- Le permite escribir código en un idioma familiar, pero al mismo tiempo utilizar funciones que existen solo en otro idioma.
- Permite la colaboración directa con un colega que está programando en otro idioma.
- Hace posible trabajar con dos idiomas y eventualmente aprender a dominarlos.

Qué necesitamos
Necesitará estos componentes para funcionar:
- R y Python, por supuesto.
- IDE RStudio (puede hacer esto en otros IDE, pero en RStudio es más fácil).
- Su administrador de entorno Python favorito (estoy usando conda aquí).
- Paquetes
rmarkdown
ereticulate
instalados en R.
Al escribir documentos de R Markdown, estaremos trabajando en RStudio, pero al mismo tiempo navegaremos entre los fragmentos de código escritos en R y en Python. Te mostraré un par de ejemplos sencillos.
Configurar el entorno de Python
Si está familiarizado con la programación de Python, entonces sabe que cualquier trabajo realizado en Python debe referirse a un entorno específico que contenga todos los paquetes necesarios para el trabajo. Hay muchas formas de administrar paquetes en Python, las dos más populares son virtualenv y conda. Aquí estoy asumiendo que estamos usando conda y que está instalado como el administrador de entorno de Python.
Puede usar el paquete reticulate en R para configurar entornos conda a través de la línea de comando R si lo desea (usando características como
conda_create()
), pero como programador regular de Python, prefiero configurar mis entornos manualmente.
Supongamos que creamos un entorno conda llamado
r_and_python
e instalamos en él
pandas
y
statsmodels
... Entonces los comandos en la terminal:
conda create -name r_and_python conda activate r_and_python conda install pandas conda install statsmodels
Después de la instalación
pandas
,
statsmodels
(y cualquier otro paquete que pueda necesitar), la configuración del entorno se ha completado. Ahora ejecute conda info en la terminal y seleccione la ruta a su entorno. Lo necesitará en el siguiente paso.
Configurando su proyecto R para trabajar con R y Python
Comenzaremos un proyecto R en RStudio, pero queremos poder ejecutar Python en el mismo proyecto. Para asegurarnos de que el código de Python se ejecute en el entorno que queremos, debemos configurar la variable de entorno del sistema
RETICULATE_PYTHON
para el ejecutable de Python en ese entorno. Esta será la ruta que eligió en la sección anterior, seguida de
/bin/python3
.
La mejor manera de asegurarse de que esta variable se establezca permanentemente en su proyecto es crear un archivo de texto con el nombre del proyecto
.Rprofile
y agregarle esta línea.
Sys.setenv(RETICULATE_PYTHON=”path_to_environment/bin/python3")
Reemplace ruta al entorno con la ruta que eligió en la sección anterior. Guarde el archivo
.Rprofile
y reinicie la sesión R. Cada vez que reinicia una sesión o proyecto, se inicia
.Rprofile
, configurando su entorno Python. Si desea probar esto, puede ejecutar la línea Sys.getenv ("RETICULATE_PYTHON").
Código de escritura: primer ejemplo
Ahora puede configurar un documento R Markdown en su proyecto
.Rmd
y escribir código en dos idiomas diferentes. Primero debe cargar la biblioteca reticulada en su primer fragmento de código.
```{r} library(reticulate) ```
Ahora, cuando desee escribir código Python, puede envolverlo con comillas inversas normales, pero marcarlo como un fragmento de código Python con
{python}
, y cuando desee escribir en R, use
{r}
.
Para nuestro primer ejemplo, suponga que ejecuta un modelo de Python en un conjunto de datos de calificaciones de exámenes de estudiantes.
```{python} import pandas as pd import statsmodels.api as sm import statsmodels.formula.api as smf # obtain ugtests data url = “http://peopleanalytics-regression-book.org/data/ugtests.csv" ugtests = pd.read_csv(url) # define model model = smf.ols(formula = “Final ~ Yr3 + Yr2 + Yr1”, data = ugtests) # fit model fitted_model = model.fit() # see results summary model_summary = fitted_model.summary() print(model_summary) ```
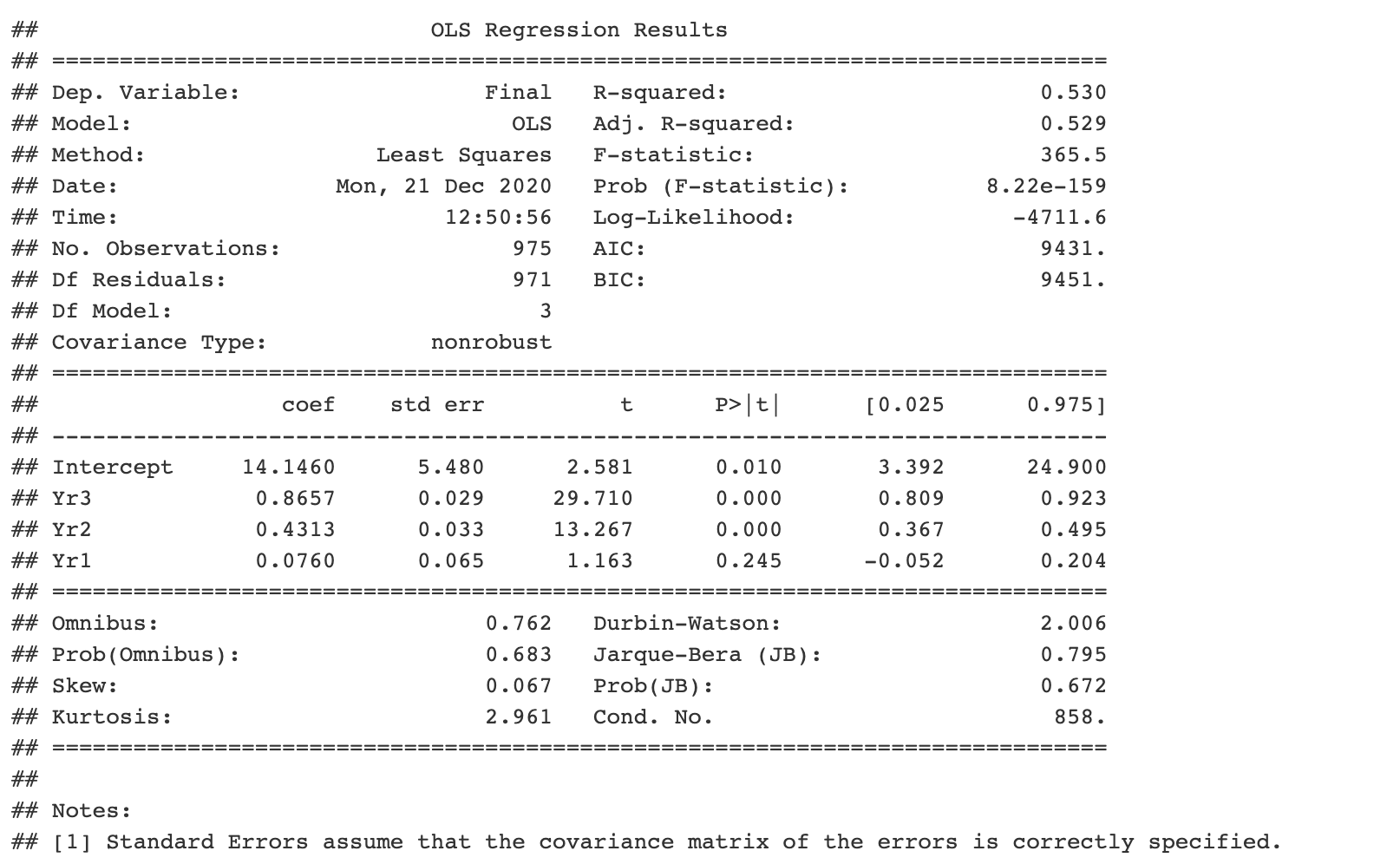
Esto es genial, pero digamos que tuvo que dejar su trabajo debido a algo más urgente y entregárselo a su colega, el programador de R. Esperaba poder diagnosticar el modelo.
No tengas miedo. Puede acceder a todos los objetos de Python que ha creado en la lista general llamada py. Entonces, si se crea un bloque R dentro de su documento R Markdown, los colegas tendrán acceso a los parámetros de su modelo:
```{r} py$fitted_model$params ```

o las primeras sobras:
```{r} py$fitted_model$resid[1:5] ```

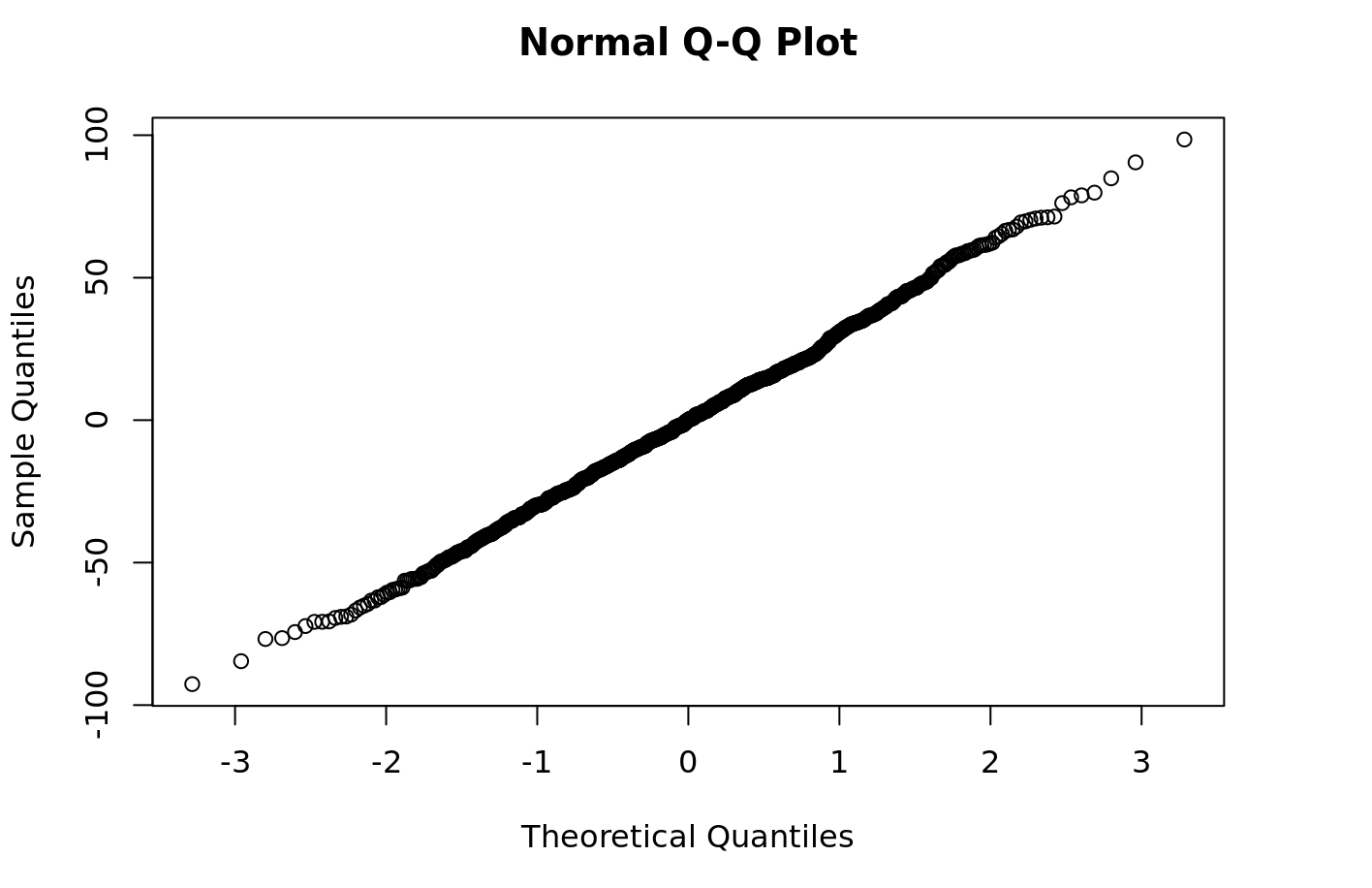
Ahora puede realizar fácilmente algunos diagnósticos en el modelo, como trazar los residuos de su modelo de cuantiles-cuantiles:
```{r} qqnorm(py$fitted_model$resid) ```
Código de escritura - segundo ejemplo
Analizó algunos datos de citas de Python y creó un marco de datos de pandas con todos los datos en él. Para simplificar, carguemos los datos y veamos:
```{python} import pandas as pd url = “http://peopleanalytics-regression-book.org/data/speed_dating.csv" speed_dating = pd.read_csv(url) print(speed_dating.head()) ```

Ahora ha ejecutado un modelo de regresión logística simple en Python para intentar asociar la solución de dec con algunas otras variables. Sin embargo, comprende que estos datos son en realidad jerárquicos y que el mismo iid individual puede tener varios conocidos.
Entonces sabe que necesita ejecutar un modelo de regresión logística de efectos mixtos, ¡pero no puede encontrar ningún programa de Python que lo haga!
Y de nuevo, no tengas miedo, envía el proyecto a un colega y él escribirá la solución en R.
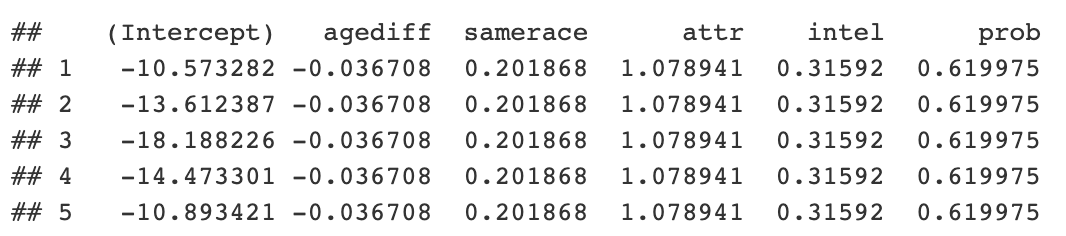
```{r} library(lme4) speed_dating <- py$speed_dating iid_intercept_model <- lme4:::glmer(dec ~ agediff + samerace + attr + intel + prob + (1 | iid), data = speed_dating, family = “binomial”) coefficients <- coef(iid_intercept_model)$iid ```
Ahora puede obtener el código y ver las probabilidades. También es posible acceder a los objetos Python R dentro de un objeto r genérico.
```{python} coefs = r.coefficients print(coefs.head()) ```
Estos dos ejemplos muestran cómo puede navegar sin problemas entre R y Python en el mismo documento de R Markdown. Entonces, la próxima vez que piense en trabajar en un proyecto en varios idiomas, piense en ejecutar todos los pasos en R Markdown. Esto puede evitarle la molestia de cambiar entre dos idiomas y ayudar a mantener todo su trabajo en un solo lugar como una narración continua.
Puede ver el documento R Markdown terminado creado en torno a la integración del lenguaje, con fragmentos de R y Python y objetos que se mueven entre ellos, publicado aquí . El repositorio de Github con el código fuente está aquí .
Los datos de muestra en el documento son de mi Referencia de modelado de regresión de People Analytics .

Otras profesiones y cursos
PROFESIÓN
CURSOS
- Profesión de desarrollador Java
- Profesión de desarrollador frontend
- Desarrollador web profesional
- Profesión Hacker ético
- Profesión de desarrollador C ++
- Desarrollador de juegos Profession Unity
- La profesión de desarrollador de iOS desde cero
- Desarrollador profesional de Android desde cero
CURSOS
- Curso de aprendizaje automático
- Curso avanzado "Machine Learning Pro + Deep Learning"
- Curso de Python para desarrollo web
- Curso de JavaScript
- « Machine Learning Data Science»
- DevOps