CREATE TABLE task AS
SELECT
id
, (random() * 100)::integer person -- 100
, least(trunc(-ln(random()) / ln(2)), 10)::integer priority -- 2
FROM
generate_series(1, 1e5) id; -- 100K
CREATE INDEX ON task(person, priority);
La palabra "es" en SQL se convierte en
EXISTS
: aquí está la versión más simple y comencemos:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

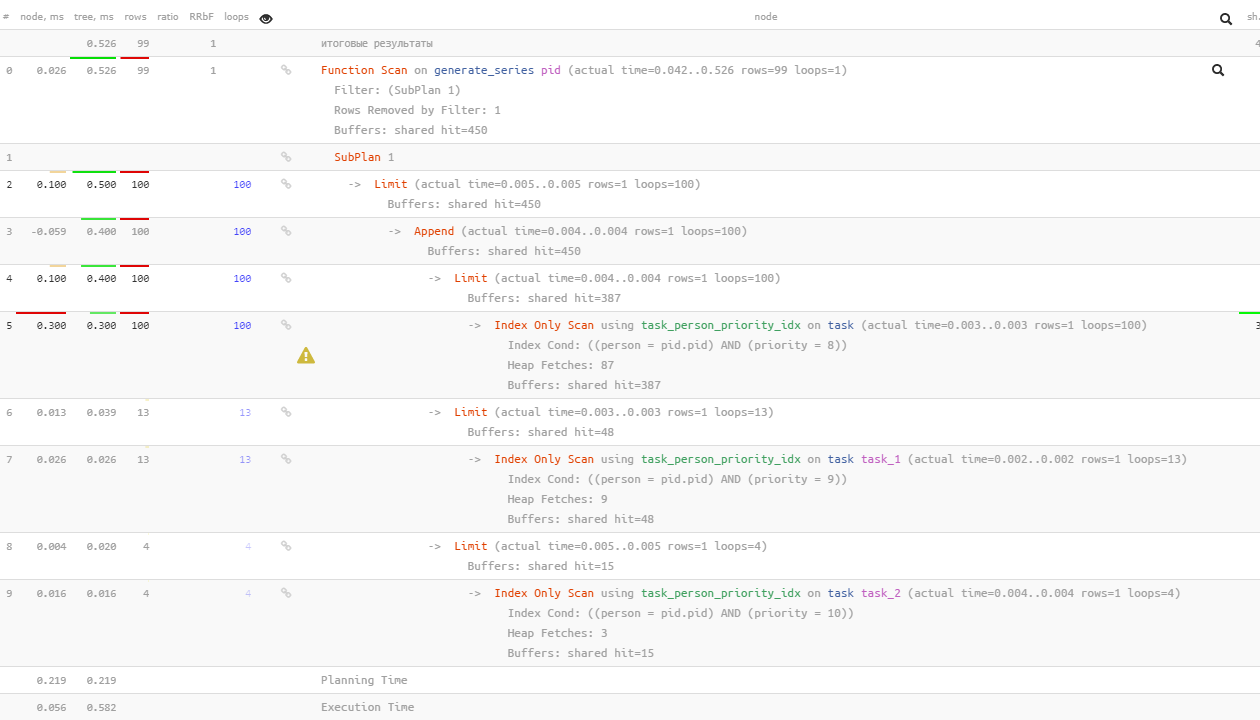
se puede hacer clic en todas las imágenes del plan
Hasta ahora, todo se ve bien, pero ...
EXISTE + EN
... luego vinieron a nosotros y nos pidieron clasificar no solo el
priority = 10
8 y el 9 como "super" :
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority IN (10, 9, 8)
);

Leyeron 1,5 veces más y también afectó el tiempo de ejecución.
O + EXISTE
Tratemos de usar nuestro conocimiento de que es
priority = 8
mucho más probable encontrar un récord con más de 10:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) OR
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
);

Tenga en cuenta que PostgreSQL 12 ya es lo suficientemente inteligente como para realizar
EXISTS
-subconsultas subsiguientes solo para aquellas "no encontradas" por las anteriores después de 100 búsquedas de valor 8 - solo 13 para el valor 9 y solo 4 para 10.
CASO + EXISTE + ...
En versiones anteriores, se puede lograr un resultado similar "ocultando bajo CASE" las siguientes consultas:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
) THEN TRUE
ELSE
CASE
WHEN
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
) THEN TRUE
ELSE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
)
END
END;
EXISTE + UNIÓN TODO + LÍMITE
Lo mismo, pero puedes ir un poco más rápido si usas el "truco"
UNION ALL + LIMIT
:
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 8
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 9
LIMIT 1
)
UNION ALL
(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority = 10
LIMIT 1
)
LIMIT 1
);
Los índices correctos son la clave para la salud de la base de datos
Ahora veamos el problema desde un lado completamente diferente. Si sabemos con certeza que el
task
número de registros que queremos encontrar es varias veces menor que el resto , haremos un índice parcial adecuado. Al mismo tiempo, pasaremos inmediatamente de la enumeración "punto"
8, 9, 10
a
>= 8
:
CREATE INDEX ON task(person) WHERE priority >= 8;
SELECT
*
FROM
generate_series(0, 99) pid
WHERE
EXISTS(
SELECT
NULL
FROM
task
WHERE
person = pid AND
priority >= 8
);

¡Tuve que leer 2 veces más rápido y 1,5 veces menos!
Pero, probablemente, restar todos los adecuados a la
task
vez, ¿será aún más rápido? ...
SELECT DISTINCT
person
FROM
task
WHERE
priority >= 8;

Lejos de siempre, y ciertamente no en este caso, porque en lugar de 100 lecturas de los primeros registros disponibles, ¡tenemos que leer más de 400!
Y para no adivinar cuál de las opciones de consulta será más efectiva, sino para saberlo con confianza, use explica.tensor.ru .