 Es conveniente fotografiar una página de un pasaporte, una tarjeta de visita de un colega, un acuerdo con un banco o un cheque de un restaurante en un teléfono inteligente. Los documentos importantes están siempre a mano y se pueden imprimir o enviar. Pero encontrar rápidamente los archivos que necesita en la galería de teléfonos móviles es cada vez más difícil. Por regla general, los usuarios acumulan toda una colección de memes e imágenes con gatos mezclados con fotografías de facturas de luz, SNILS, etc. Los empleados de empresas, por ejemplo, directores de campo de un banco o un despacho de abogados, también tienen situaciones similares. Solo que en lugar de imágenes de coños, cientos de fotografías de acuerdos con clientes y otros documentos. ¿Cómo encontrar la copia necesaria para enviar a los colegas en la oficina, o cómo imprimir una foto de una licencia de conducir en la escala correcta y no en todo el A4? Tendremos que jugar.
Es conveniente fotografiar una página de un pasaporte, una tarjeta de visita de un colega, un acuerdo con un banco o un cheque de un restaurante en un teléfono inteligente. Los documentos importantes están siempre a mano y se pueden imprimir o enviar. Pero encontrar rápidamente los archivos que necesita en la galería de teléfonos móviles es cada vez más difícil. Por regla general, los usuarios acumulan toda una colección de memes e imágenes con gatos mezclados con fotografías de facturas de luz, SNILS, etc. Los empleados de empresas, por ejemplo, directores de campo de un banco o un despacho de abogados, también tienen situaciones similares. Solo que en lugar de imágenes de coños, cientos de fotografías de acuerdos con clientes y otros documentos. ¿Cómo encontrar la copia necesaria para enviar a los colegas en la oficina, o cómo imprimir una foto de una licencia de conducir en la escala correcta y no en todo el A4? Tendremos que jugar.
Es mucho más fácil realizar todas estas tareas con una sola aplicación. Es por eso que hemos actualizado ABBYY FineScanner AI . Ahora puede ordenar automáticamente las fotos de la galería del teléfono inteligente en 7 grupos de documentos y buscar rápidamente las fotos necesarias mediante consultas de texto.
Hoy le contaremos en detalle cómo creamos cada una de estas funciones, qué tecnologías usamos y cómo el marco ABBYY NeoML ayudó en esto. También mostraremos cómo funciona en la aplicación. Y al final, compartiremos nuestros planes para el desarrollo de FineScanner y le haremos algunas preguntas.
Pon todo en los estantes de los papis
Según un estudio de Appsflyer , el uso de dispositivos móviles y las descargas de aplicaciones, incluidos los que no son juegos , se dispararon en 2020. Para trabajar juntos de forma remota, los empleados no solo necesitan mensajeros corporativos, sino también herramientas móviles convenientes para el procesamiento eficiente de la información, impresión, flujo de trabajo remoto y almacenamiento de datos.
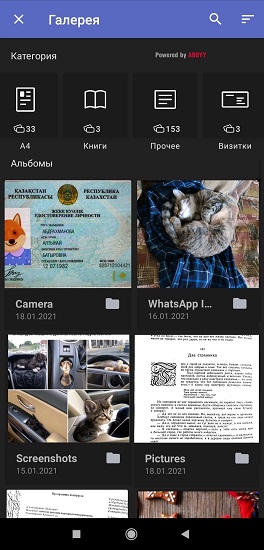
Según las encuestas de los usuarios de FineScanner y las entrevistas con ellos, la mayoría de las veces se escanean con la aplicación páginas A4 de una o varias páginas (contratos, facturas, cartas oficiales, etc.), pasaportes y licencias de conducir, libros, cheques y tarjetas de visita. El 40% de los encuestados toma fotografías de documentos aproximadamente una vez al mes y el 20%, una vez a la semana. Basándonos en estadísticas, hemos compilado una lista de los tipos de documentos que los usuarios toman con mayor frecuencia con una cámara y almacenan en la galería de teléfonos inteligentes para ellos mismos o para el trabajo. Y luego le enseñamos a FineScanner a dividir las fotos en grupos. El proceso consta de dos etapas, se lleva a cabo íntegramente en segundo plano y no requiere conexión a Internet.
uno). FineScanner primero clasifica las fotos de la galería del usuario
Después del primer lanzamiento de la aplicación y de recibir todos los permisos del usuario, las redes neuronales integradas analizan automáticamente las fotos en el teléfono inteligente y las distribuyen en 7 categorías: formato A4, libros, tarjetas de presentación, tarjetas de identidad, recibos, texto escrito a mano y “Otros” (carteles, postales se almacenan en esta carpeta, revistas en color, etc.).

Nuestra red neuronal en el motor ABBYY NeoML , de la que hablamos en detalle en Habré, está trabajando en la clasificación inteligente de imágenes . El mecanismo consta de dos redes neuronales: la primera detecta la presencia de texto en la imagen, la segunda determina los tipos de documentos. La arquitectura de la red se basa en bloques MobilenetV3.
Para nosotros era importante separar los documentos escritos a mano de los impresos, por lo que la primera cuadrícula divide los archivos en 3 clases:
- imagen con texto escrito a mano,
- imagen con texto impreso,
- imagen sin texto (gatos, selfies y el medio ambiente).
En la primera cuadrícula, usamos adicionalmente información sobre el recorte central (una parte de la imagen del centro, recortada en alta resolución) para determinar la presencia de texto en la imagen. Hicimos tal recorte, porque en la muestra (hablaremos un poco más abajo) en todas las fotos, el texto estaba principalmente en la parte central. Esta imagen se envía junto con la miniatura a una rama separada de la red y le ayuda a decidir si hay texto en la imagen o no.
La segunda cuadrícula define los tipos de documentos:
- Documento A4 (con algunos dibujos),
- 4 ( , — , ),
- ( - ),
- ( , , ),
- ,
- ID (, .) – , ,
- ( . ).
Nuestros empleados recopilaron y marcaron el conjunto de datos para el entrenamiento de redes neuronales. La muestra estuvo formada por unas 40 mil fotografías (tarjetas de visita, flyers, tarjetas bancarias, certificados, seguros, etc.) tomadas con un smartphone.
Debido a la red neuronal, el peso de la aplicación se ha incrementado de manera insignificante: solo 3 MB. Intentamos específicamente hacer que la red neuronal sea compacta. No quería inflar demasiado la aplicación por el bien de una característica tan "experimental".
2). Después de la clasificación, el texto se reconoce en las fotografías de documentos encontradas.
Para ello, utilizamos nuestra tecnología ABBYY Mobile Capture SDK , que funciona tanto en TextGrabber para OCR o secuencias de vídeo, como en Business Card Reader para procesar tarjetas de visita. FineScanner ha utilizado este SDK anteriormente para un reconocimiento rápido de documentos fuera de línea. Esta vez lo usamos al máximo: puede reconocer texto en miles de imágenes. Eso sí, intentamos hacerlo con suavidad y cuidado para que el proceso no cargue el dispositivo y no devore la batería. Además, hemos decidido no descargar las fotos del usuario subidas a las nubes por ahora, sino procesar solo las que están disponibles localmente en el dispositivo.
El tiempo total para todo el procesamiento de la galería depende de la cantidad de fotos y documentos entre ellos, así como de la generación del teléfono y es, en promedio, de 10 a 30 minutos por primera vez. En el futuro, solo se escanearán nuevas fotografías, y ya habrá muchas menos, no miles de piezas.
Encuentra un documento por su texto
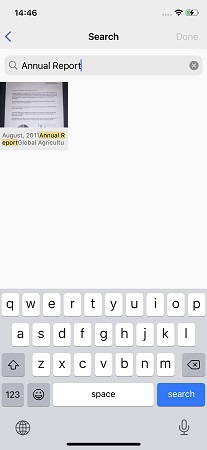 Ordenar imágenes por tipo es algo bueno, pero ¿qué pasa si hay cientos de imágenes en la carpeta Libros y necesita encontrar una, por ejemplo, una receta de shakshuka picante fotografiada de una enciclopedia culinaria poco común? ¿O encuentra en la carpeta A4 un contrato de alquiler firmado hace dos años?
Ordenar imágenes por tipo es algo bueno, pero ¿qué pasa si hay cientos de imágenes en la carpeta Libros y necesita encontrar una, por ejemplo, una receta de shakshuka picante fotografiada de una enciclopedia culinaria poco común? ¿O encuentra en la carpeta A4 un contrato de alquiler firmado hace dos años?
Para tales casos, le enseñamos a FineScanner cómo buscar el texto del documento. Además, la opción de búsqueda de una consulta exacta, palabra por palabra, se descartó de inmediato. Como regla general, no es difícil buscar texto en documentos bien fotografiados, pero en la galería de un teléfono inteligente puede haber cualquier cosa: fotos rotas o borrosas. No es difícil organizar la llamada "búsqueda clara" según ellos, pero los resultados serán tristes. Las mayúsculas (usando letras mayúsculas), por supuesto, pueden y deben ignorarse, pero hay, por ejemplo, errores de ortografía por parte de los usuarios al escribir una solicitud.
Para que la aplicación se tragara este espectro de errores, hicimos una "búsqueda difusa". No iban a escribir su propio motor de búsqueda completo, por lo que examinaron los enfoques y bibliotecas existentes. Como resultado, para resolver nuestro problema surgió un buen algoritmo de diferencias, Eugene Myers (el algoritmo de diferencias de Myer).
El algoritmo diff no se utiliza para buscar, sino para comparar dos textos o dos versiones del mismo documento.
Tomaron la implementación terminada de aquí . Es cierto que tuve que agregar encima el cálculo de la distancia de Levenshtein entre la consulta de búsqueda y la subcadena encontrada y seleccionar los umbrales para que no hubiera opciones completamente salvajes. Como resultado, nuestra búsqueda de texto funciona de forma clara, rápida y en tiempo real.
Regla AR en la versión iOS, o cómo determinar el tamaño de un documento sin bailar con una pandereta
 Cuando desarrollamos nuevas funciones en FineScanner, tomamos en cuenta los deseos de los usuarios. Por ejemplo, a menudo necesitan imprimir documentos no solo de los tamaños habituales (A4, A5, A6, tarjeta de visita), sino también de los no estándar: folletos, volantes, SNILS, etc. Y con la impresión de dichos archivos, dificultades Surgen: por ejemplo, la foto se estira a todo el A4, aunque las proporciones originales son diferentes.
Cuando desarrollamos nuevas funciones en FineScanner, tomamos en cuenta los deseos de los usuarios. Por ejemplo, a menudo necesitan imprimir documentos no solo de los tamaños habituales (A4, A5, A6, tarjeta de visita), sino también de los no estándar: folletos, volantes, SNILS, etc. Y con la impresión de dichos archivos, dificultades Surgen: por ejemplo, la foto se estira a todo el A4, aunque las proporciones originales son diferentes.
Los tamaños de documento más comunes se pueden seleccionar de una lista preparada en el apéndice, hay 8 tipos de ellos. Cualquier otro: postales, visas, etc. - ahora se puede medir automáticamente. Para ello, hemos integrado ARKit (línea en realidad aumentada) en la nueva versión de FineScanner para iOS. Para su desarrollo, utilizamos la API de Apple junto con nuestro módulo de recorte ABBYY Mobile Capture SDK, que le permite definir límites de documentos incluso sobre un fondo blanco y completarlos si se cierran a mano. La regla determina el tamaño físico del documento para especificarlo en las propiedades y que se muestre correctamente en papel cuando se imprime en una impresora.
Así es como funciona:
Cómo nuestros clientes comerciales utilizan FineScanner
Nuestros clientes B2C serán los primeros en probar la nueva funcionalidad y las empresas comenzarán a utilizar la aplicación un poco más tarde. Esto se debe principalmente a las estrictas políticas de seguridad corporativas.
Nuestros clientes de grandes empresas utilizan sus versiones de ABBYY FineScanner bajo el control de varias plataformas MDM (Mobile Device Management, es decir, soluciones que le permiten configurar los niveles de protección de la información corporativa frente al acceso y distribución no autorizados, y también determinar si la información almacenados en un dispositivo móvil estarán disponibles para aplicaciones de terceros). Por ejemplo, el personal de auditoría o consultoría empresarial de PwC utiliza un escáner móvilpara la digitalización rápida de cualquier documento. Durante las auditorías, toman fotos de, por ejemplo, contratos u pedidos en solo unos segundos, las convierten a PDF con capacidad de búsqueda y las envían a los repositorios corporativos para verificación adicional y análisis de datos.
Para la comodidad de nuestros clientes, ahora nos estamos preparando para lanzar una versión de FineScanner compatible con los sistemas MDM más populares: Microsoft InTune, Mobile Iron, Workspace One y otros.
Para el futuro
Esperamos que el FineScanner actualizado ayude a simplificar las tareas de digitalización y reconocimiento de documentos y libros directamente en su teléfono inteligente, así como a encontrar rápidamente los archivos que necesita en la galería e imprimirlos.
Recopilamos regularmente las solicitudes de los usuarios de FineScanner para comprender cómo desarrollar aún más el producto. Según nuestra última encuesta, la mitad de los usuarios envían documentos fotografiados a su propio correo oa otro y continúan trabajando con ellos en la computadora, por ejemplo, imprimen o almacenan. Además, más del 70% espera que FineScanner se integre con ABBYY FineReader PDF . Nos resultó interesante descubrir qué piensan los jhabrovitas al respecto.