
Sistemas para convertir consultas de texto a SQL
Lo que un sistema de este tipo debería poder hacer:
- Encuentre entidades en el texto que correspondan a entidades de base de datos: tablas, columnas, a veces valores.
- Vincular tablas, formar filtros.
- Defina un conjunto de datos devueltos, es decir, haga una lista de selección.
- Determine el orden de muestreo y el número de filas.
- Identifique, además de las relativamente obvias, algunas dependencias o filtros absolutamente implícitos que son opacos para cualquier persona excepto para los diseñadores del esquema base (vea la condición para el campo bonus_type en la imagen de arriba)
- Resuelva ambigüedades al seleccionar entidades. “Dame datos sobre Ivanov”: ¿deberías solicitar información sobre una contraparte o un empleado con ese apellido? Datos de los empleados para febrero: ¿Limitar la muestra por fecha de contratación o fecha de venta? etc.
Es decir, en el primer paso, debe analizar la consulta, al igual que cuando trabaja con todos los demás sistemas de PNL, y luego generar SQL sobre la marcha o encontrar la intención más adecuada, en cuya función se escribe una consulta SQL parametrizada previamente preparada. A primera vista, la primera opción parece mucho más impresionante. Hablemos de ello con más detalle.
La peculiaridad de este tipo de sistemas es que, de hecho, en ellos solo se registra un intent, que se dispara para todo lo que tenga al menos alguna relación con el modelo, con alguna superfunción que genera SQL para todo tipo de consultas. SQL se puede crear en base a cualquier regla, algorítmicamente o con la participación de redes neuronales.
Algoritmos y reglas
A primera vista, la tarea de convertir una oración analizada en SQL es un problema puramente algorítmico, es decir, se puede resolver sin problemas. Parece que tenemos todo lo necesario para convertir un modelo fuerte en otro: entidades reconocidas, referencias, co-referencias, etc. Pero, lamentablemente, los matices y ambigüedades, como siempre, complican todo, y en este caso hacen que el enfoque 100% universal sea casi inoperante. Los modelos son imperfectos (consulte los ejemplos anteriores y más adelante en el artículo), las entidades se cruzan, tanto en nombres como en significado, el crecimiento de la complejidad con un aumento en el número de entidades y la complejidad de la base se vuelve no lineal.
Redes neuronales
El uso de redes neuronales para tales sistemas es un área en rápido desarrollo. En el marco de este artículo, me limitaré a enlaces y breves conclusiones.
Te aconsejo que leas una breve serie de artículos: 1 , 2 , 3 , 4 , 5 , contienen bastante teoría, una historia sobre cómo se llevan a cabo la formación y las pruebas de calidad, una breve descripción de las soluciones. Además, aquí - más sobre SparkNLP. Aquí , sobre la solución Photon de SalesForce. Según la referencia, un representante más de la comunidad de código abierto: Allennlp. aquí- datos sobre la calidad de los sistemas, es decir, tasas de prueba. Aquí hay datos sobre el uso de bibliotecas de PNL y, en particular, soluciones similares en una empresa.
Esta dirección tiene un gran futuro, pero nuevamente con reservas, aún no para todos los tipos de modelos. Si, al trabajar con un modelo, no necesita obtener números completamente estrictos y garantizar resultados precisos, repetibles y predecibles (por ejemplo, necesita determinar una tendencia, comparar indicadores, identificar dependencias, etc.), todo está bien. Pero el no determinismo y la naturaleza probabilística de las respuestas imponen restricciones sobre el uso de tal enfoque para varios sistemas.
Ejemplos de trabajo con sistemas basados en redes neuronales
A menudo, las empresas que brindan servicios de este tipo muestran excelentes resultados en videos bien hechos y luego se ofrecen a contactarlos para una conversación detallada. Pero también hay demostraciones en línea disponibles en la red. Es especialmente conveniente experimentar con Photon , ya que en este caso el diagrama base está justo delante de sus ojos. La segunda demostración que vi en el dominio público es de Allennlp. El análisis de algunas consultas es sorprendente por su sofisticación, algunas opciones tienen un poco menos de éxito. La impresión general es mixta, intente jugar con estas demostraciones si está interesado y forme su opinión.
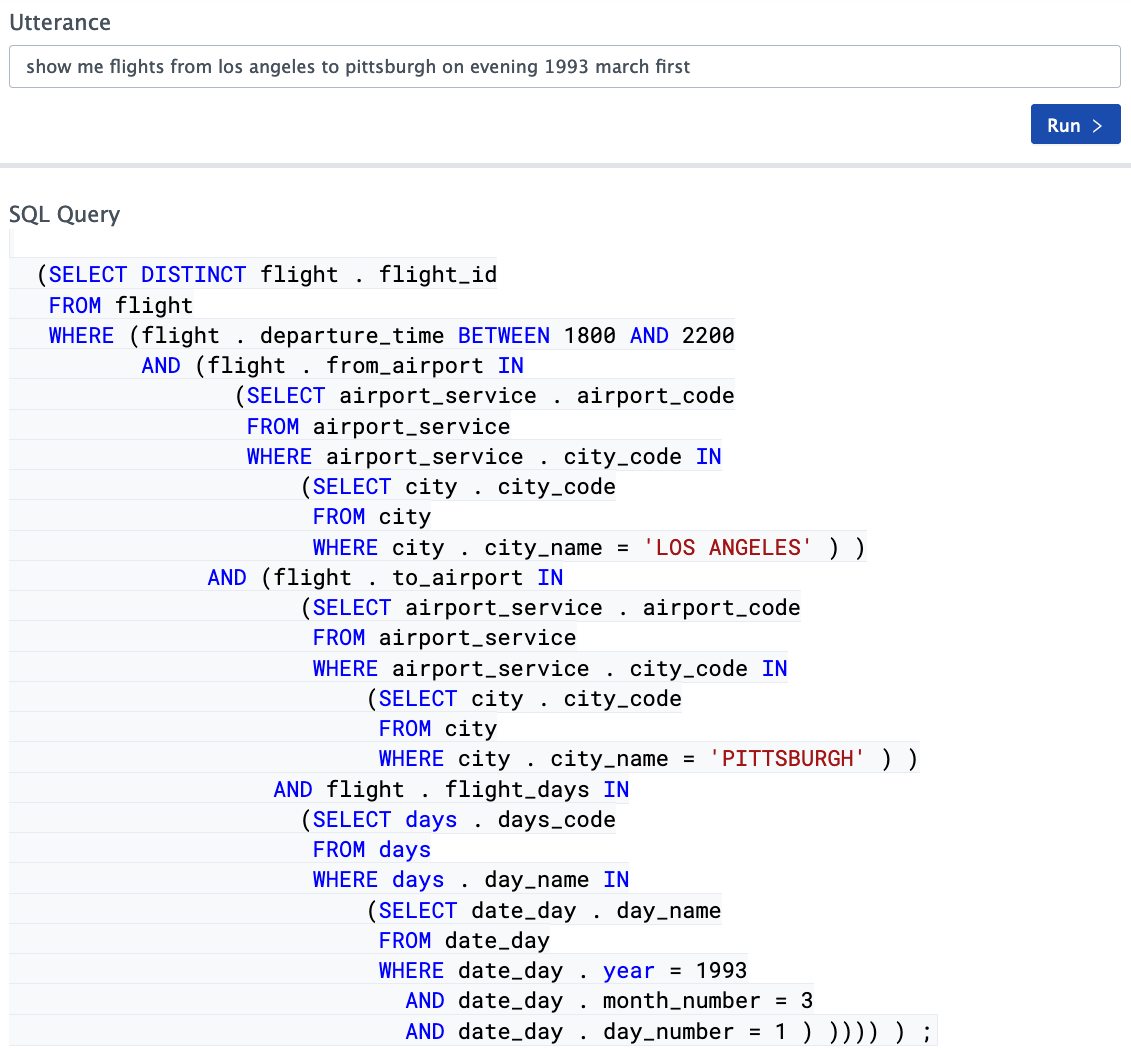
En general, la situación es bastante interesante. Los sistemas para la traducción automática de consultas textuales no estructuradas a SQL basados en redes neuronales son cada vez mejores, la calidad de los conjuntos de pruebas aprobados es cada vez mayor, pero aún así su valor no supera el 70% en el mejor de los casos ( conjunto de datos de araña : alrededor del 69% hoy día). ¿Puede considerarse bueno este resultado? Desde el punto de vista del desarrollo de este tipo de sistemas, sí, por supuesto, los resultados son impresionantes, pero está lejos de ser posible utilizarlos en sistemas reales sin modificación para todo tipo de tareas.
Herramientas de Apache NlpCraft
¿Cómo puede ayudar el proyecto Apache NlpCraft a construir y organizar dichos sistemas? Si no hay preguntas sobre la primera parte del problema (analizar una consulta de texto), todo es como de costumbre, luego para la segunda parte (formación de consultas SQL basadas en datos NLP), NlpCraft no proporciona una solución 100% completa, sino solo herramientas que ayudan a resolver este problema de forma independiente. ...
¿Dónde empezar? Si queremos automatizar al máximo el proceso de desarrollo, los metadatos del esquema de la base de datos y los propios datos nos ayudarán. Enumeraremos qué información podemos extraer de la base de datos y por simplicidad nos restringiremos a tablas, no intentaremos analizar disparadores, procedimientos almacenados, etc.
- — . , .
- (null / not null) (where clause).
- , foreign keys , 1:1, 1:0, 1:n, n:m. joins.
- . , , .. , select list.
- . . - — , — enumeration, . .
- . , . .
- Primary and unique keys — , , , .
- (, , Oracle) — .
- Compruebe las restricciones: el conocimiento de las restricciones puede ayudar a crear los mismos filtros en estas columnas.
Por tanto, si ha obtenido metadatos, entonces ya sabe mucho sobre las entidades del modelo. Entonces, por ejemplo, en algún mundo ideal, sabes casi todo sobre la tabla a continuación:
CREATE TABLE users (
id number primary key,
first_name varchar(32) not null,
last_name varchar(64) not null unique,
birthday date null,
salary_level_id number not null foreign key on salary_level(id)
);
En realidad, no todo será tan optimista, los nombres se abreviarán y serán ilegibles, los tipos de datos a menudo resultarán completamente inesperados y los campos desnormalizados y las tablas agregadas apresuradamente como 1: 0 se dispersarán aquí y allá. Como resultado, para ser realistas, la mayoría de las bases de datos que han estado en producción durante mucho tiempo solo pueden usarse con gran dificultad para reconocer entidades sin ninguna preparación previa. Esto se aplica a cualquier sistema, y se basa en redes neuronales, quizás incluso más que en otros.
En esta situación, es aconsejable dar acceso al módulo NLP a un esquema algo refinado: un conjunto de vistas preparadas previamente, con los nombres de campo correctos, un conjunto de tablas y columnas necesario y suficiente, problemas de seguridad, etc.
Empecemos a diseñar
La idea principal y muy simple es que es casi imposible cubrir todas las solicitudes de los usuarios. Si el usuario se fija el objetivo de engañar al sistema y quiere hacer una pregunta que lo confundirá, lo hará fácilmente. La tarea del desarrollador es lograr un equilibrio entre las capacidades del sistema que se está desarrollando y la complejidad de su implementación. Por lo tanto, también un consejo muy simple: no intente respaldar una intención universal que responda a todas las preguntas, con un método universal que genere SQL para todas estas opciones. Intente renunciar al 100% de la versatilidad, hará que el proyecto sea un poco menos colorido, pero más realizable.
- Pregunte a los usuarios y anote entre 30 y 40 de los tipos de preguntas más comunes.
- , , , ..
- . SQL, 20-30 . , . SQL ML text2Sql, .
- . — , , , . — SQL . C — , .
Con tal volumen de trabajo y recursos suficientes, el tiempo requerido para resolver tal problema se mide en días, y al final tienes una cobertura del 80% de las necesidades del usuario, y con una calidad de desempeño bastante alta. Luego regrese al primer punto y agregue más intenciones.
Por qué vale la pena apoyar múltiples intenciones es más fácil de explicar con un ejemplo. Casi siempre los usuarios están interesados en una cierta cantidad de informes muy atípicos, algo así como “compárame tal y cual para tal o cual período, pero no incluido en tal o cual período y al mismo tiempo ...”. Ningún sistema podrá generar SQL inmediatamente para tal consulta, tendrá que entrenarlo de alguna manera o seleccionar y programar por separado tales casos. Ser capaz de responder a una gama limitada de consultas complejas es muy importante para sus usuarios. Busque un equilibrio de nuevo, no el hecho de que habrá suficientes recursos para satisfacer todas esas solicitudes, pero ignorar por completo esos deseos significa reducir la funcionalidad del sistema a un nivel inaceptable. Si encuentra la proporción correcta,su sistema tomará una cantidad limitada de tiempo de desarrollo y no será solo un juguete divertido durante unos días, causando molestia en lugar de utilidad más adelante. Un punto muy importante es que puede agregar intents para solicitudes complicadas no de inmediato, sino en el proceso, uno por uno. Tenemos MVP con una sola intención universal a la vez.
Kit de herramientas y API
Apache NlpCraft proporciona un conjunto de herramientas para simplificar la manipulación de la base de datos.
Procedimiento de operación:
- Genere una plantilla de modelo a partir de la URL de la base de datos jdbc. Como mencioné anteriormente, a veces es mejor preparar un conjunto de vistas con una representación más "correcta" de los datos y proporcionar acceso a ese conjunto. La forma más sencilla de generar una plantilla es utilizar la utilidad CLI . Lanzamos la utilidad, especificamos el esquema de la base de datos, el controlador jdbc, una lista de tablas usadas e ignoradas y otros parámetros como parámetros, consulte la documentación para más detalles .
- JSON YAML , , , , .., , .
:
- id: "tbl:orders" groups: - "table" synonyms: - "orders" metadata: sql:name: "orders" sql:defaultselect: - "order_id" - "customer_id" - "employee_id" sql:defaultsort: - "orders.order_id#desc" sql:extratables: - "customers" - "shippers" - "employees" description: "Auto-generated from 'orders' table." ..... - id: "col:orders_order_id" groups: - "column" synonyms: - "{order_id|order <ID>}" - "orders {order_id|order <ID>}" - "{order_id|order <ID>} <OF> orders" metadata: sql:name: "order_id" sql:tablename: "orders" sql:datatype: 4 sql:isnullable: false sql:ispk: true description: "Auto-generated from 'orders.order_id' column."
- — , , . , . , , , , , , .. .
- Basado en el modelo enriquecido, el desarrollador puede usar una API compacta que facilita enormemente la construcción de consultas SQL en la función de intención; vea un ejemplo detallado .
A continuación se muestra un fragmento de código para mayor claridad:
@NCIntent(
"intent=commonReport " +
"term(tbls)~{groups @@ 'table'}[0,7] " +
"term(cols)~{
id == 'col:date' ||
id == 'col:num' ||
id == 'col:varchar'
}[0,7] " +
"term(condNums)~{id == 'condition:num'}[0,7] " +
"term(condVals)~{id == 'condition:value'}[0,7] " +
"term(condDates)~{id == 'condition:date'}[0,7] " +
"term(condFreeDate)~{id == 'nlpcraft:date'}? " +
"term(sort)~{id == 'nlpcraft:sort'}? " +
"term(limit)~{id == 'nlpcraft:limit'}?"
)
def onCommonReport(
ctx: NCIntentMatch,
@NCIntentTerm("tbls") tbls: Seq[NCToken],
@NCIntentTerm("cols") cols: Seq[NCToken],
@NCIntentTerm("condNums") condNums: Seq[NCToken],
@NCIntentTerm("condVals") condVals: Seq[NCToken],
@NCIntentTerm("condDates") condDates: Seq[NCToken],
@NCIntentTerm("condFreeDate") freeDateOpt: Option[NCToken],
@NCIntentTerm("sort") sortTokOpt: Option[NCToken],
@NCIntentTerm("limit") limitTokOpt: Option[NCToken]
): NCResult = {
val ext = NCSqlExtractorBuilder.build(SCHEMA, ctx.getVariant)
val query =
SqlBuilder(SCHEMA).
withTables(tbls.map(ext.extractTable): _*).
withAndConditions(extractValuesConditions(ext, condVals): _*).
...
// SQL
// .
}
Aquí hay un fragmento de la función de intención predeterminada que responde a cualquier elemento base definido en la solicitud y se activa si no se encontraron coincidencias más estrictas durante el proceso de coincidencia. Demuestra el uso de la API de extracción de elementos SQL, que participa en la creación de consultas SQL, así como en el trabajo con el ejemplo del constructor SQL.
Una vez más, me gustaría enfatizar que Apache NlpCraft no proporciona una herramienta lista para traducir una consulta de texto analizado a SQL, esta tarea está fuera del alcance del proyecto, al menos en la versión actual. El código del generador de consultas está disponible en ejemplos, no en la API, tiene limitaciones significativas, pero también consta de solo 500 líneas de código con comentarios, o alrededor de 300 sin ellos. Al mismo tiempo, a pesar de toda su simplicidad e incluso limitación, incluso esta implementación más simple es capaz de generar el SQL necesario para un número muy significativo de los más diversos tipos de consultas de usuario. En esta versión, sugerimos a nuestros usuarios interesados en construir sistemas similares que usen este ejemplocomo plantilla y desarrollarla según sus necesidades. Sí, esta no es una tarea para una noche, pero obtendrá un resultado de una calidad incomparablemente más alta que cuando utiliza soluciones universales de frente.
Repito que en la función de intención predeterminada, puede simplemente modificar los ejemplos del ejemplo (según las revisiones, su funcionalidad puede ser suficiente) o usar soluciones con redes neuronales.
Conclusión
Crear un sistema para acceder a una base de datos no es una tarea fácil, pero Apache NlpCraft ya ha asumido una parte considerable del trabajo de rutina y, en gran parte, debido a esto, desarrollar un sistema de calidad decente requerirá tiempo y recursos cuantificables. Si la comunidad Apache NlpCraft desarrollará la dirección de automatizar la traducción de consultas de texto a SQL y expandirá este simple ejemplo de SQL a una API completa, se mostrarán las solicitudes de tiempo y de usuario que forman el plan y la dirección del proyecto.