Cuando se trabaja con el habla siempre surgen varias preguntas muy "simples", para cuya solución no existen muchas herramientas convenientes, abiertas y simples: detección de la presencia de una voz (o música), detección de la presencia de números y clasificación de idiomas .
Para resolver el problema de la detección de voz (Voice Activity Detector, VAD), existe una herramienta bastante popular de Google: webRTC VAD . Es poco exigente en cuanto a recursos y compacto, pero su principal desventaja es la inestabilidad al ruido, una gran cantidad de falsos positivos y la imposibilidad de realizar ajustes finos. Está claro que si reformulamos el problema no en detección de voz, sino en detección de silencio (el silencio es la ausencia tanto de voz como de ruido), entonces se resuelve de formas muy triviales (umbral de energía, por ejemplo), pero con las mismas desventajas y limitaciones. Lo más desagradable es que a menudo estas decisiones son frágiles y algunos umbrales de código duro no se transfieren a otros dominios.
STT ( PyTorch ONNX), , , , VAD , MIT. .
"VAD"?
- VAD — , ;
- Number detector — , ;
- Language classifier — ;
- 4 (, , , ), VAD ( — - , , VAD !);
"" :
- 4 ;
- VAD WebRTC ;
- ;
- , 1 ;
- edge ;
- (PyTorch, ONNX);
- WebRTC , ;
- PyTorch (JIT), ONNX;
- ;
- ;
- (- , , STT);
- edge ;
- ONNX ;
- VAD 16 kHz, 8 kHz;
colab . , :
- PyTorch ONNX;
- — VAD — , / ;
- — . VAD ;
- , ( , 1 , - );
, VAD :
import torch
torch.set_num_threads(1)
model, utils = torch.hub.load(repo_or_dir='snakers4/silero-vad',
model='silero_vad',
force_reload=True)
(get_speech_ts,
_, read_audio,
_, _, _) = utils
files_dir = torch.hub.get_dir() + '/snakers4_silero-vad_master/files'
wav = read_audio(f'{files_dir}/en.wav')
speech_timestamps = get_speech_ts(wav, model,
num_steps=4)
print(speech_timestamps)
VAD
, VAD. .
1 AMD Ryzen Threadripper 3960X. :
torch.set_num_threads(1) # pytorch
ort_session.intra_op_num_threads = 1 # onnx
ort_session.inter_op_num_threads = 1 # onnx
, :
- num_steps — "";
- number of audio streams — ;
- , num_steps * number of audio streams;
:
| Batch size | Pytorch latency, ms | Onnx latency, ms |
|---|---|---|
| 2 | 9 | 2 |
| 4 | 11 | 4 |
| 8 | 14 | 7 |
| 16 | 19 | 12 |
| 40 | 36 | 29 |
| 80 | 64 | 55 |
| 120 | 96 | 85 |
| 200 | 157 | 137 |
, 1 :
| Batch size | num_steps | Pytorch model RTS | Onnx model RTS |
|---|---|---|---|
| 40 | 4 | 68 | 86 |
| 40 | 8 | 34 | 43 |
| 80 | 4 | 78 | 91 |
| 80 | 8 | 39 | 45 |
| 120 | 4 | 78 | 88 |
| 120 | 8 | 39 | 44 |
| 200 | 4 | 80 | 91 |
| 200 | 8 | 40 | 46 |
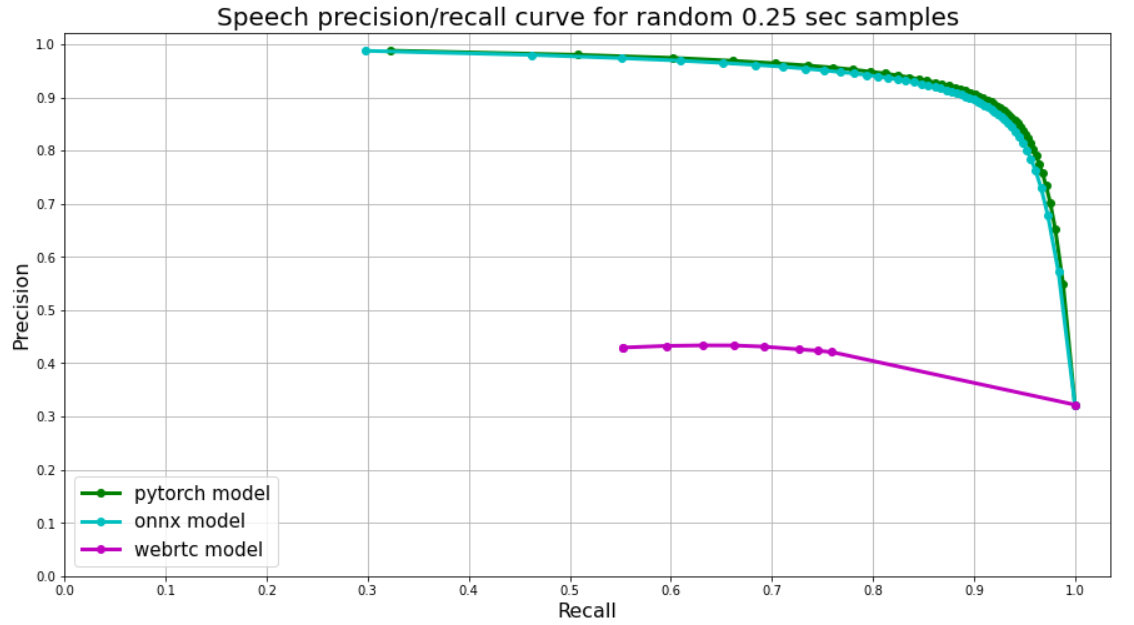
, , VAD . WebRT, 0 1?
WebRTC 0 1. - 30 , 250 8 . , 0 1 .
: