La forma habitual de paginación es por desplazamiento o número de página. Haces una solicitud como esta:
GET /api/products?page=10 {"items": [...100 products]}
y luego esto:
GET /api/products?page=11 {"items": [...another 100 products]}
En el caso de un simple desplazamiento, resulta
?offset=1000
y
?offset=1100
- los mismos huevos, solo de perfil. Aquí vamos directamente a la consulta SQL del tipo
OFFSET 1000 LIMIT 100
o multiplicamos por el tamaño de la página (valor
LIMIT
). De todos modos, esta no es una solución óptima, ya que cada base de datos debe omitir esas 1000 filas. Y para omitirlos, debe identificarlos. No importa si es PostgreSQL, ElasticSearch o MongoDB, tiene que ordenarlos, recalcularlos y desecharlos.
Este es un trabajo innecesario. Pero se repite una y otra vez, ya que este diseño es fácil de implementar: asigna directamente su API a una solicitud de base de datos.
Entonces, ¿qué se debe hacer? ¡Pudimos ver cómo funcionan las bases de datos! Tienen el concepto de cursor: es un puntero a una cadena. Para que pueda decirle a la base de datos: "Devuélvame 100 filas después de esto ". Y dicha consulta es mucho más conveniente para la base de datos, ya que existe una alta probabilidad de que esté identificando una fila por un campo con un índice. Y no necesita ir a buscar y saltarse estas líneas, pasará junto a ellas.
Ejemplo:
GET /api/products {"items": [...100 products], "cursor": "qWe"}
La API devuelve una cadena (opaca), que luego se puede usar para obtener la siguiente página:
GET /api/products?cursor=qWe {"items": [...100 products], "cursor": "qWr"}
En términos de implementación, hay muchas opciones. Normalmente, tiene algunos criterios de consulta, como una identificación de producto. En este caso, lo codifica con algún algoritmo reversible (digamos identificadores hash ). Y cuando recibe una consulta con un cursor, la decodifica y genera una consulta como
WHERE id > :cursor LIMIT 100
.
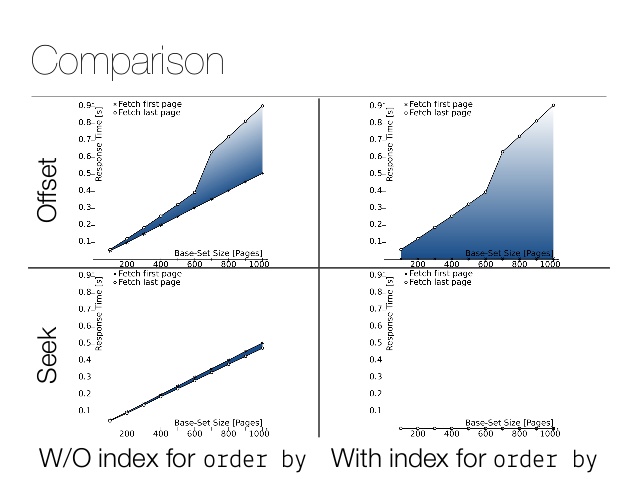
Pequeña comparación de rendimiento. Aquí está el resultado del desplazamiento: Y aquí está el resultado de la operación : ¡ La diferencia es de varios órdenes de magnitud! Por supuesto, los números reales dependen del tamaño de la tabla, los filtros y la implementación del almacenamiento. Aquí hay un gran artículo
=# explain analyze select id from product offset 10000 limit 100;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------
Limit (cost=1114.26..1125.40 rows=100 width=4) (actual time=39.431..39.561 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1274406.22 rows=11437243 width=4) (actual time=0.015..39.123 rows=10100 loops=1)
Planning Time: 0.117 ms
Execution Time: 39.589 ms
where
=# explain analyze select id from product where id > 10000 limit 100;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
Limit (cost=0.00..11.40 rows=100 width=4) (actual time=0.016..0.067 rows=100 loops=1)
-> Seq Scan on product (cost=0.00..1302999.32 rows=11429082 width=4) (actual time=0.015..0.052 rows=100 loops=1)
Filter: (id > 10000)
Planning Time: 0.164 ms
Execution Time: 0.094 ms
Para obtener más información técnica, consulte la diapositiva 42 para comparar el rendimiento.
Por supuesto, nadie consulta productos por ID; normalmente se les consulta por algún tipo de relevancia (y luego ID como parámetro decisivo ). En el mundo real, elegir una solución requiere mirar datos específicos. Las solicitudes se pueden ordenar por identificador (ya que aumenta monótonamente). Los artículos de la lista de compras futuras también se pueden clasificar de esta manera, para cuando se compile la lista. En nuestro caso, los productos se cargan desde ElasticSearch, que naturalmente admite tal cursor.
La desventaja es que no puede crear un enlace de página anterior utilizando la API sin estado. En el caso de la paginación del usuario, no hay forma de evitar este problema. Entonces, si es importante tener botones para la página anterior / siguiente y "Ir directamente a la página 10", entonces debe usar el método anterior. Pero en otros casos, el método by cursor puede mejorar significativamente el rendimiento, especialmente en tablas muy grandes con una paginación muy profunda.