
Foto de Richard Jacobs en Unsplash
En noviembre de 2020, comenzamos una importante migración para actualizar nuestro clúster de PostgreSQL de 9.6 a 12.4. En esta publicación, le daré una descripción general rápida de nuestra arquitectura en Coffee Meets Bagel, explicaré cómo se redujo el tiempo de inactividad de la actualización a menos de 30 minutos y compartiré lo que aprendimos en el camino.
Arquitectura
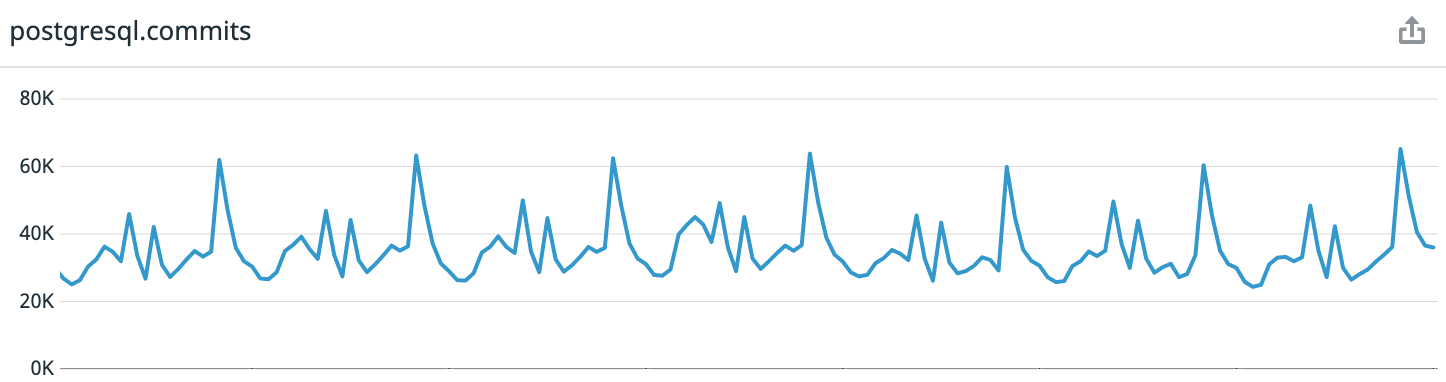
Como referencia: Coffee Meets Bagel es una aplicación de citas románticas con un sistema de selección. Todos los días, nuestros usuarios reciben un lote limitado de candidatos de alta calidad al mediodía en su zona horaria. Esto conduce a patrones de carga altamente predecibles. Si observa los datos de la última semana desde el momento de escribir el artículo, obtenemos un promedio de 30 mil transacciones por segundo, en el pico, hasta 65 mil.
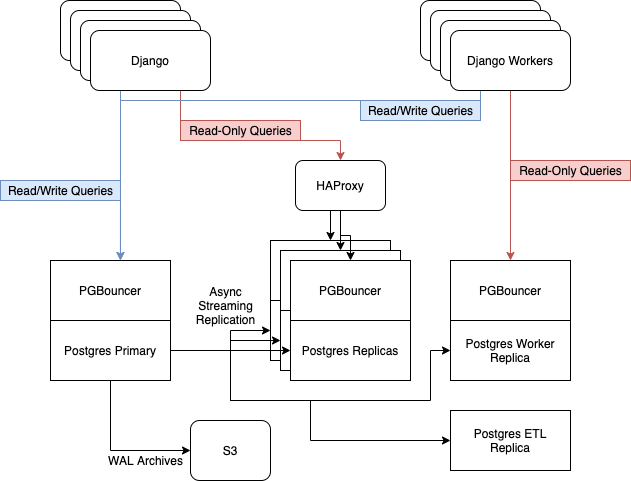
Antes de la actualización, teníamos 6 servidores Postgres ejecutándose en instancias i3.8xlarge en AWS. Contenían un nodo maestro, tres réplicas para atender tráfico web de solo lectura, equilibrado con HAProxy, un servidor para trabajadores asíncronos y un servidor para ETL [ Extraer, Transformar, Cargar ] y Business Intelligence....
Confiamos en la replicación de transmisión integrada de Postgres para mantener actualizada nuestra flota de réplicas.
Razones para la actualización
En los últimos años, hemos ignorado notablemente nuestra capa de datos y, como resultado, está un poco desactualizada. Especialmente muchas "muletas" fueron recogidas por nuestro servidor principal - ha estado en línea durante 3.5 años. Aplicamos parches a varias bibliotecas y servicios del sistema sin detener el servidor.

Mi candidato para el subreddit r / uptimeporn
Como resultado, se han acumulado muchas rarezas que te ponen nervioso. Por ejemplo,
systemd
no se inician nuevos servicios . Tuve que configurar el lanzamiento del agente
datadog
en la sesión
screen
. A veces, SSH dejaba de responder cuando la carga del procesador estaba por encima del 50% y el propio servidor enviaba solicitudes de base de datos con regularidad.
Y también el espacio libre en el disco comenzó a acercarse a valores peligrosos. Como mencioné anteriormente, Postgres se ejecutó en instancias i3.8xlarge en EC2 que tienen 7.6TB de almacenamiento NVMe. A diferencia de EBS, el tamaño del disco no se puede cambiar dinámicamente aquí; lo que se estableció originalmente será. Y llenamos alrededor del 75% del disco. Quedó claro que sería necesario cambiar el tamaño de la instancia para respaldar el crecimiento futuro.
Nuestras necesidades
- Tiempo de inactividad mínimo. Hemos establecido una meta de 4 horas de tiempo de inactividad total, incluidas las interrupciones no planificadas causadas por errores de actualización.
- Cree un nuevo clúster de base de datos en nuevas instancias para reemplazar la flota actual de servidores obsoletos.
- Vaya a i3.16xlarge para obtener espacio para crecer.
Conocemos tres formas de actualizar Postgres: hacer una copia de seguridad y restaurarlo, pg_upgrade y replicación lógica pglogical.
Inmediatamente abandonamos el primer método, restaurando desde una copia de seguridad: para nuestro conjunto de datos de 5,7 TB, llevaría demasiado tiempo. A su velocidad, pg_upgrade no cumplía con los requisitos 2 y 3: es una herramienta de migración en la misma máquina. Por lo tanto, elegimos la replicación lógica.
Nuestro proceso
Se ha escrito bastante sobre las características clave de pglogical. Por lo tanto, en lugar de repetir verdades comunes, simplemente daré artículos que me resultaron útiles:
- Actualización de la versión principal con un tiempo de inactividad mínimo ;
- Actualización de PostgreSQL de 9.4 a 10.3 con pglogical ;
- Desmitificando pglogical - Tutorial .
Creamos un nuevo servidor Postgres 12 primario y usamos pglogical para sincronizar todos nuestros datos. Cuando se sincronizó y pasó a replicar los cambios entrantes, comenzamos a agregarle réplicas de transmisión. Después de configurar la nueva réplica de transmisión, la incluimos en HAProxy y eliminamos una de la versión anterior 9.6.
Este proceso continuó hasta que los servidores de Postgres 9.6 se apagaron por completo, excepto el maestro. La configuración tomó la siguiente forma.

Luego fue el turno del cambio de clúster (failover), para lo cual solicitamos la ventana de mantenimiento. El proceso de cambio también está bien documentado en Internet, por lo que solo hablaré de los pasos generales:
- Transferencia del sitio al modo de trabajo técnico;
- Cambiar los registros DNS del maestro a un nuevo servidor;
- Sincronización forzada de todas las secuencias de claves primarias;
- Inicio manual del punto de control (
CHECKPOINT
) en el antiguo maestro. - En el nuevo asistente: realización de algunos procedimientos de prueba y validación de datos;
- Habilitando el sitio.
En general, la transición fue bien. A pesar de cambios tan importantes en nuestra infraestructura, no hubo tiempo de inactividad no planificado.
Lecciones aprendidas
Con el éxito general de la operación, se encontraron un par de problemas en el camino. El peor de ellos casi mata a nuestro maestro de Postgres 9.6 ...
Lección # 1: La sincronización lenta puede ser peligrosa
Comencemos con un contexto: ¿cómo funciona pglogical? El proceso del remitente en el proveedor (en este caso nuestro antiguo asistente 9.6) decodifica el registro WAL de escritura anticipada, obtiene los cambios lógicos y los envía al suscriptor.
Si el suscriptor se queda atrás, el proveedor almacenará los segmentos WAL para que cuando el suscriptor se ponga al día, no se pierdan datos.
La primera vez que se agrega una tabla al flujo de replicación, pglogical primero debe sincronizar los datos de la tabla. Esto se hace con el comando Postgres
COPY
. Después de eso, los segmentos WAL comienzan a acumularse en el proveedor de modo que los cambios durante la operación
COPY
resultó ser transferido al suscriptor después de la sincronización inicial, lo que garantiza que no se pierdan datos.
En la práctica, esto significa que al sincronizar una tabla grande en un sistema con una gran carga de escritura / cambios, debe monitorear cuidadosamente el uso del disco. En el primer intento de sincronizar nuestra mesa más grande (4 TB), el equipo y el operador
COPY
trabajaron durante más de un día. Durante este tiempo, el nodo del proveedor ha acumulado más de un terabyte de registros WAL proactivos.
Como recordará por lo que se dijo, a nuestros antiguos servidores de bases de datos solo les quedaban dos terabytes de espacio libre en disco. Estimamos a partir de la plenitud del disco del servidor del suscriptor que solo se copió una cuarta parte de la tabla. Por lo tanto, el proceso de sincronización tuvo que detenerse de inmediato: el disco del maestro habría terminado antes.
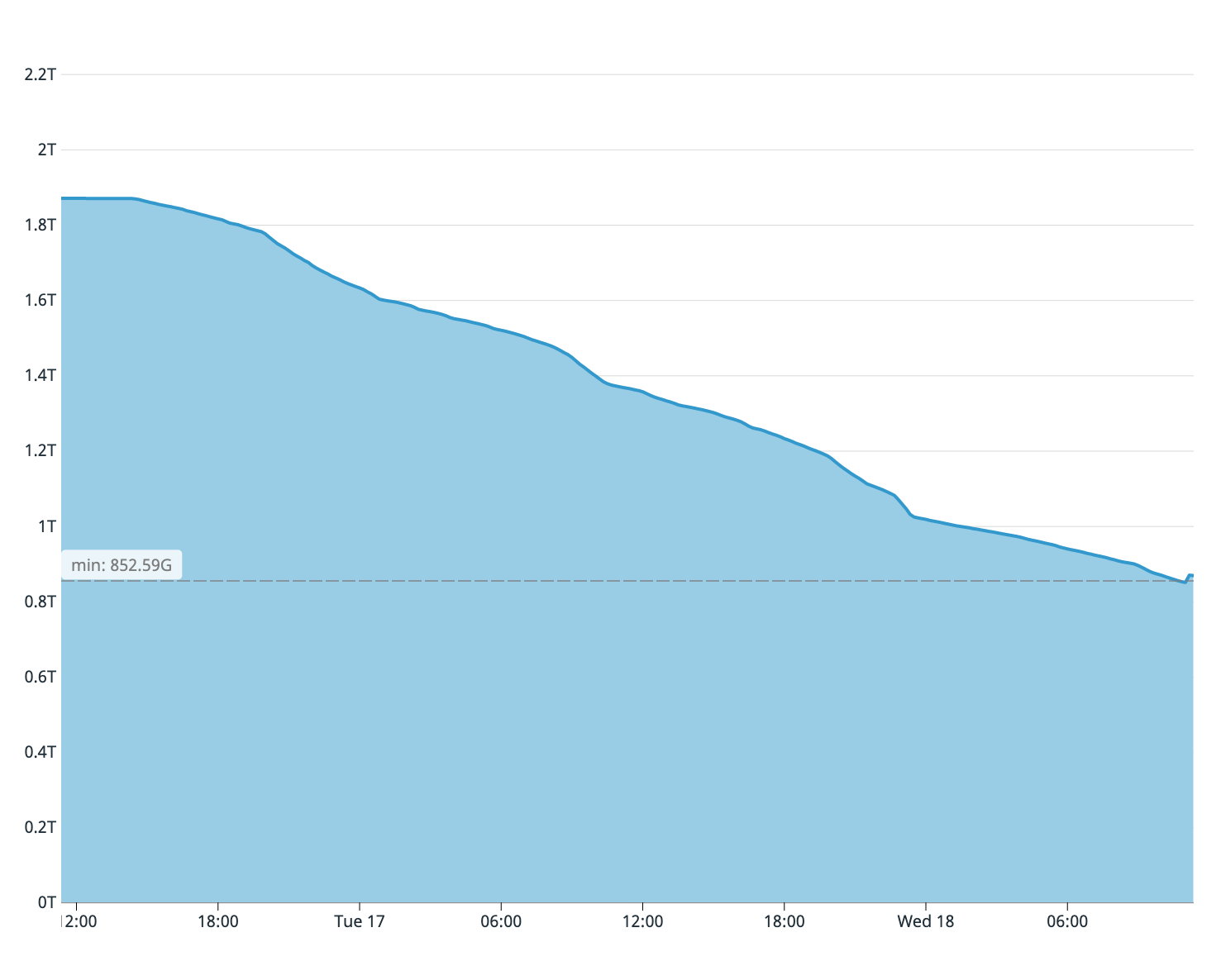
Espacio disponible en disco en el asistente anterior en el primer intento de sincronización
Para acelerar el proceso de sincronización, hicimos los siguientes cambios en la base de datos de suscriptores:
- Se eliminaron todos los índices de la tabla sincronizada;
fsynch
cambiado aoff
;- Cambiado
max_wal_size
a50GB
; - Cambiado
checkpoint_timeout
a1h
.
Estos cuatro pasos aceleran significativamente el proceso de sincronización en el suscriptor, y nuestro segundo intento de sincronización de la tabla se completó en 8 horas.
Lección n. ° 2: cada cambio de fila se registra como un conflicto
Cuando pglogical detecta un conflicto, la aplicación deja una "
CONFLICT: remote UPDATE on relation PUBLIC.foo. Resolution: apply_remote
" entrada en los registros .
Sin embargo, resultó que cada cambio de fila procesado por el suscriptor se registraba como un conflicto. En unas pocas horas de replicación, la base de datos del suscriptor dejó gigabytes de archivos de registro conflictivos.
Este problema se resolvió configurando un parámetro
pglogical.conflict_log_level = DEBUG
en el archivo
postgresql.conf
.
Sobre el Autor
 Tommy Lee es ingeniero de software senior en Coffee Meets Bagel. Antes de eso, trabajó para Microsoft y Wave HQ, un fabricante canadiense de sistemas de automatización de contabilidad.
Tommy Lee es ingeniero de software senior en Coffee Meets Bagel. Antes de eso, trabajó para Microsoft y Wave HQ, un fabricante canadiense de sistemas de automatización de contabilidad.