
Para comprender el ADN empresarial de Huawei , es útil hacer primero un recorrido rápido por los desafíos que enfrentan las redes corporativas en la actualidad.
No hay duda de que la transformación digital no pasará por alto a ninguna gran organización. Y este proceso es impensable sin un apoyo de infraestructura digno. Para satisfacer las demandas de la digitalización, la red corporativa debe ser confiable, flexible y escalable.
Esta red tiene dos partes principales: una red de acceso y una red central. En el diagrama anterior, a la izquierda de la ubicación del equipo regional se encuentra la misma red de acceso diseñada para proporcionar conexión a campus corporativos, sucursales, estructuras externas, entornos de IoT, etc. A la derecha, se muestran las conexiones interregionales e "entre nubes".
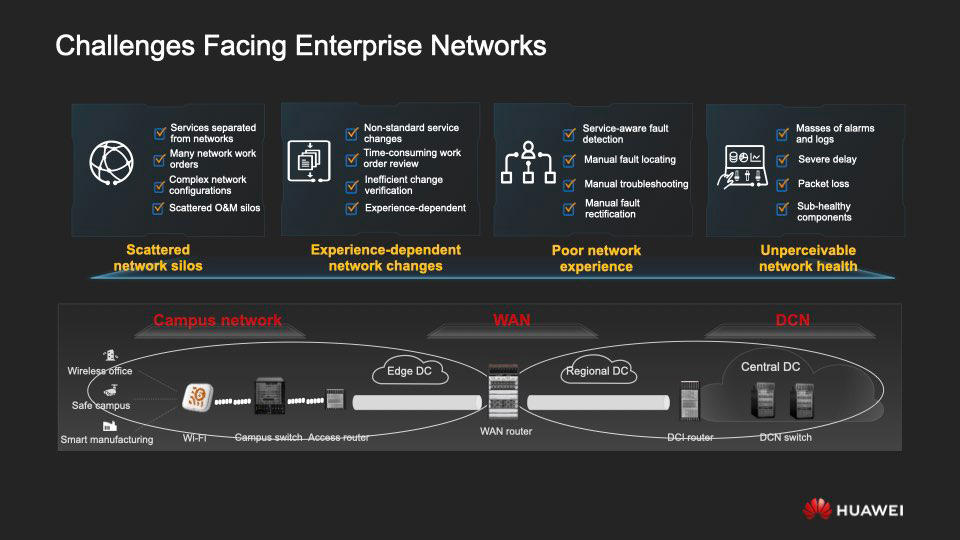
Aunque la arquitectura es fundamentalmente simple, en la práctica, por regla general, debe lidiar con una enorme red heterogénea basada en equipos de diferentes proveedores. Sus costos de operación y mantenimiento son a veces significativamente más altos que comprarlo. A continuación, presentamos cuatro factores agravantes importantes que dificultan la vida de los diseñadores y administradores de las redes corporativas modernas.
I. Los silos de red, que desconectan los servicios de la infraestructura de red, crean confusión con demasiadas tareas de red, la configuración de la red en sí se vuelve demasiado complicada y la operación y mantenimiento pierde eficiencia.
II. Un alto grado de heterogeneidad de la red, con su abigarrado parque de
equipos. Esto conduce a muchas dificultades, incluida la dependencia de la operación exitosa de la infraestructura de la experiencia de expertos individuales, ciclos prolongados de resolución de problemas, verificaciones ineficaces y errores causados por la necesidad de realizar una gran parte de las operaciones manualmente.
III. Separación de servicios a nivel empresarial e infraestructura de red.Como resultado, el pleno funcionamiento de NaaS (Red como Servicio) es imposible, ya sea en una zona separada o entre zonas de la red. En medio de una avalancha de innumerables métricas, alertas y registros de actividad de la red, el administrador no puede garantizar que los servicios funcionen sin problemas en un momento dado.
IV. Falta de visualización de redes de extremo a extremo y herramientas para su análisis integral. Es el verdadero flagelo de quienes construyen y operan redes. Las averías se revelan a menudo de forma deprimente directamente durante la operación de los servicios, los usuarios tienen tiempo para encontrarlas, ya que no pueden detectarse y eliminarse rápidamente.

Para abordar estos desafíos, Huawei ha creado una solución de red de conducción autónoma (ADN) llamada iMaster NCE. Contiene la funcionalidad de un "gemelo digital", análisis de intenciones de extremo a extremo (ya hemos escrito sobre el concepto de red impulsada por intenciones con más detalle en Habré ), así como la tecnología de toma de decisiones inteligente.
- El principio impulsado por la intención. A lo largo de la vida de una red, quienes la administran pueden usar herramientas WYSIWYG simples para mantener la red bajo control.
- Toma de decisiones inteligente. El sistema facilita que una persona elija las soluciones óptimas. Por ejemplo, en la etapa de implementación del servicio, es capaz de "solicitar" ajustes y configuraciones de red adecuados y, al analizar problemas, permite encontrar rápidamente la causa raíz del problema y sugiere pasos para eliminarlo.
- " Gemelo digital ". El iMaster NCE incluye una infraestructura de KPI de gestión y modelado de varios niveles basada en big data que opera con “instantáneas virtuales” de cualquier dispositivo físico en la red. En este caso, la solución realiza un mapeo bidireccional entre la red y su "gemelo".
Con la ayuda de ADN, son posibles cinco transformaciones importantes.
- «», , , , , . iMaster NCE .
- , , , . , O&M- .
- . , , , .
- «» . — , , — .
- Reemplazar el trabajo basado en el factor humano, principalmente en la experiencia de expertos, utilizando un modelo donde prevalece la toma de decisiones con la ayuda de tecnologías "inteligentes", incluso en el diseño de redes, monitoreo, análisis y optimización de las interacciones de la red.

Lo principal en el modelo de análisis basado en intención es la transferencia de las solicitudes comerciales de los usuarios a la capa de red. El proceso tiene tres componentes importantes.
- Formación de un modelo abstracto de intenciones (abstracción de intenciones). En las redes corporativas, la mayor parte de la intención se relaciona con las interacciones entre usuarios, dispositivos finales y aplicaciones. En consecuencia, se necesita un modelo que generalice sus requisitos a lo largo de todo el ciclo de vida de la red y asegure su personalización en base a un enfoque de escenarios.
- (intent conversion). - . .
- «» , , , , ., «», (solver), .
- - « ». , «» , .
- . . :
- ;
- - ;
- (SDN, OVS .);
- , .
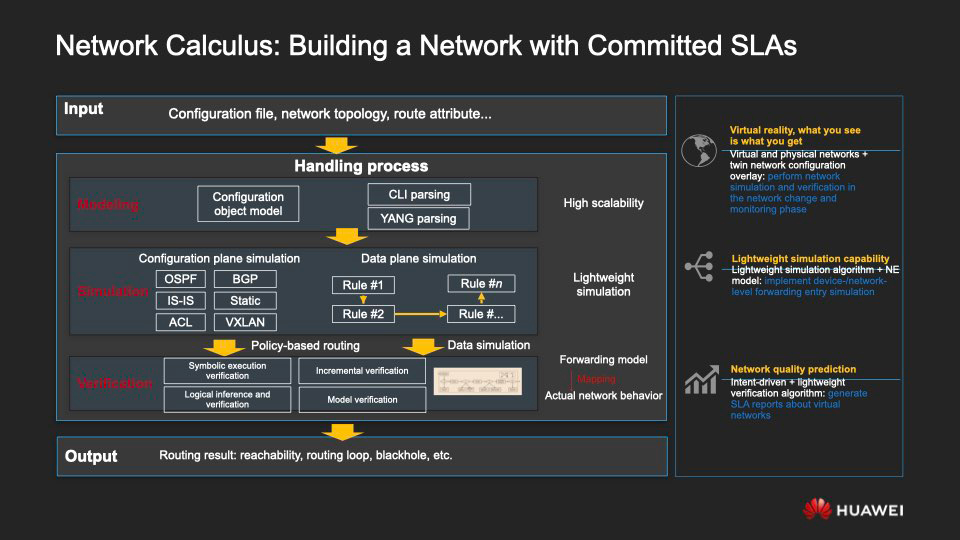
Pasemos a modelar lo que está sucediendo en la red, para qué escenarios está diseñada y por qué, usándola, se vuelve mucho más fácil construir redes manteniendo un nivel de servicio garantizado (SLA).
En esencia, simulamos la configuración de la red, los recursos y el sistema de reenvío para crear una red virtual que reflejará las características y los detalles del funcionamiento de la red real original.
Cuando trabajamos con una red virtual, utilizamos una prueba formal, un método matemático que nos permite verificar si la red cumple con los criterios de SLA, como conectividad de red estable, enrutamiento continuo, reenvío configurado correctamente, consistencia de políticas, latencia y niveles aceptables de pérdida de paquetes, etc. etc.
Echemos un vistazo rápido a los escenarios básicos para usar el método.
- El modelado integral de intenciones de extremo a extremo valida de manera proactiva la solución para garantizar que las nuevas intenciones no interrumpan los procesos que ya se están llevando a cabo en la red.
- Tras la implantación de la intención en la red corporativa, se comprueba si está funcionando como se esperaba y se monitorizan los riesgos de todo tipo de excesos, antes de que tengan tiempo de afectar el funcionamiento de los servicios.
- El comportamiento de la red virtual se verifica en escenarios que involucran una zona, en interzona, en híbrido (usando recursos en la nube, etc.), y nuevamente se puede aislar completamente de la red corporativa principal en modo automático.
En resumen, el análisis de la red se realiza en esta secuencia.
- Sobre la base de la topología de red existente y la información sobre los elementos de la red, se construye un modelo de control de la red virtual.
- Se utiliza una configuración de simulación para generar un sistema de reenvío de red virtual.
- Se utiliza un método de prueba formal para modelar el comportamiento de la red en todos los aspectos, tales como: configuración, asignación de recursos, enrutamiento.
- La plataforma sugiere algorítmicamente recomendaciones para realizar cambios en la red.

Una vez realizados todos estos pasos, entra en juego la tecnología de monitorización activa inteligente mencionada anteriormente. Está diseñado para digitalizar toda la infraestructura de la red de manera que sea posible la gestión integrada de su operación, soporte, optimización y posterior diseño.
Un par de ejemplos de cómo funciona esto. Digamos que alguna unidad de negocio de la empresa envía una señal de que han perdido el acceso a la aplicación. La plataforma iMaster NCE, principalmente a través del modelado de topología de red dinámica, facilita la consulta y visualización de todas las métricas relacionadas con una aplicación. Además, gracias al navegador de enrutamiento, es conveniente rastrear en todos los niveles de la red hacia dónde y hacia dónde se dirigía el tráfico, de acuerdo con el principio de extremo a extremo, hasta un dispositivo físico específico, como un teléfono inteligente (verifica el alcance de secciones y elementos de red, bucles y agujeros negros de enrutamiento etc.). A su vez, gracias a la compleja visualización del trabajo de las herramientas analíticas, se puede comprobar rápidamente si las entradas para dispositivos específicos en las tablas de enrutamiento están en orden,así como monitorear notificaciones, registros y registros de cambios de configuración. Y con la ayuda de una solución recomendada por el servicio RunBook (por supuesto, el administrador es libre de elegir hacer lo que crea conveniente), si es necesario, los componentes y servicios de la red se restauran rápidamente a la operatividad y se eliminan las fallas.
Otro escenario es verificar el estado de la red. Para esto, se utiliza un modelo con cinco niveles de control, cada uno de los cuales rastrea su propia porción de la infraestructura:
- ¿El equipo funciona de manera estable? ¿Son las placas, ventiladores, fuentes de alimentación, procesadores, memoria, etc.?
- si hay algún problema en las conexiones entre los dispositivos físicos que ingresan a la red, incluyendo si el estado del puerto y el tráfico son normales, la longitud de las colas y el coeficiente de atenuación óptica, si el porcentaje de paquetes "rotos" es demasiado alto, etc.
- si funciona la agregación M-LAG, el enrutamiento a través de OSPF, BGP, etc.
- todo está bien con la infraestructura de red impuesta, incluidos los estados actuales de BD, VNI, VRF, EVPN y SRV6;
- si la redirección se lleva a cabo regularmente a nivel de servicio y, en particular, cuáles son las configuraciones para la conexión TCP.
Hay dos tecnologías en el corazón de un servicio de monitoreo inteligente. El primero es el sistema "gemelo digital" mencionado anteriormente, que se basa en el modelado virtual de la situación de la red en tiempo real utilizando big data, lo que le permite rastrear fácilmente las relaciones causa-efecto y encontrar fuentes de dificultad. Para implementar esta mecánica es fundamental tener un modelo único para replicar el ciclo de vida de la red empresarial.
El segundo es un conjunto de soluciones de front-end y back-end que se utilizan para construir un mapa de alta precisión de la actividad de la red, que se basa en el concepto de un "gemelo digital". La parte frontal incluye búsqueda inteligente, detalles multinivel de informes analíticos, navegación de enrutamiento, un sistema de visualización de datos integrado, etc. El backend es principalmente un motor para reproducir dinámicamente la topología de la red y un sistema para la importación flexible de modelos de red de terceros.

El trabajo de monitoreo inteligente está respaldado por el uso de un método de análisis de red inteligente basado en gráficos de conocimiento.
Mediante el modelado, las descripciones abstractas de los elementos de la red pueden traducirse en consultas concretas en el plano del modelo de objetos.
Mediante telemetría, se monitorean los KPI de la red, los flujos de tráfico a nivel de servicio, la información de configuración y los registros de eventos de la red, y en base a esta información, los algoritmos de aprendizaje automático capturan las desviaciones de la norma sobre la marcha y las correlacionan con los datos del modelo de objeto.
Además, la plataforma iMaster NCE proporciona un entorno para resolver de forma segura las posibles consecuencias de todo tipo de fallas: los problemas que han ocurrido en otras redes de la vida real se "prueban" en la simulación de esta red en particular. Por lo tanto, recurriendo a la experiencia combinada de expertos que anteriormente lograron hacer frente a ciertas situaciones anormales de la red, entrenamos modelos ML para que ayuden de manera más efectiva a superar los excesos, incluida la identificación de patrones de nuevos problemas y, por lo tanto, la multiplicación de los conocimiento disponible para todas aquellas empresas que utilizan el iMaster NCE.
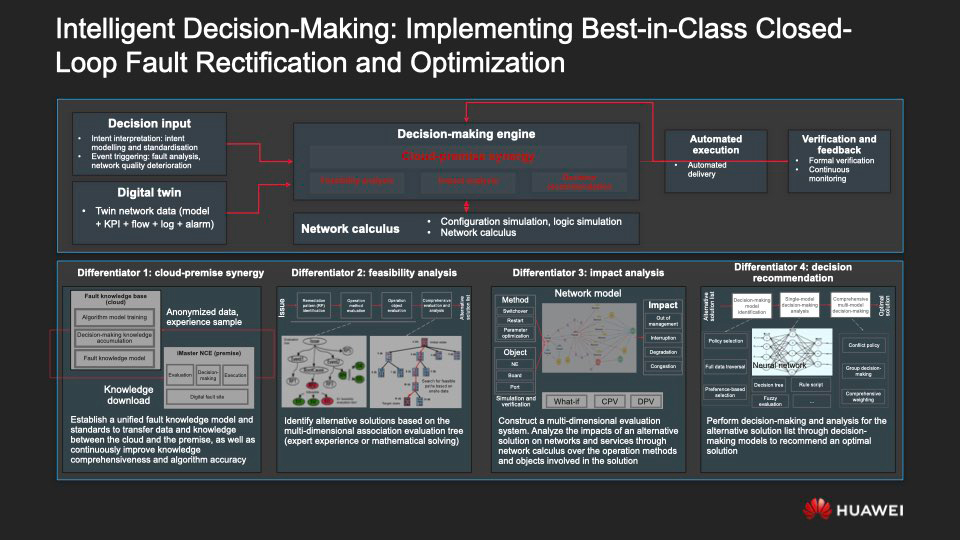
Las tecnologías enumeradas anteriormente permiten al administrador de la red detectar problemas rápidamente. Sin embargo, el análisis intelectual no es suficiente: es importante ayudar a una persona a tomar las decisiones más efectivas para superarlas, que es la esencia misma del ADN: ahora, tales decisiones se desarrollan e implementan con la ayuda directa de la IA.
Recopilar intenciones y analizar datos sobre lo que sucede en la red sobre la marcha, tomar decisiones, implementarlas y analizar las consecuencias de su adopción forman un ciclo cerrado que hace posible la toma de decisiones inteligente. Cuatro factores son claves para la efectividad de este modelo de trabajo.
- , : , on-premise cloud- ML-, iMaster NCE.
- . .
- . , , .
- . .
***
Los ingenieros de Huawei continúan mejorando las soluciones de ADN para aumentar el grado de "autosuficiencia" de la infraestructura de red y su capacidad de "autocuración", y ciertamente escribiremos sobre nuevos desarrollos en esta dirección. Y puede familiarizarse con la solución de iMaster NCE-Fabric en vivo en nuestra nube de demostración con la ayuda de los ingenieros de preventa de Huawei.