Tutorial: Armado de una red neuronal usando el ejemplo de la clasificación de animales dibujados en el modo "aprendizaje sin entrenamiento" .
: , , CLIP OpenAI.
: : .
CLIP OpenAI — , , ! , CLIP . CLIP : .
: , . " ". TensorFlow , PyTorch . . . , OpenAI CLIP? , , Python, . ? . + : ! !
, ( CLIP) , . .
, « » — - , .
?
.

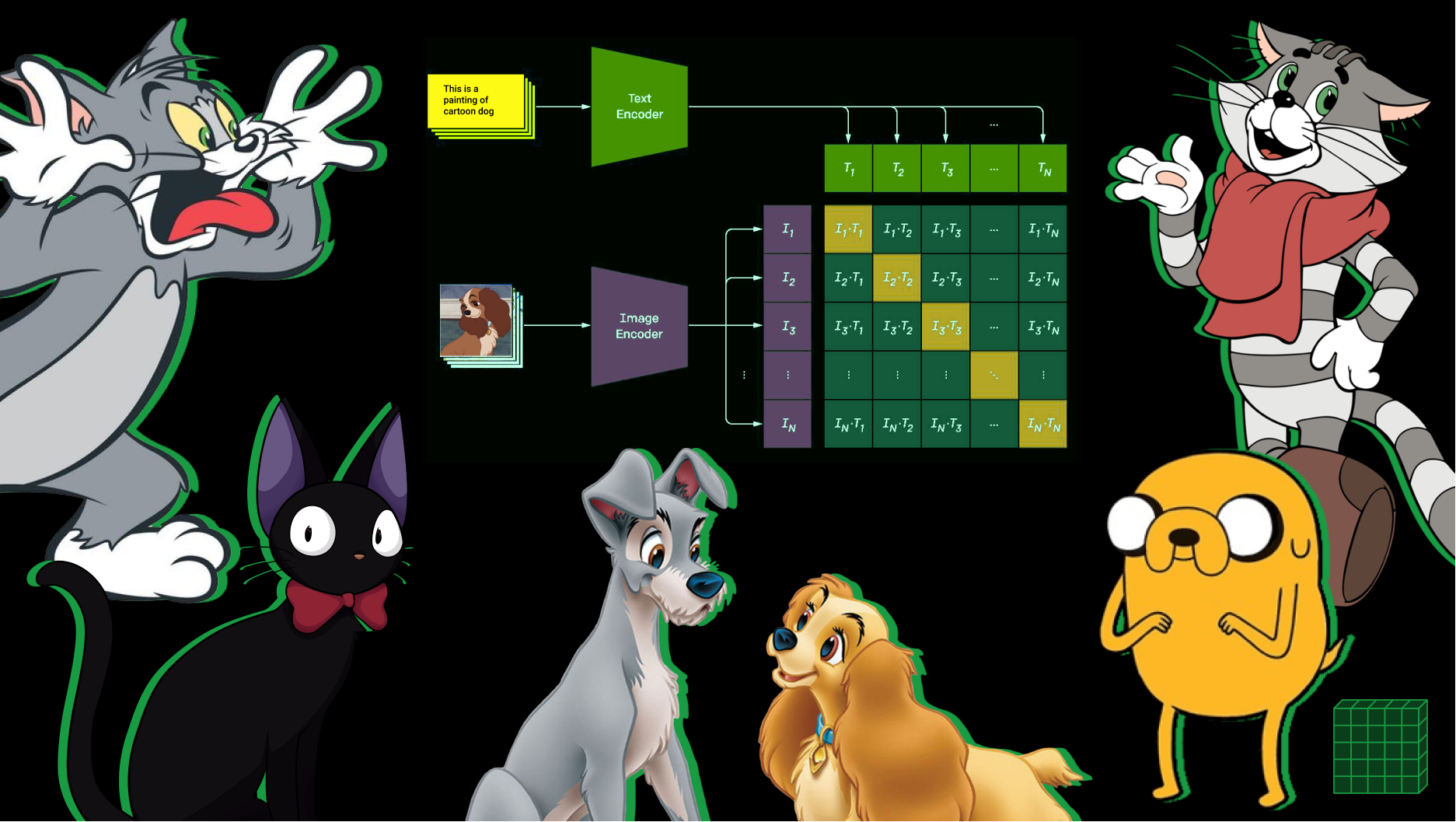
10 . . , ( 1), , CLIP . , CLIP.
:

, , , . . CLIP . , . , : a photo of a plane, a photo of a car, a photo of a dog, …, a photo of a bird. CLIP , , a photo of a dog. , , (, ) , . , , !
, : photo of a ____ a centered satellite photo of ____. , . , ! — .
: CLIP, , , :
— , ! !
: CLIP
Colab. PyTorch 1.7.1.
CLIP. .
. .
. " " !
. .
Beyond the Infinite. ?
>> Colab: . . 5 . <<
Colab
colab, , runtime c . , «GPU» Runtime > Change Runtime Type. PyTorch 1.7.1.
CLIP
CLIP, 400 -. ( ViT-B/32 CLIP). model.pt CLIP: Visual Transformer2 "ViT-B/32" + Text Transformer
: CLIP: Visual Transformer "ViT-B/32" + Text Transformer
Model parameters: 151,277,313
Input resolution: 224
Context length: 77
Vocab size: 49408
CLIP Visual Transformer "ViT-B/32", , 224x224 . . , 400 - .
Text Transformer CLIP . . ontext length, .
, CLIP.
10 . (cosine similarity ).

# image_encoder - Vision Transformer
# text_encoder - Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embe
# extract feature representations of each modality
I_f = image_encoder(I) # [n, d_i]
T_f = text_encoder(T) # [n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T)
Numpy-like pseudocode CLIP. CLIP OpenAI: , : https://habr.com/ru/post/539312/
, cosine similarity, . , CLIP .
this is a painting of cartoon ________.
?
. cosine similarity -, , , , . . , . . Text Transformer .
Cosine similarity — , ( , L2) . , . .
, , - . OpenAI c CLIP logistic regression ResNet-50, , , CLIP 16 27 baseline ( ).
CLIP .

CLIP baseline ( logistic regression ResNet-50), . 27 . CLIP baseline , 16 27 , ImageNet! - ResNet-50. , CLIP baseline Kinetics700 UCF101 " ". , .
, . .

, , — ( ). adventure time, , .

. . . Colab.
. — . . , - ( ). . .




Beyond the Infinite
:
PyTorch CLIP ~ 30
url colab ~ 30
10- + ~ 3
1 c_pickle_ ()
text_features /= text_features.norm(dim=-1, keepdim=True)
~ 1
, , , . , . BiT3 . CV .
, CLIP — NLP CV. , , , , "" . , , NLP, : Vision Transformers. few-shot zero-shot learning nlp cv . , , !
, . 6 64, . , , . : , PoC , — ( ) .

, , :
zero-shot CLIP BiT-M 16-shot linear probes. , few-shot learning CLIP, , linear probes . - , Big Transfer (BiT).
Vision Transformers . . CLIP CLIP-ViT Vision Transformer'. 224x224 : ViT-B/32, ViT-B/16, ViT-L/14, ViT-L/14, fine-tune 336336.
Big Transfer (BiT): General Visual Representation Learning - https://arxiv.org/abs/1912.11370v3
! , . !
CLIP ? " " ? , -, ? ? - ? " "? ? !