
Por lo tanto, considere un gráfico ponderado dirigido. Deje que la gráfica tenga n vértices. Cada par de vértices corresponde a algún peso (probabilidad de transición).

Cabe señalar que los gráficos web típicos son una cadena de Markov discreta y homogénea para la que se satisfacen la condición de indecomponibilidad y la condición de aperiodicidad.
Escribamos la ecuación de Kolmogorov-Chapman:
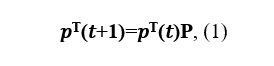
donde P es la matriz de transición.
Suponga que hay un límite. El
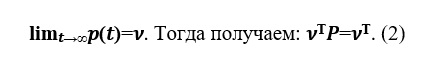
vector v se llama distribución de probabilidad estacionaria.
Fue a partir de la relación (2) que se propuso buscar el vector de ranking de páginas web en el modelo Brin-Page.
Dado que v es un límite,

la distribución estacionaria se puede calcular mediante el método de iteraciones simples (MPI).
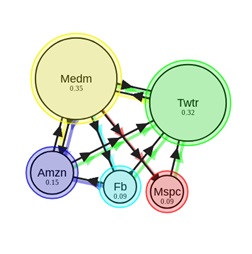
Para pasar de una página web a otra, el usuario debe, con cierta probabilidad, elegir a qué enlace ir. Si el documento tiene varios enlaces salientes, asumiremos que el usuario hace clic en cada uno de ellos con la misma probabilidad. Y finalmente, también está el coeficiente de teletransportación, que nos muestra que con cierta probabilidad el usuario puede pasar del documento actual a otra página, no necesariamente relacionada directamente con la página en la que nos encontramos en este momento. Deje que el usuario se teletransporte con probabilidad δ, entonces la ecuación (1) tomará la forma

Para 0 <δ <1, se garantiza que la ecuación tiene una solución única. En la práctica, se suele utilizar una ecuación con δ = 0,15 para calcular el PageRank.
Considere un gráfico web de Google de un enlace de sitio. Este gráfico web contiene 875713 vértices, lo que significa que para una matriz P bidimensional, debe asignar 714 Gb de memoria. La RAM de las computadoras modernas es un orden de magnitud menor, por lo que la computadora comienza a usar la memoria del disco duro, cuyo acceso ralentiza enormemente el trabajo del programa de cálculo de PageRank. Pero la matriz P es una matriz dispersa, una matriz con elementos predominantemente cero. Para trabajar con matrices dispersas en Python, se usa el módulo disperso de la biblioteca scipy, que ayuda a la matriz P a ocupar mucha menos memoria.
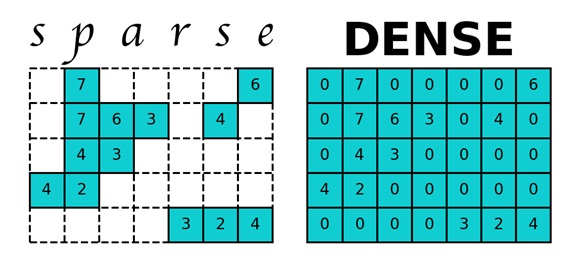
Apliquemos este algoritmo a estos datos. Los nodos son páginas web y los bordes dirigidos son hipervínculos entre ellos.
Primero, importemos las bibliotecas que necesitamos:
import cvxpy as cp
import numpy as np
import pandas as pd
import time
import numpy.linalg as ln
from scipy.sparse import csr_matrix
Ahora pasemos a la implementación en sí:
#
data = pd.read_csv("web-Google.txt", names = ['i','j'], sep="\t", header=None)
NODES = 916428
EDGES = 5105039
#
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
b = NEW.sum(axis=1)
NEW = NEW.transpose()
#
p0 = np.ones((NODES,1))/NODES
eps = 10**-5
delta = 0.15
ERROR = True
k = 0
#
while (ERROR == True):
with np.errstate(divide='ignore'):
z = p0 / b
p1 = (1-delta) * NEW.dot(csr_matrix(z)) + delta * np.ones((NODES,1))/NODES
if (ln.norm(p1-p0) < eps):
ERROR = False
k = k + 1
# PageRank
p0 = p1
En los gráficos podemos ver cómo el vector p llega a un estado estacionario v :

Utilizando el vector PageRank, también podemos determinar el ganador en las elecciones. Un pequeño subconjunto de colaboradores de Wikipedia son administradores, que son usuarios con acceso a funciones técnicas adicionales para ayudar en el mantenimiento. Para que un usuario se convierta en administrador, se emite una solicitud de administrador y la comunidad de Wikipedia, a través de comentarios públicos o votaciones, decide a quién promover al puesto de administrador.
El problema de PageRank también puede reducirse a un problema de minimización y resolverse utilizando el método de gradiente condicional de Frank-Wolfe, que es el siguiente: seleccione uno de los vértices del símplex y haga un punto de partida en este vértice. Implementación de este método en datos: el enlace se presenta a continuación:
#
data = pd.read_csv("grad.txt", names = ['i','j'], sep="\t", header=None)
NODES = 6301
EDGES = 20777
#
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
b = NEW.sum(axis=1)
NEW = NEW.transpose()
e = np.ones(NODES)
with np.errstate(divide='ignore'):
z = e / b
NEW = NEW.dot(csr_matrix(z))
#
eps = 0.05
k=0
a_0 = 1
y = np.zeros((NODES,1))
p0 = np.ones((NODES,1))/NODES
#
p0[0] = 0.1
y[np.argmin(df(p0))] = 1
p1 = (1-2/(1+k))*p0 + 2/(1+k)*y
#
while ((ln.norm(p1-p0) > eps)):
y = np.zeros((NODES,1))
k = k + 1
p0 = p1
y[np.argmin(df(p0))] = 1
p1 = (1-2/(1+k))*p0 + 2/(1+k)*y

Para el funcionamiento eficaz de un motor de búsqueda real, la velocidad de cálculo del vector PageRank es más importante que la precisión de su cálculo. MPI no le permite sacrificar la precisión en aras de la velocidad de cálculo. El algoritmo de Monte Carlo ayuda hasta cierto punto a hacer frente a este problema. Lanzamos un usuario virtual que deambula por las páginas de los sitios. Al recopilar estadísticas de sus visitas a las páginas del sitio, después de un período de tiempo bastante largo obtenemos por cada página cuántas veces la ha visitado el usuario. Al normalizar este vector, obtenemos el vector PageRank deseado. Demostremos cómo funciona este algoritmo con datos que ya están en uso .
#
def get_edges(m, i):
if (i == NODES):
return random.randint(0, NODES)
else:
if (len(m.indices[m.indptr[i] : m.indptr[i+1]]) != 0):
return np.random.choice(m.indices[m.indptr[i] : m.indptr[i+1]])
else:
return NODES
#
data = pd.read_csv("web-Google.txt", names = ['i','j'], sep="\t", header=None)
NODES = 916428
EDGES = 5105039
NEW = csr_matrix((np.ones(len(data['i'])),(data['i'],data['j'])),shape=(NODES,NODES))
#c , total –
for total in range(1000000,2000000,100000):
#
k = random.randint(0, NODES)
# PageRank
ans = np.zeros(NODES+1)
margin2 = np.zeros(NODES)
ans_prev = np.zeros(NODES)
for t in range(total):
j = get_edges(NEW, k)
ans[j] = ans[j]+1
k = j
#
ans = np.delete(ans, len(ans)-1)
ans = ans/sum(ans)
for number in range(len(ans)):
margin2[number] = ans[number] - ans_prev[number]
ans_prev = ans
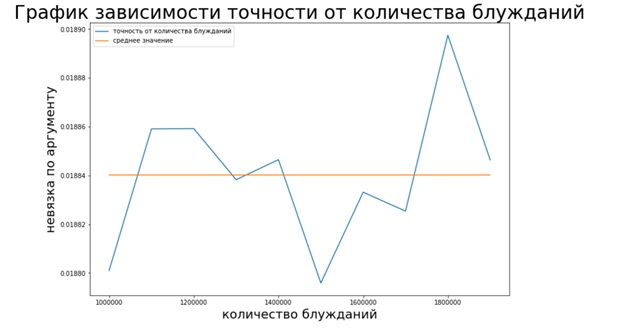
Como se puede ver en el gráfico, el método de Monte Carlo, a diferencia de los dos métodos anteriores, no es estable (no hay convergencia), sin embargo, ayuda a estimar el vector Page Rank sin requerir mucho tiempo.
Conclusión: Por lo tanto, hemos considerado los principales algoritmos para determinar el PageRank de los gráficos web. Antes de comenzar a diseñar un sitio web, debe asegurarse de que el PageRank no se desperdicie prestando atención a las siguientes cosas:
- Los enlaces internos muestran cómo se acumula el "poder de enlace" en su sitio, así que concéntrese en la información importante en la página de inicio del sitio, ya que la página de "inicio" del sitio tiene el PageRank más fuerte.
- Páginas huérfanas que no están vinculadas desde otras páginas de su sitio. Trate de evitar esas páginas.
- Vale la pena mencionar los enlaces externos si son de beneficio para el visitante de su sitio.
- Los enlaces entrantes rotos diluyen el peso total de la página, por lo que debe supervisarlos periódicamente y "arreglarlos" si es necesario.
Sin embargo, esto no significa que deba estar obsesionado con PageRank. Pero vale la pena recordar que al prestar atención a la estructura del sitio al construirlo, las características de los enlaces internos y externos, está optimizando el sitio para PageRank.