
Calientemos placas de metal en la GPU.
Todo el mundo sabe que Python no brilla con velocidad por sí solo. En mi opinión, el lenguaje es excelente en su legibilidad, pero el nicho principal de su aplicación es donde esperas la mayor parte del tiempo por alguna entrada / salida de datos. Por convención, puede escribir código de alto rendimiento en Rust o C, pero el 99% del tiempo simplemente esperará.
Sin embargo, Python también es excelente como pegamento sintáctico de alto nivel. En este caso, su parte interpretada tranquilamente invoca código de alta velocidad escrito en lenguajes de programación compilados. Normalmente, las bibliotecas tradicionales como NumPy se utilizan para esto.
Pero iremos un poco más allá, intentaremos paralelizar los cálculos en CUDA y usaremos un híbrido extraño pero funcional de C ++, stdpar y el compilador nvc ++ de Nvidia. Bueno, al mismo tiempo, intentemos evaluar el desempeño. Tomemos dos problemas: ordenar números y el método de Jacobi, que usaremos para calcular el calentamiento de una placa de metal.
Llamar a C ++ desde Python
Nuestro código de clasificación se verá así:
# distutils: language=c++
from libcpp.algorithm cimport sort
def cppsort(int[:] x):
sort(&x[0], &x[-1] + 1)
En la primera línea, indicamos explícitamente que Cython debería usar C ++, y no la C predeterminada. En la segunda, importamos la función de clasificación de C ++, y luego sigue la lógica misma. Coloque el código en el archivo cppsort.pyx. Tenga en cuenta que la extensión difiere de la py habitual, ya que la compilaremos o ejecutaremos cythonize en terminología de Cython.
La compilación puede realizarse manualmente o incluirse en setup.py, donde describimos completamente la preparación de nuestro entorno.
En setup.py, se parece a esto:
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("cppsort.pyx")
)
Pero podemos hacer esto en la línea de comando:
cythonize -i cppsort.pyx
Bajo el capó, sucederá algo como esto:

- Cython traducirá el código Python a C ++ y generará un cppsort.cpp válido.
- El compilador C ++ (en este caso g ++) compila el código C ++ en el módulo de extensión de Python
- El módulo de extensión de Python se importa al código como un módulo de Python normal.
Después de la compilación, podemos importar y probar inmediatamente la clasificación:
from cppsort import cppsort
import numpy as np
x = np.array([4, 3, 2, 1], dtype="int32")
print(x)
cppsort(x)
print(x)
La matriz [4, 3, 2, 1] se clasifica correctamente en [1, 2, 3, 4] utilizando C ++ std :: sort.
¿Vamos a la GPU?
Los algoritmos de biblioteca estándar de C ++ se pueden llamar con el argumento de política de ejecución paralela . Este argumento le dice al compilador que desea dividir el algoritmo en procesos paralelos.
Dicho esto, C ++ tiene varias opciones para esta política:
- std :: execution :: seq: ejecución secuencial. Se prohíbe el paralelismo.
- std :: execution :: unseq: Ejecución vectorizada dentro del hilo de llamada.
- std :: execution :: par: ejecución en paralelo en uno o más hilos.
- std :: execution :: par_unseq: ejecución en paralelo en uno o más hilos. Cada flujo se vectorizará siempre que sea posible.
En este caso, usted mismo debe controlar la condición de carrera y el punto muerto. El compilador estándar de g ++ intentará distribuir el cálculo entre los núcleos de la CPU. Pero podemos tomar un compilador propietario de Nvidia - nvc ++ y alimentarlo con la opción "-stdpar". stdpar es el paralelismo estándar C ++ de Nvidia con ejecución de código paralelo en la GPU.
Reescribamos el código, teniendo en cuenta la necesidad de crear una copia local de la matriz, ya que la GPU no podrá acceder a la matriz ubicada dentro de NumPy.
from libcpp.algorithm cimport sort, copy_n
from libcpp.vector cimport vector
from libcpp.execution cimport par
def cppsort(int[:] x):
cdef vector[int] temp
temp.resize(len(x))
copy_n(&x[0], len(x), temp.begin())
sort(par, temp.begin(), temp.end())
copy_n(temp.begin(), len(x), &x[0])

Ahora, esto debe compilarse nuevamente, pero usando nvc ++. Esta vez, vamos a escribir un setup.py normal y llamarlo:
CC=nvc++ python setup.py build_ext --inplace
Importamos en el código e intentamos llamar:
x = np.array([4, 3, 2, 1], dtype="int32")
cppsort(x) # GPU
Actuación
Tradicionalmente, las GPU son buenas donde hay mucho del mismo tipo de computación liviana. Las tareas pesadas, las tareas de una sola GPU no funcionarán. Además, vale la pena considerar el volumen de sus datos. Si tiene pocos datos, obtendrá una gran sobrecarga para el proceso de paralelización, E / S entre la CPU y la GPU. Como resultado, es muy probable que dicho código se ejecute de manera más eficiente en una CPU simple, a veces incluso dentro de un solo núcleo, si hay muy pocos datos. Pero en arreglos grandes, la GPU definitivamente estará por delante.
Aquí hay una gran comparación de clasificación. La velocidad NumPy se tomó como una unidad, y luego se calculó la multiplicidad del aumento de velocidad en cada método en relación con ella.
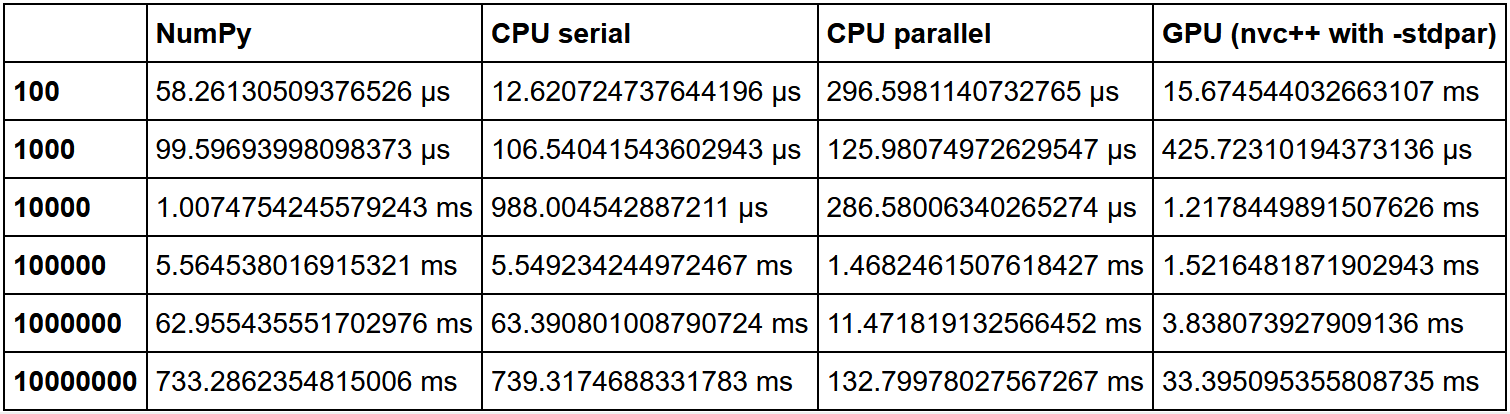
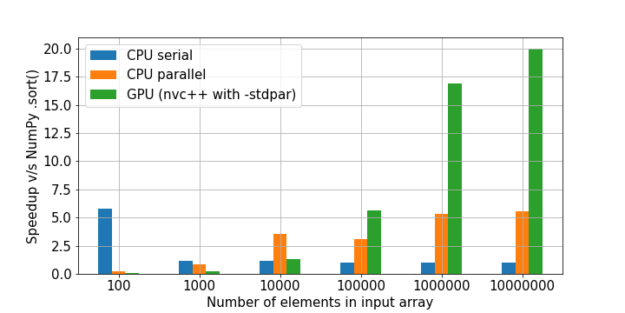
Como podemos ver, se confirma la hipótesis de que la ganancia en el uso de la GPU en una gran cantidad de datos está creciendo.
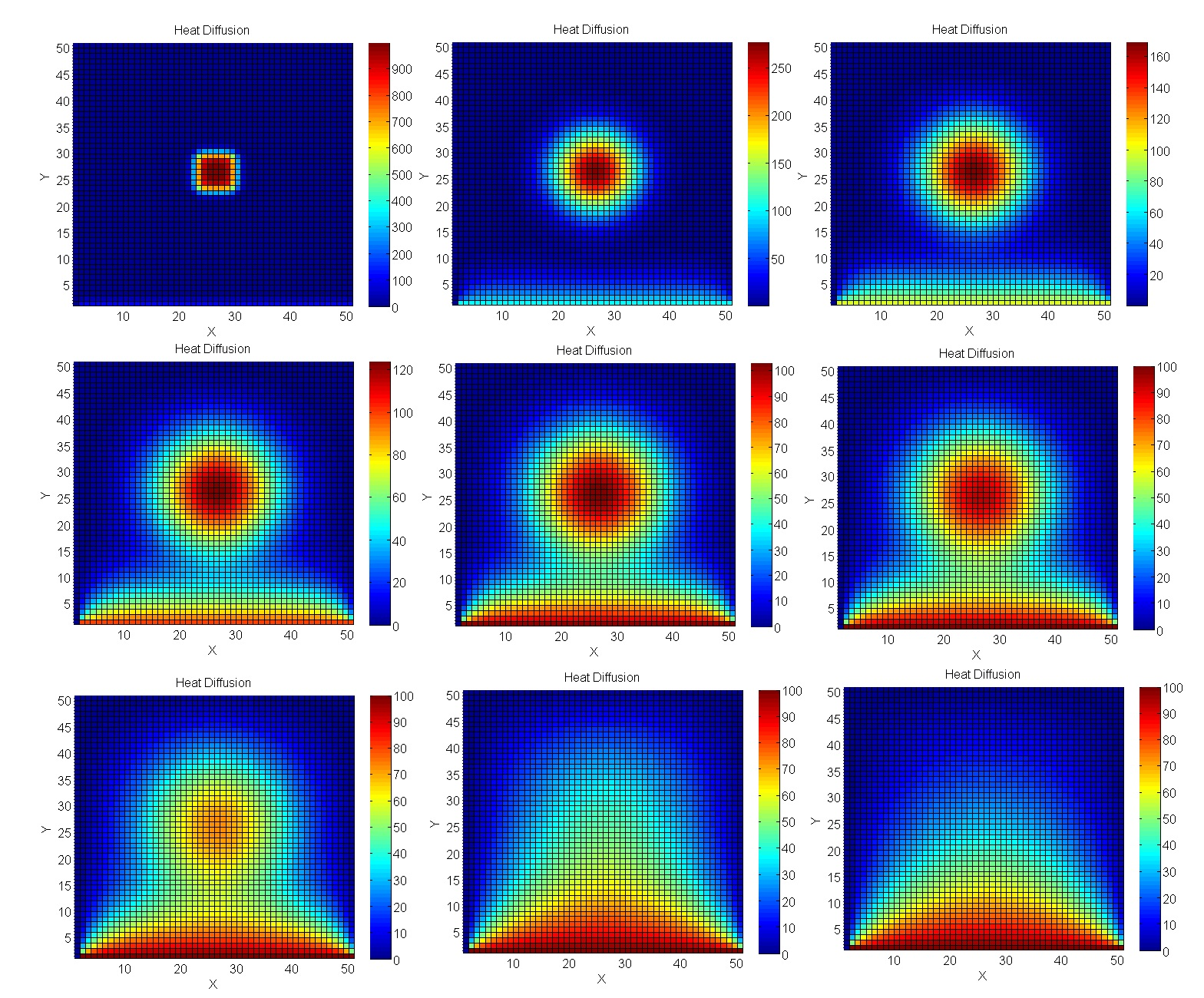
Calculamos el calentamiento de la placa.
Acerquemos un problema al modelado de ingeniería real: cálculos con el método Jacobi. En particular, son excelentes para calcular procesos de temperatura en el espacio 2D.
Código de simulación
"""
simulates heat equation on rectangle returning a heat map at a number of times
boundary and initial conditions are 0, source represents burner on a stove
This program is based on the script FEniCS tutorial demo program: Diffusion of a Gaussian hill.
u'= Laplace(u) + f in a square domain
u = u_D = 0 on the boundary
u = u_0 = 0 at t = 0
u_D = f = stove burner flame
This program succesfully runs in the fenics docker image, see the book Solving PDEs in Python.
to animate: convert -delay 4 -loop 100 heatequation10*.png heatstovelinn.gif
to crop:convert heatstovelinn.gif -coalesce -repage 0x0 -crop 810x810+95+15 +repage heatstovelin.gif
"""
from fenics import *
import time
import matplotlib.pyplot as plt
from matplotlib import cm
# Create mesh and define function space
nx = ny = 100
mesh = RectangleMesh(Point(-2, -2), Point(2, 2), nx, ny)
V = FunctionSpace(mesh, 'P', 1)
# Define boundary, source, initial
def boundary(x, on_boundary):
return on_boundary
bc = DirichletBC(V, Constant(0), boundary)
u_0 = interpolate(Constant(0), V)
f = Expression('exp(-sqrt(pow((a*pow(x[0], 2) + a*pow(x[1], 2)-a*1),2)))', degree=2, a=5) #steep guassian centred on the unit sphere
final_time = 0.035
num_pics = 72
for i in range(num_pics):
T = final_time*(i+1.0)/(num_pics+1) #solve time even space
#T = final_time*1.1**(i-num_pics+1) #solve time log space
num_steps = 30
dt = T / num_steps # time step size
# Define variational problem
u = TrialFunction(V)
v = TestFunction(V)
F = u*v*dx + dt*dot(grad(u), grad(v))*dx - (u_0 + dt*f)*v*dx
a, L = lhs(F), rhs(F)
# Time-stepping
u = Function(V)
t = 0
for n in range(num_steps):
t += dt #step
solve(a == L, u, bc) #solve
u_0.assign(u) #update
#plot solution
plot(u,cmap=cm.hot,vmin=0,vmax=0.07)
plt.axis('off')
plt.savefig('heatequation10%s.png'%(i+10),figsize=(8, 8), dpi=220,bbox_inches='tight', pad_inches=0,transparent=True)
Escribamos un solucionador similar en Cython para su posterior compilación usando CUDA:
# distutils: language=c++
# cython: cdivision=True
from libcpp.algorithm cimport swap
from libcpp.vector cimport vector
from libcpp cimport bool, float
from libc.math cimport fabs
from algorithm cimport for_each, any_of, copy
from execution cimport par, seq
cdef cppclass avg:
float *T1
float *T2
int M, N
avg(float* T1, float *T2, int M, int N):
this.T1, this.T2, this.M, this.N = T1, T2, M, N
inline void call "operator()"(int i):
if (i % this.N != 0 and i % this.N != this.N-1):
this.T2[i] = (
this.T1[i-this.N] + this.T1[i+this.N] + this.T1[i-1] + this.T1[i+1]) / 4.0
cdef cppclass converged:
float *T1
float *T2
float max_diff
converged(float* T1, float *T2, float max_diff):
this.T1, this.T2, this.max_diff = T1, T2, max_diff
inline bool call "operator()"(int i):
return fabs(this.T2[i] - this.T1[i]) > this.max_diff
def jacobi_solver(float[:, :] data, float max_diff, int max_iter=10_000):
M, N = data.shape[0], data.shape[1]
cdef vector[float] local
cdef vector[float] temp
local.resize(M*N)
temp.resize(M*N)
cdef vector[int] indices = range(N+1, (M-1)*N-1)
copy(seq, &data[0, 0], &data[-1, -1], local.begin())
copy(par, local.begin(), local.end(), temp.begin())
cdef int iterations = 0
cdef float* T1 = local.data()
cdef float* T2 = temp.data()
keep_going = True
while keep_going and iterations < max_iter:
iterations += 1
for_each(par, indices.begin(), indices.end(), avg(T1, T2, M, N))
keep_going = any_of(par, indices.begin(), indices.end(), converged(T1, T2, max_diff))
swap(T1, T2)
if (T2 == local.data()):
copy(seq, local.begin(), local.end(), &data[0, 0])
else:
copy(seq, temp.begin(), temp.end(), &data[0, 0])
return iterations
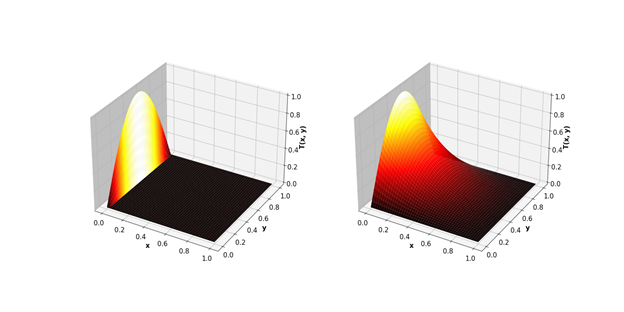

Como resultado, la brecha de GPU es aún más significativa.
Desventajas
- Escribir dicho código es algo más complicado que una versión pura de Python y requiere comprender cómo funciona la computación paralela en una GPU.
- Es necesario copiar los datos en una matriz separada para transferirlos a la GPU, donde la tarjeta de video no tiene acceso. Esto puede ser un problema cuando se trata de matrices muy grandes.
