
Existen muchos enfoques para escribir código de aplicación para evitar que la complejidad del proyecto aumente con el tiempo. Por ejemplo, el enfoque orientado a objetos y muchos patrones adjuntos permiten, si no mantener la complejidad del proyecto al mismo nivel, al menos mantenerlo bajo control durante el desarrollo y hacer que el código esté disponible para el nuevo programador del equipo.
¿Cómo puede gestionar la complejidad de un proyecto de transformación ETL en Spark?
No es tan simple.
¿Cómo se ve en la vida real? El cliente ofrece crear una aplicación que recopila un escaparate. Parece necesario ejecutar el código a través de Spark SQL y guardar el resultado. Durante el desarrollo, resulta que la construcción de este mercado requiere 20 fuentes de datos, de las cuales 15 son similares, el resto no. Estas fuentes deben combinarse. Luego, resulta que para la mitad de ellos, debe escribir sus propios procedimientos de ensamblaje, limpieza y normalización.
Y un simple escaparate, después de una descripción detallada, comienza a verse así:
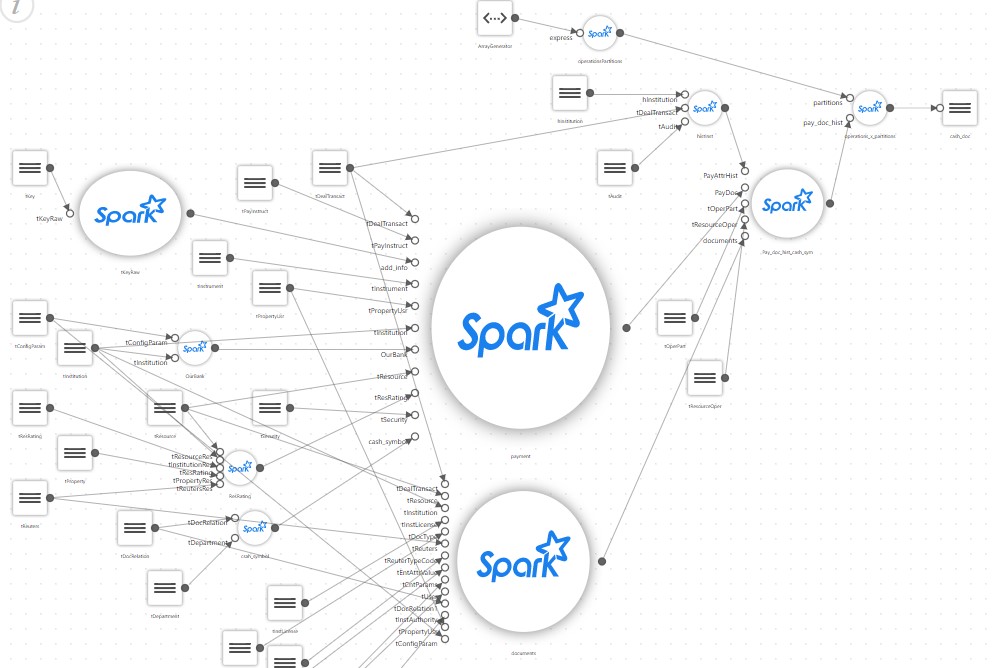
como resultado, un proyecto simple que se suponía que solo ejecutaba un script SQL que recopila el escaparate en Spark adquiere su propio configurador, un bloque para leer una gran cantidad de archivos de configuración, su propia rama de mapeo, traductores de algunas reglas especiales etc.
A la mitad del proyecto, resulta que solo el autor puede admitir el código resultante. Sí, y pasa la mayor parte del tiempo pensando. Mientras tanto, el cliente solicita recopilar un par de vitrinas más, nuevamente basándose en cientos de fuentes. Al mismo tiempo, debemos recordar que Spark generalmente no es muy adecuado para crear sus propios marcos.
Por ejemplo, Spark está diseñado para hacer que el código se vea así (pseudocódigo):
park.sql(“select table1.field1 from table1, table2 where table1.id = table2.id”).write(...pathToDestTable)
En cambio, tienes que hacer algo como esto:
var Source1 = readSourceProps(“source1”) var sql = readSQL(“destTable”) writeSparkData(source1, sql)
Es decir, mover bloques de código en procedimientos separados e intentar escribir algo propio, universal, que se pueda personalizar mediante la configuración.
Al mismo tiempo, la complejidad del proyecto permanece al mismo nivel, por supuesto, pero solo para el autor del proyecto, y solo por poco tiempo. Cualquier programador invitado tardará mucho en dominarlo, y lo principal es que no funcionará para atraer a personas que solo conocen SQL al proyecto.
Esto es lamentable, ya que Spark en sí mismo es una excelente manera de desarrollar aplicaciones ETL para aquellos que solo conocen SQL.
Y en el curso del desarrollo del proyecto, resultó que algo simple se convirtió en algo complejo.
Ahora imagine un proyecto real, donde hay docenas, o incluso cientos, de escaparates como en la imagen, y usan diferentes tecnologías, por ejemplo, algunas se pueden basar en el análisis de datos XML y otras en la transmisión de datos.
Me gustaría mantener de alguna manera la complejidad del proyecto en un nivel aceptable. ¿Cómo se puede hacer esto?
La solución puede ser utilizar una herramienta y un enfoque de código bajo, cuando un entorno de desarrollo lo decida por usted, lo que toma toda la complejidad y ofrece un enfoque conveniente, como se describe en este artículo .
Este artículo describe los enfoques y beneficios de usar la herramienta para resolver este tipo de problemas. En particular, Neoflex ofrece su propia solución Neoflex Datagram, que es utilizado con éxito por diferentes clientes.
Pero no siempre es posible utilizar una aplicación de este tipo.
¿Qué hacer?
En este caso, utilizamos un enfoque que se llama convencionalmente Orc - Object Spark u Orka, como desee.
Los datos iniciales son los siguientes:
hay un cliente que proporciona un lugar de trabajo donde hay un conjunto estándar de herramientas, a saber: Hue para desarrollar código Python o Scala, editores Hue para depuración de SQL a través de Hive o Impala y Oozie workflow Editor. Esto no es mucho, pero sí suficiente para resolver problemas. Es imposible agregar algo al entorno, es imposible instalar nuevas herramientas, por varias razones.
Entonces, ¿cómo se desarrollan aplicaciones ETL que, como de costumbre, se convertirán en un gran proyecto, en el que participarán cientos de tablas de fuentes de datos y docenas de mercados de destino, sin ahogarse en complejidad y sin escribir demasiado?
Se utilizan varias disposiciones para resolver el problema. No son su propia invención, sino que se basan completamente en la arquitectura de Spark.
- Todas las uniones, cálculos y transformaciones complejas se realizan a través de Spark SQL. El optimizador Spark SQL mejora con cada versión y funciona muy bien. Por lo tanto, le damos todo el trabajo de calcular Spark SQL al optimizador. Es decir, nuestro código se basa en la cadena SQL, donde el paso 1 prepara los datos, el paso 2 se une, el paso 3 calcula, etc.
- Spark, Spark SQL. (DataFrame) Spark SQL.
- Spark Directed Acicled Graph, , , , , 2, 2.
- Spark lazy, , , .
Como resultado, toda la aplicación se puede hacer muy simple.
Basta con hacer un archivo de configuración en el que definir una lista de fuentes de datos de un solo nivel. Esta lista secuencial de fuentes de datos es el objeto que describe la lógica de toda la aplicación.
Cada fuente de datos contiene un enlace a SQL. En SQL, para la fuente actual, puede usar una fuente que no está en Hive, pero que se describe en el archivo de configuración arriba de la actual.
Por ejemplo, la fuente 2, cuando se traduce al código Spark, se parece a esto (pseudocódigo):
var df = spark.sql(“select * from t1”); df.saveAsTempTable(“source2”);
Y la fuente 3 ya puede verse así:
var df = spark.sql(“select count(*) from source2”) df.saveAsTempTable(“source3”);
Es decir, la fuente 3 ve todo lo que se calculó antes.
Y para aquellas fuentes que son vitrinas de destino, debe especificar los parámetros para guardar esta presentación de destino.
Como resultado, el archivo de configuración de la aplicación tiene este aspecto:
[{name: “source1”, sql: “select * from t1”}, {name: “source2”, sql: “select count(*) from source1”}, ... {name: “targetShowCase1”, sql: “...”, target: True, format: “PARQET”, path: “...”}]
Y el código de la aplicación se parece a esto:
List = readCfg(...) For each source in List: df = spark.sql(source.sql).saveAsTempTable(source.name) If(source.target == true) { df.write(“format”, source.format).save(source.path) }
Esta es, de hecho, toda la aplicación. No se requiere nada más excepto un momento.
¿Cómo depurar todo esto?
Después de todo, el código en sí mismo en este caso es muy simple, qué hay que depurar, pero sería bueno verificar la lógica de lo que se está haciendo. La depuración es muy simple: debe pasar por todas las aplicaciones hasta la fuente que se está verificando. Para hacer esto, agregue un parámetro al flujo de trabajo de Oozie que le permita detener la aplicación en la fuente de datos requerida imprimiendo su esquema y contenido en el registro.
Llamamos a este enfoque Object Spark en el sentido de que toda la lógica de la aplicación se desacopla del código Spark y se almacena en un único archivo de configuración bastante simple, que es el objeto de descripción de la aplicación.
El código sigue siendo simple y, una vez creado, incluso los escaparates más complejos se pueden desarrollar utilizando programadores que solo conocen SQL.
El proceso de desarrollo es muy sencillo. Al principio, participa un programador de Spark con experiencia, que crea un código universal, y luego se edita el archivo de configuración de la aplicación agregando nuevas fuentes allí.
Qué ofrece este enfoque:
- Puede involucrar a programadores SQL en el desarrollo;
- Dado el parámetro en Oozie, depurar una aplicación de este tipo se vuelve fácil y simple. Esto es depurar cualquier paso intermedio. La aplicación trabajará todo en la fuente deseada, lo calculará y se detendrá;
- ( … ), , , , , . , Object Spark;
- , . . , , , XML JSON, -. , ;
- . , , , , .