Hace tiempo que nos interesa el tema del uso de Apache Kafka como almacén de datos, considerado desde un punto de vista teórico, por ejemplo, aquí . Es aún más interesante llamar su atención sobre una traducción de material del blog de Twitter (original, diciembre de 2020), que describe un uso poco convencional de Kafka como base de datos para procesar y reproducir eventos. Esperamos que este artículo sea interesante y le brinde ideas y soluciones nuevas cuando trabaje con Kafka .
Introducción
Cuando los desarrolladores consumen datos públicos de Twitter a través de la API de Twitter, confían en la confiabilidad, la velocidad y la estabilidad. Por lo tanto, hace algún tiempo, Twitter lanzó la API de reproducción de actividad de la cuenta para la API de actividad de la cuenta para que sea más fácil para los desarrolladores garantizar la estabilidad de sus sistemas. La API Account Activity Replay es una herramienta de recuperación de datos que permite a los desarrolladores recuperar eventos que tienen hasta cinco días de antigüedad. Esta API recupera eventos que no se entregaron por una variedad de razones, incluidos los bloqueos del servidor que ocurrieron al intentar entregar en tiempo real.
Los ingenieros de Twitter se esforzaban no solo por crear API que fueran bien recibidas por los desarrolladores, sino también por:
- Incrementar la productividad de los ingenieros;
- Haga que el sistema sea fácil de mantener. En particular, para minimizar la necesidad de cambio de contexto para los desarrolladores, los ingenieros de SRE y todos los que se ocupan del sistema.
Por este motivo, a la hora de trabajar en la creación de un sistema de reproducción que dependa de la API, se decidió tomar como base el sistema existente para trabajar en tiempo real, en el que se basa la API de Actividad de la cuenta. De esta manera, fue posible reutilizar los desarrollos existentes y minimizar el cambio de contexto y el entrenamiento, lo que sería mucho más significativo si se creara un sistema completamente nuevo para el trabajo descrito.
La solución en tiempo real se basa en una arquitectura de publicación-suscripción. Para ello, teniendo en cuenta las tareas y creando el nivel de almacenamiento de información desde el cual se leerá, surgió la idea de repensar la conocida tecnología de streaming - Apache Kafka.
Contexto
Los eventos que ocurren en tiempo real se producen en dos centros de datos. Cuando se activan estos eventos, se escriben en temas de publicación-suscripción que se replican de forma cruzada en dos centros de datos para obtener redundancia.
No se requiere que todos los eventos se entreguen, por lo que todos los eventos son filtrados por una aplicación interna que consume eventos de los temas relevantes, verifica cada uno con un conjunto de reglas en el almacén de claves y valores y decide si el evento debe entregarse a un desarrollador específico a través de la API pública. Los eventos se envían a través de un webhook y cada URL de webhook pertenece a un desarrollador identificado por una ID única.
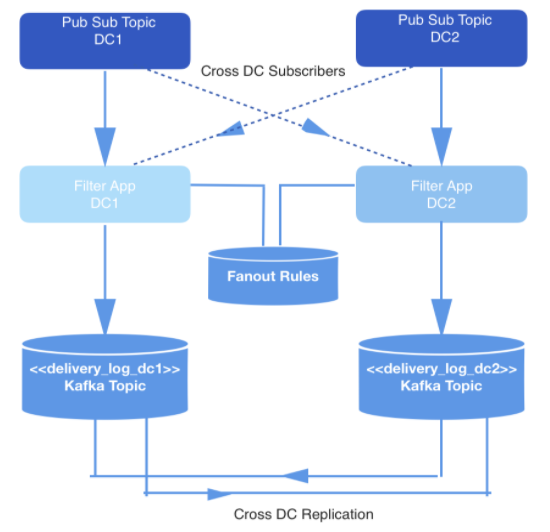
Figura: 1: Canalización de generación de datos
Almacenamiento y segmentación
Normalmente, cuando se crea un sistema de reproducción que requiere un almacén de datos de este tipo, se elige una arquitectura basada en Hadoop y HDFS. En este caso, por el contrario, se eligió Apache Kafka, por dos motivos:
- El sistema para trabajar en tiempo real se basaba en un principio de publicación-suscripción, orgánico para el dispositivo Kafka.
- La cantidad de eventos que deben almacenarse en el sistema de reproducción no está en petabytes. Almacenamos datos durante unos pocos días. Además, lidiar con trabajos de MapReduce para Hadoop es más caro y más lento que consumir datos en Kafka, y la primera opción no cumple con las expectativas de los desarrolladores.
En este caso, la carga principal recae en la canalización de reproducción de datos en tiempo real para garantizar que los eventos que deben entregarse a cada desarrollador se almacenen en Kafka. Llamemos al tema Kafka delivery_log; habrá uno de esos temas para cada centro de datos. Estos temas se replican de forma cruzada para obtener redundancia, lo que permite que se emita una solicitud de replicación desde un solo centro de datos. Los eventos almacenados de esta manera se deduplican antes de la entrega.
En este tema de Kafka, creamos muchas particiones utilizando la fragmentación semántica predeterminada. Por lo tanto, las particiones corresponden al hash de webhookId del desarrollador, y esta identificación sirve como clave para cada entrada. Se suponía que usaba fragmentación estática, pero al final se abandonó debido al mayor riesgo de que una partición contenga más datos que otras, si algunos desarrolladores generan más eventos en el curso de sus actividades que otros. En su lugar, se eligió un número fijo de particiones para distribuir los datos y la estrategia de partición se dejó en el valor predeterminado. Esto reduce el riesgo de particiones desequilibradas y no es necesario leer todas las particiones en el tema de Kafka.
Por el contrario, en función del webhookId para el que se realiza la solicitud, el servicio de reproducción determina la partición específica desde la que leer y genera un nuevo consumidor de Kafka para esa partición. El número de particiones en un tema no cambia, ya que el hash de claves y la distribución de eventos dependen de él.
Para minimizar el espacio de almacenamiento, la información se comprime utilizando el algoritmo rápido , ya que se sabe que la mayor parte de la información en la tarea descrita se procesa en el lado del consumidor. Además, snappy es más rápido de descomprimir que otros algoritmos de compresión compatibles con Kafka: gzip y lz4....
Consultas y tramitación
En un sistema diseñado de esta manera, la API envía solicitudes de reproducción. Como parte de la carga útil de cada solicitud validada, se incluye un webhookId y un rango de datos para los que se deben reproducir los eventos. Estas consultas se almacenan en MySQL durante mucho tiempo y se ponen en cola hasta que son recogidas por el servicio de reproducción. El rango de datos especificado en la solicitud se utiliza para determinar el desplazamiento en el que comenzar a leer desde el disco. La función de
offsetForTimes
objeto se
Consumer
utiliza para obtener las compensaciones.
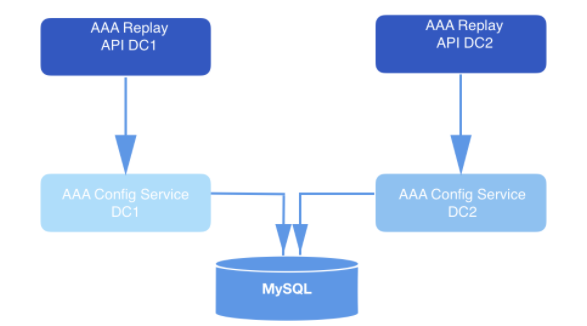
Figura: 2: sistema de reproducción. Recibe la solicitud y la envía al servicio de configuración (capa de acceso a datos) para un mayor almacenamiento a largo plazo en la base de datos.
Las instancias del servicio de reproducción manejan cada solicitud de reproducción. Las instancias se coordinan entre sí mediante MySQL para procesar el siguiente registro de reproducción almacenado en la base de datos. Cada proceso de trabajo de reproducción sondea periódicamente MySQL para ver si hay un trabajo que procesar. La solicitud va de un estado a otro. Una solicitud que no se ha recibido para su procesamiento está en estado ABIERTO. La solicitud que acaba de ser retirada de la cola está en el estado STARTED. La solicitud que se está procesando actualmente está en estado EN CURSO. Una solicitud que ha pasado por todas las transiciones está en el estado COMPLETED. El flujo de trabajo de reproducción solo recoge las solicitudes que aún no han comenzado a procesarse (es decir, en el estado ABIERTO).
Periódicamente, después de que el proceso de trabajo haya eliminado la solicitud de la cola para su procesamiento, se ingresa en la tabla MySQL, dejando marcas de tiempo y, por lo tanto, demostrando que el trabajo de reproducción aún se está procesando. En los casos en que una instancia de flujo de trabajo de reproducción muere antes de que termine de procesar una solicitud, estos trabajos se reinician. Por lo tanto, los procesos de reproducción retiran de la cola no solo las solicitudes en el estado ABIERTO, sino que también recogen aquellas solicitudes que se transfirieron al estado INICIADO o EN CURSO, pero que no recibieron ningún comentario en la base de datos después de un número específico de minutos.
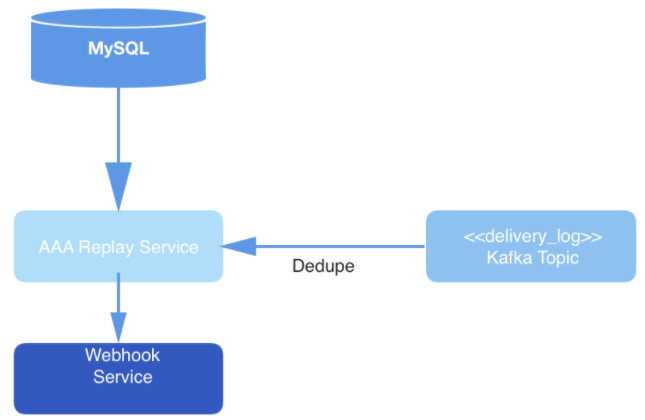
Figura: 3: Capa de entrega de datos: el servicio de reproducción sondea MySQL para un nuevo trabajo de procesamiento de solicitudes, consume la solicitud del tema de Kafka y entrega eventos a través del servicio Webhook.
Finalmente, los eventos del tema se deduplican en el proceso de lectura y luego se publican en la URL del webhook de un usuario específico. La deduplicación se realiza manteniendo un caché de eventos de lectura, que luego se procesan. Si aparece un evento con un hash idéntico al que ya está en el hash, no se entregará.
En general, este uso de Kafka no es tradicional. Pero en el marco del sistema descrito, Kafka funciona con éxito como almacén de datos y participa en el trabajo de la API, lo que contribuye tanto a la usabilidad como a la facilidad de acceso a los datos al recuperar eventos. Los puntos fuertes del sistema para el funcionamiento en tiempo real resultaron útiles en el marco de dicha solución. Además, el ritmo de recuperación de datos en un sistema de este tipo cumple plenamente con las expectativas de los desarrolladores.