- Artículo de investigación
- Pytorch : YOLOv4-CSP, YOLOv4-P5, YOLOv4-P6, YOLOv4-P7 ( repositorio principal : se usa para reproducir resultados)
YOLOv4-CSP
YOLOv4-tiny
YOLOv4-large
- Darknet : YOLOv4-tiny, YOLOv4-CSP, YOLOv4x-MISH
- Estructura YOLOv4-CSP
Scaled YOLO v4 es la red neuronal más precisa ( 55,8% AP ) en el conjunto de datos de Microsoft COCO de cualquier red neuronal publicada hasta la fecha. Y también es el mejor en términos de la relación de velocidad a precisión en todo el rango de precisión y velocidad desde 15 FPS a 1774 FPS . Actualmente es la red neuronal Top1 para la detección de objetos.
YOLO v4 escalado supera a las redes neuronales en precisión:
- Google EfficientDet D7x / DetectoRS o SpineNet-190 (autodidacta en datos adicionales)
- Amazon Cascade-RCNN ResNest200
- Microsoft RepPoints v2
- Facebook RetinaNet SpineNet-190
Demostramos que los enfoques de red YOLO y Cross-Stage-Partial (CSP) son los mejores en términos de precisión absoluta y relación precisión / velocidad.
Gráfico de precisión (eje vertical) y latencia (eje horizontal) en GPU Tesla V100 (Volta) con lote = 1 sin usar TensorRT:
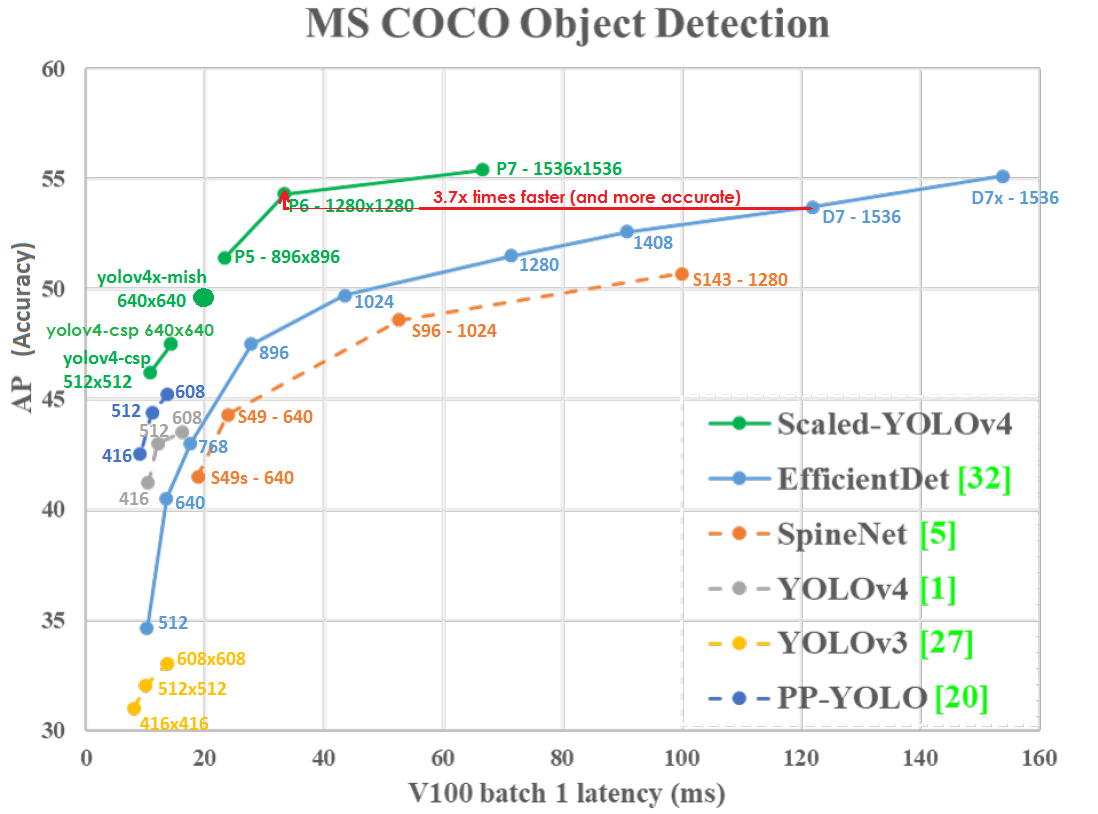
Incluso a una resolución de red más baja, Scaled-YOLOv4-P6 (1280x1280) 30 FPS es un poco más preciso y 3.7 veces más rápido que EfficientDetD7 (1536x1536) 8.2 FPS. Aquellos. YOLOv4 hace un mejor uso de la resolución de red.
YOLO v4 escalado se encuentra en la curva de optimización de Pareto ; no importa qué otra red neuronal tome, siempre existe una red YOLOv4 de este tipo, que es más precisa a la misma velocidad o más rápida con la misma precisión, es decir, YOLOv4 es el mejor en términos de velocidad y precisión.
YOLOv4 escalado es más preciso y más rápido que las redes neuronales:
- Google EfficientDet D0-D7x
- Google SpineNet S49s - S143
- Paleta Baidu PP YOLO
- Y muchos otros
Scaled YOLO v4 es una serie de redes neuronales creadas a partir de la red YOLOv4 mejorada y escalada. Nuestra red neuronal fue entrenada desde cero sin usar pesos previamente entrenados (Imagenet o cualquier otro). Índice de
precisión de las redes neuronales publicadas: paperswithcode.com/sota/object-detection-on-coco : La
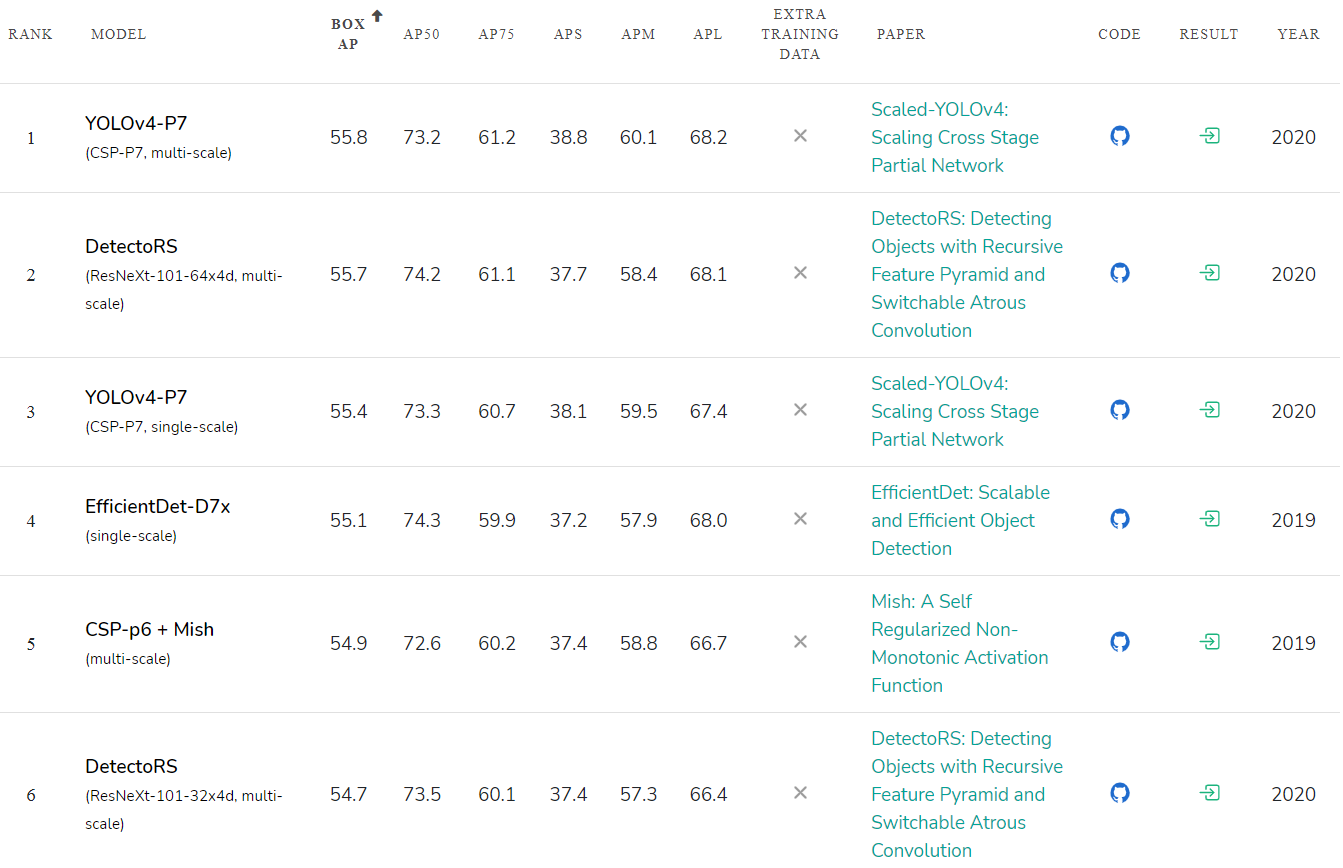
velocidad de la red neuronal YOLOv4-tiny alcanza los 1774 FPS en una GPU RTX 2080Ti para juegos con TensorRT + tkDNN (lote = 4, FP16): github. com / ceccocats / tkDNN
YOLOv4-tiny puede ejecutarse en tiempo real a 39 FPS / 25ms de latencia en JetsonNano (416x416, fp16, batch = 1) tkDNN / TensorRT:

Scaled YOLOv4 usa los recursos de computadoras paralelas como GPU y NPU de manera mucho más eficiente. Por ejemplo, GPU V100 (Volta) tiene rendimiento: 14 TFLops - 112 TFLops-TC images.nvidia.com/content/technologies/volta/pdf/tesla-volta-v100-datasheet-letter-fnl-web.pdf
Si probamos ambos modelos en GPU V100 con batch = 1 , con parámetros --hparams = mixed_precision = true y sin --tensorrt = FP32 , entonces:
- YOLOv4-CSP (640x640) - 47.5% AP - 70 FPS - 120 BFlops (60 FMA)
Basado en BFlops, debería ser 933 FPS = (112,000 / 120), pero en realidad obtenemos 70 FPS, es decir usó 7.5% GPU = (70/933) - EfficientDetD3 (896x896) – 47.5% AP – 36 FPS – 50 BFlops (25 FMA)
BFlops, 2240 FPS = (112 000 / 50), 36 FPS, .. 1.6% GPU = (36 / 2240)
Aquellos. eficiencia de las operaciones informáticas en dispositivos con computación paralela masiva, como las GPU utilizadas en YOLOv4-CSP (7.5 / 1.6) = 4.7 veces mejor que la eficiencia de las operaciones utilizadas en EfficientDetD3.
Por lo general, las redes neuronales se ejecutan en la CPU solo en tareas de investigación para facilitar la depuración, y la característica BFlops es actualmente solo de interés académico. En las tareas del mundo real, la velocidad y la precisión reales son importantes, no el rendimiento en papel. La velocidad real de YOLOv4-P6 es 3.7 veces más rápida que EfficientDetD7 en GPU V100. Por lo tanto, casi siempre se utilizan dispositivos con paralelismo masivo GPU / NPU / TPU / DSP con una velocidad, precio y disipación de calor mucho más óptimos:
- GPU integrada (Jetson Nano / Nx)
- Móvil-GPU / NPU / DSP (Bionic-NPU / Snapdragon-DSP / Mediatek-APU / Kirin-NPU / Exynos-GPU / ...)
- TPU-Edge (Google Coral / Intel Myriad / Mobileye EyeQ5 / Tesla-motors TPU 144 TOPS-8bit)
- GPU en la nube (nVidia A100 / V100 / TitanV)
- NPU en la nube (Google-TPU, Huawei Ascend, Intel Habana, Qualcomm AI 100, ...)
Además, cuando se usan redes neuronales en la Web, generalmente la GPU se usa a través de las bibliotecas WebGL, WebAssembly, WebGPU, para este caso, el tamaño del modelo puede importar: github.com/tensorflow/tfjs#about-this-repo
Uso de dispositivos y algoritmos con débiles El paralelismo es un camino de desarrollo sin salida, porque es imposible reducir el tamaño de la litografía más pequeño que el tamaño de un átomo de silicio para aumentar la frecuencia del procesador:
- El mejor tamaño actual para la fabricación de dispositivos semiconductores es de 5 nanómetros.
- El tamaño de la red cristalina del silicio es de 0,5 nanómetros.
- El radio atómico del silicio es de 0,1 nanómetros.
La solución son computadoras con un paralelismo masivo: en un solo cristal o en varios cristales conectados por un intercalador. Por lo tanto, es extremadamente importante crear redes neuronales que utilicen de manera efectiva máquinas de computación masivamente paralelas, como GPU y NPU.
Mejoras en YOLOv4 escalado sobre YOLOv4:
- YOLOv4 escalado utilizó técnicas de escalado de red óptimas para obtener redes YOLOv4-CSP -> P5 -> P6 -> P7
- Arquitectura de red mejorada: Backbone optimizado y Neck (PAN) utiliza conexiones entre etapas parciales (CSP) y activación Mish
- El promedio móvil exponencial (EMA) se usa durante el entrenamiento; este es un caso especial de SWA: pytorch.org/blog/pytorch-1.6-now-includes-stochastic-weight-averaging
- Para cada resolución de la red, se entrena una red neuronal separada (en YOLOv4, solo se entrenó una red neuronal para todas las resoluciones)
- Normalizadores mejorados en capas [yolo]
- Activaciones cambiadas para Ancho y Alto, lo que permite un entrenamiento de red más rápido
- Utilice el parámetro [net] letter_box = 1 (conserva la relación de aspecto de la imagen de entrada) para redes de alta resolución (para todas excepto yolov4-tiny.cfg)
Arquitectura de red neuronal Scaled-YOLOv4 (ejemplos de tres redes: P5, P6, P7): La

conexión CSP es muy eficiente, simple y se puede aplicar a cualquier red neuronal. La conclusión es que
- la mitad de la señal de salida sigue la ruta principal (generando más información semántica con un gran campo receptivo)
- y la otra mitad de la señal sigue un desvío (manteniendo más información espacial con un pequeño campo receptivo)
El ejemplo más simple de una conexión CSP (a la izquierda es una red regular, a la derecha una red CSP):

Un ejemplo de una conexión CSP en YOLOv4-CSP / P5 / P6 / P7
(a la izquierda es una red regular, a la derecha hay una red CSP):

En YOLOv4-tiny hay 2 conexiones CSP :

YOLOv4 se utiliza en varios campos y tareas:
- Gobierno de Taiwán: control de tráfico www.taiwannews.com.tw/en/news/3957400 y youtu.be/IiU6wFmfVnk
- Amazon: Asistente a distancia Anti-Covid19 github.com/amzn/distance-assistant e instancias Inf1 de Amazon Neurochip / Amazon EC2: aws.amazon.com/ru/blogs/machine-learning/improving-performance-for-deep-learning- detección-de-objetos-basada-con-una-neurona-aws-compilada-yolov4-modelo-en-aws-inferentia
- Laboratorio de innovación de BMW: github.com/BMW-InnovationLab
Y en muchas otras tareas….
Hay implementaciones en varios marcos:
- Pytorch : github.com/WongKinYiu/ScaledYOLOv4
- Darknet : github.com/AlexeyAB/darknet
- TensorFlow : github.com/hunglc007/tensorflow-yolov4-tflite
- o pip instalar yolov4 pypi.org/project/yolov4
- OpenCV: docs.opencv.org/master/da/d9d/tutorial_dnn_yolo.html
- OpenVINO: github.com/TNTWEN/OpenVINO-YOLOV4
- ONNX: developer.nvidia.com/blog/announcing-onnx-runtime-for-jetson
- TensorRT ONNX Scaled-YOLOv4: github.com/linghu8812/tensorrt_inference/tree/master/ScaledYOLOv4
- TensorRT + tkDNN: github.com/ceccocats/tkDNN
- TensorRT + Deepstream: github.com/NVIDIA-AI-IOT/yolov4_deepstream
- Another Pytorch implementations:
- o github.com/WongKinYiu/PyTorch_YOLOv4
- o github.com/Tianxiaomo/pytorch-YOLOv4
- o github.com/VCasecnikovs/Yet-Another-YOLOv4-Pytorch
- La estructura de la red se puede ver usando la utilidad Netron - Visualizador para redes neuronales: github.com/lutzroeder/netron
Cómo compilar y ejecutar Cloud Object Detection de forma gratuita :
- colab: colab.research.google.com/drive/12QusaaRj_lUwCGDvQNfICpa7kA7_a2dE
- video: www.youtube.com/watch?v=mKAEGSxwOAY
Cómo compilar y ejecutar Training in the Cloud de forma gratuita :
- colab: colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp=sharing
- video: youtu.be/mmj3nxGT2YQ
Además, el enfoque YOLOv4 se puede utilizar en otras tareas, por ejemplo, al detectar objetos 3D:
- Código - Complex-YOLOv4 (5-DOF): github.com/maudzung/Complex-YOLOv4-Pytorch
- Código - YOLO3D-YOLOv4 (7-DOF): github.com/maudzung/YOLO3D-YOLOv4-PyTorch
