Introducción
Cuando se trabaja en problemas de aprendizaje automático con datos en línea, es necesario recopilar varias entidades en una para su posterior análisis y evaluación. El proceso de recolección debe ser conveniente y rápido. También debería permitir una transición fluida del desarrollo al uso industrial sin esfuerzo adicional ni trabajo de rutina. Puede utilizar el enfoque de Feature Store para resolver este problema. Este enfoque se describe con muchos detalles aquí: Conozca a Michelangelo: la plataforma de aprendizaje automático de Uber . Este artículo describe cómo interpretar la solución de gestión de funciones especificada como un prototipo.
Tienda de funciones para transmisión en línea
Feature Store puede verse como un servicio que debe realizar sus funciones estrictamente de acuerdo con sus especificaciones. Antes de definir esta especificación, debe desmontarse un ejemplo simple.
Ejemplo
Dejemos que se den las siguientes entidades.
Una película que tiene una identificación y un título.
Clasificación de películas, que también tiene su propio identificador, identificador de película y valor de clasificación. La calificación cambia con el tiempo.
Fuente de calificación, que también tiene su propia calificación. Y cambia con el tiempo.
Y necesitas combinar estas entidades en una.
Esto es lo que sucede.
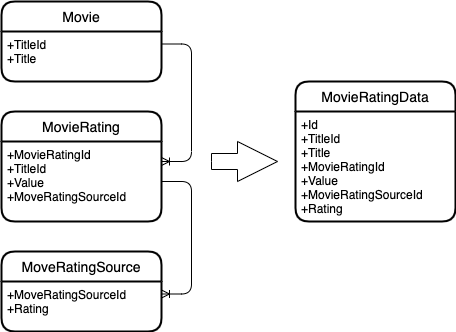
Diagrama de entidad
Como puede ver, la fusión se basa en claves de entidad. Aquellos. se buscan todas las clasificaciones de películas para una película y todas las clasificaciones de fuente para una clasificación de película.
Generalización del ejemplo
, .
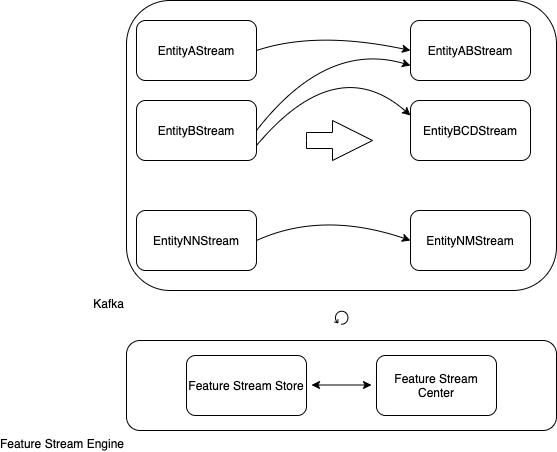
kafka-, : A, B… NN.
: AB, BCD… NM.
: Feature Stream Engine.
Feature Stream Engine kafka-, Feature Stream Store Feature Stream Center, .
Feature Stream Engine
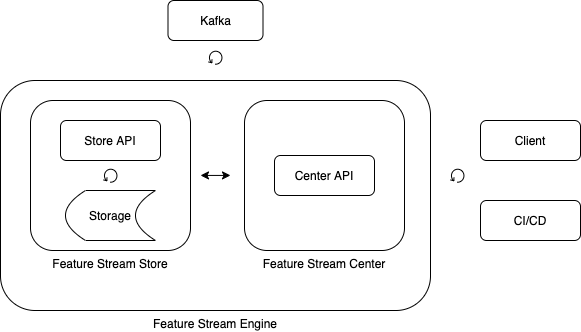
Feature Stream Store
, .
– (feature).
, , .
.
Feature Stream Center
, , .
Feature Stream Engine
Feature Stream Engine , .
Feature Stream Engine
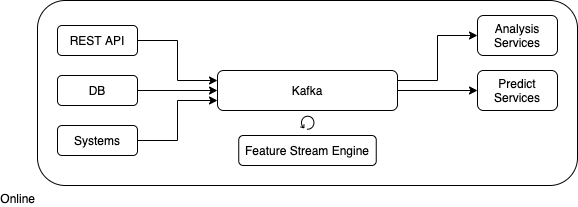
Feature Stream Engine
Feature Stream Engine , .
Feature Stream Engine .
.
kafka.
.
( ).
, .
Feature Stream Engine
.
.
, ("configration.properties").
.
topic- kafka. “,”.
. “,”.
topic-.
, .
public static FeaturesDescriptor createFromProperties(Properties properties) {
String sources = properties.getProperty(FEATURES_DESCRIPTOR_FEATURE_DESCRIPTORS_SOURCES);
String keys = properties.getProperty(FEATURES_DESCRIPTOR_FEATURE_DESCRIPTORS_KEYS);
String sinkSource = properties.getProperty(FEATURES_DESCRIPTOR_SINK_SOURCE);
String[] sourcesArray = sources.split(",");
String[] keysArray = keys.split(",");
List<FeatureDescriptor> featureDescriptors = new ArrayList<>();
for (int i = 0; i < sourcesArray.length; i++) {
FeatureDescriptor featureDescriptor =
new FeatureDescriptor(sourcesArray[i], keysArray[i]);
featureDescriptors.add(featureDescriptor);
}
return new FeaturesDescriptor(featureDescriptors, sinkSource);
}
public static class FeatureDescriptor {
public final String source;
public final String key;
public FeatureDescriptor(String source, String key) {
this.source = source;
this.key = key;
}
}
public static class FeaturesDescriptor {
public final List<FeatureDescriptor> featureDescriptors;
public final String sinkSource;
public FeaturesDescriptor(List<FeatureDescriptor> featureDescriptors, String sinkSource) {
this.featureDescriptors = featureDescriptors;
this.sinkSource = sinkSource;
}
}
.
void buildStreams(StreamsBuilder builder)
topic-, , , .
Serde<String> stringSerde = Serdes.String();
List<KStream<String, String>> streams = new ArrayList<>();
for (FeatureDescriptor featureDescriptor : featuresDescriptor.featureDescriptors) {
KStream<String, String> stream =
builder.stream(featureDescriptor.source, Consumed.with(stringSerde, stringSerde))
.map(new KeyValueMapperSimple(featureDescriptor.key));
streams.add(stream);
}
.
KStream<String, String> pref = streams.get(0);
for (int i = 1; i < streams.size(); i++) {
KStream<String, String> cur = streams.get(i);
pref = pref.leftJoin(cur,
new ValueJoinerSimple(),
JoinWindows.of(Duration.ofSeconds(1)),
StreamJoined.with(
Serdes.String(),
Serdes.String(),
Serdes.String())
);
}
topic.
pref.to(featuresDescriptor.sinkSource);
.
public void buildStreams(StreamsBuilder builder) {
Serde<String> stringSerde = Serdes.String();
List<KStream<String, String>> streams = new ArrayList<>();
for (FeatureDescriptor featureDescriptor : featuresDescriptor.featureDescriptors) {
KStream<String, String> stream =
builder.stream(featureDescriptor.source, Consumed.with(stringSerde, stringSerde))
.map(new KeyValueMapperSimple(featureDescriptor.key));
streams.add(stream);
}
if (streams.size() > 0) {
if (streams.size() == 1) {
KStream<String, String> stream = streams.get(0);
stream.to(featuresDescriptor.sinkSource);
} else {
KStream<String, String> pref = streams.get(0);
for (int i = 1; i < streams.size(); i++) {
KStream<String, String> cur = streams.get(i);
pref = pref.leftJoin(cur,
new ValueJoinerSimple(),
JoinWindows.of(Duration.ofSeconds(1)),
StreamJoined.with(
Serdes.String(),
Serdes.String(),
Serdes.String())
);
}
pref.to(featuresDescriptor.sinkSource);
}
}
}
.
void run(Properties config)
( ).
FeaturesStream featuresStream = new FeaturesStream(config);
kafka.
StreamsBuilder builder = new StreamsBuilder();
featuresStream.buildStreams(builder);
Topology topology = builder.build();
KafkaStreams streams = new KafkaStreams(topology, featuresStream.buildStreamsProperties());
.
streams.start();
.
public static void run(Properties config) {
StreamsBuilder builder = new StreamsBuilder();
FeaturesStream featuresStream = new FeaturesStream(config);
featuresStream.buildStreams(builder);
Topology topology = builder.build();
KafkaStreams streams = new KafkaStreams(topology, featuresStream.buildStreamsProperties());
CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread(() -> {
streams.close();
latch.countDown();
}));
try {
streams.start();
latch.await();
} catch (Throwable e) {
System.exit(1);
}
System.exit(0);
}
.
java -jar features-stream-1.0.0.jar -c plain.properties
: Java 1.8.
: kafka 2.6.0, jsoup 1.13.1.
. .
Primero: le permite construir rápidamente un tema de unión.
Segundo: le permite comenzar a fusionarse rápidamente en diferentes entornos.
Vale la pena señalar que la solución impone una restricción a la estructura de los datos de entrada. Es decir, tema y debe tener una estructura tabular. Para superar esta limitación, puede introducir una capa adicional que le permitirá reducir varias estructuras a una tabular.
Para la implementación industrial de la funcionalidad completa, debe prestar atención a una funcionalidad muy potente y, lo más importante, flexible: KSQL .
Enlaces y recursos
Código fuente ;
Conoce a Michelangelo: la plataforma de aprendizaje automático de Uber .