Para algunas áreas, como NLP, el caballo de batalla fue Transformer, que requiere grandes cantidades de memoria GPU. Los modelos realistas simplemente no caben en la memoria. El último método llamado Sharded [lit. 'segmentado'] se presentó en el artículo Zero de Microsoft, en el que desarrollaron un método que acerca a la humanidad a un billón de parámetros.
Especialmente para el inicio de un nuevo curso sobre Machine Learning, comparta con usted un artículo sobre Sharded que le muestra cómo usarlo con PyTorch hoy para entrenar modelos con el doble de memoria y en solo unos minutos. Esta función en PyTorch ahora está disponible a través de una colaboración entre los equipos FairScale Facebook AI Research y PyTorch Lightning .

¿Para quién es este artículo?
Este artículo es para cualquiera que use PyTorch para entrenar modelos. Sharded funciona en cualquier modelo, sin importar qué modelo entrenar: NLP (transformador), visual (SIMCL, swav, Resnet) o incluso modelos de voz. Aquí hay una instantánea del aumento de rendimiento que puede ver con Sharded en todos los tipos de modelos.
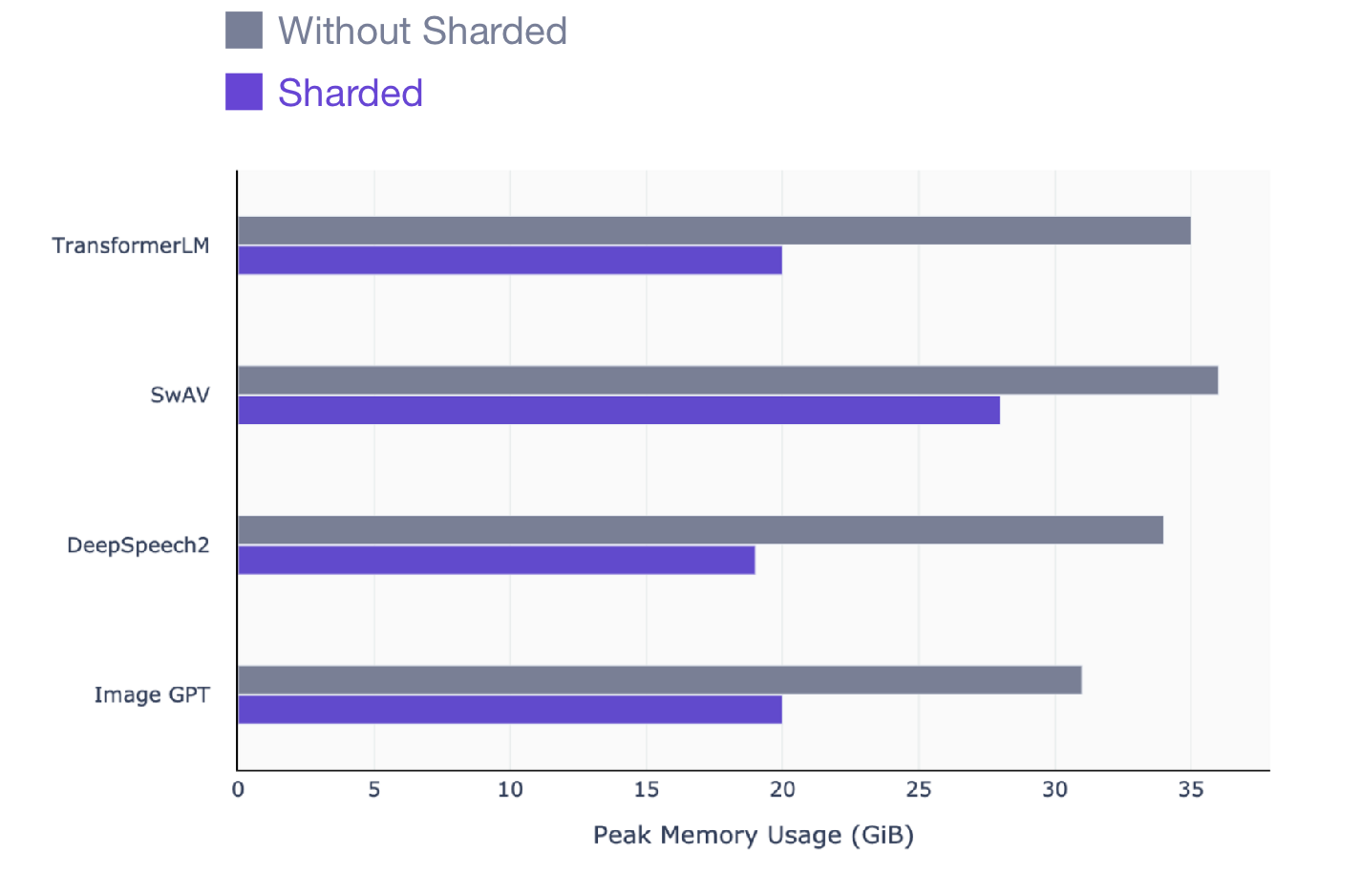
SwAV es un método de aprendizaje basado en datos de vanguardia en visión por computadora.
DeepSpeech2 es una técnica moderna para modelos de voz.
Image GPT es un método avanzado para modelos visuales.
Transformer es una técnica avanzada de procesamiento del lenguaje natural.
Cómo usar Sharded con PyTorch
Para aquellos que no tienen mucho tiempo para leer la explicación intuitiva de cómo funciona Sharded, les explicaré de inmediato cómo usar Sharded con su código PyTorch. Pero le insto a que lea el final del artículo para comprender cómo funciona Sharded.
Sharded está diseñado para usarse con múltiples GPU para aprovechar al máximo los beneficios disponibles. Pero el entrenamiento en múltiples GPU puede ser abrumador y muy doloroso de configurar.
La forma más fácil de cargar su código con Sharded es convertir su modelo a PyTorch Lightning (esto es solo una refactorización). Aquí hay un video de 4 minutos que le muestra cómo convertir su código PyTorch a Lightning.
Una vez que haya hecho eso, habilitar Sharded en 8 GPU es tan fácil como cambiar una sola bandera: no se requieren cambios en su código.

Si su modelo es de otra biblioteca de aprendizaje profundo, seguirá funcionando con Lightning (NVIDIA Nemo, fast.ai, Hugging Face). Todo lo que necesita hacer es importar el modelo a LightningModule y comenzar a aprender.
from argparse import ArgumentParser
import torch
import torch.nn as nn
import pytorch_lightning as pl
from pytorch_lightning.metrics.functional import accuracy
from transformers import BertModel
class LitBertClassifier(pl.LightningModule):
def __init__(self, n_classes, pretrained_model_name='bert-base-uncased'):
super().__init__()
self.save_hyperparameters()
self.bert = BertModel.from_pretrained(pretrained_model_name)
self.drop = nn.Dropout(p=0.3)
self.out = nn.Linear(self.bert.config.hidden_size, n_classes)
self.loss_fn = nn.CrossEntropyLoss()
def forward(self, input_ids, attention_mask):
outputs = self.bert(
input_ids=input_ids,
attention_mask=attention_mask,
return_dict=False
)
pooled_output = outputs[1]
output = self.drop(pooled_output)
return self.out(output)
def training_step(self, batch, batch_idx):
loss, acc = self._shared_step(batch, batch_idx)
self.log("acc", acc)
return loss
def validation_step(self, batch, batch_idx):
_, acc = self._shared_step(batch, batch_idx)
self.log("val_acc", acc)
def _shared_step(self, batch, batch_idx):
input_ids = batch["input_ids"]
attention_mask = batch["attention_mask"]
targets = batch["targets"]
outputs = self.forward(
input_ids=input_ids,
attention_mask=attention_mask
)
_, preds = torch.max(outputs, dim=1)
loss = self.loss_fn(outputs, targets)
acc = accuracy(preds, targets)
return loss, acc
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=2e-5)
if __name__ == '__main__':
# TODO: add your own dataset
train_dataloader = ...
val_dataloader = ...
bert = LitBertClassifier()
trainer = pl.Trainer(gpus=8, plugins='ddp_sharded')
trainer.fit(bert, train_dataloader)
Explicación intuitiva de cómo funciona Sharded
Se utilizan varios enfoques para entrenar de manera efectiva en una gran cantidad de GPU. En un enfoque (DP), cada paquete se divide entre GPU. Aquí hay una ilustración de DP donde cada parte del paquete se envía a una GPU diferente y el modelo se copia varias veces en cada una.

Entrenamiento de DP
Este enfoque es malo, sin embargo, porque los pesos del modelo se transmiten a través del dispositivo. Además, la primera GPU admite todos los estados del optimizador. Por ejemplo, Adam guarda una copia completa adicional de los pesos de su modelo.
En otra técnica (Distribución de datos en paralelo, DDP), cada GPU se entrena en un subconjunto de datos y los gradientes se sincronizan entre las GPU. Este método también funciona en muchas máquinas (nodos). En esta figura, cada GPU recibe un subconjunto de los datos e inicializa los mismos pesos de modelo para todas las GPU. Luego, después del pase hacia atrás, todos los gradientes se sincronizan y actualizan.
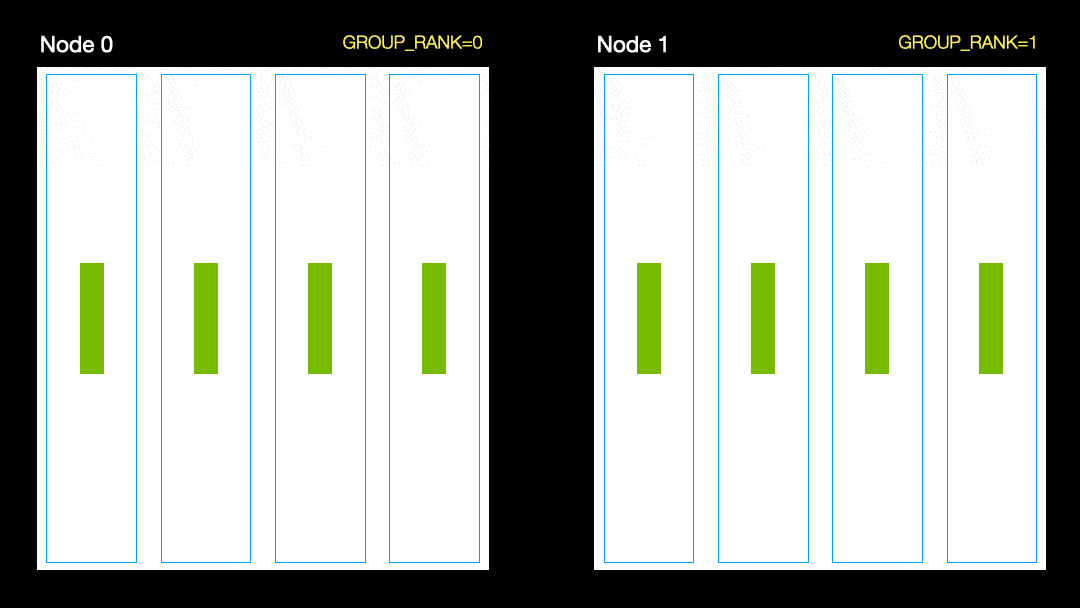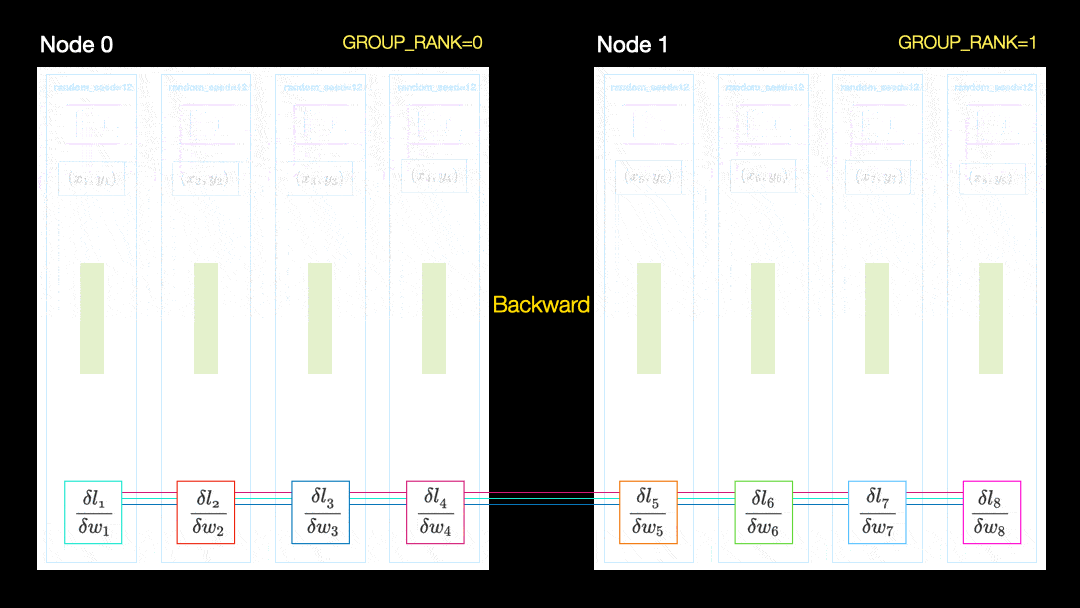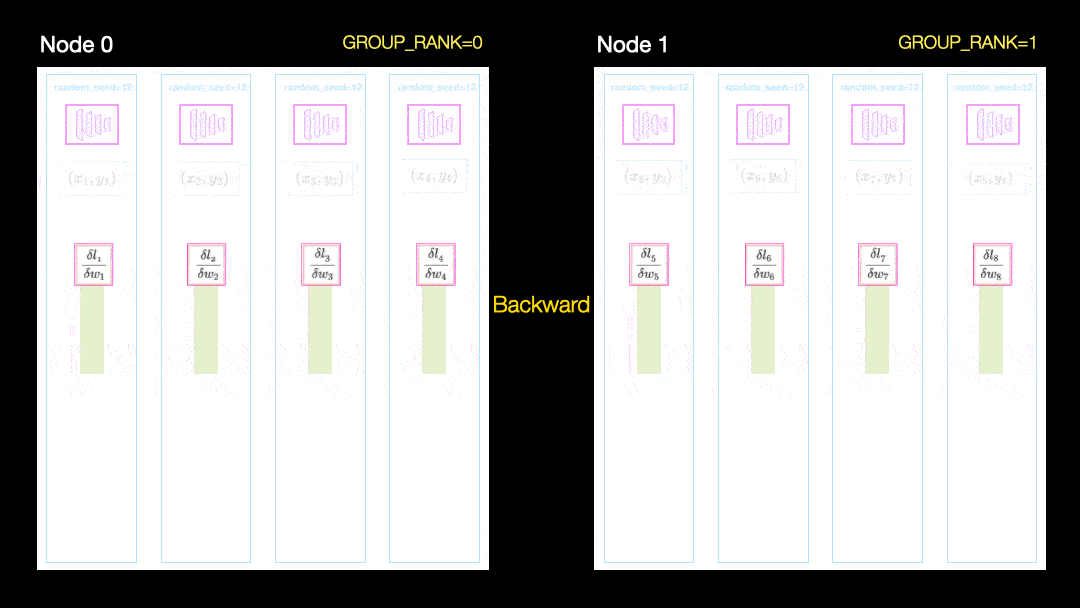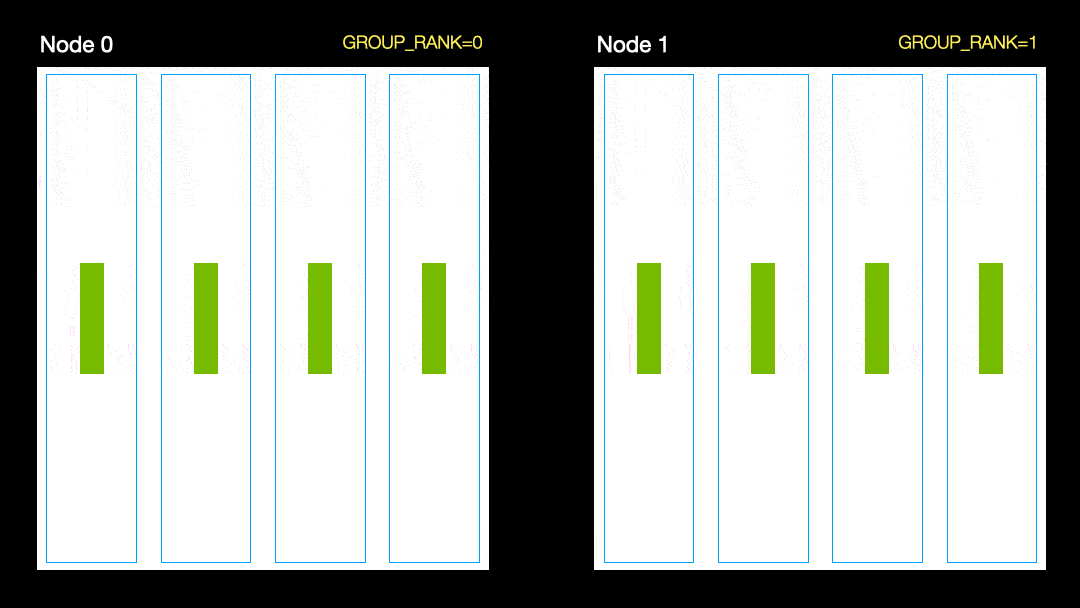
Distribución de datos en paralelo
Sin embargo, este método todavía tiene un problema, que es que cada GPU debe mantener una copia de todos los estados del optimizador (aproximadamente 2-3 veces los parámetros del modelo), así como todas las activaciones hacia adelante y hacia atrás.
Sharded elimina esta redundancia. Funciona de la misma manera que DDP, excepto que toda la sobrecarga (gradientes, estado del optimizador, etc.) se calcula solo para una fracción de los parámetros totales y, por lo tanto, eliminamos la redundancia de almacenar el mismo gradiente y estados. optimizador en todas las GPU. En otras palabras, cada GPU almacena solo un subconjunto de activaciones, parámetros del optimizador y cálculos de gradiente.
Usando algún tipo de modo distribuido

En PyTorch Lightning, cambiar los modos de distribución es trivial.
Como puede ver, con cualquiera de estos enfoques de optimización, hay muchas formas de aprovechar al máximo el aprendizaje distribuido.
La buena noticia es que todos estos modos están disponibles en PyTorch Lightning sin tener que cambiar su código. Puede probar cualquiera de ellos y ajustar si es necesario para su modelo específico.
Un método que no existe es el modelo paralelo. Sin embargo, tenga en cuenta este método, ya que ha demostrado ser mucho menos eficaz que el entrenamiento segmentado y debe usarse con precaución. Podría funcionar en algunos casos, pero en general es mejor usar fragmentación.
¡La ventaja de usar Lightning es que nunca se queda atrás de los últimos avances en investigación de IA! El equipo y la comunidad de código abierto están comprometidos a compartir los últimos avances con Lightning a través de Lightning.

- Curso de aprendizaje automático
- Formación profesional en ciencia de datos
- Formación de analista de datos
Otras profesiones y cursos