Compiladores AOT y JIT
Los procesadores solo pueden ejecutar un conjunto limitado de instrucciones: código de máquina. Para que un programa sea ejecutado por un procesador, debe representarse como código de máquina.
Hay lenguajes de programación compilados como C y C ++. Los programas escritos en estos lenguajes se distribuyen como código de máquina. Después de que se escribe el programa, un proceso especial, el compilador Ahead-of-Time (AOT), generalmente denominado simplemente compilador, traduce el código fuente en código de máquina. El código de máquina está diseñado para ejecutarse en un modelo de procesador específico. Los procesadores con una arquitectura común pueden ejecutar el mismo código. Los modelos de procesador posteriores generalmente admiten instrucciones de modelos anteriores, pero no al revés. Por ejemplo, el código de máquina que utiliza instrucciones AVX para los procesadores Intel Sandy Bridge no se puede ejecutar en procesadores Intel más antiguos. Hay varias formas de resolver este problema, por ejemplo, transfiriendo partes críticas del programa a una biblioteca que tenga versiones para los modelos de procesadores principales.Pero a menudo los programas simplemente se compilan para modelos de procesador relativamente antiguos y no aprovechan los nuevos conjuntos de instrucciones.
A diferencia de los lenguajes de programación compilados, existen lenguajes interpretados como Perl y PHP. Con este enfoque, el mismo código fuente se puede ejecutar en cualquier plataforma para la que exista un intérprete. La desventaja de este enfoque es que el código interpretado es más lento que el código de máquina que hace lo mismo.
El lenguaje Java ofrece un enfoque diferente, un cruce entre lenguajes compilados e interpretados. Las aplicaciones Java se compilan en un código intermedio de bajo nivel: bytecode.
Se eligió el nombre bytecode porque se usa exactamente un byte para codificar cada operación. Hay alrededor de 200 operaciones en Java 10.
Luego, la JVM ejecuta el código de bytes, así como un programa de lenguaje interpretado. Pero dado que el código de bytes tiene un formato bien definido, la JVM puede compilarlo en código de máquina en tiempo de ejecución. Naturalmente, las versiones anteriores de la JVM no podrán generar código de máquina utilizando los nuevos conjuntos de instrucciones del procesador que vienen después. Por otro lado, para acelerar un programa Java, ni siquiera es necesario volver a compilarlo. Es suficiente ejecutarlo en una JVM más nueva.
Compilador HotSpot JIT
Diferentes implementaciones de JVM JIT pueden implementar el compilador de diferentes formas. En este artículo, analizamos Oracle HotSpot JVM y su implementación del compilador JIT. El nombre HotSpot proviene del enfoque que utiliza la JVM para compilar el código de bytes. Normalmente, en una aplicación, solo pequeñas partes del código se ejecutan con la frecuencia suficiente y el rendimiento de la aplicación depende principalmente de la velocidad de ejecución de estas partes en particular. Estas partes del código se denominan puntos calientes y son las que compila el compilador JIT. Varios juicios subyacen a este enfoque. Si el código solo se ejecuta una vez, compilar ese código es una pérdida de tiempo. Otra razón son las optimizaciones. Cuantas más veces la JVM ejecuta cualquier código, más estadísticas acumula, con las cuales puede generar un código más optimizado.Además, el compilador comparte los recursos de la máquina virtual con la propia aplicación, por lo que los recursos gastados en perfilado y optimización podrían utilizarse para ejecutar la propia aplicación, lo que obliga a observar un cierto equilibrio. La unidad de trabajo del compilador HotSpot es un método y un bucle.
La unidad de código compilado se llama nmethod (abreviatura de método nativo).
Compilación escalonada
De hecho, HotSpot JVM no tiene uno, sino dos compiladores: C1 y C2. Sus otros nombres son cliente y servidor. Históricamente, C1 se utilizó en aplicaciones GUI y C2 en aplicaciones de servidor. Los compiladores difieren en la rapidez con la que comienzan a compilar código. C1 comienza a compilar el código más rápido, mientras que C2 puede generar un código más optimizado.
En versiones anteriores de la JVM, tenía que elegir un compilador usando los indicadores -client para el cliente y -server o -d64para la sala de servidores. JDK 6 introdujo el modo de compilación multinivel. En términos generales, su esencia radica en una transición secuencial del código interpretado al código generado por el compilador C1 y luego C2. En JDK 8, los indicadores -client, -server y -d64 se ignoran, y en JDK 11, el indicador -d64 se ha eliminado y da como resultado un error. Puede desactivar el modo de compilación por niveles con el indicador -XX: -TieredCompilation .
Hay 5 niveles de compilación:
- 0 - código interpretado
- 1 - C1 totalmente optimizado (sin creación de perfiles)
- 2 - C1 teniendo en cuenta el número de llamadas a métodos e iteraciones de bucle
- 3 - C1 con perfilado
- 4 - C2
Las secuencias típicas de transiciones entre niveles se muestran en la tabla.
| Secuencia
|
Descripción
|
|---|---|
| 0-3-4 | Intérprete, nivel 3, nivel 4. Más común. |
| 0-2-3-4 | , 4 (C2) . 2. , 3 , , 4. |
| 0-2-4 | , 3 . 4 3. 2 4. |
| 0-3-1 | . 3, , 4 . 1. |
| 0-4 | . |
Code cache
El código de máquina compilado por el compilador JIT se almacena en un área de memoria llamada caché de código. También almacena el código de máquina de la propia máquina virtual, como el código de intérprete. El tamaño de esta área de memoria es limitado y, cuando está llena, se detiene la compilación. En este caso, algunos de los métodos "calientes" continuarán siendo ejecutados por el intérprete. En caso de desbordamiento, la JVM muestra el siguiente mensaje:
Java HotSpot(TM) 64-Bit Server VM warning: CodeCache is full. Compiler has been disabled.
Otra forma de averiguar sobre un desbordamiento de esta área de memoria es habilitar el registro del trabajo del compilador (cómo hacer esto se explica a continuación).
La caché de código se puede configurar de la misma manera que otras áreas de memoria en la JVM. El tamaño inicial lo especifica el parámetro -XX: InitialCodeCacheSize . El tamaño máximo lo especifica el parámetro -XX: ReservedCodeCacheSize . De forma predeterminada, el tamaño inicial es 2496 KB. El tamaño máximo es de 48 MB cuando la compilación por niveles está desactivada y de 240 MB cuando está activada.
Desde Java 9, la caché de código se divide en 3 segmentos (el tamaño total aún está limitado por los límites descritos anteriormente):
- JVM internal (non-method code). , JVM, , . . 5.5 MB. -XX:NonNMethodCodeHeapSize.
- Profiled code. . non-method code . 21.2 MB 117.2 MB . -XX:ProfiledCodeHeapSize.
- Non-profiled code. . non-method code . 21.2 MB 117.2 MB . -XX: NonProfiledCodeHeapSize.
Puede habilitar el registro del proceso de compilación con el indicador -XX: + PrintCompilation (está deshabilitado por defecto). Cuando se establece esta bandera, la JVM escribirá un mensaje en la salida estándar (STDOUT) cada vez que se compile un método o bucle. La mayoría de los mensajes tienen el siguiente formato: timestamp compilation_id atributos tiered_level nombre_método tamaño deopt.
El campo de marca de tiempo es el tiempo transcurrido desde el inicio de la JVM.
El campo compilation_id es el ID interno del problema. Por lo general, crece secuencialmente con cada mensaje, pero a veces el orden puede estar desordenado. Esto puede suceder cuando hay varios subprocesos de compilación ejecutándose en paralelo.
El campo de atributos es un conjunto de cinco caracteres que contienen información adicional sobre el código compilado. Si alguno de los atributos no es aplicable, se muestra un espacio en su lugar. Existen los siguientes atributos:
- % - OSR (reemplazo en la pila);
- s - el método está sincronizado;
- ! - el método contiene un manejador de excepciones;
- b - la compilación se produjo en modo de bloqueo;
- n: el método compilado es un contenedor del método nativo.
OSR significa reemplazo en pila. La compilación es un proceso asincrónico. Cuando la JVM decide que un método debe compilarse, se pone en cola. Mientras se compila el método, la JVM continúa ejecutándolo por el intérprete. La próxima vez que se vuelva a llamar al método, se ejecutará su versión compilada. En el caso de un ciclo largo, esperar a que se complete el método no es práctico; es posible que no se complete en absoluto. La JVM compila el cuerpo del bucle y debería comenzar a ejecutar la versión compilada del mismo. La JVM almacena el estado de los subprocesos en una pila. Para cada método llamado, se crea un nuevo objeto Stack Frame en la pila, que almacena los parámetros del método, las variables locales, el valor de retorno y otros valores. Durante OSR, se crea un nuevo Stack Frame para reemplazar al anterior.
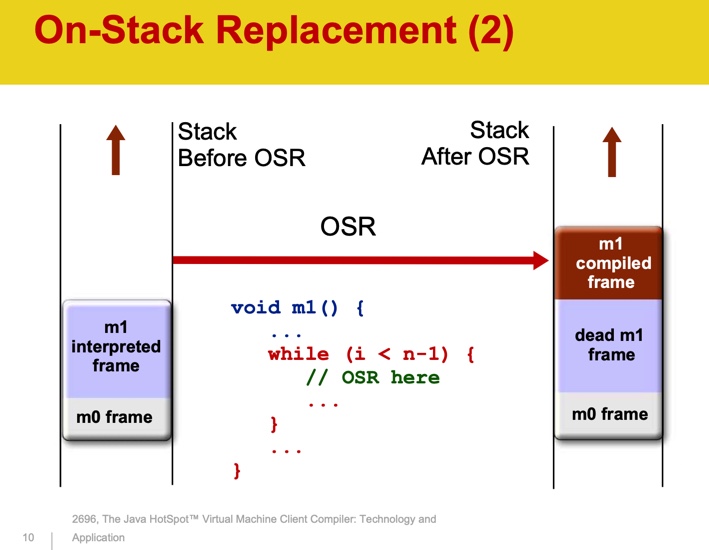
Fuente: Compilador de cliente de máquina virtual Java HotSpotTM: tecnología y aplicación
Los atributos "s" y "!" Creo que no necesitan explicación.
El atributo "b" significa que la compilación no se realizó en segundo plano y no debería encontrarse en las versiones modernas de la JVM.
El atributo "n" significa que el método compilado es un envoltorio de un método nativo.
El campo tiered_level contiene el número de nivel en el que se compiló el código o puede estar vacío si la compilación por niveles está deshabilitada.
El campo nombre_método contiene el nombre del método compilado o el nombre del método que contiene el ciclo compilado.
El campo de tamaño contiene el tamaño del código de bytes compilado, no el tamaño del código de máquina resultante. El tamaño está en bytes.
El campo deopt no aparece en todos los mensajes, contiene el nombre de la desoptimización realizada y puede contener mensajes como "hecho no participante" y "hecho zombie".
A veces, las siguientes entradas pueden aparecer en el registro: timestamp compile_id COMPILE SKIPPED: motivo. Significan que algo salió mal cuando se compiló el método. Hay momentos en los que se espera esto:
- Caché de código lleno: es necesario aumentar el tamaño del área de memoria caché de código.
- Carga de clases concurrente: la clase se modificó en tiempo de compilación.
En todos los casos, excepto por un desbordamiento de la caché de código, la JVM intentará volver a compilar. Si no es así, puede intentar simplificar el código.
Si el proceso se inició sin el indicador -XX: + PrintCompilation, puede ver el proceso de compilación con la utilidad jstat . Jstat tiene dos opciones para mostrar información de compilación.
El parámetro -compiler muestra un resumen de la operación del compilador (5003 es el ID del proceso):
% jstat -compiler 5003 Compiled Failed Invalid Time FailedType FailedMethod 206 0 0 1.97 0
Este comando también muestra el número de métodos que no se pudieron compilar y el nombre del último de esos métodos.
El parámetro -printcompilation imprime información sobre el último método compilado. Combinado con el segundo parámetro, el período de repetición de la operación, puede observar el proceso de compilación a lo largo del tiempo. El siguiente ejemplo ejecuta el comando -printcompilation cada segundo (1000ms):
% jstat -printcompilation 5003 1000 Compiled Size Type Method 207 64 1 java/lang/CharacterDataLatin1 toUpperCase 208 5 1 java/math/BigDecimal$StringBuilderHelper getCharArray
Planes para la segunda parte
En la siguiente parte, veremos los umbrales de contador en los que la JVM comienza a compilar y cómo puede cambiarlos. También veremos cómo la JVM elige el número de subprocesos del compilador, cómo puede cambiarlo y cuándo debe hacerlo. Finalmente, echemos un vistazo rápido a algunas de las optimizaciones realizadas por el compilador JIT.
Referencias y enlaces
- Rendimiento de Java: consejos detallados para ajustar y programar Java 8, 11 y versiones posteriores, Scott Oaks. ISBN: 978-1-492-05611-9.
- Optimización de Java: técnicas prácticas para mejorar el rendimiento de las aplicaciones JVM, Benjamin J. Evans, James Gough y Chris Newland. ISBN: 978-1-492-02579-5.
- JEP 197: caché de código segmentado
- Compilador de cliente de máquina virtual Java HotSpotTM: tecnología y aplicación