Dio la casualidad de que en 1998 ingresé a la escuela de posgrado en la Academia Estatal de Agricultura de Rusia y elegí AI / ML como el tema de mi trabajo científico. Estos fueron los duros tiempos de la próxima era de hielo de las redes neuronales. Fue en este momento que Yang Lecun publicó su famoso trabajo "Aprendizaje basado en gradientes aplicado al reconocimiento de documentos" sobre los principios de la organización de redes convolucionales, que, en mi opinión, fue solo el comienzo de un nuevo deshielo. Es curioso que en ese momento estuve trabajando en algunos elementos similares, es cierto que dicen que la idea, cuando llega el momento, está en el aire. Sin embargo, no todo el mundo está dispuesto a darle vida. Desafortunadamente, nunca llevé mi trabajo a la defensa, pero siempre quise terminarlo algún día.
Fuente: Hitecher
Y ahora, después de 20 años, cuando comencé a trabajar como docente en la Universidad Federal del Sur y al mismo tiempo enseñaba en el programa de educación adicional "Samsung IT School", tuve una segunda oportunidad. Samsung ofreció a SFedU ser el primero en lanzar la pista de capacitación "Samsung IT Academy" sobre inteligencia artificial para licenciados y maestros. Tenía algunas preocupaciones de que sería posible implementar todo el plan de estudios en su totalidad, pero respondí con entusiasmo a la oferta de leer el curso. Me di cuenta de que el círculo estaba cerrado y todavía tenía una segunda oportunidad de hacer lo que una vez había fallado. Cabe señalar aquí que el curso Samsung AI / ML es uno de los mejores cursos de idioma ruso abiertos actualmente disponibles de forma gratuita en la plataforma Stepik ( https://stepik.org/org/srr). Sin embargo, en el caso de un programa universitario, además del curso teórico / práctico, se agregó la parte del proyecto. Es decir, se consideró dominado el plan de estudios anual de "Samsung IT Academy" en el caso de cursar dos módulos "Redes neuronales y visión artificial", "Redes neuronales y procesamiento de texto" con la recepción de los certificados Stepik correspondientes, así como la implementación de un proyecto individual. El curso finalizó con la defensa de los proyectos de los estudiantes, a la que se invitó a expertos, incl. empleados del Centro de Moscú de Inteligencia Artificial Samsung.
Y desde septiembre de 2019, hemos iniciado un curso en el Instituto de Altas Tecnologías y Piezotecnia de la SFedU. Por supuesto, un número bastante grande de estudiantes llegó al HYIP y posteriormente hubo una deserción escolar grave. El programa no era muy complicado, pero sí voluminoso; se necesitaban conocimientos:
- álgebra lineal,
- teoría de probabilidad,
- calculo diferencial,
- el lenguaje de programación Python.
Por supuesto, todos los conocimientos y habilidades requeridos no van más allá del plan de estudios del programa de pregrado de tercer año de la universidad. Daré un par de ejemplos, de los que son más complicados:
- Encuentre la derivada de la función de activación de la tangente hiperbólica
 y exprese el resultado en términos de
...
y exprese el resultado en términos de
...
- Encuentre la derivada de la función de activación sigmoidea
 y exprese el resultado en términos de la función sigmoidea
...
y exprese el resultado en términos de la función sigmoidea
...
- En el gráfico de cálculos que se muestra en la Fig. 1 presenta una función compleja
con parámetros
... Para mayor comodidad, se agregaron resultados intermedios de operaciones como
... Es necesario determinar a qué será igual la derivada
por parámetro

Para ser honesto, estudié algo apresuradamente, especialmente de algoritmos modernos para trabajar con redes neuronales, con estudiantes. Inicialmente, se asumió que los propios estudiantes estudiarían videoconferencias del curso en línea de Samsung en Stepik, y en el aula solo haríamos talleres. Sin embargo, tomé la decisión de leer la teoría también. Esta decisión se debe a que con el profesor se puede resolver un tema incomprensible, discutir las ideas que han surgido, etc. Los estudiantes recibieron tareas prácticas en forma de asignaciones de tareas. El enfoque resultó ser correcto: en el aula, se obtuvo un ambiente animado, vi que los estudiantes en general tuvieron bastante éxito en dominar el material.
Un mes después, pasamos sin problemas del modelo de neuronas a las primeras arquitecturas simples completamente conectadas, de la regresión simple a la clasificación de clases múltiples, del cálculo de gradiente simple a los algoritmos de optimización de descenso de gradiente SGD, ADAM, etc. Completamos la primera mitad del curso con redes convolucionales y arquitecturas de redes profundas modernas. La tarea final del primer módulo Computer Vision fue participar en la competencia " Dirty vs Cleaned " en Kaggle, superando el umbral de precisión del 80%.
Otro factor, en mi opinión, importante: no estábamos cerrados dentro de la universidad. Los organizadores de la pista realizaron seminarios web y clases magistrales para nosotros con expertos invitados de los laboratorios de Samsung. Tales eventos aumentaron la motivación de los estudiantes, y la mía, para ser honesta :). Por ejemplo, hubo un evento de orientación profesional interesante: un puente en línea entre las aulas de SFedU, la Universidad Estatal de Moscú y Samsung, donde los empleados del Centro de IA de Moscú Samsung hablaron sobre las tendencias modernas en el desarrollo de IA / ML y respondieron las preguntas de los estudiantes.
La segunda parte del curso, dedicada al procesamiento de textos, comenzó con una teoría general del análisis lingüístico. Luego, a los estudiantes se les presentaron los modelos de texto vectorial y TF-IDF, y luego la semántica de distribución y word2vec. A partir de los resultados se llevaron a cabo varios talleres interesantes: generar incrustaciones de word2wec, generar nombres y eslóganes. Luego pasamos a la teoría y la práctica del uso de redes convolucionales y recurrentes para el análisis de texto.
Si bien el punto es sí, publiqué un artículo en la revista VAK y comencé a preparar el siguiente, reuniendo gradualmente material para una nueva disertación. Mis alumnos tampoco se quedaron quietos, sino que empezaron a trabajar en sus primeros proyectos. Los estudiantes eligieron temas por su cuenta, y como resultado, se obtuvieron 7 proyectos de graduación en diferentes áreas de aplicación de las redes neuronales:
- « » , .
- « » .
- « » .
- « » .
- « » .
- « » .
- « » , .

Todos los proyectos fueron defendidos, pero el grado de complejidad y sofisticación fue diferente, lo que, con razón, se reflejó en las estimaciones de los proyectos. Según los resultados de la defensa, se seleccionaron cuatro proyectos para la competencia anual de la Academia de TI de Samsung . Y puedo decir con orgullo que el jurado otorgó a dos de nuestros proyectos los primeros lugares. A continuación, daré una breve descripción de estos proyectos, basada en los materiales proporcionados por mis alumnos Grateful Alexander, Krikunov Stanislav y Pandov Vyacheslav, por lo que muchas gracias a ellos. Creo que las soluciones que han demostrado bien pueden valorarse como un trabajo de investigación serio.
I « » «IT Samsung».
« », ,
El proyecto consistió en crear una aplicación móvil que identifique y cuantifique la actividad física en el entrenamiento mediante sensores de teléfonos móviles. Ahora existen muchas aplicaciones móviles que pueden reconocer la actividad física de una persona: Google Fit, Nike Training Club, MapMyFitness y otras. Sin embargo, estas aplicaciones no pueden reconocer ciertos tipos de ejercicio y contar el número de repeticiones.
Uno de los autores del proyecto Grateful Alexander, mi graduado en 2015 del programa Samsung IT School, y yo, no sin orgullo, nos alegramos de que los conocimientos adquiridos sobre desarrollo móvil en la escuela se aplicaran de esa manera.
¿Cómo se reconoce la actividad física? Comencemos con cómo se determina el momento del ejercicio. Para detectar el comienzo y el final de los ejercicios, los estudiantes decidieron utilizar el módulo de aceleración calculado como la raíz de la suma de los cuadrados de las aceleraciones a lo largo de los ejes. Se eligió un cierto umbral, con el que se comparó el valor de aceleración actual. Si se supera el umbral (la derivada de la aceleración es positiva), entonces consideramos que ha comenzado el ejercicio. Si la aceleración actual está por debajo del umbral (la derivada de la aceleración es negativa), entonces consideramos que el ejercicio ha terminado. Desafortunadamente, este enfoque no permite el procesamiento en tiempo real. Una posible mejora es la aplicación de una ventana deslizante sobre los datos con el cálculo del resultado en cada paso del turno.
El conjunto de datos fue recopilado por los propios autores. Al realizar 7 ejercicios diferentes, se utilizaron 3 tipos de teléfonos inteligentes (versiones de Android 4.4, 9.0, 10.0). El teléfono inteligente se adjuntó a la mano mediante un bolsillo especial. Tres voluntarios realizaron un total de 1800 repeticiones. Durante la ejecución podían surgir errores en la técnica por cualquier motivo, por lo que se llevó a cabo un procedimiento de limpieza de muestras. Para ello, se construyeron las distribuciones de correlaciones cruzadas para todo tipo de ejercicios. Luego, para cada ejercicio, se seleccionó un umbral de correlación, por debajo del cual el ejercicio se considera inadecuado y se excluye de la muestra.
Un mismo ejercicio, dependiendo de la repetición, tiene un tiempo de ejecución diferente. Para combatir esto, se decidió interpolar los datos con un número fijo de muestras, independientemente de cuántas provengan de los sensores. Recibido 50 - el doble de la frecuencia de muestreo, calculando las posiciones intermedias como el promedio aritmético de las vecinas. Recibido 200 - descartar cada 2 conteos. En este caso, el número de muestras será constante. De manera similar, para cualquier relación entre el número de entrada de muestras y el número de salida deseado.
Para la red neuronal, se decidió aplicar datos en el dominio de la frecuencia. Dado que el peso corporal de una persona es bastante grande, se puede esperar que las frecuencias de señal características se encuentren en la región de baja frecuencia del espectro en la mayoría de los ejercicios estándar. En este caso, las altas frecuencias se pueden considerar fluctuaciones durante la ejecución o ruido de los sensores. Qué significa eso? Esto significa que podemos encontrar el espectro de la señal usando la FFT y usar solo el 10-20% de los datos para el análisis. ¿Por qué tan poco? Dado que 1) el espectro es simétrico, puede cortar inmediatamente la mitad de los componentes 2) información básica: solo el 20-40% de la parte informativa del espectro. Estas suposiciones describen especialmente bien los ejercicios de fuerza lentos.
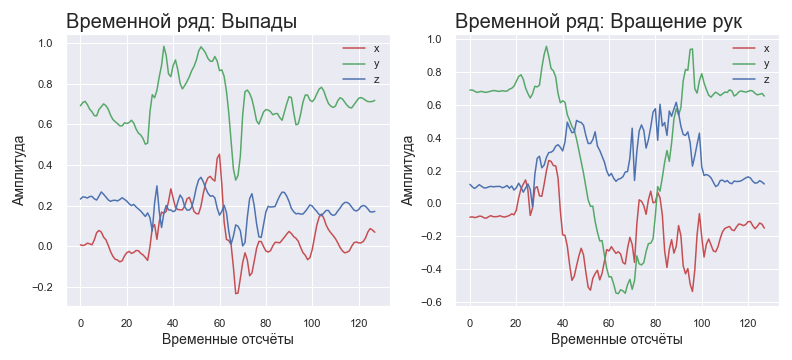
Series de tiempo normalizadas para diferentes ejercicios
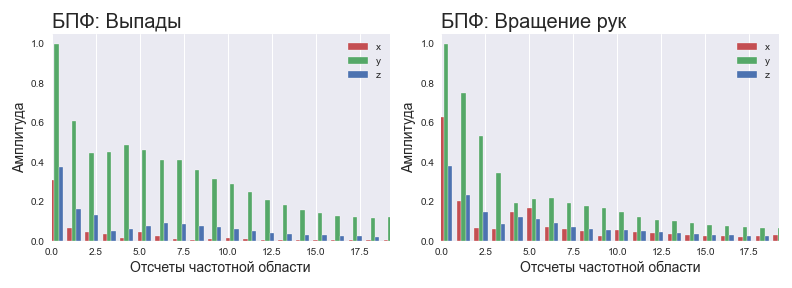
Espectro normalizado para diferentes ejercicios
Antes del procesamiento por la red neuronal, el espectro de datos se normaliza al valor máximo entre los tres ejes para ajustar todas las muestras de ejercicio en el rango de amplitud 0-1. En este caso, se conservan las proporciones entre los ejes.
La red neuronal realiza la tarea de clasificar ejercicios. Esto significa que genera un vector de probabilidades de todos los ejercicios de la lista con la que fue entrenado. El índice del elemento máximo en este vector es el número del ejercicio completado. Además, si la confianza en el ejercicio realizado es inferior al 85%, se considera que no se ha realizado ninguno de los ejercicios. La red consta de 3 capas: 4 convolucionales, 3 totalmente conectadas, el número de neuronas de salida es igual al número de ejercicios que queremos reconocer. En la arquitectura, para ahorrar recursos computacionales, solo se utilizan convoluciones con un tamaño de núcleo de 3x3. La arquitectura de red relativamente simple se justifica por los recursos informáticos limitados de los teléfonos inteligentes; en nuestra tarea, se requiere el reconocimiento con un retraso mínimo.

Descripción de la arquitectura de la red neuronal
La estrategia de entrenamiento de la red neuronal es el entrenamiento por épocas utilizando la normalización por lotes de los datos de entrenamiento hasta que la función de pérdida en la muestra de entrenamiento alcanza su valor mínimo.
Resultados: con un rendimiento de ejercicio más o menos de alta calidad, la confianza de la red es del 95-99%. En el conjunto de validación, la precisión fue del 99,8%.
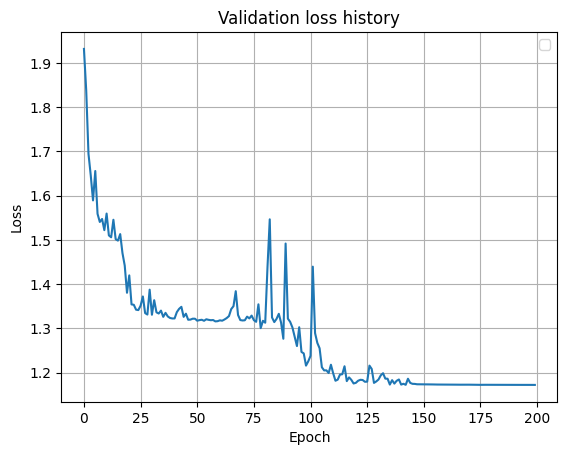
Error durante el entrenamiento en un conjunto de validación

Matriz de errores para una
red neuronal La red neuronal se integró en una aplicación móvil y mostró resultados similares a los del entrenamiento.
El estudio también probó otros modelos de aprendizaje automático que se utilizan hoy en día para resolver problemas de clasificación: regresión logística, bosques aleatorios, XG Boost. Para estas arquitecturas, se utilizó la regularización de Tikhonov (L2), la validación cruzada y la búsqueda de cuadrículas para encontrar los parámetros óptimos. Como resultado, los indicadores de precisión fueron los siguientes:
- Regresión logística: 99,4%
- Bosques aleatorios: 99,1%
- Aumento de XG: 97,5%
El conocimiento adquirido durante la capacitación en la Samsung IT Academy ayudó a los autores del proyecto a expandir los horizontes de sus intereses e hizo una contribución invaluable al ingresar al programa de maestría en el Instituto de Ciencia y Tecnología de Skolkovo. En este momento, mis alumnos están investigando allí en el campo del aprendizaje automático para sistemas de comunicación.
Código en GitHub
II « » «IT Samsung».
« »,
El trabajo de la modelo está bien descrito en esta diapositiva:

Todo comienza con una fotografía. En la implementación presentada, proviene de un bot de Telegram. Utilizándolo, Dlib frontal_face_detector encuentra todas las caras en la imagen. Luego, se detectan 68 puntos 2D clave de cada cara usando Dlib shape_predictor_68_face_landmarks. Cada conjunto se normaliza de la siguiente manera: centrado (restando el promedio de X e Y) y escalado (dividiendo por el máximo absoluto de X e Y). Cada coordenada del punto normalizado pertenece al intervalo [-1, +1].
Entonces entra en juego una red neuronal, que predice la profundidad de cada punto clave de la cara: la coordenada Z, utilizando las coordenadas normalizadas (X, Y). Este modelo se entrenó en el conjunto de datos AFLW2000.
Además, estos puntos están conectados entre sí, formando una máscara de malla. También se le puede llamar biometría facial. Las longitudes de los segmentos de dicha máscara se utilizan como una de las formas de definir las emociones. La idea es que cada segmento de línea tenga su propio lugar en el vector de segmento de línea y algunos de ellos dependan de la emoción. Y cada emoción, en teoría, tiene un número limitado de tales vectores. Esta hipótesis se confirmó en el curso de experimentos. Para entrenar dicho modelo, se utilizaron los siguientes conjuntos de datos: Cohn-Kanade +, JAFFE, RAF-DB.
Paralelamente, otra red está aprendiendo a clasificar las emociones por la propia imagen. Las imágenes de caras se recortan de los rectángulos que se encuentran con Dlib. Convertido a blanco y negro de un solo canal y comprimido a 48x48. Para entrenar este modelo, se utilizaron los mismos conjuntos de datos que para el modelo biométrico. Sin embargo, también se utilizó el conjunto de datos FER2013.
En conclusión, entra en funcionamiento la tercera red neuronal, cuya arquitectura combina las dos redes congeladas y preentrenadas anteriores con una capa entrenada. Estas redes también anulan las últimas capas completamente conectadas. En lugar del "vector de probabilidades" esperado mediante el cual se puede determinar la clase objetivo, ahora se devuelven más "características de bajo nivel". Y la capa unificadora está entrenada para interpretar esta información en la clase objetivo.
Entre las "soluciones similares" se encuentran las siguientes: EmoPy, DLP-CNN (RAF-DB), FER2013, EmotioNet. Sin embargo, es difícil hacer comparaciones porque fueron entrenados con diferentes datos.
Código en GitHub
Conclusión
En conclusión, me gustaría decir que el curso piloto ha demostrado su valía, y en este año académico 2020/21, el programa ya se está impartiendo en 23 universidades, socios de la Samsung IT Academy en Rusia y Kazajstán. La lista completa se puede ver aquí.... Este año, un grupo de maestros y solteros ya está estudiando con nosotros (¡incluso hay un doctorado completo en el grupo!) Y hasta ahora, en general, el granito de la ciencia está royendo con éxito. Aún no se han encontrado ideas para un proyecto individual, pero los estudiantes están llenos de optimismo. Por supuesto, en la próxima competencia de proyectos individuales, la competencia se multiplicará por diez, pero esperamos seguir recibiendo altas calificaciones por los logros de nuestros estudiantes. Y lo más importante, estoy seguro de que el conocimiento y la experiencia adquiridos serán de gran ayuda para nuestros graduados en su desarrollo futuro en el campo de las TI.
2020 Rostov del Don. SFedU, Academia de TI de Samsung.

Dmitry Yatsenko
Profesor titular del Departamento de Tecnologías de la Información y la Medición, Facultad de Altas Tecnologías, Universidad Federal del Sur,
Profesor de la Escuela de TI de Samsung,
Profesor de AI IT Track en Samsung Academy.