
Con 12 problemas detrás de nosotros, es hora de cambiar un poco el nombre y el diseño, pero por dentro todavía está esperando investigaciones, demostraciones, modelos abiertos y conjuntos de datos. Conozca la nueva entrega de Machine Learning Toolkit.
DALL E
Accesibilidad: página del proyecto / acceso a API cerrada a través de lista de espera
OpenAI presentó su nuevo modelo de lenguaje transformador DALL-E con 12 mil millones de parámetros, entrenado en pares imagen-texto. El modelo se basa en GPT-3 y se utiliza para sintetizar imágenes a partir de descripciones textuales.
En junio pasado, la compañía mostró cómo un modelo entrenado en secuencias de píxeles con una descripción precisa puede llenar los vacíos en las imágenes que se introducen en la entrada. Los resultados ya eran impresionantes entonces, pero aquí Open AI superó todas las expectativas. Al igual que GPT-3 sintetiza oraciones completas coherentes, DALL · E crea imágenes complejas.

Los modelos son sorprendentemente buenos en objetos antropomórficos (rábanos paseando al perro) y una combinación de objetos incompatibles (un caracol en forma de arpa), por lo que eligieron la fusión de dos nombres para el nombre: el surrealista español Salvador Dalí. y el robot Pixar WALL-I.
Entonces, ¿qué resultados tiene el modelo?
El modelo es capaz de visualizar la profundidad del espacio, por lo que es posible manipular una escena tridimensional. Basta, al describir la imagen deseada, indicar desde qué ángulo se debe ver el objeto y bajo qué iluminación. En el futuro, esto permitirá la creación de verdaderas representaciones en 3D.
Además, el modelo es capaz de aplicar efectos ópticos a la escena, por ejemplo, al disparar con un objetivo de ojo de pez. Pero hasta ahora no se adapta bien a los reflejos: el cubo en el espejo no se ha sintetizado de manera convincente. Por tanto, con distintos grados de fiabilidad, DALL · E a través del lenguaje natural hace frente a las tareas para las que se utilizan motores de modelado 3D en la industria. Esto permite que se utilice para renderizar diseños de salas.
El modelo conoce bien la geografía y los puntos de referencia icónicos, así como las características distintivas de las distintas épocas. Puede sintetizar una fotografía de un teléfono antiguo o del puente Golden Gate en San Francisco.
Con todo esto, el modelo no necesita una descripción ultra precisa: llenará algunos de los vacíos por sí mismo. Como señaló Open AI, cuanto más precisa sea la descripción, peor será el resultado.
Recuerde que el GPT-3 es un modelo de disparo cero, no es necesario configurarlo ni capacitarlo adicionalmente para realizar tareas específicas. Además de la descripción, puede dar una pista para que el modelo genere la respuesta deseada. DALL · E hace lo mismo con el renderizado y puede realizar varias tareas de conversión de imagen a imagen según las indicaciones. Por ejemplo, puede dar una imagen como entrada y pedir que la haga en forma de boceto.
Sorprendentemente, los creadores no se fijaron ese objetivo y no lo proporcionaron de ninguna manera al entrenar al modelo. La habilidad se reveló solo durante las pruebas.
Guiados por este descubrimiento, los autores estudiaron la capacidad de DALL · E para resolver problemas lógicos de la prueba de CI visual y establecieron la tarea no para elegir la respuesta correcta de las opciones presentadas, sino para predecir completamente el elemento faltante.
En general, el modelo logró continuar correctamente la secuencia en la parte de las tareas donde se requería comprensión geométrica.
El modelo aún no se ha publicado y ni siquiera hay una descripción aproximada de su arquitectura. En esta etapa, puede solicitar acceso a la API o consultar la implementación no oficial en PyTorch (también se está trabajando en una versión no oficial en TensorFlow ).
CLIP (Lenguaje contrastivo - Preentrenamiento de imágenes)
Accesibilidad: Página del proyecto / Código fuente
El aprendizaje profundo ha revolucionado la visión por computadora, pero los enfoques actuales todavía tienen dos problemas importantes que cuestionan el uso de DNN en esta área.
En primer lugar, la creación de conjuntos de datos sigue siendo muy costosa, pero al mismo tiempo, como resultado, permite el reconocimiento de un conjunto muy limitado de imágenes visuales y es adecuado para tareas limitadas. Por ejemplo, al preparar el conjunto de datos de ImageNet, se necesitaron 25.000 personas para componer descripciones de 14 millones de imágenes para 22.000 categorías de objetos. Al mismo tiempo, el modelo ImageNet es bueno para predecir solo aquellas categorías que están representadas en el conjunto de datos, y si se requiere alguna otra tarea, los especialistas deberán crear nuevos conjuntos de datos y completar el entrenamiento del modelo.
En segundo lugar, los modelos que funcionan bien en los puntos de referencia se quedan cortos en su entorno natural. Los modelos implementados en el mundo real no funcionan tan bien como en un laboratorio. En otras palabras, el modelo está optimizado para aprobar una prueba específica como un estudiante abarrotando preguntas anteriores del examen.
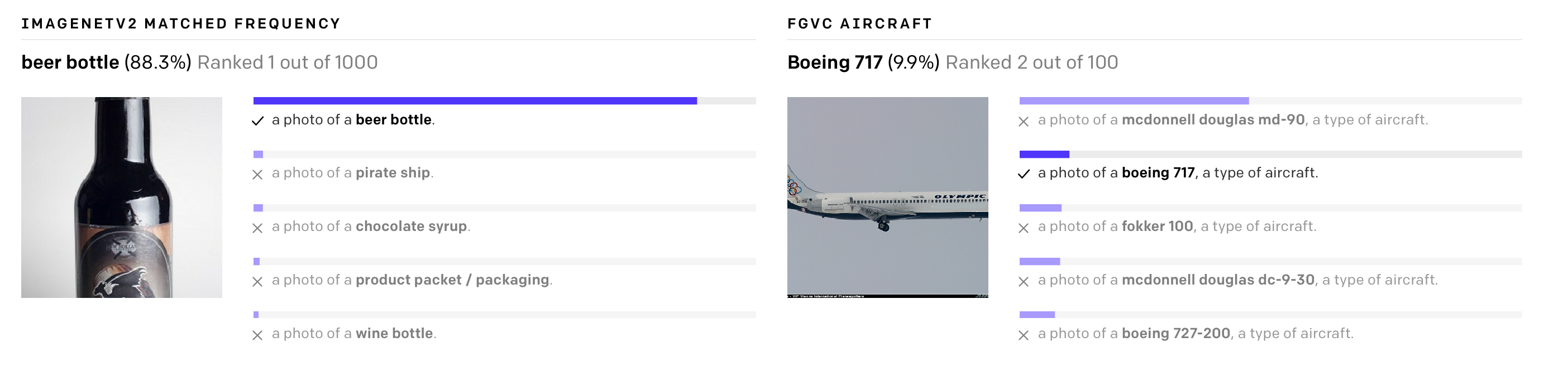
La red neuronal abierta CLIP de OpenAI tiene como objetivo resolver estos problemas. El modelo se entrena en una gran cantidad de imágenes y descripciones de texto disponibles en Internet y las traduce en representaciones vectoriales, incrustaciones. Estas representaciones se comparan para que los números de la inscripción y la imagen adecuada para ella estén cerca.
CLIP se puede probar inmediatamente en diferentes puntos de referencia sin necesidad de formación sobre sus datos. El modelo realiza pruebas de clasificación sin optimización directa. Por ejemplo, la prueba ObjectNet prueba la capacidad del modelo para reconocer objetos en diferentes ubicaciones y con fondos cambiantes, mientras que ImageNet Rendition e ImageNet Sketch prueban la capacidad del modelo para reconocer imágenes más abstractas de objetos (no solo un plátano, sino un plátano en rodajas). o dibujo de banana). CLIP funciona igualmente bien en todos ellos.
CLIP se puede adaptar para realizar una amplia gama de tareas de clasificación visual sin ejemplos de formación adicionales. Para aplicar CLIP a un nuevo problema, solo necesita darle al codificador los nombres de las representaciones visuales, y producirá un clasificador lineal de estas representaciones, que no es inferior en precisión a los modelos entrenados con el profesor.
Github ya tiene una implementación para fotos con Unsplash, que muestra qué tan bien agrupa las imágenes el modelo. Los diseñadores ya pueden usarlo para diseñar moodboards.
DeBERTa de Microsoft
Disponibilidad: Fuente / Página del proyecto
Como de costumbre, las noticias de OpenAI eclipsaron otros anuncios, aunque hubo otro evento que se discutió activamente en la comunidad. El modelo DeBERTa de Microsoft superó la línea de base humana en la prueba SuperGLUE Natural Language Comprehension (NLU).
Un punto de referencia basado en 10 parámetros determina si el algoritmo "comprende" lo que ha leído y hace una calificación. La puntuación media para los no expertos es de 89,8 puntos y los problemas que deben resolver los modelos son comparables a los de un examen de inglés. DeBERTa mostró 90,3, seguido por T5 + Meena de Google.
Así, el modelo logró adelantar a un humano por segunda vez, pero es de destacar que DeBERTa tiene 1.500 millones de parámetros de entrenamiento, 8 veces menos que T5.
El modelo representa un nuevo mecanismo de atención dividida, diferente del transformador original, donde cada token está codificado por vectores de contenido y posiciones que no se suman en un vector, matrices separadas trabajan con ellos.
NeuralMagicOjo
Accesibilidad: página del proyecto / código / colab ¿
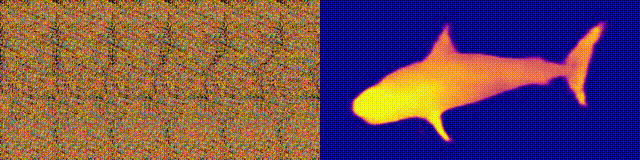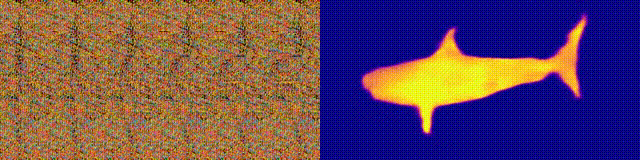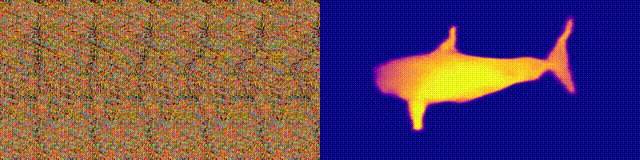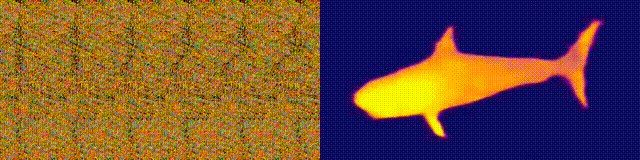
Recuerda los álbumes Magic Eye con estereogramas? Aquí hay algo similar, solo para autostereogramas, en el que ambas partes del estereopair están en la misma imagen y codificadas en una estructura raster, de modo que puede crear ilusiones visuales de tridimensionalidad.
El autor del estudio entrenó al modelo de CNN para reconstruir la profundidad del autoestereograma y comprender su contenido. Para lograr el efecto estéreo, el modelo tuvo que ser entrenado para detectar y evaluar el desajuste de texturas cuasi-periódicas. El modelo se entrenó en un conjunto de datos de modelos 3D, sin un maestro.
El método le permite restaurar con precisión la profundidad del autoestereograma. Los investigadores esperan que esto ayude a las personas con discapacidad visual, y los estereogramas se pueden utilizar como marcas de agua en las imágenes.
StyleFlow

Accesibilidad: código fuente
Como hemos visto más de una vez, las GAN incondicionales (como las StyleGAN) pueden crear imágenes fotorrealistas de alta calidad. Sin embargo, rara vez es posible gestionar el proceso de generación utilizando atributos semánticos mientras se mantiene la calidad de la salida. Debido a la latencia de GAN compleja y confusa, la edición de un atributo a menudo da como resultado cambios no deseados en otros. Este modelo ayuda a resolver este problema. Por ejemplo, puede cambiar el ángulo de visión, la variación de la iluminación, la expresión, el vello facial, el género y la edad.
Transformadores domesticados
Accesibilidad: página del proyecto / código fuente Los
transformadores son capaces de ofrecer excelentes resultados en una variedad de aplicaciones. Pero en términos de potencia informática son muy exigentes, por lo que no son adecuados para trabajar con imágenes de alta resolución. Los autores del estudio combinaron un transformador con una red convolucional desplazada inductivamente y pudieron obtener imágenes con alta resolución.
Integración de POse

Accesibilidad: código fuente Las
actividades diarias, ya sea correr o leer un libro, se pueden considerar como una secuencia de posturas, que consisten en la posición y orientación del cuerpo de una persona en el espacio. El reconocimiento de pose abre una serie de posibilidades en AR, control de gestos, etc. Sin embargo, los datos obtenidos de la imagen 2D difieren según el punto de vista de la cámara. Este algoritmo de Google AI reconoce la similitud de poses desde diferentes ángulos, haciendo coincidir los puntos clave de la visualización 2D de la pose con la incrustación invariante de vista.
Aprendiendo a aprender
Accesibilidad: código fuente
Para aprender a levantar o colocar una botella sobre la mesa, solo necesitamos ver a otra persona hacerlo. Para aprender a operar tales objetos, una máquina requiere recompensas programadas manualmente para completar con éxito los componentes básicos de una tarea. Antes de que un robot pueda aprender a colocar una botella sobre una mesa, debe ser recompensado por aprender a mover la botella verticalmente. Solo después de una serie de tales iteraciones aprenderá a colocar la botella. Facebook introdujo un método que entrena una máquina en un par de sesiones de observación humana.
Así de brillante fue el primer mes de este año. ¡Gracias por leer y estad atentos a los próximos lanzamientos!