
“¡Déjame en paz, por favor, soy un creador! ¡Déjame crear! ”- el programador Gennady por tercera vez esta noche recita este mantra en su cabeza. Sin embargo, todavía no ha escrito una sola línea de código, porque ha llegado otra solicitud de extracción a la biblioteca que está tratando de desarrollar. Y, de acuerdo con la política de la empresa, la revisión del código debe realizarse con retrasos mínimos. Ahora Gennady está pensando en qué hacer: sin buscar aceptar los cambios, también sin buscar rechazarlos, o aún dedicar un tiempo precioso a comprender su esencia. Después de todo, ¿quién sino él? Escribió este código, lo seguirá. Y todos los cambios son posibles solo con su consentimiento personal, porque esta es la Biblioteca Doomsday.
Mientras tanto, literalmente detrás del muro, un equipo llamado "Cedar Beavers" redistribuye las solicitudes entre ellos para que la carga al verlas caiga más o menos uniformemente. Sí, no se ocupan de la Biblioteca Doomsday, pero realizan otras tareas que requieren cambios de código rápidos y procesos más rápidos.
No existe una solución única para todos los casos: para algunos, la racionalización y la velocidad de los procesos es importante, en algún lugar puede ser necesario tener una mano firme y un control total. Además, en diferentes etapas del desarrollo del mismo producto, pueden ser necesarios diferentes enfoques para reemplazarse entre sí. Cada uno de ellos tiene sus pros y sus contras, y en base a ellos, llegamos a donde estamos ahora.
Entonces, ¿a dónde fuimos en Wrike?
¿Qué opciones elegimos de nuestra propia forma de poseer el código?
Estrictamente personal. Ni siquiera hemos considerado esto. Ahora, si Gennady prohíbe la creación de solicitudes de extracción a su biblioteca, y hace todos los cambios personalmente, entonces obtiene un enfoque estrictamente personal. Seguramente Gennady comenzó de esta manera.
Una de las desventajas obvias de este enfoque es simplemente el totalitarismo en el mundo del desarrollo. Gennady es sin exagerar la única persona en la Tierra que conoce a fondo el código, tiene (o no) planes para su desarrollo y puede cambiarlo. El mismo bus, que es el "factor de graves", ya ha salido de la esquina. Si Gennady se resfría, lo más probable es que el proyecto fracase con él. Otro desarrollador tendrá que bifurcar, habrá muchos y se producirá un caos total.
Este enfoque tiene una ventaja: un enfoque de desarrollo completamente consolidado. Una persona toma todas las decisiones sobre arquitectura, estilo de código y resuelve personalmente cualquier problema. Sin gastos de comunicación.
Condicionalmente personal. Esto es exactamente lo que Gennady no quiere hacer: ver todos los MR, dar la oportunidad de cambiar el código de su biblioteca a otras personas, pero tener control total sobre los cambios y tener derecho de veto. Los pros y los contras son los mismos que en el párrafo anterior, pero ahora están un poco suavizados por la capacidad de enviar una solicitud de extracción a desarrolladores externos directamente al repositorio, y no redactar una especificación técnica para la implementación de algunas características.
Colectivocomo Cedar Beavers. En este caso, todo el equipo es responsable del código, y sus propios miembros deciden quién vigilará qué solicitud.
Entre las ventajas, se puede notar la alta velocidad de revisión de la revisión, la distribución de la experiencia entre los miembros del equipo y una disminución en el factor bus. Por supuesto, también hay desventajas. En discusiones en Internet, muchos mencionan la falta de responsabilidad si se "contagia" entre varias personas. Pero depende de la estructura del equipo y la cultura de los desarrolladores: el desarrollador senior o el líder del equipo puede ser responsable del equipo, luego será el punto de entrada para las preguntas. Y MR y escribir nuevas funciones se pueden dividir según el nivel de formación del desarrollador. Después de todo, sería incorrecto darle a un novato que recién está comenzando a comprender la arquitectura de la aplicación para refactorizar el código.
En Wrike, adoptamos un enfoque colaborativo para la propiedad del código, con el líder del equipo como la principal responsabilidad. Esta persona tiene la mayor experiencia en el código, sabe qué desarrollador es competente en la revisión de una complejidad particular y tiene la responsabilidad total de la calidad del código del equipo.
Pero el camino hacia la implementación técnica de esta solución no fue el más fácil. Sí, en palabras, todo suena bastante fácil: aquí hay una función, aquí hay un comando. El equipo sabe de qué es responsable, lo que significa que lo controlará.
Tales acuerdos pueden funcionar como un contrato verbal si el número de comandos es menor que el número de dedos de una mano. Y en nuestro caso, son más de treinta comandos y millones de líneas de código. Además, a menudo los límites de una característica no pueden ser designados por un repositorio: hay integraciones bastante cercanas de algunas características en otras.
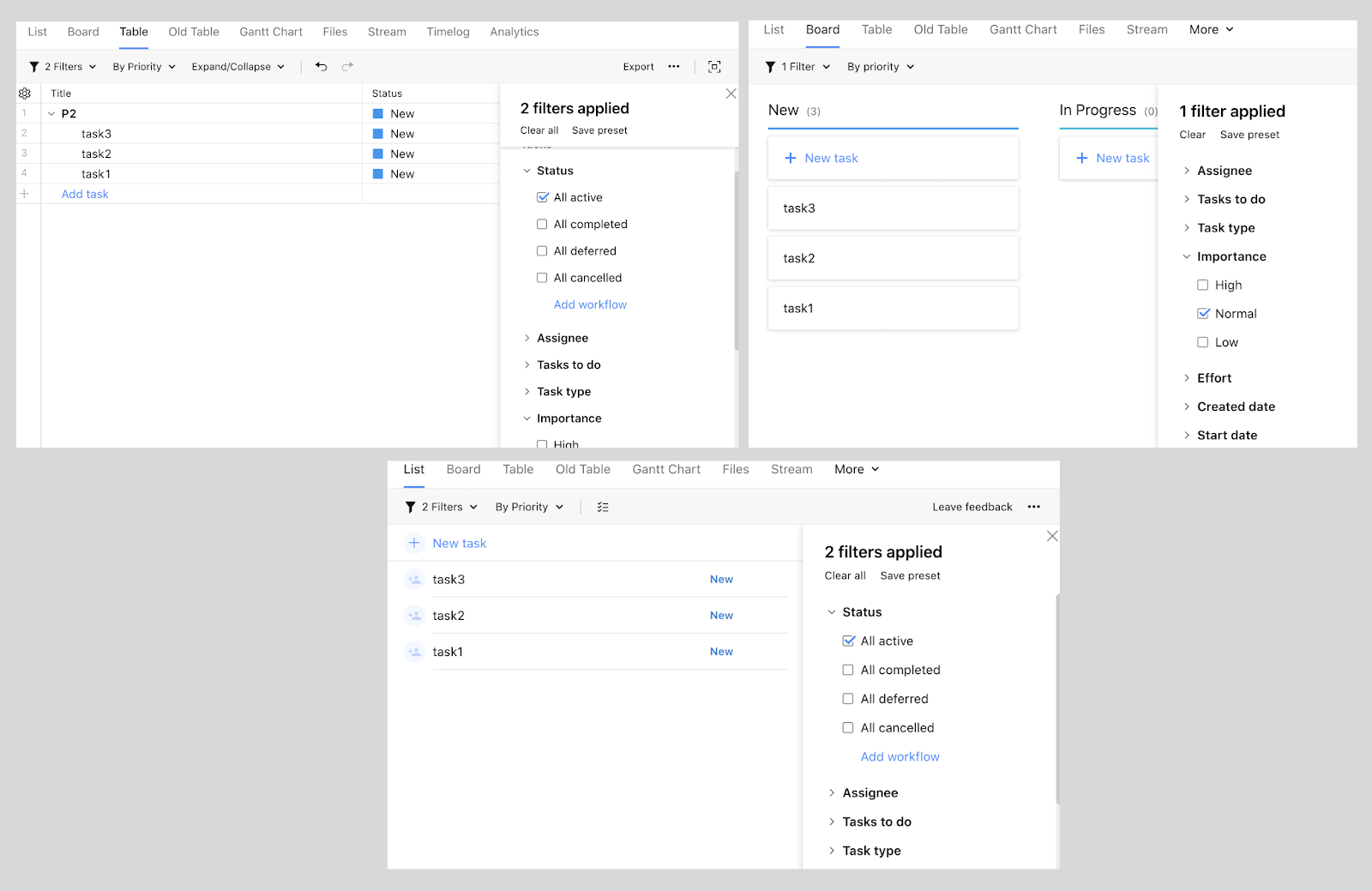 El panel de filtro de la derecha es el mismo para todas las vistas. Esta es una característica del equipo "A". Además, todas las vistas son características de los otros tres equipos, el
El panel de filtro de la derecha es el mismo para todas las vistas. Esta es una característica del equipo "A". Además, todas las vistas son características de los otros tres equipos, el
ejemplo más obvio son los filtros. Se ven y se comportan igual en todas las vistas posibles, mientras que las vistas en sí mismas pueden diferir en funcionalidad. Esto significa que la vista pertenece a un equipo y el panel de filtro único pertenece a otro. Y así, decenas de repositorios, miles de archivos de código diferente. ¿A quién debe acudir para realizar una revisión si necesita realizar cambios en un archivo específico?
Al principio intentamos resolver este problema con un simple archivo JSON que estaba en la raíz del repositorio. Había una descripción de la funcionalidad y los nombres de los responsables. Podrían ser contactados para obtener una revisión de su solicitud de extracción.
Esto es un poco como un modelo de propiedad de código personal condicional. La única excepción es que no se indica a una persona como responsable, sino dos o tres. Pero este enfoque nunca nos convenció: la gente se mudó a otros equipos, se enfermó, se fue de vacaciones, renunció, y cada vez teníamos que buscar primero a alguien que reemplace al propietario especificado y luego decirle a los propietarios que cambien manualmente el nombre y presionen los cambios.
Más tarde, pasaron de personas específicas a especificar comandos.Sin embargo, todo está en el mismo archivo JSON. No mejoró mucho, porque ahora era necesario encontrar miembros del equipo a quienes se pudiera enviar el código para su revisión. Y tenemos cientos (un poco astutos, casi 70) desarrolladores front-end, y no fue fácil encontrar a todos los participantes en ese momento. El sistema de propiedad ya se ha convertido en colectivo, pero encontrar a las personas adecuadas a veces no era más fácil que buscar un propietario adjunto de la versión anterior. Además, el problema con el código, en el que varias características podrían cruzarse, aún no se pudo resolver.
Por lo tanto, era de vital importancia resolver dos preguntas: cómo asignar ciertas funciones a un determinado equipo dentro del repositorio de otro equipo y cómo hacer que la información sea simple y accesible para todos los equipos que puedan poseer el código.
Por qué las herramientas prefabricadas no nos quedaban bien.Existen herramientas en el mercado para asignar personas a las revisiones y asociar a personas específicas con un código. Al usarlos, no es necesario recurrir a la creación de archivos con los nombres de las personas a las que debe ejecutar en caso de revisiones, errores, refactorizaciones complejas.
En Azure DevOps Services tiene funcionalidad: incluye automáticamente el revisor de código. El nombre habla por sí solo, y un ex colega mío dice que utilizan esta herramienta en su empresa y con mucho éxito. No trabajamos con Azure, por lo que sería genial escuchar a los lectores cómo van las cosas con el autorrevisor.
Usamos GitLab, por lo que sería lógico mirar hacia los propietarios de código de GitLab. Pero el principio de funcionamiento de esta herramienta no nos convenía: la funcionalidad de GitLab es un montón de rutas en el repositorio (archivos y carpetas) y personas a través de sus cuentas en GitLab. Este paquete está escrito en un archivo especial: codeowners.md. Necesitábamos un montón de ruta y características. Además, nuestras funciones están contenidas en un diccionario especial, donde se asignan al comando. Esto le permite marcar características complejas que pueden existir en más de un repositorio, ser desarrolladas por varios equipos y, nuevamente, no estar vinculadas a nombres específicos. Además, teníamos planes de utilizar esta información para crear un directorio conveniente de equipos, funciones asociadas y todos los miembros del equipo.
Como resultado, decidimos crear nuestro propio sistema de control de propiedad del código. La implementación de la primera versión de nuestro sistema se basó en las capacidades del Dart SDK , porque en un principio se lanzó para los repositorios del departamento de front-end y solo para los archivos Dart. Usamos nuestras propias metaetiquetas (afortunadamente, esto es compatible a nivel de idioma), luego ejecutamos todos los archivos fuente con un analizador estático e hicimos algo así como una tabla: Archivo / Característica - Comando del propietario Puede marcar tanto archivos separados como rutas completas con varias carpetas.
Después de un tiempo, el marcado con características estuvo disponible para el código en Dart, JS y Java, y esta es la base de código completa: tanto el frontend como el backend. Para obtener información sobre los propietarios, se utiliza un analizador estático. Pero, por supuesto, no es lo mismo que en la primera versión y solo funcionaba con código Dart. Por ejemplo, para archivos Java, se utiliza la biblioteca javaparser . Estos analizadores se ejecutan según lo programado y recopilan toda la información relevante en un solo registro.
Además de vincular cierto código a los equipos propietarios, construimos una integración con el servicio para recopilar errores en la producción y publicamos toda la información útil sobre los equipos y las funciones en un recurso interno. Ahora cualquier empleado puede ver a quién acudir si de repente tiene preguntas en una vista en particular. Y también lo hicimos automático para crear tareas para los responsables en caso de algunos cambios globales, como pasar a una nueva versión de Dart o Angular.
 Al hacer clic en el comando, puede ver todas las características, todos los miembros del equipo, qué características son puramente técnicas y cuáles son producto
Al hacer clic en el comando, puede ver todas las características, todos los miembros del equipo, qué características son puramente técnicas y cuáles son producto
Como resultado, obtuvimos no solo un sistema bastante flexible para vincular funciones con equipos, sino también una infraestructura completa que ayuda, a partir del código, a encontrar una función relacionada, un equipo con todos los participantes, un propietario de producto de una función e informes de errores.
Entre las desventajas se encuentran la necesidad de monitorear de cerca el marcado de características al refactorizar y transferir código de un lugar a otro, y la necesidad de poder adicional para recopilar toda la información sobre el marcado.
¿Cómo resuelves el problema de poseer tu código? ¿Y hay algún problema relacionado y, lo más importante, su solución?