En dentsu, creamos Podcaster, una herramienta analítica para medir las audiencias de podcasts y planificar anuncios en ellas. Cómo comenzamos a recopilar datos y resolvimos el problema del reconocimiento de la audiencia, qué dificultades encontramos y qué surgió, te lo contaremos en este artículo.

Antecedentes
La programación de podcasts ahora se basa en datos de vendedores (estudios o agencias especializadas) que se comunican con los autores de podcasts y solicitan descripciones de los oyentes. Los mismos podcasters reciben datos de la plataforma en la que se publica el podcast o de un sistema de estadísticas externo. Hay una serie de limitaciones en este enfoque:
- los podcasts se pueden seleccionar de una lista limitada, con la que el vendedor tiene acuerdos y tiene datos sobre la audiencia del podcast;
- no hay posibilidad de elegir podcasts más afines (la afinidad es la proporción de una audiencia objetivo determinada entre los oyentes y todos los oyentes de podcasts), porque, por regla general, se encuentra disponible una descripción del núcleo de oyentes, y generalmente es la misma en términos de edad para la mayoría de los podcasts
- Los mismos podcasters tienen datos sobre cada podcast, pero ni los podcasts ni los vendedores saben cómo se cruzan los oyentes entre los podcasts.
Para hacer la programación de podcasts más inteligente, intentamos formar un sistema de análisis unificado que se basaría en los datos de la lista de podcasts existentes y la base de usuarios que escuchan estos podcasts, así como en la capacidad de determinar el género y la edad de estos mismos oyentes.
Un acercamiento
Rápidamente nos dimos cuenta de que nosotros mismos no podíamos conseguir audiciones específicas para usuarios. Pero hay me gusta / suscriptores de podcasts: una mecánica similar funciona, por ejemplo, en Instagram con bloggers, cuando una persona se suscribe a un blogger para ver sus noticias. Asumimos que ocurre lo mismo con los podcasts: los oyentes se suscriben a sus podcasts favoritos para que sean rápidamente accesibles y puedan seguir nuevos episodios.
Decidimos probar esta hipótesis utilizando una plataforma popular a través de la cual la audiencia escucha podcasts. Según Tiburon, Yandex.Music es el líder en escuchar podcasts.
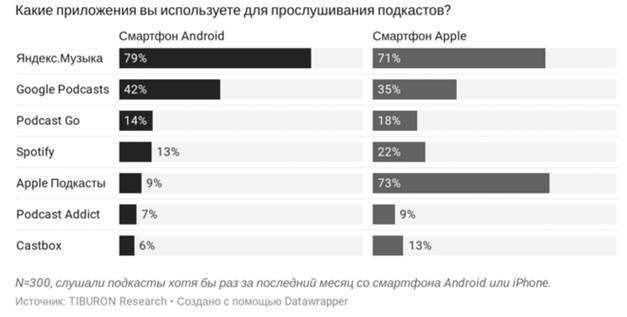
Afortunadamente, Ya Music tiene una página de usuario que proporciona información sobre las suscripciones a podcasts.
Un ejemplo de perfil con fotos y suscripciones a podcasts
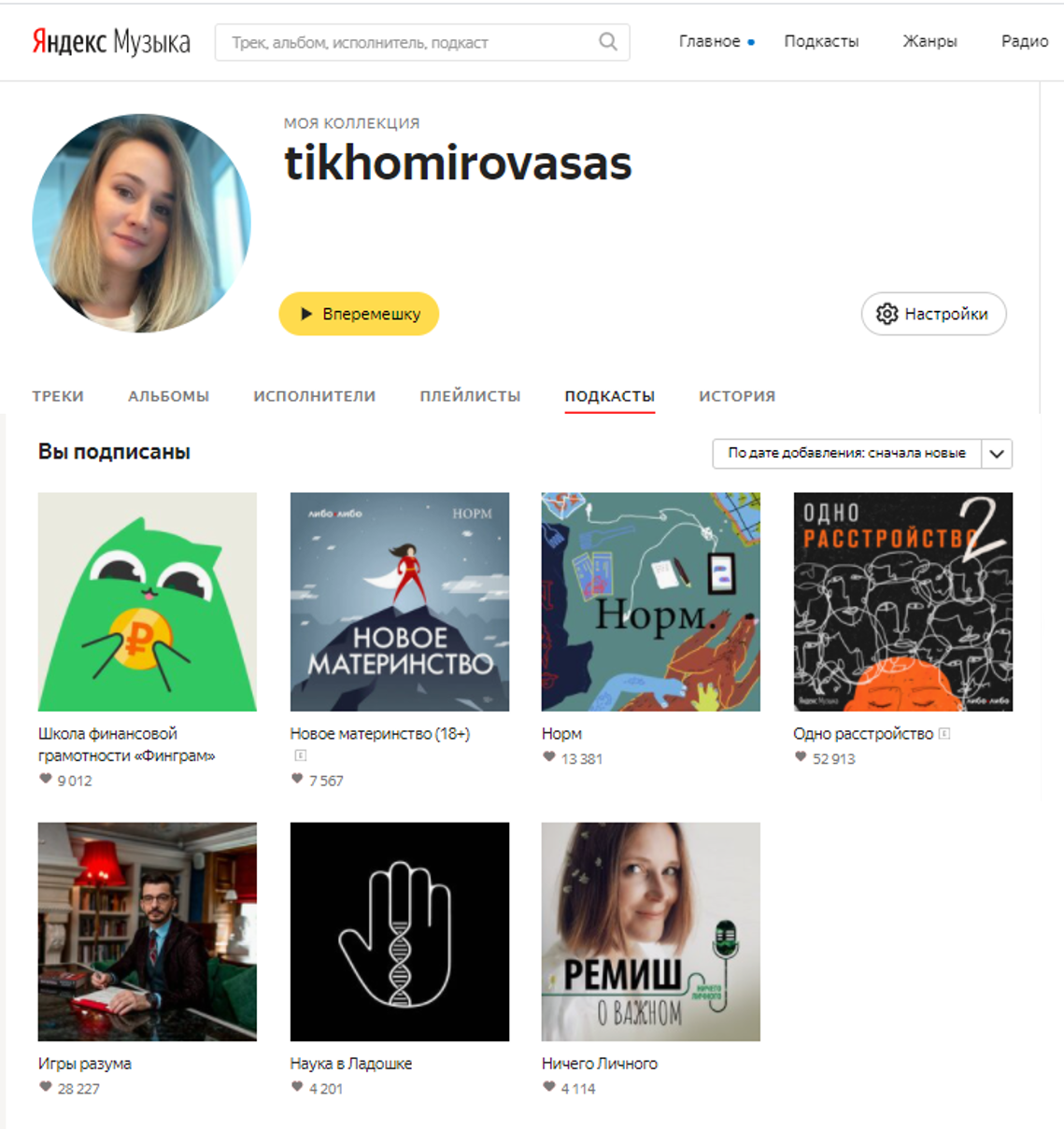
Además de la suscripción en sí, hay un apodo y avatar de usuario en el dominio público. Esto ya es algo, ya que de hecho vemos el núcleo de oyentes de podcasts, es decir, aquellos que los escuchan habitualmente. También aquí tenemos el enlace de usuario-podcast que queríamos encontrar.
Mecánica
Comenzamos a recopilar datos, es decir, usuarios y podcasts a los que se suscribieron los oyentes. Inicialmente, encontramos usuarios de Ya.Muzyka con podcasts sobre los datos de los empleados de dentsu que proporcionaron sus buzones de correo en Yandex. No fue difícil ampliar el proyecto, ya que llevamos varios años trabajando con datos públicos.
La buena noticia fue que la base de suscriptores de podcasts se estaba acumulando muy rápidamente: en solo un mes y medio obtuvimos más de 10,000 usuarios que se suscribieron a al menos un podcast.
Pero también hubo malas noticias: no siempre es posible determinar el género y la edad a ojo por foto y apodo, o más bien, es imposible en absoluto. Para nosotros, para poder seleccionar podcasts relevantes para diferentes públicos, no podemos prescindir del género y la edad. Nuestra red neuronal hizo
frente a esta tarea de determinar el sexo y la edad a partir de una fotografía , cuya precisión es del 96%. El algoritmo es simple: tomamos una foto del usuario J. Music, buscamos una cara y la usamos para determinar el género y la edad. La cara se encuentra en la biblioteca de reconocimiento facial.
usando dlib. Y en el corazón de nuestra red neuronal se encuentra un modelo VGGFace previamente entrenado basado en la arquitectura ResNet-50, que hemos entrenado con fotos de usuarios de VK disponibles a través de la API pública. El conjunto de datos consta de un millón de fotografías que se han aumentado adicionalmente mediante albumentarias. Cabe señalar que no consideramos fotografías de usuarios menores de 12 y mayores de 65 con fines formativos.
resultados
Después de la capacitación, nos dimos cuenta de que en aproximadamente el 45% de los perfiles de usuario con podcasts, podemos determinar el género y la edad, ya que hay muchos perfiles sin una foto o una imagen, un símbolo o simplemente una foto de mala calidad. Pero incluso este resultado nos conviene.
Dada la dinámica de búsqueda de perfiles que se suscriban a podcasts, esperamos que en unos meses la base de oyentes sea de 50.000 perfiles, y 22.500 de ellos tendrán género y edad.
Ejemplo de perfil por el que no podemos determinar género y edad
Los desarrollos actuales nos permiten realizar muestras de podcasts afines para diferentes grupos de audiencia.
Una selección de podcasts para 20-50 en temas relevantes para la marca.

Afinidad = público objetivo entre los oyentes de podcasts / todos los oyentes de podcasts) / (todos los oyentes de podcasts / todas las personas con podcasts)
También podemos analizar un podcast específico si el anunciante está interesado en él.
Al ver cuántas personas están suscritas a los podcasts, podemos hacer recomendaciones sobre el paquete de podcast que generarán el mayor alcance.
Curva de cobertura para 50 podcasts seleccionados
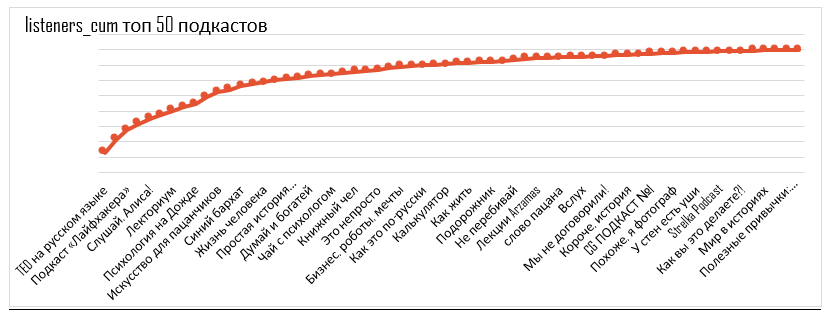
Cada punto +1 podcast por mezcla. El primer punto es el podcast con la audiencia única más grande, el último punto es el podcast con la audiencia única más pequeña.
Mecánica de curvas y modelo matemático
En primer lugar, tomamos el podcast que tiene mayor audiencia, en nuestro caso es el podcast 3. A continuación se muestra una tabla que revela la lógica de la búsqueda, es decir, el principio de repartir conciliadores entre podcasts.

A continuación, tachamos los oyentes a los que llegamos con el podcast 3, y nuevamente seleccionamos el podcast con la audiencia más singular (podcast 4). Este es un podcast que nos brinda 2 nuevos oyentes únicos, por lo que recomendamos colocarlo a continuación.

Repetimos el ejercicio, y resulta que no cubriremos más oyentes únicos, es decir, la colocación en 2 de 6 podcasts es suficiente para cubrir a toda la audiencia única posible.

conclusiones
No respondimos todas las preguntas, por lo que continuamos buscando datos. Por ejemplo, recientemente Ya.Muzyka comenzó a publicar información sobre la cantidad de audiencia suscrita para cada uno de los podcasts. Ahora entendemos el volumen de los oyentes recopilados del total.
Estamos trabajando en la mecánica de combinar datos de suscripción con datos de sitios y podcasters para refinar el modelo para estimar el número y la composición de los oyentes. Pero ya ahora, nuestro enfoque está ayudando a cambiar el esquema de planificación para las integraciones publicitarias en los podcasts y no procede de datos agregados de la intuición de los vendedores o anunciantes sobre la audiencia del podcast, sino de la audiencia de la marca. Y también para componer paquetes de podcast que sean relevantes específicamente para la audiencia de esta marca y construir el máximo alcance para ella.
Autor Sasha_Kopylova