
AWS Fault Injection Simulator (FIS)- una herramienta que le permite implementar escenarios previamente conocidos de fallas del sistema interno dentro de los servicios de AWS. ¿Para qué? - para que los equipos puedan elaborar escenarios para su eliminación y, en general, evaluar el comportamiento de su producto en las condiciones propuestas. El sistema ofrecerá inmediatamente varias plantillas con escenarios de falla, por ejemplo, ralentización del servidor, falla del servidor, error de acceso a la base de datos o su caída. Al mismo tiempo, FIS se asegurará de que el experimento no vaya demasiado lejos y cuando se alcancen ciertos parámetros, las pruebas se detendrán y el sistema volverá a la normalidad. El eslogan principal del nuevo producto del gigante de la nube es "aumentar la resistencia y el rendimiento utilizando tecnología de caos controlado". El lanzamiento del nuevo sistema de prueba está programado para 2021.
AWS también ofrece pruebas y sistemas virtualizados distribuidos que dependen menos de un solo host. La especificidad de una falla en un sistema distribuido es que el problema puede ser cíclico y tener una estructura más compleja. La nueva función de AWS le permitirá buscar vulnerabilidades no solo en la infraestructura de monolitos, sino también en sistemas distribuidos y aplicaciones.
Veamos por qué esto es importante y genial.
La ingeniería del caos es un proceso de prueba de simulación en el que el impacto principal en el sistema proviene del interior y afecta la infraestructura del proyecto. El equipo simula situaciones en las que la parte de infraestructura del proyecto se enfrenta a problemas técnicos y de otro tipo, por ejemplo, con una disminución puntual o sistémica del rendimiento en las instancias. Esto también puede incluir fallas del servidor, fallas de API y otras pesadillas del backend que el equipo puede enfrentar en cualquier momento o, peor aún, el día en que se lanza la próxima versión.
Todavía no existe una definición inequívoca de ingeniería del caos, por lo que estas son algunas de las opciones más populares y, en nuestra opinión, precisas. La ingeniería del caos es: "un enfoque que implica experimentar con un sistema de producción para asegurarse de que pueda resistir varias perturbaciones que ocurren durante la operación" y "un experimento para mitigar los efectos de la falla".
Por qué se necesita AWS Fault Injection Simulator
Los desarrolladores de la herramienta citan varias razones por las que FIS será útil para los equipos al probar y preparar sus sistemas.
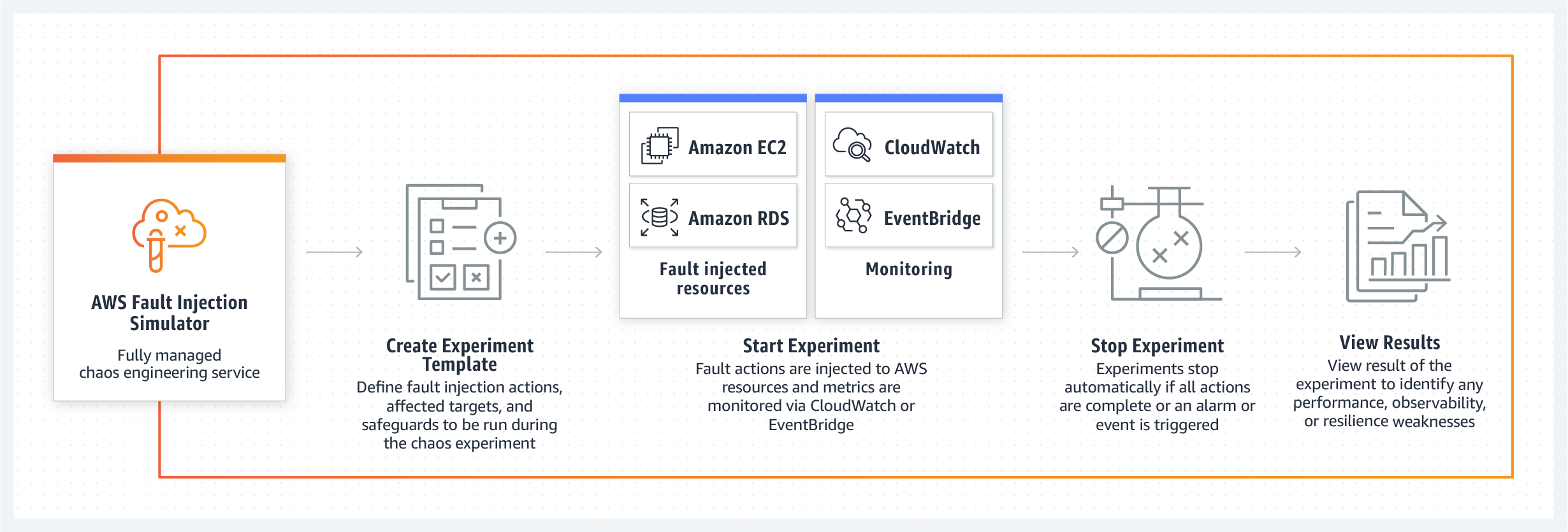
El rendimiento, la resistencia y la transparencia del sistema son uno de los mensajes centrales del equipo de AWS FIS.
AWS Fault Injection Simulator , , «» , .
De hecho, los métodos de prueba habituales son, en primer lugar, la simulación de la carga externa en el sistema. Por ejemplo, simulando un efecto habra o un ataque DDoS externo en un sistema o servicio. Muy a menudo, todos los principales sistemas de monitoreo están vinculados precisamente a estos nodos, mientras que el seguimiento del comportamiento de la infraestructura interna, a menudo, se limita solo a recibir datos en el estilo "abajo / abajo" o la carga en la CPU. Al mismo tiempo, los mayores daños y las fallas más poderosas de los últimos años se asocian precisamente a fallas internas o errores de infraestructura. Baste recordar el desplome de CloudFlare del año pasado, cuando, debido a una serie de fallas y errores, los desarrolladores literalmente obligaron a la mitad de Internet a "tumbarse" con sus propias manos.
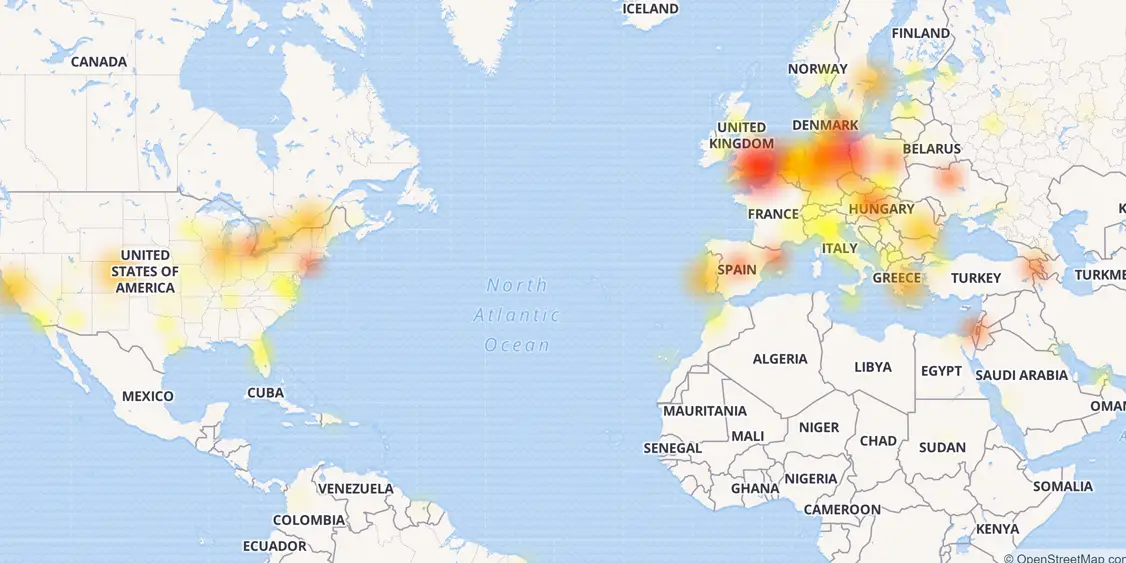
Mapa de esa falla de CloudFlare
La nueva herramienta es capaz de elaborar plantillas listas para usar para escenarios de falla de la base de datos, API o degradación del rendimiento, así como crear condiciones de prueba ciegas aleatorias en las que los problemas ocurrirán en una secuencia arbitraria en diferentes nodos.
Otro punto fuerte del nuevo kit de herramientas de AWS es la capacidad de control del caos creado por el equipo en el sistema. Los ingenieros aseguran que con la ayuda de su panel de control, los desarrolladores pueden detener un escenario de falla controlado en cualquier momento y devolver el sistema a su estado de funcionamiento original. Fault Injection Simulator es compatible con Amazon CloudWatch y herramientas de monitoreo de terceros conectadas a través de Amazon EventBridge para que los desarrolladores puedan usar sus métricas para monitorear experimentos de caos controlados. Y, por supuesto, después de detener la prueba, el administrador recibirá un informe completo sobre qué nodos del sistema y en qué secuencia se vieron afectados por la falla, lo que en el futuro ayudará a desarrollar un conjunto de medidas y procedimientos para localizar y eliminar problemas.
Cómo se originaron los Señores del Caos
Obviamente, estas pruebas de estrés del sistema son más lógicas de realizar en el período previo al lanzamiento para asegurarse de que la infraestructura existente en AWS resistirá el nuevo parche. Sin embargo, en realidad, la técnica de la ingeniería del caos se remonta a prácticas más antiguas, cuyo fundador es uno de los gerentes de Amazon en la década de 2000, Jesse Robbins. Su puesto se llamaba oficialmente “Maestro del desastre”, que en una patética traducción se puede confundir con “Señor de los desastres”, y en una versión gratuita su puesto sonaba como “Maestro Lomaster”.
 Fue Robbins, un ex bombero / trabajador de rescate, quien
implementó GameDay en Amazon.... El objetivo de la iniciativa Robbins era extremadamente simple: desarrollar una comprensión intuitiva entre los equipos de ingenieros sobre cómo lidiar con un desastre, de la misma manera que este sentimiento se entrena en los cuerpos de bomberos. Fue por esto que se eligió el método de simulación global del caos total: todo se rompe por todos lados, simultánea o secuencialmente, y cada intento de hacer frente al fracaso conduce a nuevos y nuevos problemas.
Fue Robbins, un ex bombero / trabajador de rescate, quien
implementó GameDay en Amazon.... El objetivo de la iniciativa Robbins era extremadamente simple: desarrollar una comprensión intuitiva entre los equipos de ingenieros sobre cómo lidiar con un desastre, de la misma manera que este sentimiento se entrena en los cuerpos de bomberos. Fue por esto que se eligió el método de simulación global del caos total: todo se rompe por todos lados, simultánea o secuencialmente, y cada intento de hacer frente al fracaso conduce a nuevos y nuevos problemas.
Cuando una persona no preparada se enfrenta a la confusión de los elementos, la mayoría de las veces cae en estupor o pánico. La mayoría de los desarrolladores e ingenieros no están preparados psicológicamente para una situación en la que la resolución de un problema debería llevar tres días y el nivel de estrés es simplemente fuera de escala.
Robbins llama al resultado más importante de GameDay el efecto psicológico de tales ejercicios: desarrollan la capacidad de aceptar el hecho de que ocurren interrupciones a gran escala . Es la aceptación del hecho de que todo alrededor está en llamas y colapsando, lo llama muy importante para el ingeniero, para que pueda ordenar sus pensamientos y finalmente comenzar a "apagar el fuego". Una persona no capacitada, en el mejor de los casos, correrá en círculos y gritará "todo está perdido".
Después de la implementación de la práctica de GameDay, resultó que tales ejercicios identifican perfectamente los problemas arquitectónicos y los cuellos de botella a los que no se les presta atención durante las pruebas y verificaciones clásicas.
Otra diferencia significativa entre GameDay y nuestros ejercicios habituales de "entrenamiento y orden" es que pocas personas conocen el escenario específico y lo que sucederá en general. La información sobre los próximos "juegos" se da de una manera muy general y vaga, por lo que los participantes no pudieron prepararse completamente para este evento. Es ideal anunciar solo la fecha del próximo "día de juego" sin ninguna aclaración, solo para que los participantes no lo confundan con un accidente real. Por supuesto, esta metodología no se escala a una gran empresa, por ejemplo, GameDay no se puede llevar a cabo en todo Yandex o Microsoft a la vez.
Como resultado, la práctica se actualizó a GameDay local y se introdujo en todas las grandes empresas de TI existentes, por ejemplo, en Google, Flickr y muchas otras. Tiene sus propios Maestros de Desastres (bueno, o Master-Lommasters, como más te guste), que organizan las fallas de formación y luego analizan los resultados obtenidos en proyectos específicos.
La principal dificultad para implementar esta práctica en todas partes radica en dos aspectos: cómo organizarla y cómo recolectar datos para que GameDay no sea en vano. Es por eso que, en las empresas más pequeñas, esta técnica no se utilizó mucho (si es que se utilizó) hasta hace poco. En lugar de GameDay y simulación de desastres, el negocio se centró más en diferentes tipos de pruebas, CI / CD y otras metodologías para un desarrollo ordenado y consistente. Es decir, sobre lo que previene la catástrofe como tal.
El nuevo kit de herramientas de AWS le permitirá abordar el otro lado de la interrupción: en lugar de la prevención, que sin duda es importante, FIS permitirá que los equipos de ingeniería de todos los tamaños se capaciten de manera efectiva para resolver las interrupciones de la infraestructura global. Después de todo, lo principal que señala Robbins es que los desastres ocurren de todos modos: no se pueden evitar.