¡Hola! Mi nombre es Dmitry Shelamov y trabajo en Vivid.Money como desarrollador backend en el departamento de atención al cliente. Nuestra empresa es una startup europea que crea y desarrolla servicios de banca por Internet para países europeos. Esta es una tarea ambiciosa, lo que significa que su implementación técnica requiere una infraestructura bien pensada que pueda soportar altas cargas y escalar de acuerdo con los requisitos comerciales.
El proyecto se basa en una arquitectura de microservicios, que incluye decenas de servicios en diferentes idiomas. Estos incluyen Scala, Java, Kotlin, Python y Go. Este último es donde escribo el código, por lo que los ejemplos prácticos de esta serie usarán principalmente Go (y un poco de docker-compose).
Trabajar con microservicios tiene sus propias características, una de las cuales es la organización de las comunicaciones entre servicios. El modelo de interacción en estas comunicaciones puede ser sincrónico o asincrónico y puede tener un impacto significativo en el rendimiento y la tolerancia a fallas del sistema en su conjunto.
Comunicación asíncrona
Entonces, imaginemos que tenemos dos microservicios (A y B). Asumiremos que la comunicación entre ellos se realiza a través de la API y no saben nada sobre la implementación interna de cada uno, según lo prescrito por el enfoque de microservicio. El formato de los datos transmitidos entre ellos está previamente acordado.
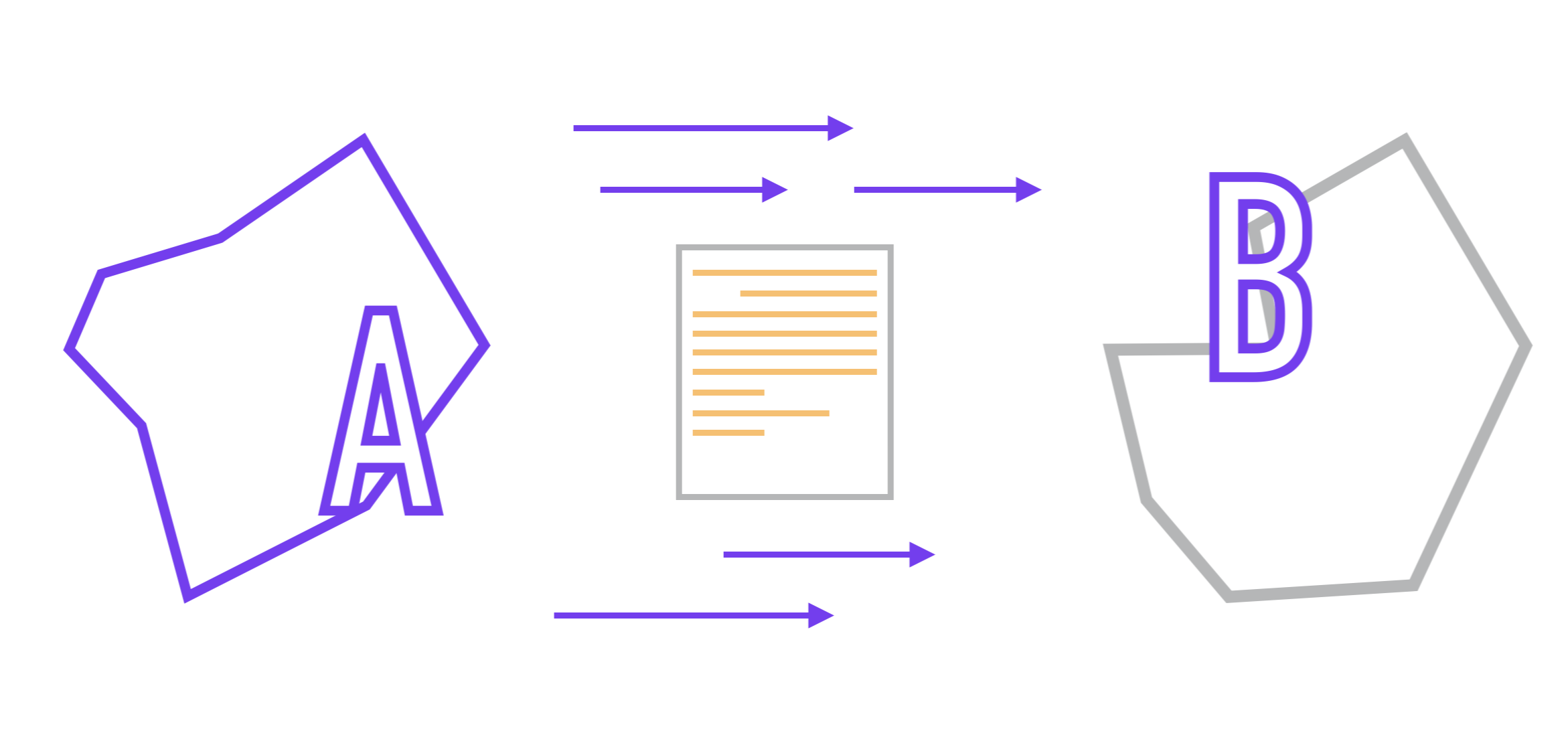
La tarea que tenemos ante nosotros es la siguiente: necesitamos organizar la transferencia de datos de una aplicación a otra y, preferiblemente, con retrasos mínimos.
En el caso más simple, la tarea se logra mediante interacción síncrona , cuando A envía una solicitud a la aplicación B, luego de lo cual el servicio B la procesa y, dependiendo de si la solicitud se procesó con éxito o no, envía una respuesta.servicio A que espera esta respuesta.
Si no se ha recibido la respuesta a la solicitud (por ejemplo, B interrumpe la conexión antes de enviar la respuesta, o A cae por tiempo de espera), el servicio A puede repetir su solicitud a B.
Por un lado, este modelo de interacción da certeza del estado de entrega de datos para cada solicitud cuando el remitente sabe con certeza si el destinatario recibió los datos y qué acciones adicionales debe realizar en función de la respuesta.
Por otro lado, el precio a pagar está esperando. Después de enviar una solicitud, el servicio A (o el hilo en el que se ejecuta la solicitud) se bloquea hasta que recibe una respuesta o considera que la solicitud no se ha realizado correctamente de acuerdo con su lógica interna, después de lo cual toma otras acciones.
El problema no es solo que se producen tiempos de espera y de inactividad, sino que los retrasos en la comunicación de la red son inevitables. El principal problema es la imprevisibilidad de este retraso. Los participantes de la comunicación en el enfoque de microservicio no conocen los detalles de la implementación de los demás, por lo tanto, no siempre es obvio para la parte solicitante si su solicitud se procesa de manera rutinaria o si los datos deben volver a enviarse.
Todo lo que queda de este modelo de interacción es simplemente esperar. Quizás un nanosegundo, quizás una hora. Y esta cifra es bastante real si B, en el proceso de procesamiento de datos, realiza operaciones pesadas, como el procesamiento de video.
Quizás el problema no le pareció importante: una pieza de hierro está esperando que la otra responda, ¿es grande la pérdida?
Para hacer este problema más personal, suponga que el servicio A es una aplicación que se ejecuta en su teléfono y mientras espera una respuesta de B, ve una animación de carga en la pantalla. No puede continuar usando la aplicación hasta que el servicio B responda y debe esperar. Cantidad de tiempo desconocida. Dado que su tiempo es mucho más valioso que el tiempo de ejecución de un fragmento de código.
Dicha aspereza se resuelve de la siguiente manera: divide a los participantes de la interacción en dos "campos": algunos no pueden trabajar más rápido, sin importar cómo los optimice (procesamiento de video), mientras que otros no pueden esperar más de un cierto tiempo (interfaz de la aplicación en su teléfono).
Luego reemplazas la sincronizaciónla interacción entre ellos (cuando una parte se ve obligada a esperar a la otra para asegurarse de que los datos han sido entregados y procesados por el servicio receptor) a asincrónica , es decir, el modelo de trabajo se envía y se olvida ; en este caso, el servicio A continuará su trabajo sin esperar una respuesta de B.
Pero, ¿cómo puede asegurarse de que la transferencia se haya realizado correctamente en este caso? No puede, por ejemplo, después de subir un video a un servicio de alojamiento de videos, mostrar un mensaje al usuario: "su video puede ser procesado, pero puede que no", porque el servicio que descarga el video no ha recibido la confirmación del procesador de servicio de que el video ha llegado él sin incidentes.
Como una de las soluciones a este problema, podemos agregar una capa entre los servicios A y B, que actuará como almacenamiento temporal y garante de la entrega de datos a un ritmo conveniente para el remitente y el receptor. Así, podremos desacoplar servicios, cuya interacción sincrónica podría ser potencialmente problemática:
- Los datos que se pierden cuando el servicio de recepción finaliza de forma anormal ahora se pueden recuperar del almacén provisional mientras el servicio de envío sigue haciendo su trabajo. De esta forma, obtenemos un mecanismo de garantía de entrega ;
- Esta capa también protege a los destinatarios de las sobrecargas, porque el destinatario recibe los datos a medida que se procesan y no a medida que llegan;
- Las solicitudes de operaciones pesadas (como la reproducción de video) ahora se pueden pasar a través de esta capa, proporcionando menos conectividad entre las partes rápida y lenta de la aplicación.
Un DBMS ordinario es bastante adecuado para los requisitos anteriores. Los datos que contiene se pueden almacenar durante mucho tiempo sin preocuparse por la pérdida de información. También se excluye la sobrecarga de destinatarios, porque son libres de elegir el ritmo y los volúmenes de lectura de los registros destinados a ellos. La confirmación del procesamiento se puede realizar marcando los registros leídos en las tablas correspondientes.
Sin embargo, elegir un DBMS como herramienta de intercambio de datos puede generar problemas de rendimiento a medida que aumenta la carga de trabajo. Esto se debe a que la mayoría de las bases de datos no están diseñadas para este caso de uso. Además, muchos DBMS carecen de la capacidad de separar a los clientes conectados en destinatarios y remitentes (Pub / Sub); en este caso, la lógica de entrega de datos debe implementarse en el lado del cliente.
Probablemente necesitemos algo más especializado que una base de datos.
Corredores de mensajes
Un agente de mensajes (cola de mensajes) es un servicio independiente que se encarga de almacenar y entregar datos de los servicios del remitente a los servicios del destinatario mediante el modelo Pub / Sub.
Este modelo asume que la comunicación asincrónica sigue la siguiente lógica de dos roles:
- Los editores publican nueva información como mensajes agrupados por algún atributo;
- Los suscriptores se suscriben a flujos de mensajes con atributos específicos y los procesan.
El atributo de agrupación de mensajes es la cola , que es necesaria para separar los flujos de datos; por lo tanto, los destinatarios pueden suscribirse solo a los grupos de mensajes que les interesan.
Similar a suscribirse a varias plataformas de contenido: al suscribirse a un autor específico, puede filtrar el contenido eligiendo ver solo el que le interesa.

Se puede pensar en la cola como un canal de comunicación extendido entre el escritor y el lector. Los escritores colocan mensajes en una cola, después de lo cual se “envían” a los lectores que se han suscrito a esa cola. Un lector recibe un mensaje a la vez, después de lo cual se vuelve inaccesible para otros lectores.
Un mensaje, por otro lado, es una unidad de datos, que generalmente consta de un cuerpo de mensaje y metadatos del agente.
En general, un cuerpo es una colección de bytes en un formato específico.
El destinatario debe conocer este formato para poder deserializar su cuerpo para su posterior procesamiento después de recibir un mensaje.
Puede usar cualquier formato conveniente, sin embargo, es importante recordar la compatibilidad con versiones anteriores, que es compatible, por ejemplo, con el binario Protobuf y el marco Apache Avro.
La mayoría de los agentes de mensajes basados en AMQP (Protocolo de cola de mensajes avanzado) funcionan según este principio, un protocolo que describe un estándar para la mensajería tolerante a errores a través de colas.
Este enfoque nos proporciona varias ventajas importantes:
- Cohesión débil. Se logra mediante la transmisión de mensajes asincrónica: es decir, el remitente deja caer los datos y sigue trabajando sin esperar una respuesta del receptor, y el receptor lee y procesa los mensajes cuando le conviene y no cuando le fueron enviados. En este caso, la cola se puede comparar con un buzón en el que el cartero pone tus cartas, y las recoges cuando te conviene.
- . , ( , ), - .
, . - . - . , , : , , , -, .
- . “at least once” “at most once”.
Como mucho una vez elimina el reprocesamiento de mensajes, pero permite que se pierdan. En este caso, el corredor entregará mensajes a los destinatarios "enviar y olvidar". Si el destinatario no pudo, por alguna razón, procesar el mensaje en el primer intento, el corredor no lo reenviará.
Al menos una vez , en cambio, garantiza que el destinatario recibirá el mensaje, pero existe la posibilidad de reprocesar los mismos mensajes.
A menudo, esta garantía se logra utilizando el mecanismo Ack / Nack (reconocimiento / reconocimiento negativo) , que prescribe reenviar un mensaje si el destinatario, por alguna razón, no pudo procesarlo.
Por lo tanto, para cada mensaje enviado por el corredor (pero aún no procesado), hay tres estados finales: el receptor devolvió Ack (procesamiento exitoso), devolvió Nack (procesamiento incorrecto ) o cortó la conexión. Los dos últimos escenarios dan como resultado el reenvío y el reprocesamiento de mensajes.
Sin embargo, el corredor puede reenviar el mensaje incluso si el receptor lo procesa correctamente. Por ejemplo, si el destinatario procesó el mensaje, pero salió sin enviar una señal de Ack al corredor.
En este caso, el corredor volverá a poner el mensaje en la cola, después de lo cual se procesará nuevamente, lo que puede provocar errores y corrupción de datos, si el desarrollador no ha proporcionado un mecanismo para eliminar duplicados del lado del destinatario.
Vale la pena señalar que existe otra garantía de entrega denominada "exactamente una vez" . Es difícil de conseguir en sistemas distribuidos, pero también es el más deseable.
En este sentido, Apache Kafka, del que hablaremos más adelante, destaca favorablemente en el contexto de muchas soluciones disponibles en el mercado. Desde la versión 0.11, Kafka ofrece una garantía de entrega exactamente una vezdentro de un clúster y transacciones, mientras que los corredores de AMQP no pueden ofrecer tales garantías. Transacciones en Kafka es un tema para una publicación separada, hoy comenzaremos conociendo Apache Kafka.
Apache Kafka
Me parece que será útil para la comprensión comenzar la historia de Kafka con una representación esquemática del dispositivo de racimo.
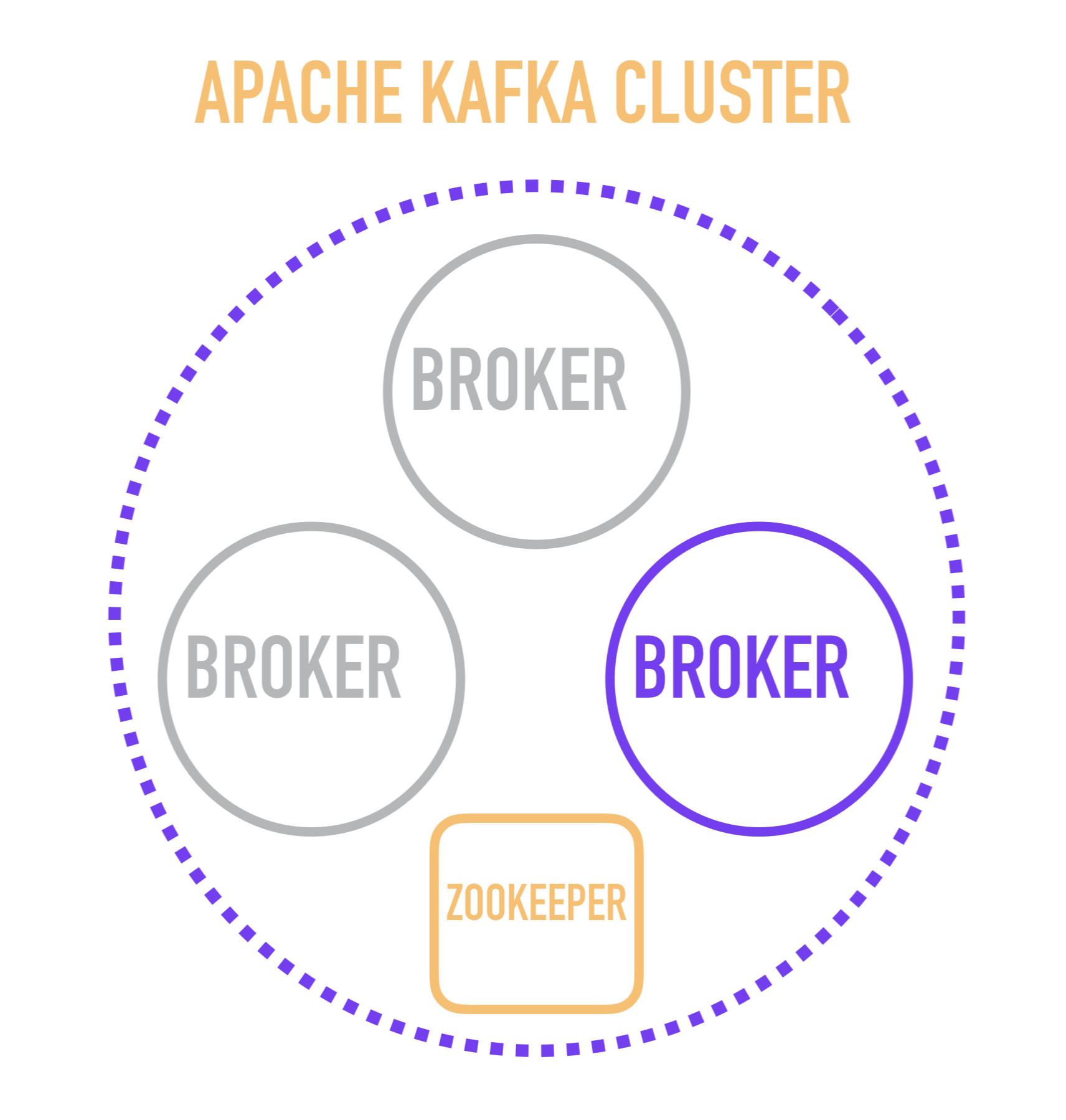
Un servidor de Kafka independiente se denomina intermediario . Los corredores forman un clúster en el que uno de estos corredores actúa como un controlador que se hace cargo de algunas de las operaciones administrativas (marcadas en violeta).
La elección de un intermediario-controlador, a su vez, es responsabilidad de un servicio separado: ZooKeeper, que también realiza el descubrimiento de servicios de los intermediarios, almacena configuraciones y participa en la distribución de nuevos lectores entre los intermediarios, y en la mayoría de los casos almacena información sobre el último mensaje leído para cada uno de los lectores. Este es un punto importante, cuyo estudio requiere que baje un nivel y considere cómo funciona internamente un corredor individual.
Confirmar registro
La estructura de datos detrás de Kafka se llama registro de confirmación o registro de confirmación.

Los nuevos elementos agregados al registro de confirmación se colocan estrictamente al final, y su orden posterior no se cambia, de modo que en cada registro individual los elementos siempre se enumeran en el orden en que se agregaron.
La propiedad de ordenación del registro de confirmación permite que se utilice, por ejemplo, para la replicación de acuerdo con el principio de consistencia eventual entre las réplicas de la base de datos: almacenan un registro de los cambios realizados en los datos en el nodo maestro, cuya aplicación secuencial en los nodos esclavos permite llevar los datos en ellos a lo acordado con el maestro. mente.
En Kafka, estos registros se denominan particiones y los datos almacenados en ellos se denominan mensajes .
¿Qué es un mensaje? Es la unidad básica de datos en Kafka y es simplemente una colección de bytes en la que puede pasar información arbitraria; su contenido y estructura son irrelevantes para Kafka. El mensaje puede contener una clave, que también es un conjunto de bytes. La clave le permite tener más control sobre el mecanismo para distribuir mensajes a las particiones.
Particiones y temas
¿Por qué esto podría ser importante? El hecho es que una partición no es análoga a una cola en Kafka, como podría parecer a primera vista. Permítame recordarle que técnicamente una cola de mensajes es un medio para agrupar y administrar los flujos de mensajes, lo que permite que ciertos lectores se suscriban solo a ciertos flujos de datos.
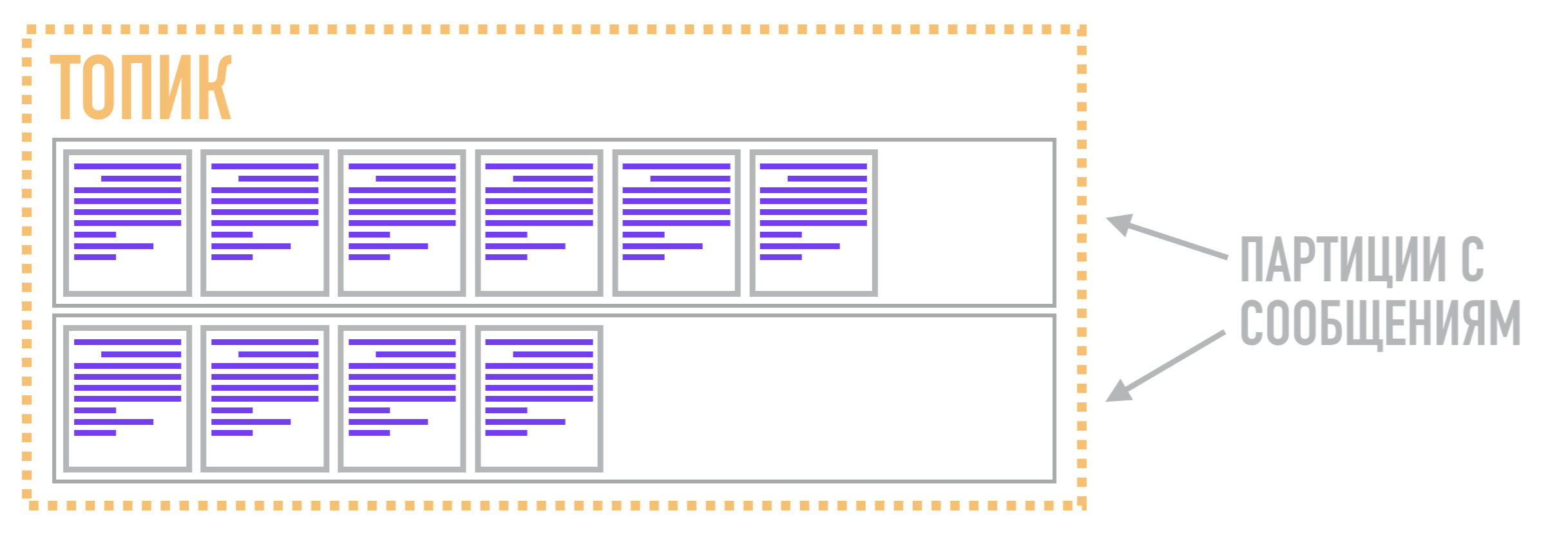
Entonces, en Kafka, la función de la cola no la realiza la partición, sino el tema . Es necesario combinar varias particiones en un flujo común. Las particiones en sí mismas, como dijimos anteriormente, almacenan mensajes en una forma ordenada de acuerdo con la estructura de datos del registro de confirmación. Por lo tanto, un mensaje relacionado con un tema se puede almacenar en dos particiones diferentes, de las cuales los lectores pueden extraerlos si lo solicitan.
Por lo tanto, la unidad de paralelismo en Kafka no es un tema (o una cola en los corredores AMQP), sino una partición. Debido a esto, Kafka puede procesar diferentes mensajes relacionados con el mismo tema en varios corredores al mismo tiempo, y también replicar no todo el tema como un todo, sino solo particiones individuales, lo que proporciona flexibilidad y escalabilidad adicionales en comparación con los corredores AMQP.
Tire y empuje
Tenga en cuenta que no utilicé accidentalmente la palabra "saca" en relación con el lector.
En los intermediarios descritos anteriormente, la entrega de mensajes se logra empujándolos ( push ) a los destinatarios a través de una tubería convencional.
En Kafka, el proceso de entrega en sí no lo es: cada lector es responsable de extraer ( extraer ) mensajes de las particiones, que lee.
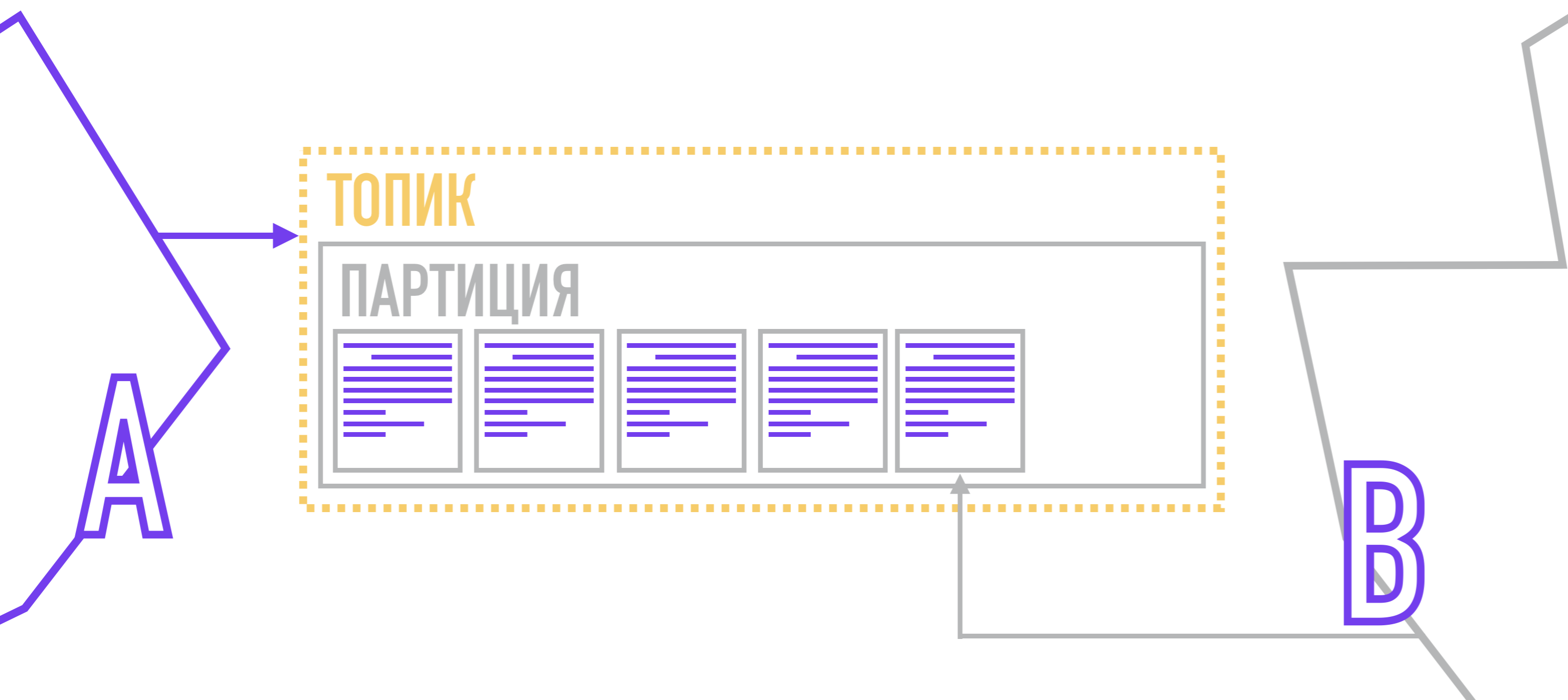
Los productores, formando mensajes, le adjuntan una clave y un número de partición. El número de partición se puede elegir al azar (round-robin) si el mensaje no tiene una clave.
Si necesita más control, puede adjuntar una clave al mensaje y luego usar una función hash o escribir su propio algoritmo mediante el cual se seleccionará la partición para el mensaje. Después de la formación, el productor envía un mensaje a Kafka, que lo guarda en el disco, indicando a qué partición pertenece.
A cada destinatario se le asigna una partición específica (o varias particiones) en el tema de interés, y cuando aparece un nuevo mensaje, recibe una señal para leer el siguiente elemento en el registro de confirmación, mientras anota el último mensaje que leyó. Por lo tanto, al volver a conectarse, sabrá qué mensaje leer a continuación.
¿Cuáles son las ventajas de este enfoque?
- . , , . , ( Retention Policy, ), .
- Message Replay. , . , , .
- . , ( ) – , .
- . (batch) , , . : (1 ), .
Las desventajas de este enfoque incluyen trabajar con mensajes de problemas. A diferencia de los corredores clásicos, los mensajes rotos (que no se pueden procesar teniendo en cuenta la lógica existente del destinatario o debido a problemas con la deserialización) no se pueden volver a poner en cola indefinidamente hasta que el destinatario aprenda a procesarlos correctamente.
En Kafka, de forma predeterminada, la lectura de mensajes de la partición se detiene cuando el destinatario llega al mensaje roto, y hasta que se omite y se lanza a la cola de "cuarentena" (también llamada "cola de mensajes no entregados ") para su procesamiento posterior, continúe leyendo la partición. no trabajará.
También en Kafka es más difícil (en comparación con los corredores AMQP) implementar la prioridad de los mensajes. Esto se deriva directamente del hecho de que los mensajes en las particiones se almacenan y leen estrictamente en el orden en que se agregaron. Una de las formas de sortear esta limitación en Kafka es crear varios temas para mensajes con diferentes prioridades (los temas solo diferirán en el nombre), por ejemplo, events_low, events_medium, events_high , y luego implementar la lógica de lectura prioritaria de los temas enumerados en el lado de la aplicación del consumidor.
Otro inconveniente de este enfoque está asociado con el hecho de que es necesario mantener registros del último mensaje leído en la partición por cada uno de los lectores. Debido a la simplicidad de la estructura de las particiones, esta información se presenta en forma de un valor entero llamado desplazamiento (desplazamiento). Offset le permite determinar qué mensaje está leyendo actualmente cada uno de los lectores. La analogía más cercana al desplazamiento es el índice de un elemento en una matriz, y el proceso de lectura es similar a caminar a través de la matriz en un bucle utilizando un iterador como índice del elemento.
Sin embargo, este inconveniente se nivela debido al hecho de que Kafka, a partir de la versión 0.9, almacena las compensaciones para cada usuario en un tema especial __consumer_offsets (antes de la versión 0.9, las compensaciones se almacenaban en ZooKeeper).
Además, puede realizar un seguimiento de las compensaciones directamente en el lado del destinatario.

El escalado también se vuelve más complicado: permítame recordarle que en los corredores de AMQP, para acelerar el procesamiento del flujo de mensajes, solo necesita agregar varias instancias del servicio de lectura y suscribirlas a una cola, y no necesita realizar ningún cambio en la configuración del propio corredor.
Sin embargo, escalar es un poco más difícil en Kafka que en los corredores AMQP. Por ejemplo, si agrega otra instancia del lector y la configura en la misma partición, obtendrá una eficiencia cero, ya que en este caso ambas instancias leerán el mismo conjunto de datos.
Por lo tanto, la regla básica para el escalado de Kafka es que el número de lectores competitivos (es decir, un grupo de servicios que implementan la misma lógica de procesamiento (réplicas)) de un tema no debe exceder el número de particiones en este tema, de lo contrario, algunos lectores procesarán el mismo conjunto de datos.
Grupo de consumidores
Para evitar la situación con la lectura de una partición por lectores de la competencia, en Kafka se acostumbra combinar varias réplicas de un servicio en un grupo de consumidores , dentro del cual Zookeeper no asignará más de un lector a una partición.
Dado que los lectores están vinculados directamente a la partición (mientras que el lector generalmente no sabe nada sobre el número de particiones en el tema), ZooKeeper, cuando se conecta un nuevo lector, redistribuye miembros al Grupo de consumidores para que cada partición tenga un solo lector.
El lector designa su grupo de consumidores cuando se conecta a Kafka.
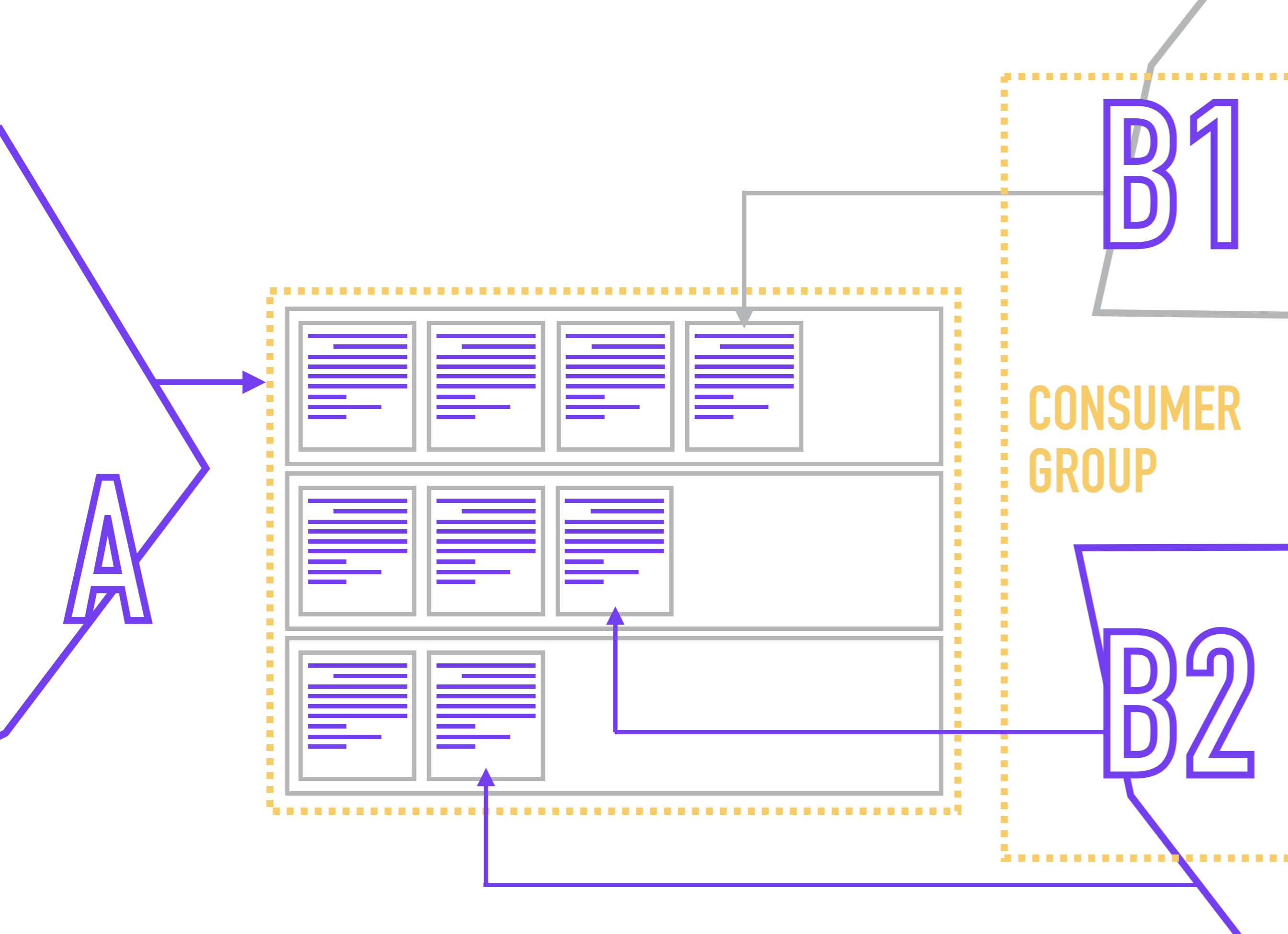
Al mismo tiempo, nada le impide colgar varios lectores con lógica de procesamiento diferente en una partición. Por ejemplo, almacena en un tema una lista de eventos por acciones del usuario y desea utilizar estos eventos para generar varias vistas de los mismos datos (por ejemplo, para analistas de negocios, analistas de productos, analistas de sistemas y el paquete Yarovaya) y luego enviarlos a los repositorios apropiados.
Pero aquí podemos enfrentar otro problema, causado por el hecho de que Kafka usa una estructura de temas y particiones. Permítanme recordarles que Kafka no garantiza el orden de los mensajes dentro de un tema, solo dentro de una partición, lo que puede ser crítico, por ejemplo, al generar informes sobre las acciones de los usuarios y enviarlos al almacenamiento tal cual.
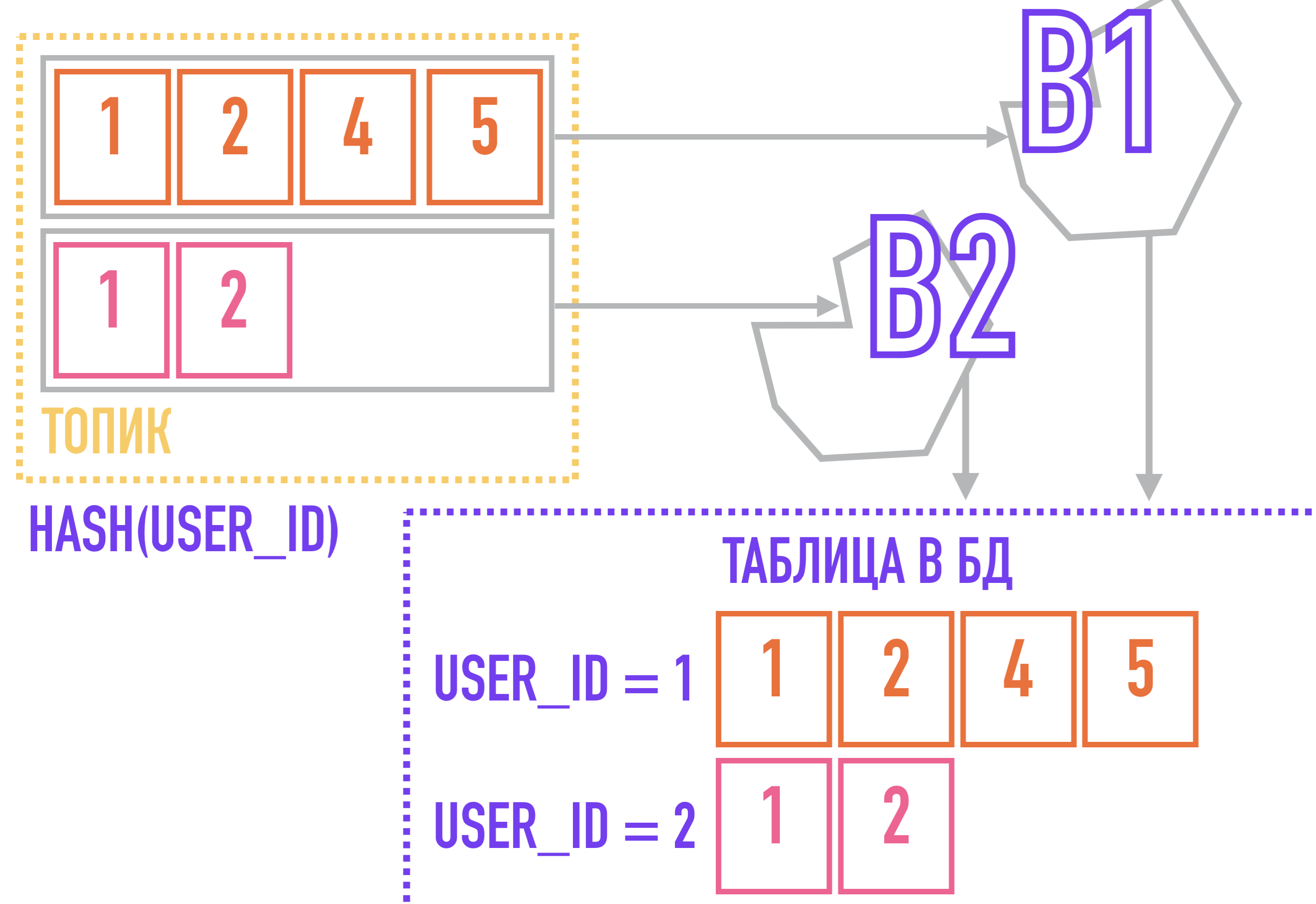
Para resolver este problema, podemos pasar de lo contrario: si todos los eventos relacionados con una entidad (por ejemplo, todas las acciones relacionadas con el mismo user_id) se agregan siempre a la misma partición, se ordenarán dentro del tema simplemente porque están en la misma partición, el orden dentro del cual está garantizado por Kafka.
Para hacer esto, necesitamos una clave para los mensajes: por ejemplo, si usamos un algoritmo que calcula el hash a partir de la clave para seleccionar la partición a la que se agregará el mensaje, entonces se garantizará que los mensajes con la misma clave caigan en una partición y, por lo tanto, extraiga el destinatario del mensaje. con la misma clave en el orden en que se agregaron al tema.
En un caso con un flujo de eventos sobre las acciones del usuario, la clave de partición puede ser user_id.
Política de retención
Ahora es el momento de hablar sobre la Política de retención.
Esta es una configuración que se encarga de eliminar mensajes del disco cuando se exceden los umbrales para la fecha de adición ( Política de retención basada en el tiempo ) o el espacio ocupado en el disco ( Política de retención basada en el tamaño ).
- Si configura TBRP durante 7 días, todos los mensajes que tengan más de 7 días se marcarán para su posterior eliminación. En otras palabras, esta configuración garantiza que los mensajes por debajo del umbral de edad sean legibles en cualquier momento. Puede configurarse en horas, minutos y milisegundos.
- SBRP funciona de manera similar: cuando se excede el umbral de espacio en disco, los mensajes se marcarán para su eliminación desde el final (más antiguo). Debe tenerse en cuenta: dado que la eliminación de mensajes no es instantánea, el espacio en disco ocupado siempre será un poco mayor que el especificado en la configuración. Establecer en bytes.
La política de retención se puede configurar tanto para todo el clúster como para temas individuales: por ejemplo, los mensajes de un tema para rastrear las acciones del usuario se pueden almacenar durante varios días, mientras que las notificaciones push se pueden almacenar durante varias horas. Al eliminar los datos según su relevancia, ahorramos espacio en disco, lo que puede ser importante a la hora de elegir un SSD como almacenamiento en disco principal.
Política de compactación
Otra forma de optimizar el espacio en disco es utilizar la Política de compactación: esta configuración le permite almacenar solo el último mensaje para cada clave, eliminando todos los mensajes anteriores. Esto puede ser útil cuando solo estamos interesados en el último cambio.
Casos de uso de Kafka
- . : . , , , (Clickhouse !) .
Customer Care Vivid.Money CRM. - . , . , - ( ) , , .
, ( ) . , , , , . - . , .
- (commit log). , - / .
, , «» .
Customer Care CRM- .
Kafka
- – , ;
- – (pull) , . (, ) Consumer Group, ZooKeeper, , , , ;
- . , , , . , () ;
- , , AMQP , – . , ;
- . , , --, – .