
Hay muchos artículos que explican para qué sirve Python GIL (The Global Interpreter Lock) (me refiero a CPython). En resumen, el GIL evita que el código Python limpio multiproceso use múltiples núcleos de procesador.
Sin embargo, en Vaex realizamos la mayoría de las tareas computacionalmente intensivas en C ++ con GIL desactivado. Esta es una práctica normal para las bibliotecas de Python de alto rendimiento, donde Python solo actúa como un pegamento de alto nivel.
El GIL debe desactivarse explícitamente, y es responsabilidad del programador, que puede olvidarse, lo que conducirá a un uso ineficiente de la capacidad. Recientemente, yo mismo he estado en el papel del olvidadizo y encontré un problema similar en Apache Arrow(esta es una dependencia de Vaex, por lo que cuando GIL no está deshabilitado en Arrow, nosotros (y todos los demás) experimentamos un impacto en el rendimiento).
Además, cuando se ejecuta en 64 núcleos, el rendimiento de Vaex a veces está lejos de ser ideal. Puede estar usando 4000% de la CPU en lugar de 6400%, lo que no me conviene. En lugar de insertar interruptores al azar para estudiar este efecto, quiero entender qué está sucediendo y, si el problema está en el GIL, quiero entender por qué y cómo ralentiza Vaex.
Porque estoy escribiendo esto
Planeo escribir una serie de artículos que cubran algunas de las herramientas y técnicas para perfilar y rastrear Python con extensiones nativas, y cómo estas herramientas se pueden combinar para analizar y visualizar el rendimiento de Python con GIL habilitado y deshabilitado.
Con suerte, esto ayudará a mejorar el seguimiento, la creación de perfiles y otras medidas de rendimiento en el ecosistema del lenguaje, así como el rendimiento de todo el ecosistema de Python.
Requisitos
Linux
Necesita acceso de root a la máquina Linux (sudo es suficiente). O pídale a su administrador de sistemas que ejecute los siguientes comandos por usted. Para el resto de este artículo, los privilegios de usuario son suficientes.
Perf
Asegúrese de tener perf instalado, por ejemplo, en Ubuntu, puede hacerlo así:
$ sudo yum install perf
Configuración del kernel
Ejecutar como usuario:
# Enable users to run perf (use at own risk)
$ sudo sysctl kernel.perf_event_paranoid=-1
# Enable users to see schedule trace events:
$ sudo mount -o remount,mode=755 /sys/kernel/debug
$ sudo mount -o remount,mode=755 /sys/kernel/debug/tracing
Paquetes de Python
Usaremos VizTracer y per4m
$ pip install "viztracer>=0.11.2" "per4m>=0.1,<0.2"
Seguimiento del estado de subprocesos y procesos con perf
No hay forma de averiguar el estado de GIL en Python (aparte de usar el sondeo ) porque no hay una API para eso. Podemos monitorear el estado desde el kernel, y para eso necesitamos la herramienta perf .
Con su ayuda (también conocida como perf_events), podemos escuchar los cambios en el estado de los procesos y subprocesos (solo estamos interesados en la suspensión y la ejecución) y registrarlos. Perf puede parecer intimidante, pero es una herramienta poderosa. Si quieres saber más al respecto, te recomiendo leer el artículo de Julia Evans o el sitio web de Brendan Gregg .
Para sintonizarnos, primero apliquemos perf a un programa simple :
import time
from threading import Thread
def sleep_a_bit():
time.sleep(1)
def main():
t = Thread(target=sleep_a_bit)
t.start()
t.join()
main()
Solo escuchamos algunos eventos para reducir el ruido (tenga en cuenta el uso de comodines):
$ perf record -e sched:sched_switch -e sched:sched_process_fork \
-e 'sched:sched_wak*' -- python -m per4m.example0
[ perf record: Woken up 2 times to write data ]
[ perf record: Captured and wrote 0,032 MB perf.data (33 samples) ]
Y usaremos el comando de script perf para generar un resultado legible adecuado para el análisis.
Texto oculto
$ perf script
:3040108 3040108 [032] 5563910.979408: sched:sched_waking: comm=perf pid=3040114 prio=120 target_cpu=031
:3040108 3040108 [032] 5563910.979431: sched:sched_wakeup: comm=perf pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563910.995616: sched:sched_waking: comm=kworker/31:1 pid=2502104 prio=120 target_cpu=031
python 3040114 [031] 5563910.995618: sched:sched_wakeup: comm=kworker/31:1 pid=2502104 prio=120 target_cpu=031
python 3040114 [031] 5563910.995621: sched:sched_waking: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563910.995622: sched:sched_wakeup: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563910.995624: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=R+ ==> next_comm=kworker/31:1 next_pid=2502104 next_prio=120
python 3040114 [031] 5563911.003612: sched:sched_waking: comm=kworker/32:1 pid=2467833 prio=120 target_cpu=032
python 3040114 [031] 5563911.003614: sched:sched_wakeup: comm=kworker/32:1 pid=2467833 prio=120 target_cpu=032
python 3040114 [031] 5563911.083609: sched:sched_waking: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563911.083612: sched:sched_wakeup: comm=ksoftirqd/31 pid=198 prio=120 target_cpu=031
python 3040114 [031] 5563911.083613: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=R ==> next_comm=ksoftirqd/31 next_pid=198 next_prio=120
python 3040114 [031] 5563911.108984: sched:sched_waking: comm=node pid=2446812 prio=120 target_cpu=045
python 3040114 [031] 5563911.109059: sched:sched_waking: comm=node pid=2446812 prio=120 target_cpu=045
python 3040114 [031] 5563911.112250: sched:sched_process_fork: comm=python pid=3040114 child_comm=python child_pid=3040116
python 3040114 [031] 5563911.112260: sched:sched_wakeup_new: comm=python pid=3040116 prio=120 target_cpu=037
python 3040114 [031] 5563911.112262: sched:sched_wakeup_new: comm=python pid=3040116 prio=120 target_cpu=037
python 3040114 [031] 5563911.112273: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
python 3040116 [037] 5563911.112418: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112450: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112473: sched:sched_wake_idle_without_ipi: cpu=31
swapper 0 [031] 5563911.112476: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563911.112485: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
python 3040116 [037] 5563911.112485: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112489: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563911.112496: sched:sched_switch: prev_comm=python prev_pid=3040116 prev_prio=120 prev_state=S ==> next_comm=swapper/37 next_pid=0 next_prio=120
swapper 0 [031] 5563911.112497: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
python 3040114 [031] 5563911.112513: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
swapper 0 [037] 5563912.113490: sched:sched_waking: comm=python pid=3040116 prio=120 target_cpu=037
swapper 0 [037] 5563912.113529: sched:sched_wakeup: comm=python pid=3040116 prio=120 target_cpu=037
python 3040116 [037] 5563912.113595: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
python 3040116 [037] 5563912.113620: sched:sched_waking: comm=python pid=3040114 prio=120 target_cpu=031
swapper 0 [031] 5563912.113697: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
Eche un vistazo a la cuarta columna (tiempo en segundos): el programa se quedó dormido (pasó un segundo). Aquí vemos la entrada al estado de reposo:
python 3040114 [031] 5563911.112513: sched:sched_switch: prev_comm=python prev_pid=3040114 prev_prio=120 prev_state=S ==> next_comm=swapper/31 next_pid=0 next_prio=120
Esto significa que el kernel ha cambiado el estado del hilo de Python a
S
(= durmiendo).
Un segundo después, el programa se despertó:
swapper 0 [031] 5563912.113697: sched:sched_wakeup: comm=python pid=3040114 prio=120 target_cpu=031
Por supuesto, para comprender lo que está sucediendo, deberá recopilar las herramientas. Sí, el resultado también se puede analizar fácilmente usando per4m , pero antes de continuar, quiero visualizar el flujo de un programa un poco más complejo usando VizTracer .
VizTracer
Es un trazador de Python capaz de visualizar el trabajo que está haciendo un programa en un navegador. Apliquémoslo a un programa más complejo :
import threading
import time
def some_computation():
total = 0
for i in range(1_000_000):
total += i
return total
def main():
thread1 = threading.Thread(target=some_computation)
thread2 = threading.Thread(target=some_computation)
thread1.start()
thread2.start()
time.sleep(0.2)
for thread in [thread1, thread2]:
thread.join()
main()
El resultado de la operación del trazador:
$ viztracer -o example1.html --ignore_frozen -m per4m.example1 Loading finish Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ... Dumping trace data to json, total entries: 94, estimated json file size: 11.0KiB Generating HTML report Report saved.
Así es como se ve el HTML resultante:
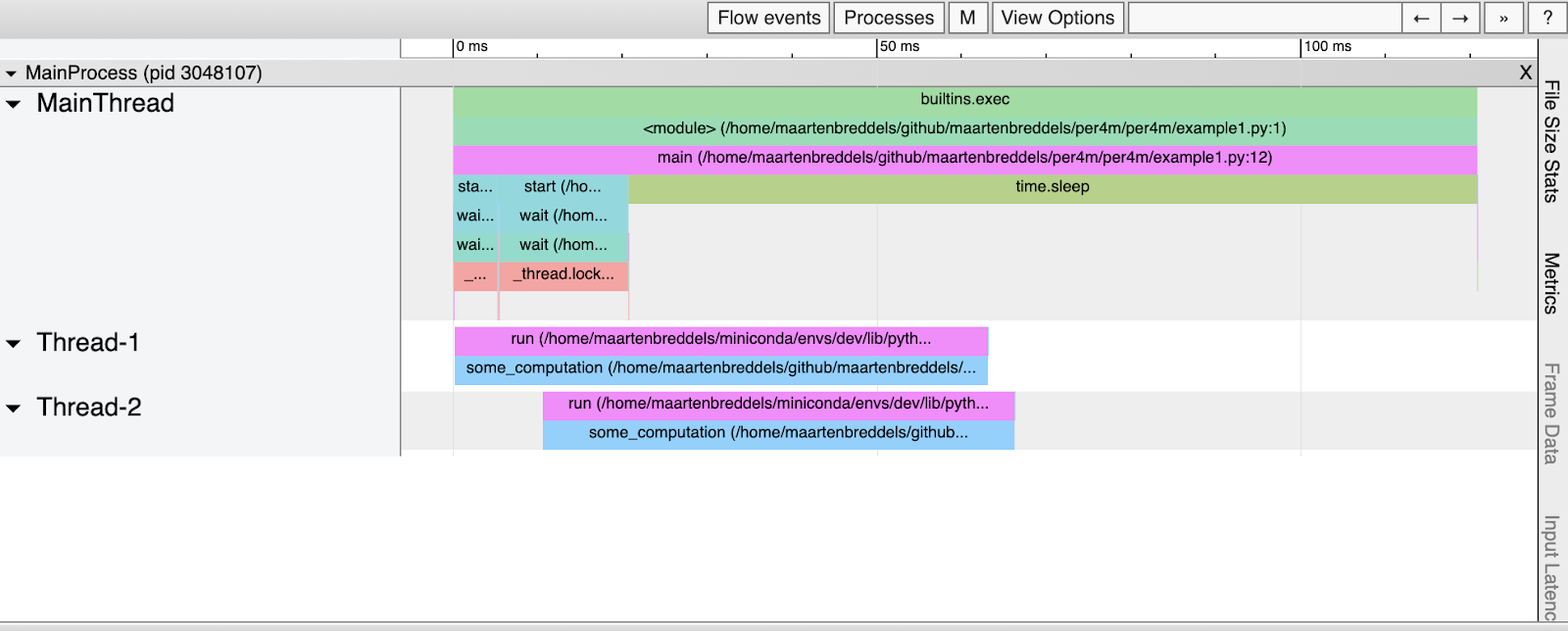
Parece que se ha
some_computation
ejecutado en paralelo (dos veces), aunque sabemos que el GIL lo impide. ¿Que está pasando aqui?
Combinando VizTracer y resultados de rendimiento
Apliquemos perf como en example0.py. Solo que ahora agreguemos un argumento
-k CLOCK_MONOTONIC
para usar el mismo reloj que VizTracer y pedirle que genere JSON en lugar de HTML:
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*' \
-k CLOCK_MONOTONIC -- viztracer -o viztracer1.json --ignore_frozen -m per4m.example1
Luego usamos per4m para convertir los resultados del script perf a JSON que VizTracer pueda leer:
$ perf script | per4m perf2trace sched -o perf1.json
Wrote to perf1.json
Ahora, usando VizTracer, combinemos los dos archivos JSON:
$ viztracer --combine perf1.json viztracer1.json -o example1_state.html Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ... Dumping trace data to json, total entries: 131, estimated json file size: 15.4KiB Generating HTML report Report saved.
Esto es lo que tenemos:
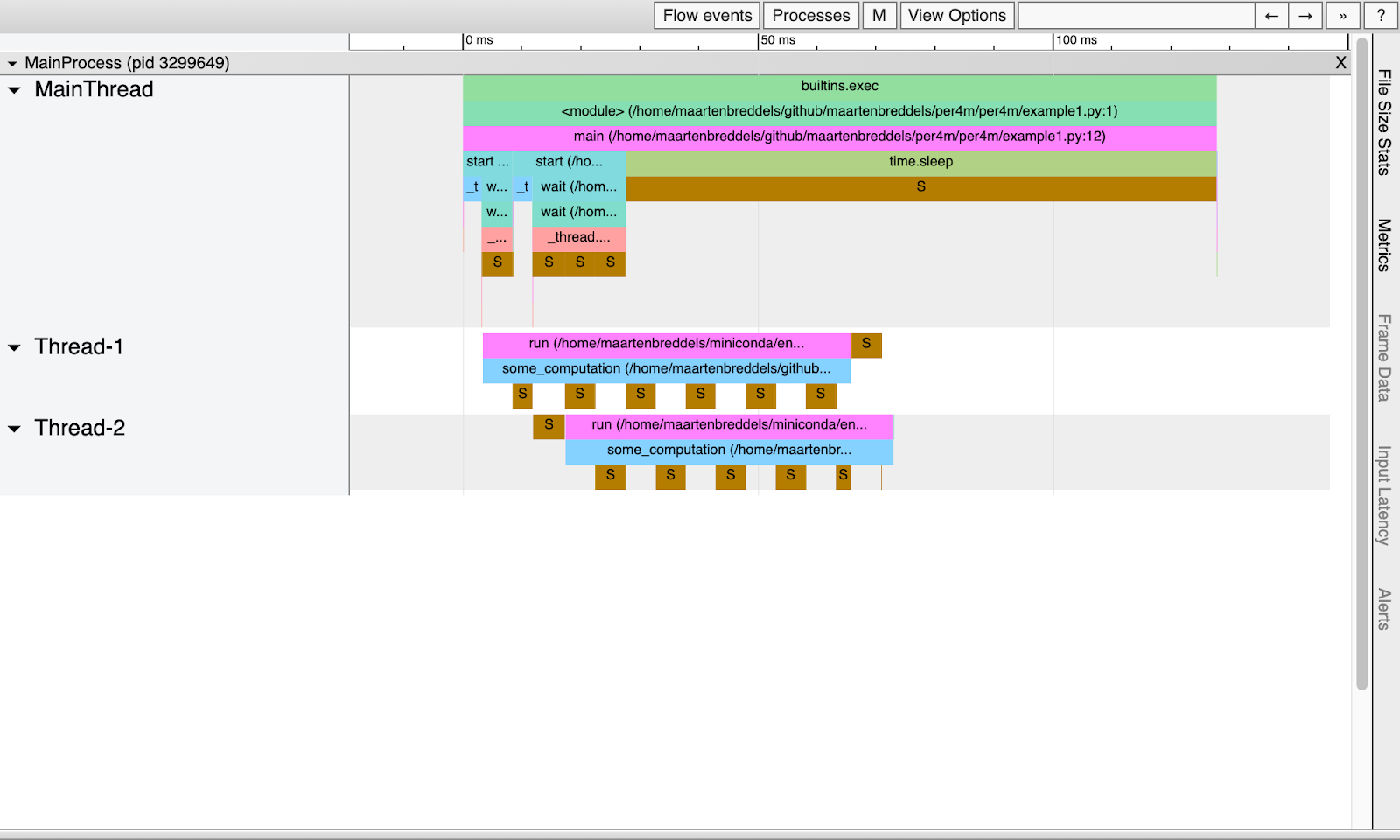
Obviamente, los subprocesos duermen regularmente debido al GIL y no se ejecutan en paralelo.
Nota : la fase de suspensión dura unos 5 ms , lo que corresponde al intervalo predeterminado sys.getswitch
Definición de GIL
Nuestro proceso se va a dormir, pero no vemos la diferencia entre los estados de sueño que se inician con una llamada
time.sleep
o el GIL. Hay varias formas de notar la diferencia, veamos dos de ellas.
A través del rastro de la pila
Con ayuda
perf record -g
(o mejor
perf record --call-graph dwarf
, eso implica
-g
), obtenemos los seguimientos de pila para cada evento de rendimiento.
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*'\
-k CLOCK_MONOTONIC --call-graph dwarf -- viztracer -o viztracer1-gil.json --ignore_frozen -m per4m.example1
Loading finish
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/viztracer1-gil.json ...
Dumping trace data to json, total entries: 94, estimated json file size: 11.0KiB
Report saved.
[ perf record: Woken up 3 times to write data ]
[ perf record: Captured and wrote 0,991 MB perf.data (164 samples) ]
Al observar el resultado del script perf (que agregamos por razones de rendimiento
--no-inline
), obtenemos mucha información. Mira el evento de cambio de estado, ¡resulta que se llamó a take_gil !
Texto oculto
$ perf script --no-inline | less
...
viztracer 3306851 [059] 5614683.022539: sched:sched_switch: prev_comm=viztracer prev_pid=3306851 prev_prio=120 prev_state=S ==> next_comm=swapper/59 next_pid=0 next_prio=120
ffffffff96ed4785 __sched_text_start+0x375 ([kernel.kallsyms])
ffffffff96ed4785 __sched_text_start+0x375 ([kernel.kallsyms])
ffffffff96ed4b92 schedule+0x42 ([kernel.kallsyms])
ffffffff9654a51b futex_wait_queue_me+0xbb ([kernel.kallsyms])
ffffffff9654ac85 futex_wait+0x105 ([kernel.kallsyms])
ffffffff9654daff do_futex+0x10f ([kernel.kallsyms])
ffffffff9654dfef __x64_sys_futex+0x13f ([kernel.kallsyms])
ffffffff964044c7 do_syscall_64+0x57 ([kernel.kallsyms])
ffffffff9700008c entry_SYSCALL_64_after_hwframe+0x44 ([kernel.kallsyms])
7f4884b977b1<a href="https://www.maartenbreddels.com/cdn-cgi/l/email-protection"> [email protected]@GLIBC_2.3.2+0x271 (/usr/lib/x86_64-linux-gnu/libpthread-2.31.so)
55595c07fe6d take_gil+0x1ad (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfaa0b3 PyEval_RestoreThread+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c000872 lock_PyThread_acquire_lock+0x1d2 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe71f3 _PyMethodDef_RawFastCallKeywords+0x263 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7313 _PyCFunction_FastCallKeywords+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d657 call_function+0x3b7 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b00 _PyFunction_FastCallKeywords+0x520 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b00 _PyFunction_FastCallKeywords+0x520 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060ae4 _PyEval_EvalFrameDefault+0x3f4 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c074e5d builtin_exec+0x33d (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7078 _PyMethodDef_RawFastCallKeywords+0xe8 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfe7313 _PyCFunction_FastCallKeywords+0x23 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c066c39 _PyEval_EvalFrameDefault+0x6549 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb77e0 _PyEval_EvalCodeWithName+0xc80 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6b62 _PyFunction_FastCallKeywords+0x582 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c01d334 call_function+0x94 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060d00 _PyEval_EvalFrameDefault+0x610 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfd6766 _PyFunction_FastCallKeywords+0x186 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c060ae4 _PyEval_EvalFrameDefault+0x3f4 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb6db1 _PyEval_EvalCodeWithName+0x251 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595bfb81e2 PyEval_EvalCode+0x22 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0c51d1 run_mod+0x31 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0cf31d PyRun_FileExFlags+0x9d (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0cf50a PyRun_SimpleFileExFlags+0x1ba (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0d05f0 pymain_main+0x3e0 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
55595c0d067b _Py_UnixMain+0x3b (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
7f48849bc0b2 __libc_start_main+0xf2 (/usr/lib/x86_64-linux-gnu/libc-2.31.so)
55595c075100 _start+0x28 (/home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
…
Nota : también llamado
pthread_cond_timedwait
, es usado por https://github.com/sumerc/gilstats.py para eBPF si está interesado en otros mutex.
Otra nota : tenga en cuenta que aquí no hay ningún rastro de pila de Python, sino que tenemos
_PyEval_EvalFrameDefault
más. En el futuro, planeo escribir cómo insertar un seguimiento de pila.
La herramienta de conversión
per4m perf2trace
comprende esto y genera un resultado diferente cuando el seguimiento contiene
take_gil
:
$ perf script --no-inline | per4m perf2trace sched -o perf1-gil.json
Wrote to perf1-gil.json
$ viztracer --combine perf1-gil.json viztracer1-gil.json -o example1-gil.html
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1.html ...
Dumping trace data to json, total entries: 131, estimated json file size: 15.4KiB
Generating HTML report
Report saved.
Obtenemos:
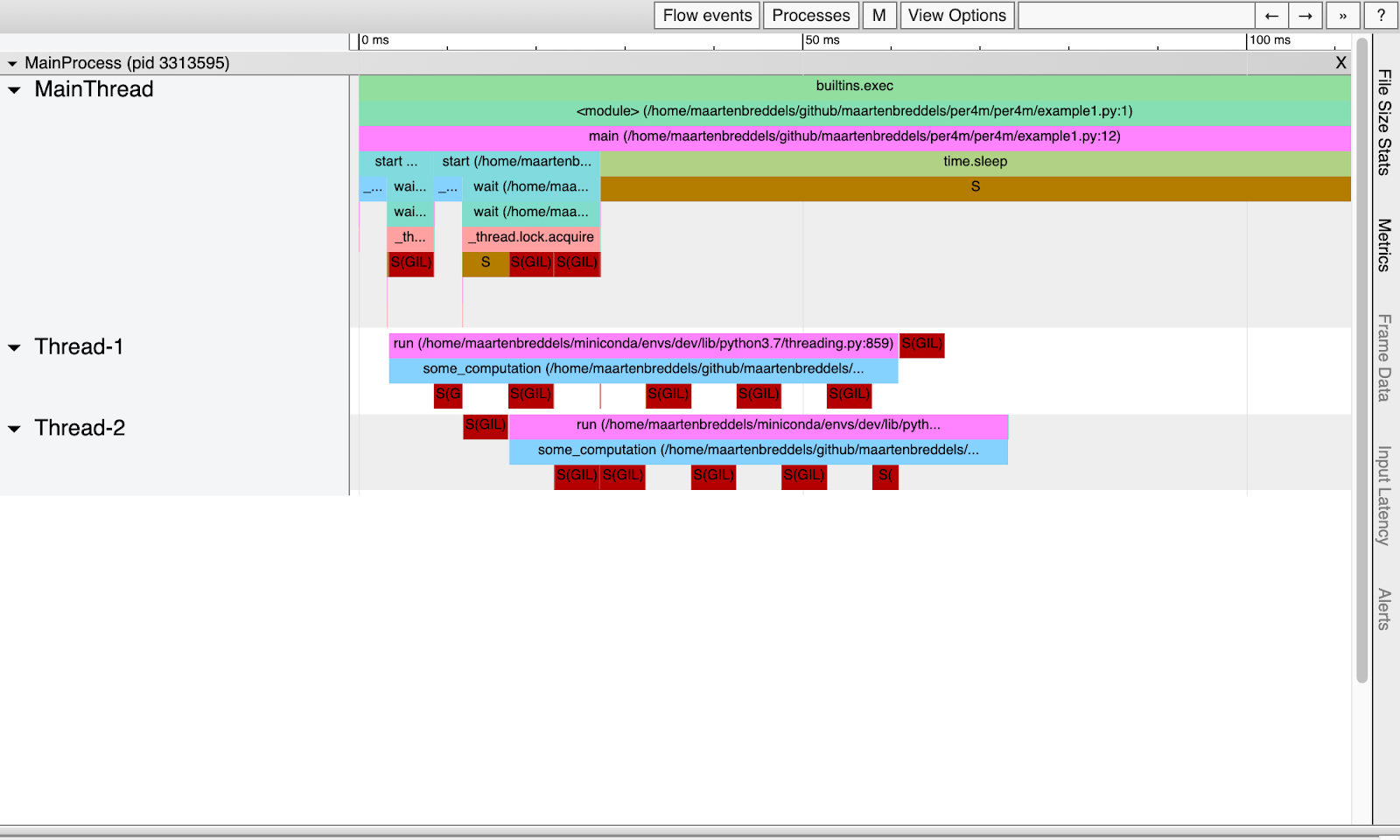
¡Ahora podemos ver exactamente dónde entra en juego el GIL!
A través de sondeo (kprobes / uprobes)
Sabemos cuándo los procesos se suspenden (debido al GIL u otras razones), pero si desea saber más sobre cuándo se enciende o apaga el GIL, necesita saber cuándo se llaman y devuelven los resultados
take_gil
y
drop_gil
. Esta traza se puede obtener probando con perf. En un entorno de usuario, las sondas son uprobes, que son análogas a kprobes, que, como habrás adivinado, funcionan en el entorno del kernel. Una vez más, Julia Evans es una gran fuente de información adicional .
Instale 4 sondas:
sudo perf probe -f -x `which python` python:take_gil=take_gil
sudo perf probe -f -x `which python` python:take_gil=take_gil%return
sudo perf probe -f -x `which python` python:drop_gil=drop_gil
sudo perf probe -f -x `which python` python:drop_gil=drop_gil%return
Added new events:
python:take_gil (on take_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
python:take_gil_1 (on take_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:take_gil_1 -aR sleep 1
Failed to find "take_gil%return",
because take_gil is an inlined function and has no return point.
Added new event:
python:take_gil__return (on take_gil%return in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:take_gil__return -aR sleep 1
Added new events:
python:drop_gil (on drop_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
python:drop_gil_1 (on drop_gil in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:drop_gil_1 -aR sleep 1
Failed to find "drop_gil%return",
because drop_gil is an inlined function and has no return point.
Added new event:
python:drop_gil__return (on drop_gil%return in /home/maartenbreddels/miniconda/envs/dev/bin/python3.7)
You can now use it in all perf tools, such as:
perf record -e python:drop_gil__return -aR sleep 1
Hay algunas quejas, y debido a las en línea
drop_gil
,
take_gil
se agregaron varias sondas / eventos (es decir, la función se presenta varias veces en el archivo binario), pero todo funciona.
Nota : Es posible que haya tenido suerte de que mi binario de Python (de conda-forge) se compiló para que el correspondiente
take_gil
/
drop_gil
(y sus resultados) funcionaran con éxito para resolver este problema.
Tenga en cuenta que las sondas no afectan el rendimiento, y solo cuando están "activas" (por ejemplo, cuando las monitoreamos desde perf), ejecutan el código en una rama diferente. Durante el monitoreo, las páginas afectadas se copian para el proceso monitoreado y los puntos de control se insertan en los lugares correctos.(INT3 para procesadores x86). El punto de control dispara un evento para rendimiento con poca sobrecarga. Si desea eliminar las sondas, ejecute el comando:
$ sudo perf probe --del 'python*'
Ahora perf conoce los nuevos eventos que puede escuchar, así que vamos a ejecutarlo nuevamente con un argumento adicional
-e 'python:*gil*'
:
$ perf record -e sched:sched_switch -e sched:sched_process_fork -e 'sched:sched_wak*' -k CLOCK_MONOTONIC \
-e 'python:*gil*' -- viztracer -o viztracer1-uprobes.json --ignore_frozen -m per4m.example1
Nota : lo eliminamos
--call-graph dwarf
, de lo contrario, el rendimiento no llegará a tiempo y perderemos eventos.
Luego, usando per4m perf2trace, lo convertimos a JSON, que es comprensible para VizTracer, y al mismo tiempo obtenemos nuevas estadísticas.
$ perf script --no-inline | per4m perf2trace gil -o perf1-uprobes.json
...
Summary of threads:
PID total(us) no gil% has gil% gil wait%
-------- ----------- ----------- ------------ -------------
3353567* 164490.0 65.9 27.3 6.7
3353569 66560.0 0.3 48.2 51.5
3353570 60900.0 0.0 56.4 43.6
High 'no gil' is good, we like low 'has gil',
and we don't want 'gil wait'. (* indicates main thread)
...
Wrote to perf1-uprobes.json
El subcomando
per4m perf2trace gil
también da como resultado gil_load . De él, aprendemos que ambos hilos esperan el GIL aproximadamente la mitad del tiempo, como se esperaba.
Con el mismo archivo perf.data registrado por perf, también podemos generar información sobre el estado de un hilo o proceso. Pero como estábamos ejecutando sin seguimiento de pila, no sabemos si el proceso se suspendió debido al GIL o no.
$ perf script --no-inline | per4m perf2trace sched -o perf1-state.json
Wrote to perf1-state.json
Finalmente, juntemos los tres resultados:
$ viztracer --combine perf1-state.json perf1-uprobes.json viztracer1-uprobes.json -o example1-uprobes.html Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example1-uprobes.html ... Dumping trace data to json, total entries: 10484, estimated json file size: 1.2MiB Generating HTML report Report saved.
VizTracer da una buena idea de quién tenía el GIL y quién lo estaba esperando:

Encima de cada hilo se escribe cuando el hilo o proceso espera el GIL y cuando está encendido (marcado como LOCK). Tenga en cuenta que estos períodos se superponen con períodos en los que el hilo o proceso está activo (¡en ejecución!). También tenga en cuenta que solo vemos un hilo o proceso en el estado de ejecución, como debería ser debido al GIL.
El tiempo entre llamadas
take_gil
, es decir, entre bloqueos (y por lo tanto entre dormir o despertarse), es exactamente el mismo que en la tabla anterior en la columna gil wait%. La duración de activación de GIL para cada hilo, etiquetado LOCK, corresponde al tiempo en la columna de gil%.
Liberando el Kraken ... ghm, GIL
Hemos visto cómo, cuando un programa Python puro es multiproceso, GIL limita el rendimiento al permitir que solo se ejecute un hilo o proceso a la vez (para un proceso Python, por supuesto, y posiblemente en el futuro para un (sub) intérprete) . Ahora veamos qué sucede si deshabilita el GIL, como sucede cuando se ejecutan funciones de NumPy.
El segundo ejemplo se ejecuta
some_numpy_computation
que llama a la función NumPy M = 4 veces en paralelo en dos subprocesos, mientras que el subproceso principal ejecuta código Python puro.
import threading
import time
import numpy as np
N = 1024*1024*32
M = 4
x = np.arange(N, dtype='f8')
def some_numpy_computation():
total = 0
for i in range(M):
total += x.sum()
return total
def main(args=None):
thread1 = threading.Thread(target=some_numpy_computation)
thread2 = threading.Thread(target=some_numpy_computation)
thread1.start()
thread2.start()
total = 0
for i in range(2_000_000):
total += i
for thread in [thread1, thread2]:
thread.join()
main()
En lugar de ejecutar este script con perf y VizTracer, usaremos una utilidad
per4m giltracer
que automatiza todos los pasos anteriores. Ella lo hará un poco más inteligente. Básicamente, ejecutaremos perf dos veces, una vez sin un seguimiento de pila y la segunda vez con él, e importaremos el módulo / script antes de ejecutar su función principal para deshacernos de un seguimiento poco interesante como la misma importación. Esto sucederá lo suficientemente rápido para que no perdamos eventos.
$ giltracer --state-detect -o example2-uprobes.html -m per4m.example2 ...
Totales de transmisiones:
PID total(us) no gil% has gil% gil wait%
-------- ----------- ----------- ------------ -------------
3373601* 1359990.0 95.8 4.2 0.1
3373683 60276.4 84.6 2.2 13.2
3373684 57324.0 89.2 1.9 8.9
High 'no gil' is good, we like low 'has gil',
and we don't want 'gil wait'. (* indicates main thread)
...
Saving report to /home/maartenbreddels/github/maartenbreddels/per4m/example2-uprobes.html ...
...
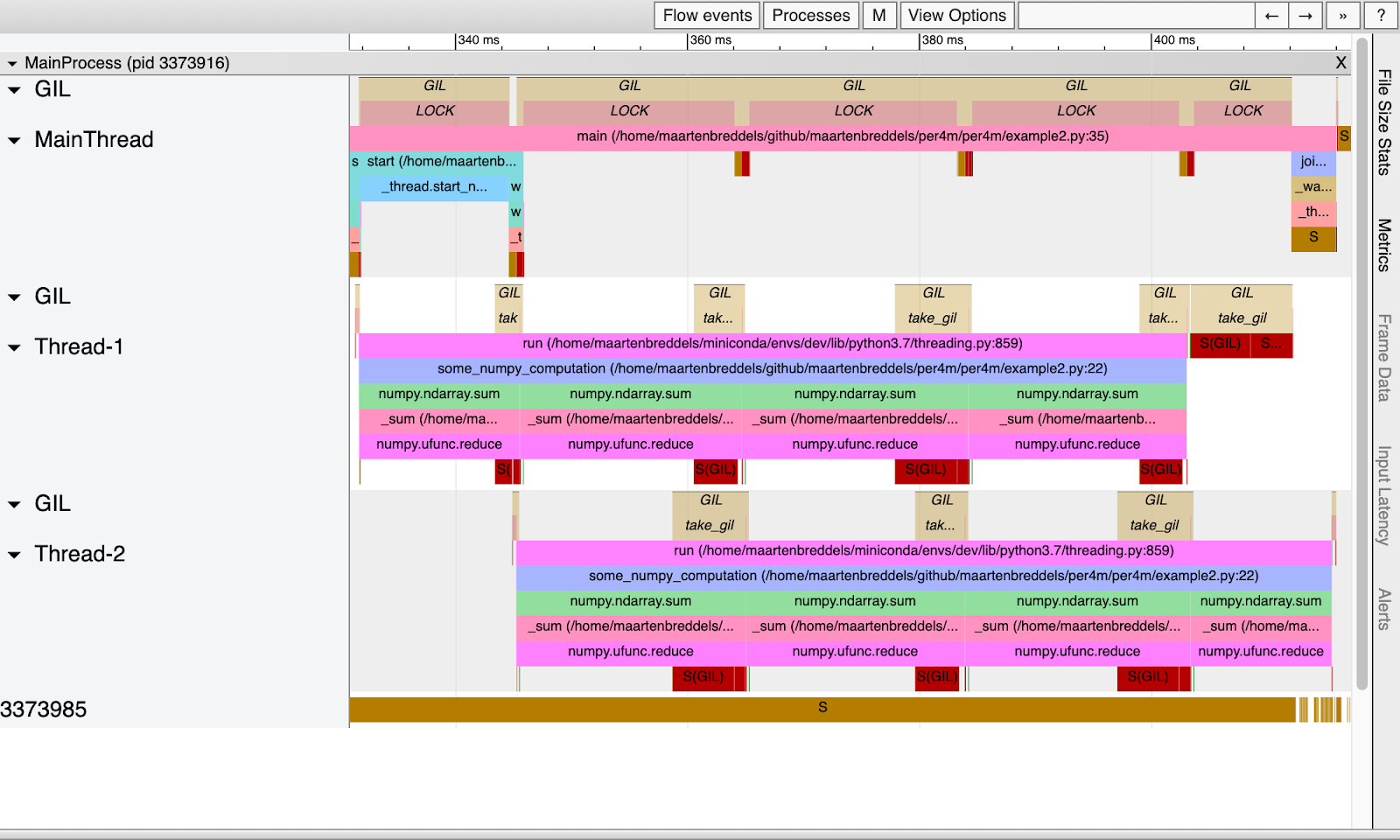
Aunque el subproceso principal ejecuta código Python (GIL está habilitado para ello, que se indica con la palabra LOCK), otros subprocesos también se ejecutan en paralelo. Tenga en cuenta que en el ejemplo puro de Python, tenemos un hilo o proceso ejecutándose al mismo tiempo. Y aquí, en realidad, se ejecutan tres hilos en paralelo. Esto es posible porque las rutinas NumPy incluidas con C / C ++ / Fortran desactivaron el GIL.
Sin embargo, el GIL todavía afecta a los subprocesos, porque cuando la función NumPy vuelve a Python, necesita obtener el GIL nuevamente, como se ve en los bloques largos
take_gil
. Esto toma el 10% del tiempo de cada hilo.
Integración con Jupyter
Dado que mi flujo de trabajo a menudo implica ejecutar un MacBook (que no ejecuta perf, pero admite dtrace) conectado a una máquina Linux de forma remota, utilizo el portátil Jupyter para ejecutar el código de forma remota. Y como soy desarrollador de Jupyter, tuve que hacer una envoltura con
cell magic
.
# this registers the giltracer cell magic
%load_ext per4m
%%giltracer
# this call the main define above, but this can also be a multiline code cell
main()
Saving report to /tmp/tmpvi8zw9ut/viztracer.json ...
Dumping trace data to json, total entries: 117, estimated json file size: 13.7KiB
Report saved.
[ perf record: Woken up 1 times to write data ]
[ perf record: Captured and wrote 0,094 MB /tmp/tmpvi8zw9ut/perf.data (244 samples) ]
Wait for perf to finish...
perf script -i /tmp/tmpvi8zw9ut/perf.data --no-inline --ns | per4m perf2trace gil -o /tmp/tmpvi8zw9ut/giltracer.json -q -v
Saving report to /home/maartenbreddels/github/maartenbreddels/fastblog/_notebooks/giltracer.html ...
Dumping trace data to json, total entries: 849, estimated json file size: 99.5KiB
Generating HTML report
Report saved.
Descargue giltracer.html
Abra giltracer.html en una nueva pestaña (puede que no funcione debido a la seguridad)
Conclusión
Con perf, podemos determinar los estados de procesos o subprocesos, lo que ayuda a comprender cuál de ellos tiene el GIL habilitado en Python. Y con la ayuda de los seguimientos de pila, puede determinar que el GIL fue la causa del sueño, y no
time.sleep
, por ejemplo.
La combinación de uprobes con perf le permite rastrear la invocación y la devolución de los resultados de la función
take_gil
y obtener
drop_gil
aún más información sobre el impacto de GIL en su programa Python.
Nuestro trabajo se ve facilitado por el paquete experimental per4m, que convierte el script perf al formato JSON VizTracer, así como algunas herramientas de orquestación.
Mucho bukaf, no dominaba
Si solo desea ver el impacto del GIL, ejecute esto una vez:
sudo yum install perf
sudo sysctl kernel.perf_event_paranoid=-1
sudo mount -o remount,mode=755 /sys/kernel/debug
sudo mount -o remount,mode=755 /sys/kernel/debug/tracing
sudo perf probe -f -x `which python` python:take_gil=take_gil
sudo perf probe -f -x `which python` python:take_gil=take_gil%return
sudo perf probe -f -x `which python` python:drop_gil=drop_gil
sudo perf probe -f -x `which python` python:drop_gil=drop_gil%return
pip install "viztracer>=0.11.2" "per4m>=0.1,<0.2"
Ejemplo de uso:
# module
$ giltracer per4m/example2.py
# script
$ giltracer -m per4m.example2
# add thread/process state detection
$ giltracer --state-detect -m per4m.example2
# without uprobes (in case that fails)
$ giltracer --state-detect --no-gil-detect -m per4m.example2
Planes futuros
Ojalá no tuviera que desarrollar estas herramientas. Con suerte, pude inspirar a alguien a crear mejores productos que el mío. Quiero centrarme en escribir código de alto rendimiento. Sin embargo, tengo esos planes para el futuro:
- Busque un medidor de rendimiento en VizTracer para ver las pérdidas de caché o el tiempo de inactividad del proceso.
- Implemente el seguimiento de la pila de Python en los seguimientos de rendimiento para combinar con herramientas como http://www.brendangregg.com/offcpuanalysis.html
- Repita el mismo ejercicio con dtrace para usar en macOS.
- Detecta automáticamente qué funciones de C no deshabilitan el GIL ( https://github.com/vaexio/vaex/pull/1114 , https://github.com/apache/arrow/pull/7756 )
- , https://github.com/h5py/h5py/issues/1516