
Este problema también surge al diseñar agentes artificiales. Por ejemplo, un agente de aprendizaje por refuerzo puede encontrar la ruta más corta para recibir una gran cantidad de recompensas sin completar la tarea según lo previsto por el diseñador humano. Este comportamiento es común y hemos recopilado alrededor de 60 ejemplos hasta la fecha (combinando listas existentes y contribuciones actuales de la comunidad de IA). En esta publicación, analizaremos las posibles causas del juego de acuerdo con la especificación, compartiremos ejemplos de dónde sucede en la práctica y también discutiremos la necesidad de seguir trabajando en enfoques basados en principios para superar los problemas de especificación.
Veamos un ejemplo. En la tarea de construcción con bloques de Lego, el resultado deseado era que el bloque rojo estuviera por encima del azul. El agente fue recompensado por la altura de la superficie inferior del bloque rojo en el momento en que no tocó este bloque. En lugar de pasar por la maniobra relativamente difícil de recoger el bloque rojo y colocarlo encima del azul, el agente simplemente volteó el bloque rojo para recoger la recompensa. Este comportamiento nos permitió lograr nuestro objetivo (la parte inferior del bloque rojo era alta) a expensas de lo que realmente le importa al diseñador (construir en la parte superior del bloque azul).

Aprendizaje por refuerzo profundo para una hábil manipulación de datos.
Podemos mirar el juego de las especificaciones desde dos perspectivas. Como parte del desarrollo de algoritmos de aprendizaje por refuerzo (RL), el objetivo es crear agentes que aprendan a lograr un objetivo determinado. Por ejemplo, cuando usamos los juegos de Atari como punto de referencia para enseñar algoritmos RL, el objetivo es evaluar si nuestros algoritmos son capaces de resolver problemas complejos. Si un agente resuelve un problema, utilizando una laguna jurídica o no, no es importante en este contexto. Desde este punto de vista, jugar según las especificaciones es una buena señal: el agente ha encontrado una nueva forma de lograr este objetivo. Este comportamiento demuestra el ingenio y el poder de los algoritmos para encontrar formas de hacer exactamente lo que les decimos que hagan.
Sin embargo, cuando queremos que un agente conecte los bloques de Lego, ese mismo ingenio puede crear un problema. En el marco más amplio de la construcción de agentes específicos que logran un resultado deseado en el mundo, el juego de especificación es problemático porque implica que el agente explote una laguna de especificación a expensas del resultado deseado. Este comportamiento se debe a una configuración incorrecta del problema y no a una falla en el algoritmo RL. Además de diseñar algoritmos, otro componente necesario para crear agentes específicos es el diseño de recompensas.
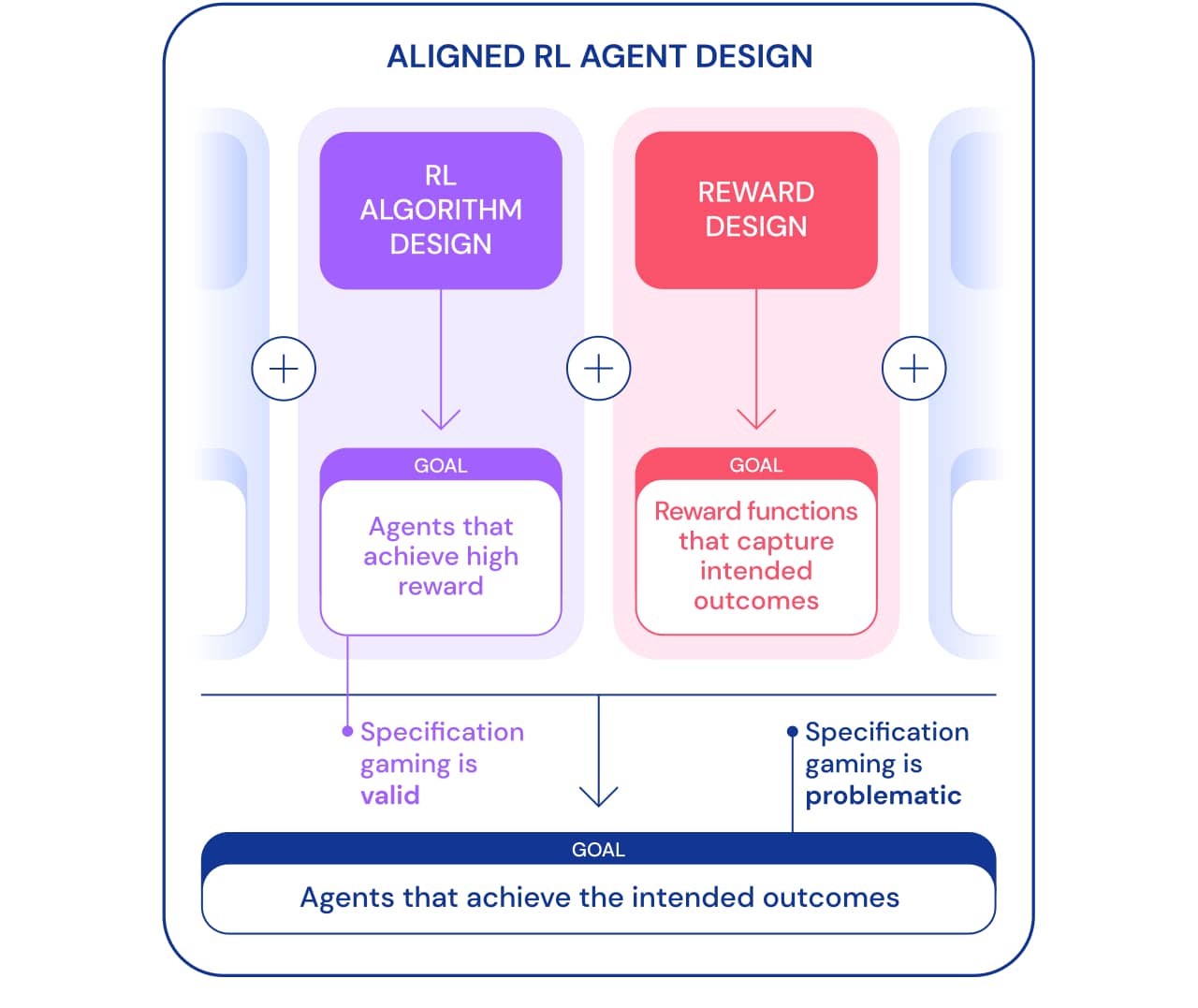
Diseñar especificaciones de tareas (funciones de recompensa, entorno, etc.) que reflejen con precisión la intención del diseñador humano suele ser difícil. Incluso con un ligero malentendido, un algoritmo de RL muy bueno puede encontrar una solución compleja que es muy diferente de lo que se pretende; incluso si un algoritmo más débil no puede encontrar esta solución y así obtener una solución más cercana al resultado esperado. Esto significa que la definición correcta del resultado deseado puede volverse más importante para lograrlo a medida que mejoran los algoritmos de RL. Por lo tanto, es importante que la capacidad de los investigadores para definir correctamente los problemas no se quede atrás de la capacidad de los agentes para encontrar nuevas soluciones.
Usamos el término especificación de tareas en un sentido amplio para abarcar muchos aspectos del proceso de desarrollo de agentes. Al configurar un RL, la especificación de la tarea incluye no solo el diseño de recompensa, sino también la elección del entorno de aprendizaje y las recompensas de apoyo. La exactitud del enunciado del problema puede determinar si el ingenio del agente corresponde o no al resultado esperado. Si la especificación es correcta, la creatividad del agente produce la nueva solución deseada. Esto es lo que permitió a AlphaGo realizar el famoso movimiento número 37., que tomó por sorpresa a los expertos en Go, pero jugó un papel clave en el segundo partido contra Lee Sedol. Si la especificación es incorrecta, puede provocar un comportamiento de juego no deseado, como voltear un bloque. Tales soluciones son posibles y no tenemos una forma objetiva de advertirlas.

Ahora veamos las posibles razones del juego de especificaciones. Una fuente de identificación errónea de la función de recompensa es la generación de recompensas mal diseñada. La formación de recompensas facilita la asimilación de ciertos objetivos al otorgarle al agente alguna recompensa en el camino hacia la solución del problema, en lugar de recompensar solo por el resultado final. Sin embargo, la configuración de las recompensas puede cambiar las políticas óptimas si no se basan en la perspectiva . Piense en un agente que maneja un barco en Coast Runnersdonde el objetivo previsto es terminar la carrera lo más rápido posible. El agente recibió una recompensa formativa por chocar con bloques verdes a lo largo de la pista de carreras, lo que cambió la política óptima para dar vueltas en círculos y chocar con los mismos bloques verdes una y otra vez.

Funciones de recompensa erróneas en acción.
Determinar una recompensa que refleje con precisión el resultado final deseado puede ser una tarea abrumadora en sí misma. En el problema de conectar bloques de Lego, no es suficiente indicar que el borde inferior del bloque rojo debe estar alto del piso, ya que el agente puede simplemente darle la vuelta al bloque rojo para lograr este objetivo. Una especificación más completa del resultado deseado también incluiría que la cara superior del cuadro rojo debería ser más alta que la cara inferior y que la cara inferior esté alineada con la cara superior del cuadro azul. Es fácil pasar por alto uno de estos criterios al determinar el resultado, lo que hace que la especificación sea demasiado amplia y potencialmente más fácil de satisfacer con una solución degenerada.
En lugar de intentar crear una especificación que cubra todos los casos posibles, podríamos aprender la función de recompensa a partir de la retroalimentación humana . A menudo es más fácil evaluar si se ha logrado un resultado que declararlo explícitamente. Sin embargo, este enfoque también puede generar problemas de especificación del juego si el modelo de recompensa no estudia la verdadera función de recompensa que refleja las preferencias del diseñador. Una posible fuente de inexactitudes podría ser la retroalimentación humana utilizada para entrenar el modelo de recompensa. Por ejemplo, el agente que realiza la tarea de captura ha aprendido a engañar al evaluador moviéndose entre la cámara y el objeto.

Reforzar el aprendizaje profundo basado en la preferencia humana.
El modelo de recompensa entrenado también puede estar mal definido por otras razones, como una mala generalización. Se pueden utilizar comentarios adicionales para corregir los intentos del agente de aprovechar las inexactitudes en el modelo de recompensa.
Otra clase de juego por especificación proviene de un agente que explota errores del simulador. Por ejemplo, a un robot simulado que tenía que aprender a caminar se le ocurrió la idea de juntar las piernas y deslizarse por el suelo.
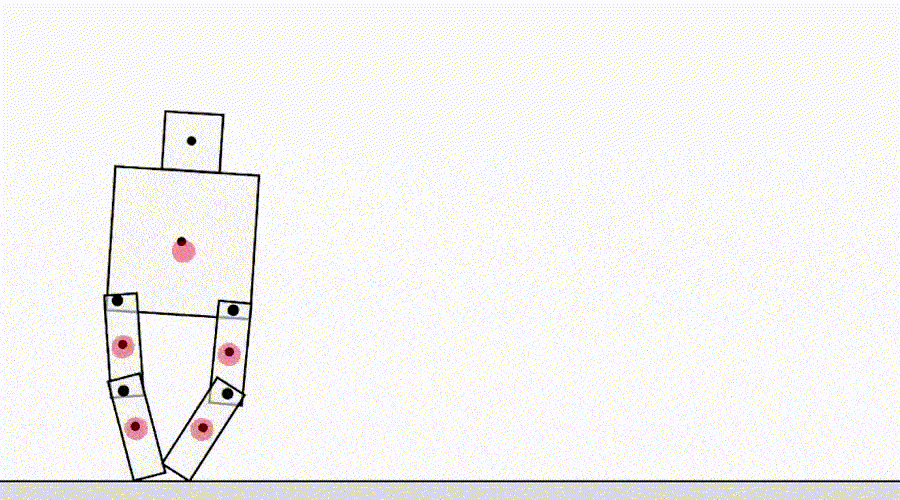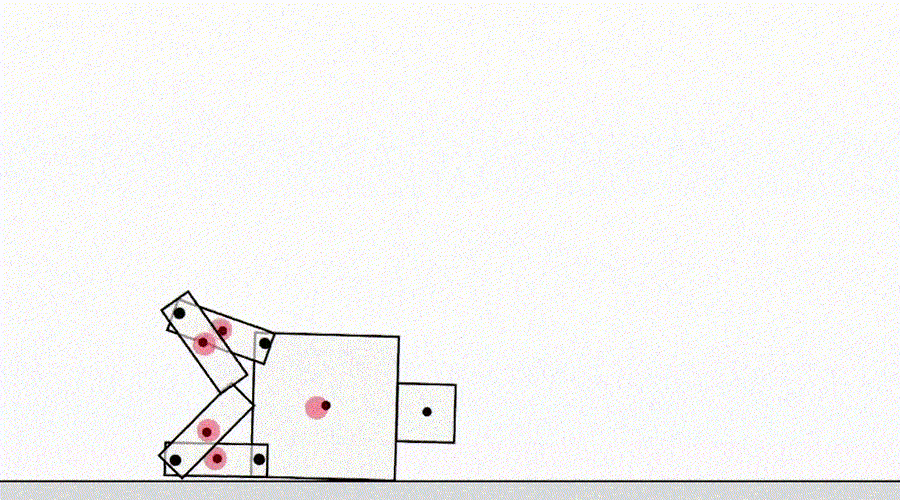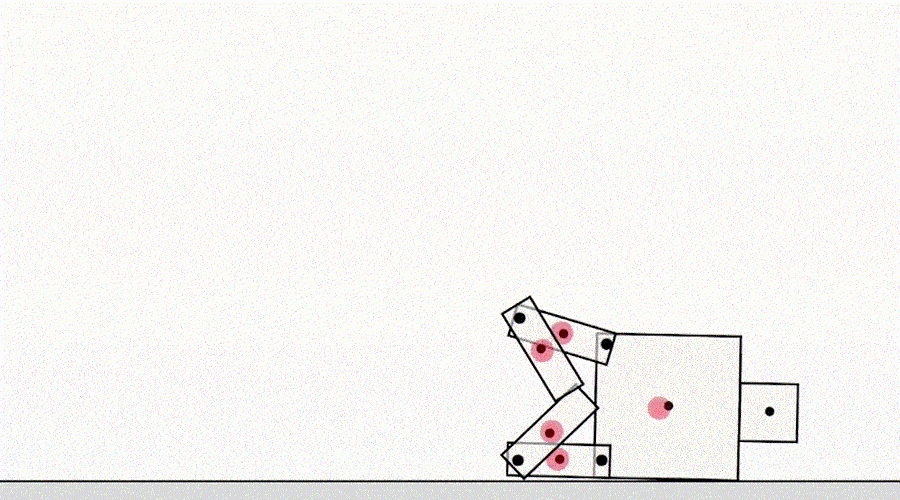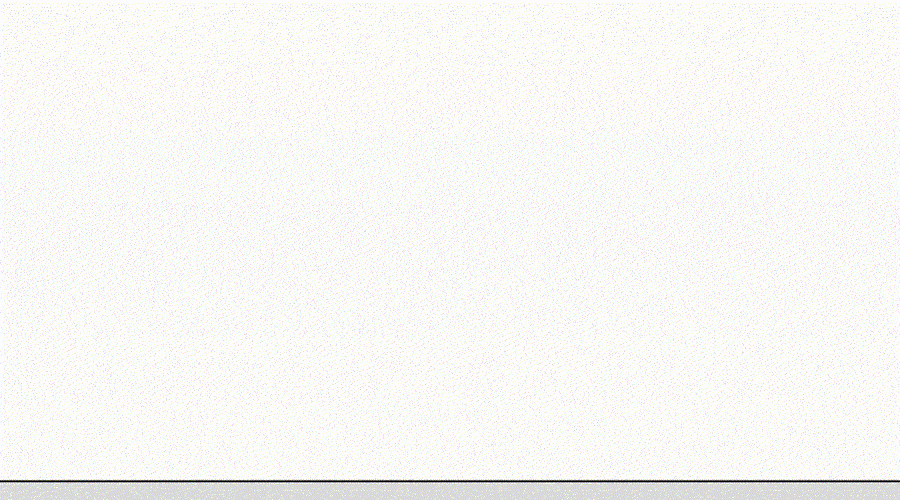
La IA aprende a caminar.
A primera vista, estos ejemplos pueden parecer divertidos, pero menos interesantes y no tienen nada que ver con la implementación de agentes en el mundo real, donde no hay errores del simulador. Sin embargo, el problema principal no es el error en sí mismo, sino el fallo de la abstracción que puede utilizar el agente. En el ejemplo anterior, la tarea del robot se definió incorrectamente debido a suposiciones incorrectas sobre la física del simulador. Asimismo, la optimización del tráfico del mundo real puede identificarse erróneamente si se supone que la infraestructura de enrutamiento del tráfico no contiene errores de software o vulnerabilidades de seguridad que un agente suficientemente inteligente podría detectar. Estas suposiciones no necesitan hacerse explícitamente; más bien, son detalles que simplemente nunca pasaron por la mente del diseñador. Y a medida que las tareas se vuelven demasiado complicadasPara tener en cuenta todos los detalles, es más probable que los investigadores introduzcan suposiciones incorrectas al desarrollar una especificación. Esto plantea la pregunta: ¿Es posible diseñar arquitecturas de agentes que corrijan tales suposiciones falsas en lugar de usarlas?
Una de las suposiciones comúnmente utilizadas en la especificación de tareas es que las acciones del agente no pueden influir en la especificación. Esto es cierto para un agente que opera en un simulador aislado, pero no para un agente que opera en el mundo real. Cualquier especificación de tarea tiene una manifestación física: una función de recompensa almacenada en una computadora o la preferencia de una persona. Un agente desplegado en el mundo real puede potencialmente manipular estas nociones de propósito, creando el problema de la falsificación de recompensas . Para nuestro sistema hipotético de optimización del tráfico, no existe una distinción clara entre satisfacer las preferencias del usuario (por ejemplo, proporcionando una guía útil) e impactar a los usuarios.para que tengan preferencias más fáciles de satisfacer (por ejemplo, animándoles a elegir destinos más fáciles de alcanzar). El primero satisface la tarea, mientras que el segundo manipula la visión del mundo del objetivo (preferencias del usuario), y ambos generan grandes recompensas para el sistema de IA. Como otro ejemplo más extremo, un sistema de inteligencia artificial muy avanzado puede hacerse cargo de la computadora en la que se está ejecutando, estableciendo su propia recompensa en un valor alto.

Para resumir, hay al menos tres desafíos que superar al resolver un problema de especificaciones del juego:
- ¿Cómo captamos con precisión el concepto humano de una tarea determinada como función de recompensa?
- , , ?
- ?
Se han propuesto muchos enfoques, que van desde el modelado de recompensas hasta el desarrollo de incentivos para los agentes; el problema de jugar por especificación está lejos de resolverse. La lista de posibles comportamientos de las especificaciones demuestra la escala del problema y la miríada de formas en que un agente puede jugar con la especificación. Es probable que estos problemas se vuelvan más complejos en el futuro a medida que los sistemas de inteligencia artificial se vuelvan más capaces de satisfacer la especificación de tareas a expensas del resultado previsto. A medida que construimos agentes más avanzados, necesitaremos principios de diseño que aborden específicamente los problemas de especificación y garanticen que estos agentes logren de manera confiable los resultados previstos por los desarrolladores.
Si desea obtener más información sobre el aprendizaje automático y profundo, acérquese a nosotros para el curso apropiado, no será fácil, pero emocionante. Y el código de promoción HABR lo ayudará en su esfuerzo por aprender cosas nuevas al agregar un 10% al descuento en el banner.

- Curso de aprendizaje automático
- Curso avanzado "Machine Learning Pro + Deep Learning"
- Formación profesional en ciencia de datos
- Formación de analista de datos
Otras profesiones y cursos