
Hoy hablaremos de un tema aparentemente simple como los datos relacionales y relacionados.
A pesar de toda su simplicidad, me doy cuenta de que a veces la gente se confunde mucho con ellos; decidí solucionar este problema escribiendo una explicación breve e informal de qué son y por qué son necesarios.
Discutiremos qué es el modelo relacional y el SQL relacionado y el álgebra relacional. Luego pasemos a ejemplos de datos relacionados de Wikidat, y luego RDF, SPARQL y una pequeña charla sobre Datalog y representación lógica de datos. Al final, las conclusiones: cuándo aplicar el modelo relacional y cuándo el lógico coherente.
El propósito principal de la publicación es describir cuándo tiene sentido aplicar y por qué. Dado que hay muchos conceptos difíciles que convergen en un solo lugar, entonces, por supuesto, sería posible escribir un libro para cada uno, pero nuestra tarea hoy es dar una idea del tema y lo analizaremos de manera informal utilizando ejemplos simples.
Si tiene alguna duda sobre en qué se diferencia uno del segundo y por qué necesita datos vinculados (LinkedData), le damos la bienvenida a cat.

Datos relacionales
Comencemos con una definición estándar: una
base de datos relacional es una colección de datos con relaciones predefinidas entre ellos. Estos datos están organizados como un conjunto de tablas que consta de columnas y filas. Las tablas almacenan información sobre los objetos representados en la base de datos.
Cuando se aplica:
- Modelado de dominio fijo
- El esquema de datos cambia poco o los cambios afectan inmediatamente a un grupo significativo de registros
- Consultas básicas: filtrado de categorías por campos clave de registros, agregación, generación de informes y análisis basados en indicadores estadísticos, etc.
En esta situación, la unidad de modelado es la tabla y las relaciones entre las tablas (como las claves externas). De hecho, una tabla es un predicado con atributos fijos, es decir siempre conocemos la aridad de un predicado tabular.
Tomemos una clave externa como ejemplo de relaciones de restricción: la clave "p (_, X, _) → q (_, Y, _)", que establece las restricciones en la forma X \ subconjunto Y, donde X es un atributo de la relación p, e Y atributo de relación q.

Más importante aún, en el mundo de los datos relacionales, ¡tenemos todo por tabla! Y las operaciones toman una tabla como entrada y devuelven una tabla, por ejemplo:

Lenguaje de datos relacionales: SQL y álgebra relacional
El álgebra relacional (álgebra de Codd) es esencialmente un conjunto de operaciones en tablas que devuelven tablas. Es decir, para ti, el elemento central del modelado son precisamente las tablas fijas y sus transformaciones.
El lenguaje SQL es una superestructura declarativa y una implementación concreta de las ideas del álgebra relacional.
Un ejemplo de una consulta simple y los correspondientes operadores relacionales del álgebra.

Hasta ahora, todo lo que hemos cubierto son las cosas clásicas que sabemos de cualquier curso de base de datos.
Datos vinculados y gráficos de conocimiento
Imaginemos qué pasará si tenemos nuevas propiedades y esto sucede, ¿quizás en tiempo real? Es decir, el dominio no es fijo, sino flexible y extensible .
En tal situación, por supuesto, podemos agregar tablas y columnas a las tablas inyectando valores NULL o predeterminados. Pero además de ser técnicamente inconveniente, también es una herramienta inadecuada desde el punto de vista del modelado.
Imagina que estás modelando la vida de las personas en todos sus aspectos posibles. Incluso dos personas diferentes tendrán un conjunto bastante diferente de propiedades clave y esto es absolutamente normal.
No tienes una lista fija de cómo se describirá un personaje específico Escritor y jugador de fútbol: son dos personas que tienen muchas propiedades importantes, pero, sin embargo, diferentes.
Comencemos con el escritor Douglas Adams: las propiedades principales son bastante típicas para cualquier persona, aquí y más adelante usamos Wikidata como ejemplo de LinkedData.
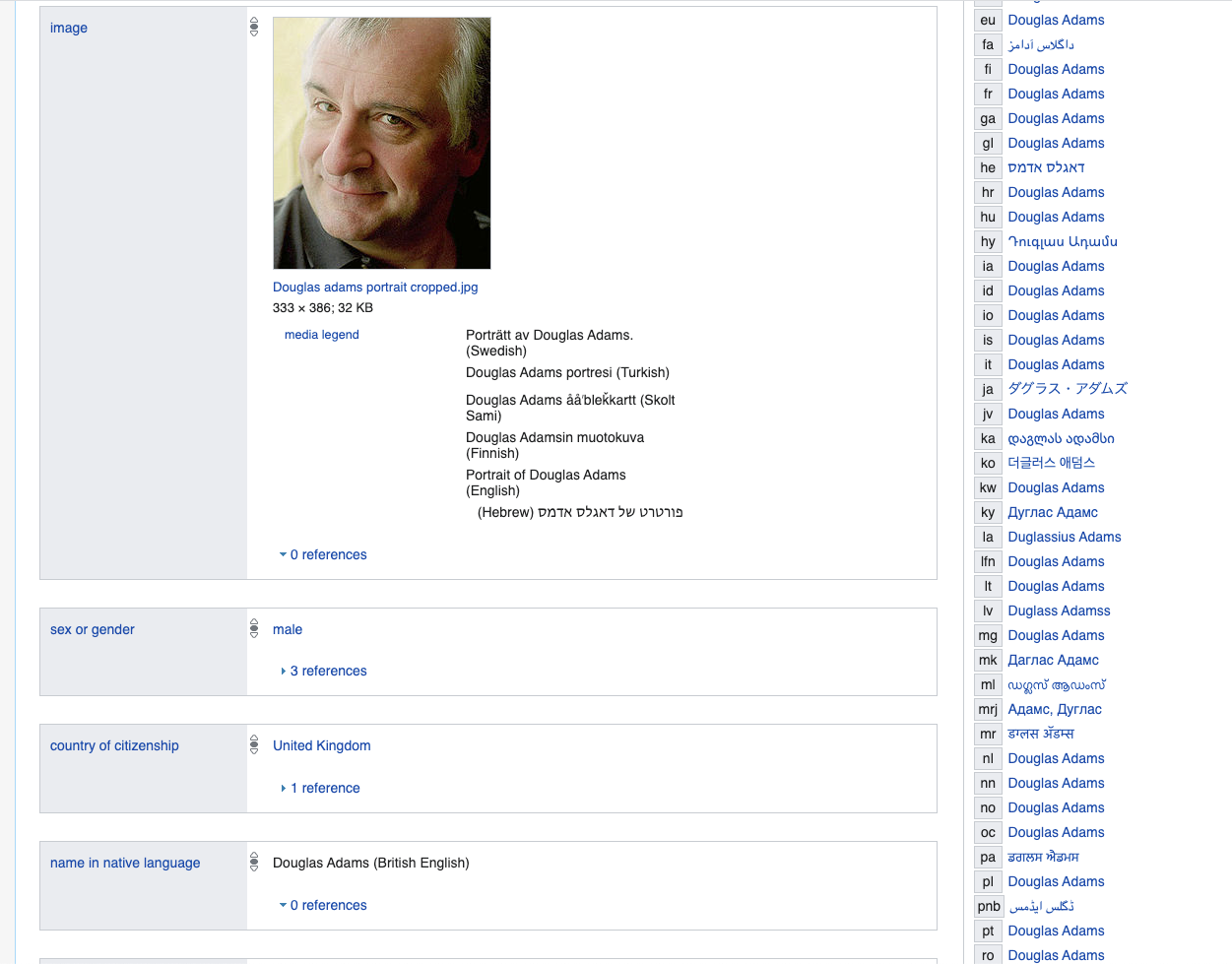
www.wikidata.org/wiki/Q42
Pero profundicemos un poco más y
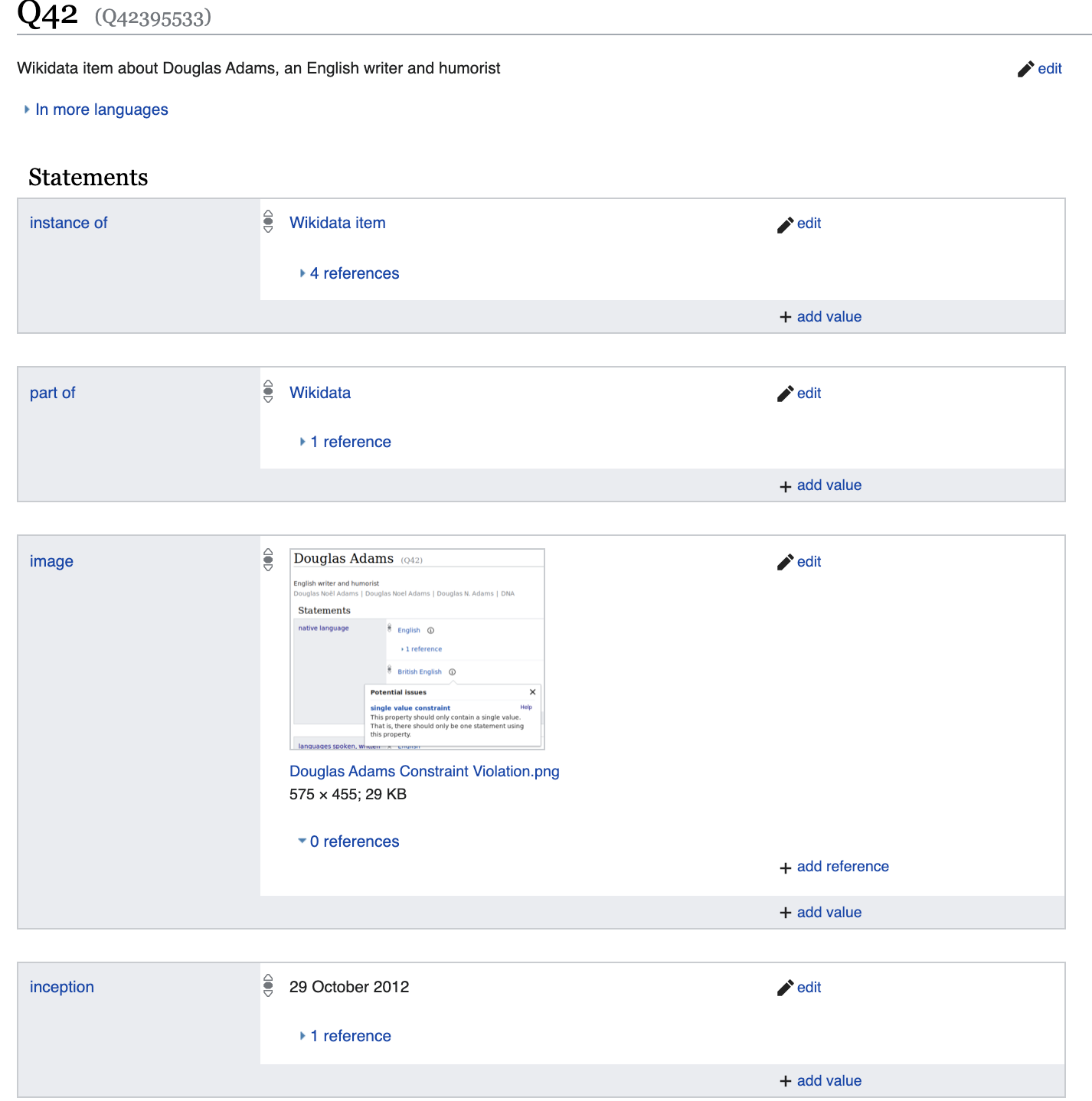
veamos un conjunto de propiedades que se diferenciarán significativamente de, por ejemplo, Diego Maradonna.
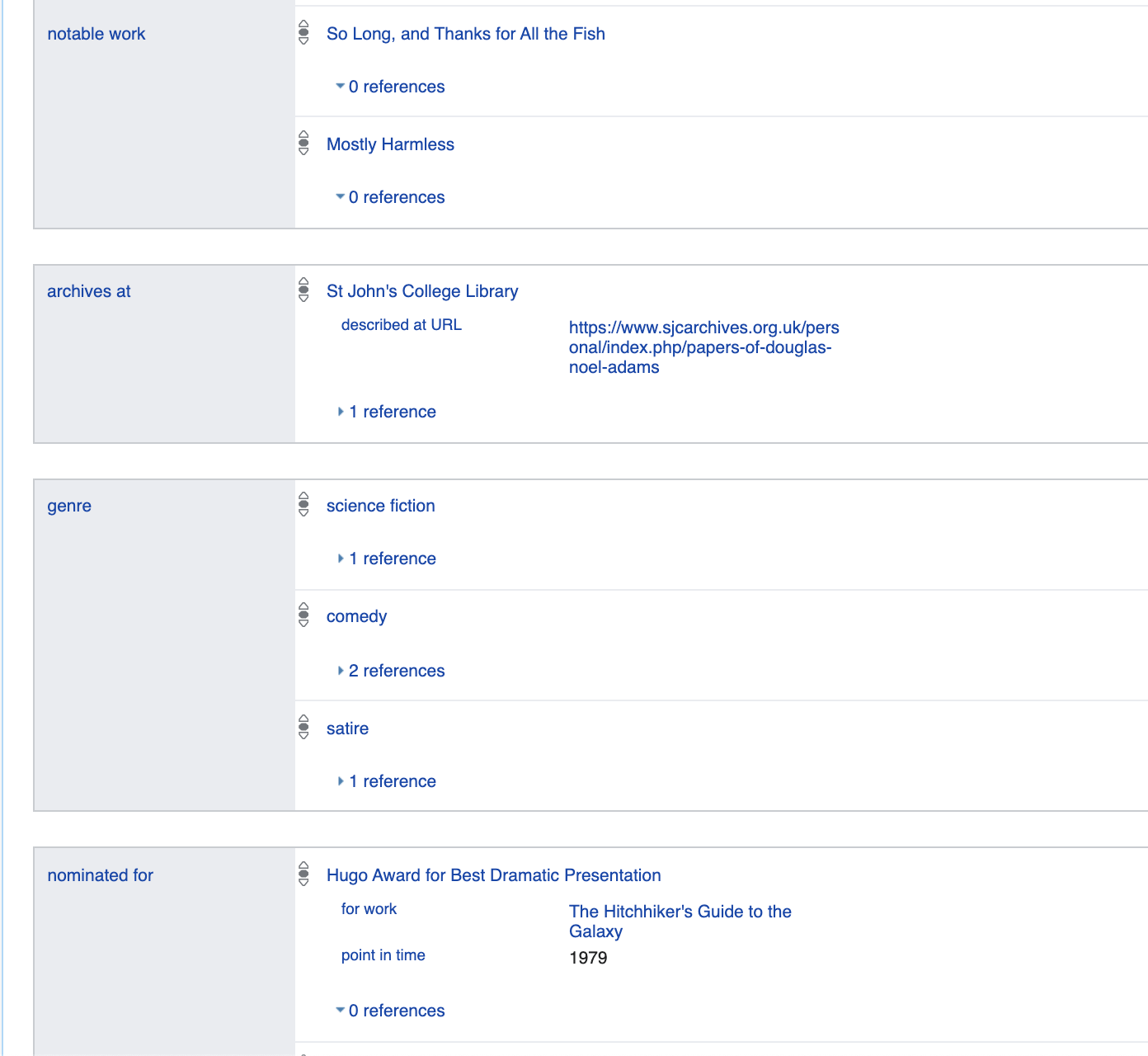
Hablemos un poco más sobre las propiedades especificadas aquí. Por ejemplo, género: masculino es

esencialmente un reflejo del hecho lógico: p21 (Q42, Q6581097).
Donde p21 → es gender_identity / 2 es un predicado binario
Q42 → Douglas Adams
Q6581097 → male
Por lo tanto, todos los datos se presentan como predicados unarios, por ejemplo is_dead (Q42), o como p21 binario (Q42, Q6581097).
De hecho, este es otro paradigma paradigmático de modelado: lógica de primer orden, pero sobre predicados unarios y binarios.
Y aquí es muy fácil agregar nuevos datos: todo lo que no está indicado en forma de predicado sobre objetos es falso, en la literatura se conoce como el supuesto del mundo cerrado .
Además, este formato permite un metamodelado absolutamente natural
https://www.wikidata.org/wiki/Q42395533
Hay varias consultas básicas de almacenamiento y escritura para dichos datos; veamos las opciones populares.
RDF y el lenguaje de consulta SPARQL
RDF es un lenguaje formal para describir datos relacionados para el procesamiento posterior de consultas, es decir, es un formato legible por máquina.
De hecho, para él, la clave es el concepto de triplete:

y aquí hay un ejemplo de registro de datos en este modelo (los prefijos determinan dónde se encuentran las "descripciones" de estos predicados)

Este formato de registro le permite representar gráficamente datos sobre objetos; por ejemplo, puede escribir información sobre la ciudad de Berlín.

Para el formato RDF, crearon el lenguaje de consulta SPARQL: que esencialmente describe las restricciones sobre los predicados lógicos y dice qué variable debe extraerse de la expresión lógica:

Lo que realmente queremos encontrar es el valor de la variable? País, de modo que member_of es verdadero que member_of (? País, q458) y q458 es el ID de la UE.
En código real, podría verse así:
Total: RDF es un formato para representar datos en forma de triples (predicados binarios) y SPARQL es un lenguaje de consulta basado en lógica para triples.
Derivados y lenguaje de consulta de registro de datos
Además, para escribir consultas en RDF (y no solo en él, más sobre eso más adelante), puede usar Datalog, un lenguaje declarativo (a menudo) que representa sintácticamente un subconjunto de Prolog (más a menudo).
En él, las consultas se ven así: la
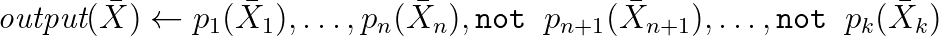
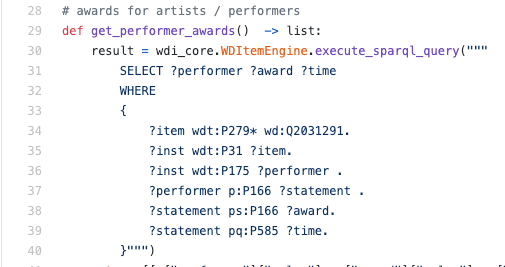
sintaxis a menudo se amplía con agregaciones y otras cosas prácticamente importantes. De hecho, estas son reglas de inferencia tomadas de la lógica y, con su ayuda, puede modelar la inferencia de nuevas propiedades y escribir consultas en RDF. El siguiente es un ejemplo del mundo real trabajando con WikiData basado en uno de los dialectos

Otra ventaja importante de los lenguajes de consulta lógica basados en Datalog es que para ellos RDF es simplemente un formato para registrar hechos (declaraciones) de lógica binaria. También pueden manejar cualquier otra afirmación lógica, no necesariamente binaria.
conclusiones
Primero, los datos relacionales son adecuados para modelar dominios fijos, donde el esquema cambia con poca frecuencia o los cambios afectan no solo a registros individuales, sino a segmentos completos.
En segundo lugar, los lenguajes relacionales son adecuados para tareas de modelado en las que es necesario extraer subtablas, transformar y combinar las existentes; esta no es una herramienta ideal cuando una parte importante del trabajo pasa al nivel de modificación y / o inferencia en un registro en particular.
En tercer lugar, si el dominio de modelado es un área que lo abarca todo, e incluso cambia, donde incluso los registros de la misma clase son sorprendentemente diferentes, los datos coherentes son adecuados.
Cuarto, la representación estándar es RDF y tiene sentido intentarlo primero. Al atornillar las bases de datos necesarias y usar lenguajes similares a SPARQ, puede extraer los datos necesarios.
En quinto lugar, si el modelado con tripletes se vuelve engorroso e incómodo, puede considerar la representación lógica de los datos y Datalog como un lenguaje de consulta.

