En la actualidad, una de las tendencias en el estudio de las redes neuronales de grafos es el análisis del funcionamiento de dichas arquitecturas, la comparación con los métodos nucleares, la evaluación de la complejidad y la capacidad de generalización. Todo esto ayuda a comprender los puntos débiles de los modelos existentes y crea espacio para otros nuevos.
El trabajo tiene como objetivo investigar dos problemas relacionados con las redes neuronales gráficas. En primer lugar, los autores dan ejemplos de gráficos que tienen una estructura diferente, pero que no se pueden distinguir para GNN simples y más potentes . En segundo lugar, limitaron el error de generalización para las redes neuronales de gráficos con mayor precisión que los límites de VC.
Introducción
Las redes neuronales gráficas son modelos que funcionan directamente con gráficas. Le permiten tener en cuenta información sobre la estructura. Un GNN típico incluye una pequeña cantidad de capas que se aplican secuencialmente, actualizando las representaciones de vértices en cada iteración. Ejemplos de arquitecturas populares: GCN , GraphSAGE , GAT , GIN .
El proceso de actualización de las incrustaciones de vértices para cualquier arquitectura GNN se puede resumir mediante dos fórmulas:

donde AGG suele ser una función invariante a las permutaciones ( suma , media , max , etc.), COMBINE es una función que combina la representación de un vértice y sus vecinos.

Las arquitecturas más avanzadas pueden considerar información adicional, como características de borde, ángulos de borde, etc.
El artículo considera la clase GNN para el problema de clasificación de gráficos. Estos modelos están estructurados así:
Primero, los vértices se pueden incrustar usando L pasos de convoluciones de gráficos
(, sum, mean, max)
GNN:
(LU-GNN). GCN, GraphSAGE, GAT, GIN
CPNGNN, , 1 d, d - ( port numbering)
DimeNet, 3D-,
LU-GNN
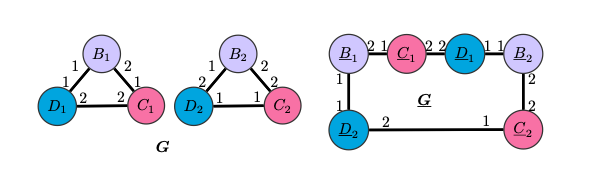
G G LU-GNN, , , readout-, . CPNGNN G G, .
CPNGNN

, “” , CPNGNN .
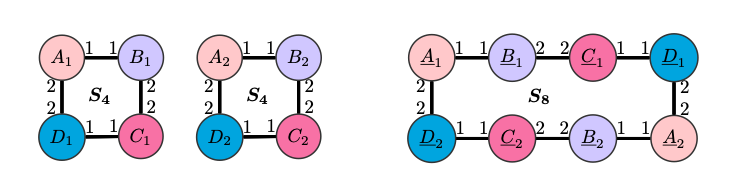
S8 S4 , , ( ), , , CPNGNN readout-, , . , .
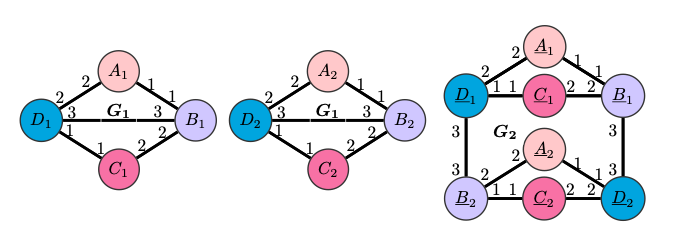
CPNGNN G2 G1. , DimeNet , , , , 
 .
.
DimeNet

DimeNet G4 , G3, . , . , G4 G3 S4 S8, , , DimeNet S4 S8 .
GNN
. , , .
GNN, :
DimeNet
message-



 , c - i- v, t - .
, c - i- v, t - .
:

readout-
.
: LU-GNN,

 - ,
- ,  - v, ,
- v, ,  . ,
. , 
 ,
,  .
.  GNN.
GNN.
. 
 .
.
 - GNN
- GNN  ,
,  - ,
- ,  .
.
,  ,
, - :
![pérdida _ {\ gamma} \ left (a \ right) = \ mathbb {I} \ left [a> 0 \ right] + (1 + \ frac {a} {\ gamma}) \ mathbb {I} \ left [a \ in \ left [\ gamma, 0 \ right] \ right].](https://habrastorage.org/getpro/habr/upload_files/10f/f87/63c/10ff8763ced82f8bcc4a3f1514442cd6.svg)
GNN 
 :
:

, , , , GNN . , (GNN, ), , , .
, :
,
( )

 - “ ”:
- “ ”:  , r - , d - , m - , L - ,
, r - , d - , m - , L - ,  - ,
- ,

( ), . , , , , , , .
Se pueden encontrar pruebas e información más detallada leyendo el artículo original o viendo un informe de uno de los autores.