Pero, como las personas no son computadoras, están buscando algo como " algo así fue de Ivanov o de Ivanovsky ... no, eso no, antes, incluso antes ... ¡aquí está! "
Pero esto amenaza al desarrollador con problemas terribles: después de todo, para la búsqueda FTS en PostgreSQL , se utilizan los tipos "espaciales" de índices GIN y GiST , que no permiten el "deslizamiento" de datos adicionales, excepto un vector de texto.
Solo queda leer tristemente todos los registros por coincidencia de prefijo (¡hay miles de ellos!) Y ordenar o, por el contrario, ir por el índice de fecha y filtrartodas las entradas encontradas para el prefijo coinciden hasta que encontremos las adecuadas (¿qué tan pronto habrá "galimatías"? ..).
Ambos no son muy agradables para el rendimiento de las consultas. ¿O todavía puedes pensar en algo para una búsqueda rápida?
Primero, generemos nuestros "textos hasta la fecha":
CREATE TABLE corpus AS
SELECT
id
, dt
, str
FROM
(
SELECT
id::integer
, now()::date - (random() * 1e3)::integer dt -- - 3
, (random() * 1e2 + 1)::integer len -- "" 100
FROM
generate_series(1, 1e6) id -- 1M
) X
, LATERAL(
SELECT
string_agg(
CASE
WHEN random() < 1e-1 THEN ' ' -- 10%
ELSE chr((random() * 25 + ascii('a'))::integer)
END
, '') str
FROM
generate_series(1, len)
) Y;
Enfoque ingenuo # 1: gist + btree
Intentemos rodar el índice tanto para FTS como para ordenar por fecha; ¿y si ayudan?
CREATE INDEX ON corpus(dt);
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str));
Buscaremos todos los documentos que contengan palabras que empiecen por
'abc...'
. Y, primero, verifiquemos que hay pocos documentos de este tipo y que el índice FTS se usa normalmente:
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*');
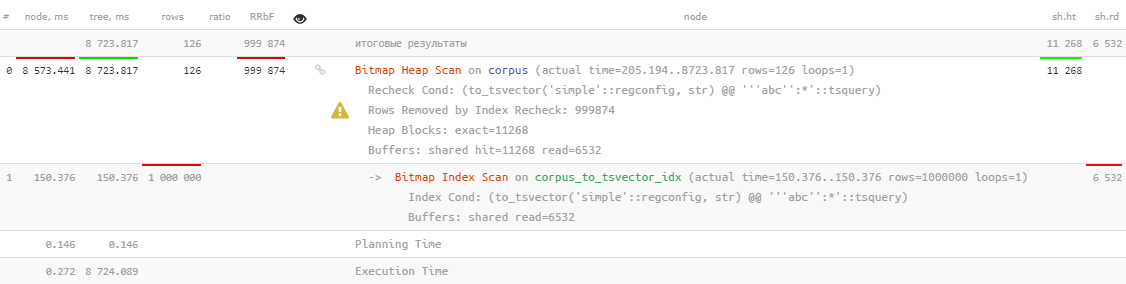
Bueno ... por supuesto, se usa, pero toma más de 8 segundos , que claramente no es lo que nos gustaría gastar buscando 126 registros.
Tal vez si agrega la clasificación por fecha y busca solo los últimos 10 registros , ¿será mejor?
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt DESC
LIMIT 10;

Pero no, solo se agregó clasificación en la parte superior.
Enfoque ingenuo # 2: btree_gist
Pero hay una extensión excelente
btree_gist
que le permite "deslizar" un valor escalar en un índice GiST, lo que debería permitirnos usar inmediatamente la clasificación de índices usando el operador de distancia
<->
, que se puede usar para búsquedas kNN :
CREATE EXTENSION btree_gist;
CREATE INDEX ON corpus USING gist(to_tsvector('simple', str), dt);
SELECT
*
FROM
corpus
WHERE
to_tsvector('simple', str) @@ to_tsquery('simple', 'abc:*')
ORDER BY
dt <-> '2100-01-01'::date DESC -- ""
LIMIT 10;
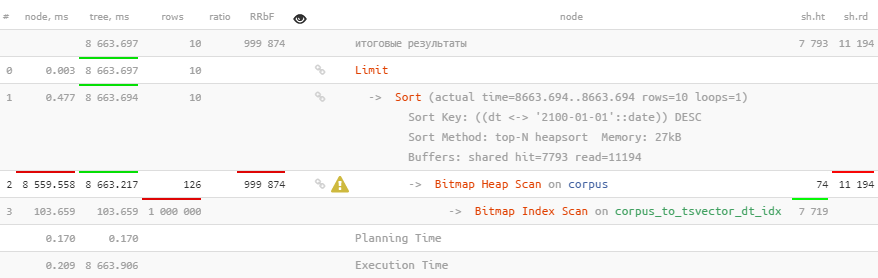
Por desgracia, esto no ayuda en absoluto.
¡Geometría al rescate!
¡Pero es demasiado pronto para desesperarse! Veamos la lista de clases de operador integradas GiST - el operador de distancia está
<->
disponible solo para "geométrico"
circle_ops, point_ops, poly_ops
, y desde PostgreSQL 13 - para
box_ops
.
Así que intentemos traducir nuestra tarea "en el plano": asignamos las coordenadas de algunos puntos a nuestros pares
(, )
utilizados para la búsqueda de modo que las palabras de "prefijo" y las fechas no lejanas estén lo más cerca posible:

Rompemos el texto en palabras
Por supuesto, nuestra búsqueda no será completamente de texto completo, en el sentido de que no puede establecer una condición para varias palabras al mismo tiempo. ¡Pero definitivamente será prefijo!
Formemos una tabla de diccionario auxiliar:
CREATE TABLE corpus_kw AS
SELECT
id
, dt
, kw
FROM
corpus
, LATERAL (
SELECT
kw
FROM
regexp_split_to_table(lower(str), E'[^\\-a-z-0-9]+', 'i') kw
WHERE
length(kw) > 1
) T;
En nuestro ejemplo, había 4,8 millones de "palabras" por 1 millón de "textos".
Dejando las palabras
Para traducir una palabra a su "coordenada", imaginemos que se trata de un número escrito en notación base
2^16
(después de todo, también queremos admitir caracteres UNICODE). Solo lo escribiremos comenzando desde la posición 47 fija:
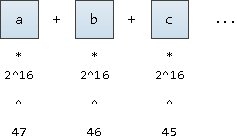
podríamos comenzar desde la posición 63, esto nos dará valores ligeramente menores que los valores
1E+308
límite para
double precision
, pero luego se producirá un desbordamiento al construir el índice.
Resulta que en el eje de coordenadas se ordenarán todas las palabras:

ALTER TABLE corpus_kw ADD COLUMN p point;
UPDATE
corpus_kw
SET
p = point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
);
CREATE INDEX ON corpus_kw USING gist(p);
Formamos una consulta de búsqueda
WITH src AS (
SELECT
point(
( --
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
SELECT
*
, src.ps <-> kw.p d
FROM
corpus_kw kw
, src
ORDER BY
d
LIMIT 10;

Ahora tenemos los
id
documentos que estábamos buscando, ordenados en el orden correcto, ¡y nos llevó menos de 2 ms, 4000 veces más rápido !
Una pequeña mosca en el ungüento.
El operador
<->
no sabe nada sobre nuestro pedido a lo largo de dos ejes, por lo que nuestros datos requeridos se ubican solo en uno de los cuartos correctos, dependiendo de la clasificación requerida por fecha:

Bueno, aún queríamos seleccionar los textos-documentos en sí mismos, y no sus palabras clave, así que necesitaremos un índice olvidado hace mucho tiempo:
CREATE UNIQUE INDEX ON corpus(id);
Finalicemos la solicitud:
WITH src AS (
SELECT
point(
(
SELECT
sum((2 ^ 16) ^ (48 - i) * ascii(substr(kw, i, 1)))
FROM
generate_series(1, length(kw)) i
)
, extract('epoch' from dt)
) ps
FROM
(VALUES('abc', '2100-01-01'::date)) T(kw, dt) --
)
, dc AS (
SELECT
(
SELECT
dc
FROM
corpus dc
WHERE
id = kw.id
)
FROM
corpus_kw kw
, src
WHERE
p[0] >= ps[0] AND -- kw >= ...
p[1] <= ps[1] -- dt DESC
ORDER BY
src.ps <-> kw.p
LIMIT 10
)
SELECT
(dc).*
FROM
dc;

Obtuvimos un pequeño agregado derivado
InitPlan
del cálculo de la constante x / y, ¡pero aún así nos mantuvimos dentro de los mismos 2 ms !
Vuela en el ungüento # 2
Nada es gratis:
SELECT relname, pg_size_pretty(pg_total_relation_size(oid)) FROM pg_class WHERE relname LIKE 'corpus%';
corpus | 242 MB -- corpus_id_idx | 21 MB -- PK corpus_kw | 705 MB -- corpus_kw_p_idx | 403 MB -- GiST-
242 MB de "textos" se convirtieron en 1,1 GB de "índice de búsqueda".
Pero después de todo,
corpus_kw
la fecha y la palabra en sí se encuentran, que no hemos utilizado en la búsqueda, así que eliminémoslas:
ALTER TABLE corpus_kw
DROP COLUMN kw
, DROP COLUMN dt;
VACUUM FULL corpus_kw;
corpus_kw | 641 MB -- id point
Un poco, pero agradable. No ayudó demasiado, pero aún así se recuperó el 10% del volumen.