la configuración mínima, puede constar de 2 nodos: la propia aplicación y la base de datos, respectivamente.

Con este esquema, las actualizaciones de aplicaciones a menudo ocurren con tiempo de inactividad. Al mismo tiempo, puede actualizar la base de datos. En tal situación, el criterio principal es el tiempo, es decir, debe completar la migración lo más rápido posible para minimizar el tiempo de indisponibilidad del servicio.
Si la aplicación crece y se hace necesario realizar lanzamientos sin tiempo de inactividad, comenzamos a utilizar múltiples servidores de aplicaciones. Puede haber tantos como desee y estarán en diferentes versiones. En este caso, es necesario garantizar la compatibilidad con versiones anteriores.

En la siguiente etapa de crecimiento, los datos dejan de caber en una base de datos. También comenzamos a escalar la base de datos, mediante la fragmentación. Dado que en la práctica es muy difícil migrar múltiples bases de datos de forma síncrona, esto significa que en algún momento tendrán diferentes esquemas de datos. En consecuencia, trabajaremos en un entorno heterogéneo, donde los servidores de aplicaciones pueden tener diferentes códigos y bases de datos con diferentes esquemas de datos.
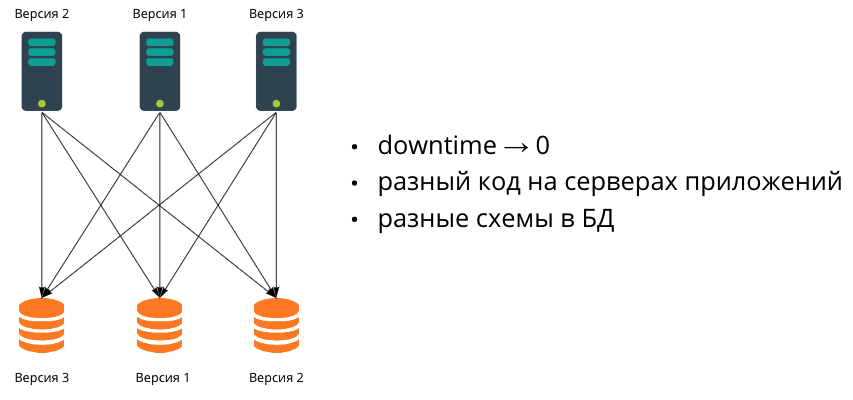
Se trata de esta configuración de la que hablaremos en este artículo y consideraremos las migraciones más populares que escriben los desarrolladores, desde las más simples hasta las más complejas.
Nuestro objetivo es realizar migraciones SQL con un impacto mínimo en el rendimiento de la aplicación, es decir, cambie los datos o el esquema de datos para que la aplicación continúe ejecutándose y los usuarios no se den cuenta.
Agregar una columna
ALTER TABLE my_table ADD COLUMN new_column INTEGER --
Probablemente, cualquier persona que trabaje con la base de datos escribió una migración similar. Si hablamos de PostgreSQL, entonces esta migración es muy barata y segura. El comando en sí, aunque captura el bloqueo de nivel más alto ( AccessExclusive ), se ejecuta muy rápidamente, porque bajo el capó solo se agrega metainformación sobre una nueva columna sin reescribir los datos de la tabla en sí. En la mayoría de los casos, esto pasa desapercibido. Pero pueden surgir problemas si en el momento de la migración hay transacciones largas trabajando con esta tabla. Para comprender la esencia del problema, veamos un pequeño ejemplo de cómo funcionan los bloqueos de forma simplificada en PostgreSQL. Este aspecto será muy importante al considerar también la mayoría de las otras migraciones.
Supongamos que tenemos una tabla grande y SELECCIONAMOS todos los datos de ella. Dependiendo del tamaño de la base de datos y de la propia tabla, puede tardar varios segundos o incluso minutos.

El bloqueo de AccessShare más débil que protege contra cambios en la estructura de la tabla se adquiere durante la transacción .
En este momento, llega otra transacción, que solo intenta realizar una consulta ALTER TABLE a esta tabla. El comando ALTER TABLE, como se mencionó anteriormente, toma un bloqueo AccessExclusive , que no es compatible con ningún otro bloqueo . Ella se pone en fila.
Esta cola de bloqueo se "rastrilla" en estricto orden; incluso si otras consultas vienen después de ALTER TABLE (por ejemplo, también SELECT), que por sí mismas no entran en conflicto con la primera consulta, todas se ponen en cola para ALTER TABLE. Como resultado, la aplicación "se detiene" y espera a que se ejecute ALTER TABLE.
¿Qué hacer en tal situación? Puede limitar el tiempo que se tarda en adquirir un bloqueo mediante el comando SET lock_timeout . Ejecutamos este comando antes de ALTER TABLE (la palabra clave LOCAL significa que la configuración es válida solo dentro de la transacción actual, de lo contrario, dentro de la sesión actual):
SET LOCAL lock_timeout TO '100ms'
y si en 100 milisegundos el comando no logra adquirir el bloqueo, fallará. Luego, o lo reiniciamos nuevamente, esperando que sea exitoso, o vamos a averiguar por qué la transacción lleva tanto tiempo, si esto no debería estar en nuestra aplicación. En cualquier caso, lo principal es que no bloqueamos la aplicación.
Se debe decir que establecer un tiempo de espera es útil antes de cualquier comando que tome un bloqueo estricto.
Agregar una columna con un valor predeterminado
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42
Si este comando se ejecuta en una versión anterior de PostgreSQL (por debajo de la 11), sobrescribirá todas las filas de la tabla. Obviamente, si la mesa es grande, esto puede llevar mucho tiempo. Y dado que se captura un bloqueo estricto ( AccessExclusive ) durante el tiempo de ejecución , también se bloquean todas las consultas a la tabla.
Si PostgreSQL es 11 o más reciente, esta operación es bastante económica. El caso es que en la versión 11 se hizo una optimización, gracias a la cual, en lugar de reescribir la tabla, se almacena el valor por defecto en una tabla especial pg_attribute, y posteriormente, al realizar SELECT, todos los valores vacíos de esta columna serán ser reemplazado sobre la marcha con este valor. En este caso, más adelante, cuando las filas de la tabla se sobrescriban debido a otras modificaciones, el valor se escribirá en estas filas.
Además, a partir de la versión 11, también puede crear inmediatamente una nueva columna y marcarla como NOT NULL:
-- PG 11
ALTER TABLE my_table ADD COLUMN new_column INTEGER DEFAULT 42 NOT NULL
¿Qué pasa si PostgreSQL tiene más de 11 años?
La migración se puede realizar en varios pasos. Primero, creamos una nueva columna sin restricciones ni valores predeterminados. Como se dijo anteriormente, es barato y rápido. En la misma transacción, modificamos esta columna agregando un valor predeterminado.
ALTER TABLE my_table ADD COLUMN new_column INTEGER;
ALTER TABLE my_table ALTER COLUMN new_column SET DEFAULT 42;
Esta división de un comando en dos puede parecer un poco extraña, pero la mecánica es tal que cuando se crea una nueva columna inmediatamente con un valor predeterminado, afecta a todos los registros que están en la tabla, y cuando el valor se establece para una columna existente (aunque solo sea lo creado, como en nuestro caso), solo afecta a los registros nuevos.
Así, luego de ejecutar estos comandos, nos queda actualizar los valores que ya estaban en la tabla. En términos generales, debemos hacer algo como esto:
UPDATE my_table set new_column = 42 --
Pero tal ACTUALIZACIÓN "frontal" es realmente imposible, porque al actualizar una tabla grande, bloquearemos toda la tabla durante mucho tiempo. En el segundo artículo (aquí en el futuro habrá un enlace) veremos qué estrategias existen para actualizar tablas grandes en PostgreSQL, pero por ahora asumiremos que de alguna manera hemos actualizado los datos, y ahora tanto los datos antiguos como el nuevo tendrá el valor requerido por defecto.
Eliminar una columna
ALTER TABLE my_table DROP COLUMN new_column --
Aquí la lógica es la misma que cuando se agrega una columna: los datos de la tabla no se modifican, solo se cambia la metainformación. En este caso, la columna se marca como eliminada y no está disponible para consultas. Esto explica el hecho de que cuando se suelta una columna en PostgreSQL, no se libera espacio físico (a menos que realice un VACUUM FULL), es decir, los datos de los registros antiguos aún permanecen en la tabla, pero no están disponibles cuando se accede a ellos. La desasignación se produce gradualmente a medida que se sobrescriben las filas de la tabla.
Por lo tanto, la migración en sí es simple, pero, por regla general, a veces se encuentran errores en el backend. Antes de eliminar una columna, hay que seguir unos sencillos pasos preparatorios.
- Primero, debe eliminar todas las restricciones (NOT NULL, CHECK, ...) que están en esta columna:
ALTER TABLE my_table ALTER COLUMN new_column DROP NOT NULL
- El siguiente paso es garantizar la compatibilidad con el backend. Debe asegurarse de que la columna no se use en ningún lugar. Por ejemplo, en Hibernate, debe marcar un campo mediante una anotación
@Transient
. En el JOOQ que estamos usando, el campo se agrega a las excepciones usando una etiqueta<excludes>
:
<excludes>my_table.new_column</excludes>
También debe observar de cerca las consultas"SELECT *"
: los marcos pueden mapear todas las columnas en una estructura en el código (y viceversa) y, en consecuencia, puede enfrentar nuevamente el problema de acceder a una columna inexistente.
Una vez publicados los cambios en todos los servidores de aplicaciones, puede eliminar la columna.
Creación de índice
CREATE INDEX my_table_index ON my_table (name) -- ,
Aquellos que trabajan con PostgreSQL probablemente sepan que este comando bloquea toda la tabla. Pero desde la muy antigua versión 8.2 existe la palabra clave CONCURRENTLY , que le permite crear un índice en un modo sin bloqueo.
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name) --
El comando es más lento, pero no interfiere con las solicitudes paralelas.
Este equipo tiene una salvedad. Puede fallar, por ejemplo, al crear un índice único en una tabla que contiene valores duplicados. Se creará el índice, pero se marcará como no válido y no se utilizará en consultas. El estado del índice se puede verificar con la siguiente consulta:
SELECT pg_index.indisvalid
FROM pg_class, pg_index
WHERE pg_index.indexrelid = pg_class.oid
AND pg_class.relname = 'my_table_index'
En tal situación, debe eliminar el índice anterior, corregir los valores en la tabla y luego volver a crearlo.
DROP INDEX CONCURRENTLY my_table_index
UPDATE my_table ...
CREATE CONCURRENTLY INDEX my_table_index ON my_table (name)
Es importante tener en cuenta que el comando REINDEX , que solo está destinado a reconstruir el índice, funciona solo en modo de bloqueo hasta la versión 12 , lo que hace que sea imposible de usar. PostgreSQL 12 agrega soporte CONCURRENTEMENTE y ahora se puede usar.
REINDEX INDEX CONCURRENTLY my_table_index -- PG 12
Crear un índice en una tabla particionada
También deberíamos discutir la creación de índices para tablas particionadas. En PostgreSQL, hay 2 tipos de particionamiento: por herencia y declarativo, que apareció en la versión 10. Veamos ambos con un ejemplo sencillo.
Supongamos que queremos particionar una tabla por fecha y que cada partición contendrá datos durante un año.
Al particionar por herencia, tendremos aproximadamente el siguiente esquema.
Tabla de padres:
CREATE TABLE my_table (
...
reg_date date not null
)
Particiones secundarias para 2020 y 2021:
CREATE TABLE my_table_y2020 (
CHECK ( reg_date >= DATE '2020-01-01' AND reg_date < DATE '2021-01-01' ))
INHERITS (my_table);
CREATE TABLE my_table_y2021 (
CHECK ( reg_date >= DATE '2021-01-01' AND reg_date < DATE '2022-01-01' ))
INHERITS (my_table);
Índices por campo de partición para cada una de las particiones:
CREATE INDEX ON my_table_y2020 (reg_date);
CREATE INDEX ON my_table_y2021 (reg_date);
Dejemos la creación de un disparador / regla para insertar datos en una tabla.
Lo más importante aquí es que cada una de las particiones es prácticamente una tabla independiente que se mantiene por separado. Por lo tanto, la creación de nuevos índices también se realiza como con las tablas regulares:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name);
CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
Ahora veamos el particionamiento declarativo.
CREATE TABLE my_table (...) PARTITION BY RANGE (reg_date);
CREATE TABLE my_table_y2020 PARTITION OF my_table FOR VALUES FROM ('2020-01-01') TO ('2020-12-31');
CREATE TABLE my_table_y2021 PARTITION OF my_table FOR VALUES FROM ('2021-01-01') TO ('2021-12-31');
La creación de índices depende de la versión de PostgreSQL. En la versión 10, los índices se crean por separado, al igual que en el enfoque anterior. En consecuencia, la creación de nuevos índices para una tabla existente también se realiza de la misma manera.
En la versión 11, se ha mejorado el particionamiento declarativo y las tablas ahora se sirven juntas . La creación de un índice en la tabla principal crea automáticamente índices para todas las particiones nuevas y existentes que se crearán en el futuro:
-- PG 11 ()
CREATE INDEX ON my_table (reg_date)
Esto es útil cuando se crea una tabla particionada, pero no cuando se crea un índice nuevo en una tabla existente, porque el comando toma un bloqueo fuerte mientras se crean los índices.
CREATE INDEX ON my_table (name) --
Desafortunadamente, CREATE INDEX no admite la palabra clave CONCURRENTLY para tablas particionadas. Para sortear la limitación y migrar sin bloquear, puede hacer lo siguiente.
- Crear índice en la tabla principal con ÚNICA opción
CREATE INDEX my_table_index ON ONLY my_table (name)
El comando creará un índice no válido vacío sin crear índices para las particiones . - Cree índices para cada una de las particiones:
CREATE CONCURRENTLY INDEX my_table_y2020_index ON my_table_y2020 (name); CREATE CONCURRENTLY INDEX my_table_y2021_index ON my_table_y2021 (name);
- Adjunte índices de particiones al índice de la tabla principal:
ALTER INDEX my_table_index ATTACH PARTITION my_table_y2020_index; ALTER INDEX my_table_index ATTACH PARTITION my_table_y2021_index;
Limitaciones
Ahora repasemos las restricciones: claves NOT NULL, foráneas, únicas y primarias.
Creando una restricción NOT NULL
ALTER TABLE my_table ALTER COLUMN name SET NOT NULL --
Al crear una restricción de esta manera, se escaneará toda la tabla; se verificará en todas las filas la condición no nula y, si la tabla es grande, puede llevar mucho tiempo. El bloque fuerte que captura este comando bloqueará todas las solicitudes simultáneas hasta que se complete.
¿Qué se puede hacer? PostgreSQL tiene otro tipo de restricción, CHECK , que se puede usar para obtener el resultado deseado. Esta restricción prueba cualquier condición booleana que consta de columnas de fila. En nuestro caso, la condición es trivial -
CHECK (name IS NOT NULL)
. Pero lo más importante es que la restricción CHECK admite la invalidación (palabra clave
NOT VALID
):
ALTER TABLE my_table ADD CONSTRAINT chk_name_not_null
CHECK (name IS NOT NULL) NOT VALID -- , PG 9.2
La restricción creada de esta manera se aplica solo a los registros recién agregados y modificados, y los existentes no se verifican, por lo que la tabla no se escanea.
Para garantizar que los registros existentes también satisfagan la restricción, es necesario validarlo (por supuesto, primero actualizando los datos en la tabla):
ALTER TABLE my_table VALIDATE CONSTRAINT chk_name_not_null
El comando itera sobre las filas de la tabla y verifica que todos los registros no sean nulos. Pero a diferencia de la restricción NOT NULL habitual, el bloqueo capturado en este comando no es tan fuerte (ShareUpdateExclusive); no bloquea las operaciones de inserción, actualización y eliminación.
Creando una clave foránea
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) --
Cuando se agrega una clave externa, todos los registros de la tabla secundaria se comprueban en busca de un valor en la principal. Si la mesa es grande, entonces este escaneo será largo y el bloqueo que se mantiene en ambas mesas también será largo.
Afortunadamente, las claves foráneas en PostgreSQL también admiten NOT VALID, lo que significa que podemos usar el mismo enfoque que se discutió anteriormente con CHECK. Creemos una clave externa no válida:
ALTER TABLE my_table ADD CONSTRAINT fk_group
FOREIGN KEY (group_id) REFERENCES groups(id) NOT VALID
luego actualizamos los datos y realizamos la validación:
ALTER TABLE my_table VALIDATE CONSTRAINT fk_group_id
Crea una restricción única
ALTER TABLE my_table ADD CONSTRAINT uk_my_table UNIQUE (id) --
Como en el caso de las restricciones discutidas anteriormente, el comando captura un bloqueo estricto, bajo el cual verifica todas las filas de la tabla con la restricción, en este caso, la unicidad.
Es importante saber que, bajo el capó, PostgreSQL impone restricciones únicas utilizando índices únicos. En otras palabras, cuando se crea una restricción, se crea un índice único correspondiente con el mismo nombre para atender esa restricción. Con la siguiente consulta, puede averiguar el índice de publicación de la restricción:
SELECT conindid index_oid, conindid::regclass index_name
FROM pg_constraint
WHERE conname = 'uk_my_table_id'
Al mismo tiempo, se utiliza en la mayoría de las limitaciones de tiempo de creación, lo mismo ocurre con el índice y su posterior enlace para limitar muy rápidamente. Además, si ya ha creado un índice único, puede hacerlo usted mismo creando un índice utilizando las palabras clave USING INDEX:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id UNIQUE
USING INDEX uk_my_table_id -- , PG 9.1
Por lo tanto, la idea es simple: creamos un índice único CONCURRENTEMENTE, como discutimos anteriormente, y luego creamos una restricción única basada en él.
En este punto, puede surgir la pregunta : ¿por qué crear una restricción, si el índice hace exactamente lo que se requiere, garantiza la unicidad de los valores? Si excluimos los índices parciales de la comparación , entonces, desde un punto de vista funcional, el resultado es realmente casi idéntico. La única diferencia que hemos encontrado es que las restricciones pueden diferirse , pero los índices no. La documentación para versiones anteriores de PostgreSQL (hasta la 9.4 incluida) tenía una nota al piecon la información de que la forma preferida de crear una restricción de unicidad es crear explícitamente una restricción
ALTER TABLE ... ADD CONSTRAINT
, y el uso de índices debe considerarse un detalle de implementación. Sin embargo, en versiones más recientes se ha eliminado esta nota a pie de página.
Creando una clave primaria
Además de ser única, la clave principal impone la restricción no nula. Si la columna originalmente tenía tal restricción, entonces no será difícil "convertirla" en una clave primaria - también creamos un índice único CONCURRENTEMENTE, y luego la clave primaria:
ALTER TABLE my_table ADD CONSTRAINT uk_my_table_id PRIMARY KEY
USING INDEX uk_my_table_id -- id is NOT NULL
Es importante tener en cuenta que la columna debe tener una restricción NO NULL "justa"; el enfoque CHECK discutido anteriormente no funcionará.
Si no hay límite, hasta la undécima versión de PostgreSQL no hay nada que hacer; no hay forma de crear una clave primaria sin bloquear.
Si tiene PostgreSQL 11 o más reciente, esto se puede lograr creando una nueva columna que reemplazará a la existente. Entonces, paso a paso.
Cree una nueva columna que no sea nula de forma predeterminada y tenga un valor predeterminado:
ALTER TABLE my_table ADD COLUMN new_id INTEGER NOT NULL DEFAULT -1 -- PG 11
Configuramos la sincronización de los datos de las columnas antiguas y nuevas usando un disparador:
CREATE FUNCTION on_insert_or_update() RETURNS TRIGGER AS
$$
BEGIN
NEW.new_id = NEW.id;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER trg BEFORE INSERT OR UPDATE ON my_table
FOR EACH ROW EXECUTE PROCEDURE on_insert_or_update();
A continuación, debe actualizar los datos de las filas que no se vieron afectadas por el activador:
UPDATE my_table SET new_id = id WHERE new_id = -1 --
La solicitud con la actualización anterior está escrita "en la frente", en una mesa grande no vale la pena hacer esto, porque habrá un bloqueo largo. Como se mencionó anteriormente, el segundo artículo analizará los enfoques para actualizar tablas grandes. Por ahora, supongamos que los datos están actualizados y todo lo que queda es intercambiar las columnas.
ALTER TABLE my_table RENAME COLUMN id TO old_id;
ALTER TABLE my_table RENAME COLUMN new_id TO id;
ALTER TABLE my_table RENAME COLUMN old_id TO new_id;
En PostgreSQL, los comandos DDL son transaccionales; esto significa que puede cambiar el nombre, agregar, eliminar columnas y, al mismo tiempo, una transacción paralela no verá esto en el curso de sus operaciones.
Después de cambiar las columnas, queda crear un índice y "limpiar": eliminar el activador, la función y la columna anterior.
Una hoja de trucos rápida con migraciones
Antes de cualquier comando que capture bloqueos fuertes (casi todos
ALTER TABLE ...
), se recomienda llamar a:
SET LOCAL lock_timeout TO '100ms'
| Migración | Enfoque recomendado |
|---|---|
| Agregar una columna | |
| Agregar una columna con un valor predeterminado [y NO NULO] | con PostgreSQL 11:
antes de PostgreSQL 11:
|
| Eliminar una columna |
|
| Creación de índice | Si falla:
|
| Crear un índice en una tabla particionada | Particionamiento por herencia + declarativo en PG 10:
Particionamiento declarativo con PG 11:
|
| Creando una restricción NOT NULL |
|
| Creando una clave foránea |
|
| Crea una restricción única |
|
| Creando una clave primaria | Si la columna NO ES NULA:
Si la columna ES NULA con PG 11:
|
En el próximo artículo, veremos enfoques para actualizar tablas grandes.
¡Migraciones fáciles para todos!