
Un poco sobre mí: también soy un desarrollador principiante, estoy tomando el curso "Desarrollador Python". Este material no fue compilado como resultado de la teledetección, sino en el orden del autodesarrollo. Mi código puede ser bastante ingenuo y, por lo tanto, no dude en dejar sus comentarios en los comentarios. Si aún no te he asustado, por favor, debajo del corte :)
Analizaremos un ejemplo práctico de normalización de una tabla plana que contiene datos duplicados al estado de 3NF ( tercera forma normal ).
De esta tabla:
Tabla de datos

hagamos tal base de datos:
Diagrama de conexión DB
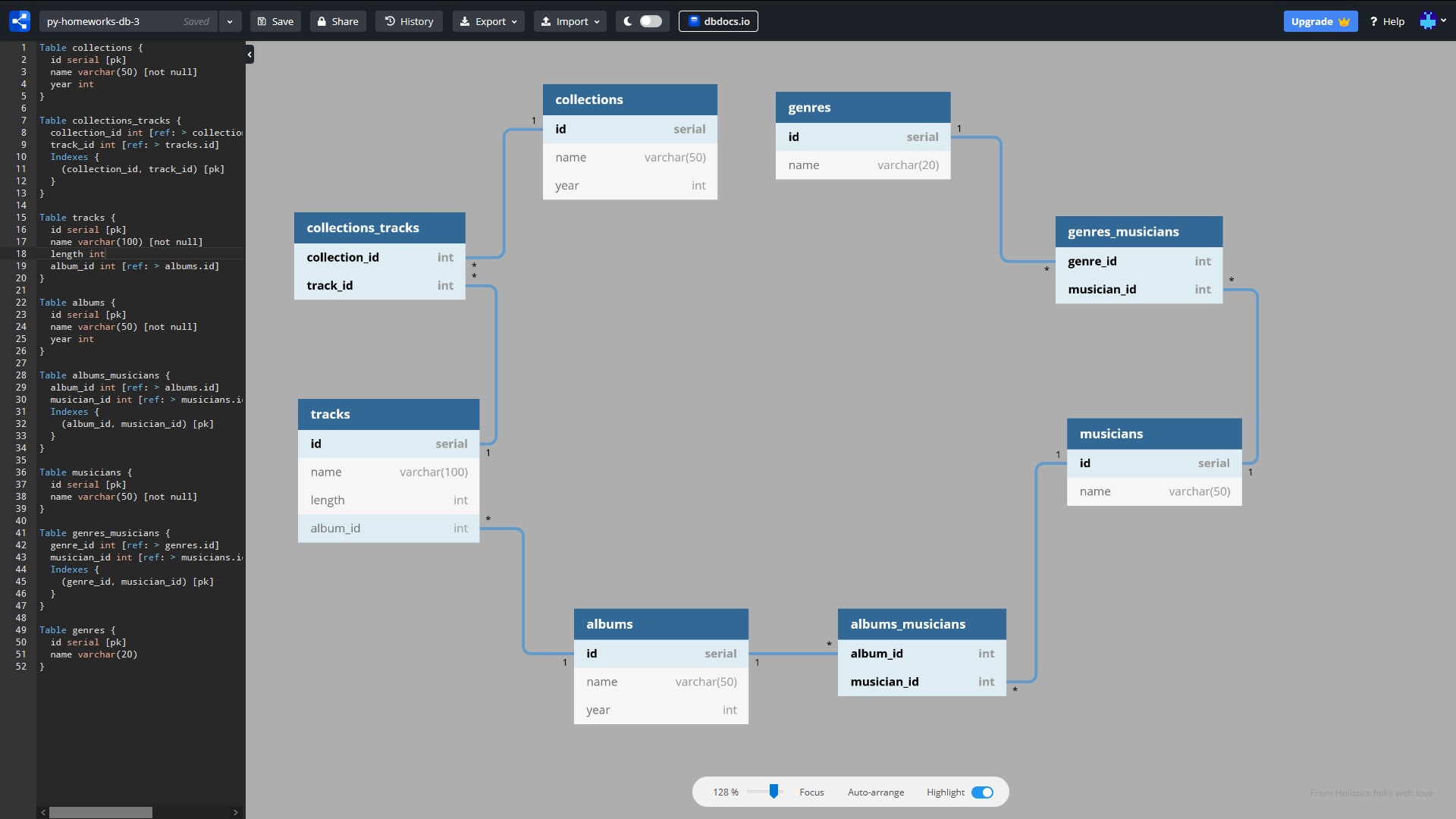
Para los impacientes: el código listo para ejecutarse está en este repositorio . Esquema de base de datos interactivo aquí . Una hoja de trucos para escribir consultas ORM se encuentra al final del artículo.
Acordemos que en el texto del artículo usaremos la palabra "Tabla" en lugar de "Relación", y la palabra "Campo" en lugar de "Atributo". En la asignación, necesitamos colocar una tabla con archivos de música en la base de datos, mientras eliminamos la redundancia de datos. La tabla original (formato CSV) contiene los siguientes campos (pista, género, músico, álbum, duración, album_year, colección, collection_year). Las conexiones entre ellos son las siguientes:
- cada músico puede cantar en varios géneros, así como varios músicos pueden actuar en un género (relación de muchos a muchos)
- uno o varios músicos pueden participar en la creación de un álbum (relación de muchos a muchos)
- una pista pertenece a un solo álbum (relación de uno a muchos)
- las pistas se pueden incluir en varias colecciones (relación de varios a varios)
- la pista puede no estar incluida en ninguna colección.
Para simplificar, digamos que los nombres de géneros, artistas, álbumes y colecciones no se repiten. Los nombres de las pistas se pueden repetir. Hemos diseñado 8 tablas en la base de datos:
- géneros (géneros)
- genres_musicians (mesa de preparación)
- músicos (músicos)
- album_musicians (mesa intermedia)
- álbumes (álbumes)
- pistas
- collections_tracks (tabla de preparación)
- colecciones (colecciones)
* este esquema es de prueba, tomado de una de las DZ, tiene algunos inconvenientes, por ejemplo, no hay conexión entre las pistas y el músico, así como la pista con el género. Pero esto no es esencial para el aprendizaje, y omitiremos esta desventaja.
Para la prueba, creé dos bases de datos en el Postgres local: "TestSQL" y "TestORM", acceso a ellas: prueba de login y contraseña. ¡Por fin escribamos un código!
Crea conexiones y tablas
Crea conexiones a la base de datos
* read_data clear_db .
DSN_SQL = 'postgresql://test:test@localhost:5432/TestSQL'
DSN_ORM = 'postgresql://test:test@localhost:5432/TestORM'
# CSV .
DATA = read_data('data/demo-data.csv')
print('Connecting to DB\'s...')
# , .
engine_orm = sa.create_engine(DSN_ORM)
Session_ORM = sessionmaker(bind=engine_orm)
session_orm = Session_ORM()
engine_sql = sa.create_engine(DSN_SQL)
Session_SQL = sessionmaker(bind=engine_sql)
session_sql = Session_SQL()
print('Clearing the bases...')
# . .
clear_db(sa, engine_sql)
clear_db(sa, engine_orm)
Creamos tablas de la manera clásica usando SQL
* read_query . .
print('\nPreparing data for SQL job...')
print('Creating empty tables...')
session_sql.execute(read_query('queries/create-tables.sql'))
session_sql.commit()
print('\nAdding musicians...')
query = read_query('queries/insert-musicians.sql')
res = session_sql.execute(query.format(','.join({f"('{x['musician']}')" for x in DATA})))
print(f'Inserted {res.rowcount} musicians.')
print('\nAdding genres...')
query = read_query('queries/insert-genres.sql')
res = session_sql.execute(query.format(','.join({f"('{x['genre']}')" for x in DATA})))
print(f'Inserted {res.rowcount} genres.')
print('\nLinking musicians with genres...')
# assume that musician + genre has to be unique
genres_musicians = {x['musician'] + x['genre']: [x['musician'], x['genre']] for x in DATA}
query = read_query('queries/insert-genre-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, value in genres_musicians.items():
res += session_sql.execute(query.format(value[1], value[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding albums...')
# assume that albums has to be unique
albums = {x['album']: x['album_year'] for x in DATA}
query = read_query('queries/insert-albums.sql')
res = session_sql.execute(query.format(','.join({f"('{x}', '{y}')" for x, y in albums.items()})))
print(f'Inserted {res.rowcount} albums.')
print('\nLinking musicians with albums...')
# assume that musicians + album has to be unique
albums_musicians = {x['musician'] + x['album']: [x['musician'], x['album']] for x in DATA}
query = read_query('queries/insert-album-musician.sql')
# this query can't be run in batch, so execute one by one
res = 0
for key, values in albums_musicians.items():
res += session_sql.execute(query.format(values[1], values[0])).rowcount
print(f'Inserted {res} connections.')
print('\nAdding tracks...')
query = read_query('queries/insert-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['track'], item['length'], item['album'])).rowcount
print(f'Inserted {res} tracks.')
print('\nAdding collections...')
query = read_query('queries/insert-collections.sql')
res = session_sql.execute(query.format(','.join({f"('{x['collection']}', {x['collection_year']})" for x in DATA if x['collection'] and x['collection_year']})))
print(f'Inserted {res.rowcount} collections.')
print('\nLinking collections with tracks...')
query = read_query('queries/insert-collection-track.sql')
# this query can't be run in batch, so execute one by one
res = 0
for item in DATA:
res += session_sql.execute(query.format(item['collection'], item['track'])).rowcount
print(f'Inserted {res} connections.')
session_sql.commit()
De hecho, creamos directorios en paquetes (géneros, músicos, álbumes, colecciones) y luego en un bucle vinculamos el resto de los datos y construimos manualmente tablas intermedias. Ejecute el código y compruebe que se ha creado la base de datos. Lo principal es no olvidar llamar a commit () en la sesión.
Ahora estamos tratando de hacer lo mismo, pero usando el enfoque ORM. Para trabajar con ORM, necesitamos describir las clases de datos. Para ello crearemos 8 clases (una para cada mesa).
Lista de clases de bases de datos
.
Base = declarative_base()
class Genre(Base):
__tablename__ = 'genres'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(20), unique=True)
# Musician genres_musicians
musicians = relationship("Musician", secondary='genres_musicians')
class Musician(Base):
__tablename__ = 'musicians'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
# Genre genres_musicians
genres = relationship("Genre", secondary='genres_musicians')
# Album albums_musicians
albums = relationship("Album", secondary='albums_musicians')
class GenreMusician(Base):
__tablename__ = 'genres_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('genre_id', 'musician_id'),)
#
genre_id = sa.Column(sa.Integer, sa.ForeignKey('genres.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Album(Base):
__tablename__ = 'albums'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50), unique=True)
year = sa.Column(sa.Integer)
# Musician albums_musicians
musicians = relationship("Musician", secondary='albums_musicians')
class AlbumMusician(Base):
__tablename__ = 'albums_musicians'
# ,
__table_args__ = (PrimaryKeyConstraint('album_id', 'musician_id'),)
#
album_id = sa.Column(sa.Integer, sa.ForeignKey('albums.id'))
musician_id = sa.Column(sa.Integer, sa.ForeignKey('musicians.id'))
class Track(Base):
__tablename__ = 'tracks'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(100))
length = sa.Column(sa.Integer)
# album_id ,
album_id = sa.Column(sa.Integer, ForeignKey('albums.id'))
# Collection collections_tracks
collections = relationship("Collection", secondary='collections_tracks')
class Collection(Base):
__tablename__ = 'collections'
id = sa.Column(sa.Integer, primary_key=True, autoincrement=True)
name = sa.Column(sa.String(50))
year = sa.Column(sa.Integer)
# Track collections_tracks
tracks = relationship("Track", secondary='collections_tracks')
class CollectionTrack(Base):
__tablename__ = 'collections_tracks'
# ,
__table_args__ = (PrimaryKeyConstraint('collection_id', 'track_id'),)
#
collection_id = sa.Column(sa.Integer, sa.ForeignKey('collections.id'))
track_id = sa.Column(sa.Integer, sa.ForeignKey('tracks.id'))
Solo necesitamos crear una clase base Base para el estilo declarativo de describir tablas y heredar de ella. Toda la magia de las relaciones de mesa radica en el uso correcto de la relación y ForeignKey. El código indica en qué caso creamos qué relación. Lo principal es no olvidar registrar la relación en ambos lados de la relación de muchos a muchos.
La creación directa de tablas utilizando el enfoque ORM se realiza llamando a:
Base.metadata.create_all(engine_orm)
Y aquí es donde entra la magia, literalmente , todas las clases declaradas en el código a través de la herencia de Base se convierten en tablas. Inmediatamente no vi cómo especificar las instancias de qué clases deberían crearse ahora y cuáles deberían posponerse para su creación más adelante (por ejemplo, en otra base de datos). Seguramente existe tal manera, pero en nuestro código todas las clases heredadas de Base se instancian a la vez, ten esto en cuenta.
El llenado de tablas utilizando el enfoque ORM se ve así:
Llenado de tablas con datos a través de ORM
print('\nPreparing data for ORM job...')
for item in DATA:
#
genre = session_orm.query(Genre).filter_by(name=item['genre']).scalar()
if not genre:
genre = Genre(name=item['genre'])
session_orm.add(genre)
#
musician = session_orm.query(Musician).filter_by(name=item['musician']).scalar()
if not musician:
musician = Musician(name=item['musician'])
musician.genres.append(genre)
session_orm.add(musician)
#
album = session_orm.query(Album).filter_by(name=item['album']).scalar()
if not album:
album = Album(name=item['album'], year=item['album_year'])
album.musicians.append(musician)
session_orm.add(album)
#
# ,
#
track = session_orm.query(Track).join(Album).filter(and_(Track.name == item['track'],
Album.name == item['album'])).scalar()
if not track:
track = Track(name=item['track'], length=item['length'])
track.album_id = album.id
session_orm.add(track)
# ,
if item['collection']:
collection = session_orm.query(Collection).filter_by(name=item['collection']).scalar()
if not collection:
collection = Collection(name=item['collection'], year=item['collection_year'])
collection.tracks.append(track)
session_orm.add(collection)
session_orm.commit()
Tienes que completar cada libro de referencia (géneros, músicos, álbumes, colecciones) por pieza. En el caso de las consultas SQL, fue posible generar adiciones de datos por lotes. Pero las tablas intermedias no necesitan ser creadas explícitamente; los mecanismos internos de SQLAlchemy son responsables de esto.
Consultas de base de datos
En la asignación, necesitamos escribir 15 consultas utilizando técnicas tanto SQL como ORM. A continuación se muestra una lista de las preguntas planteadas en orden de dificultad creciente:
- título y año de lanzamiento de los álbumes lanzados en 2018;
- título y duración de la pista más larga;
- el nombre de las pistas, cuya duración es de al menos 3,5 minutos;
- títulos de colecciones publicadas en el período de 2018 a 2020 inclusive;
- artistas intérpretes o ejecutantes cuyo nombre consta de 1 palabra;
- el nombre de las pistas que contienen la palabra "yo".
- el número de intérpretes en cada género;
- el número de pistas incluidas en los álbumes 2019-2020;
- duración media de las pistas de cada álbum;
- todos los artistas que no han lanzado álbumes en 2020;
- títulos de colecciones en las que está presente un artista específico;
- el nombre de los álbumes en los que hay intérpretes de más de 1 género;
- el nombre de las pistas que no están incluidas en las colecciones;
- el artista o artistas que escribieron la pista más corta (en teoría, puede haber varias de estas pistas);
- el nombre de los álbumes que contienen el menor número de pistas.
Como puede ver, las preguntas anteriores implican tanto una simple selección y concatenación de tablas, como el uso de funciones agregadas.
A continuación se proporcionan soluciones para cada una de las 15 consultas en dos opciones (usando SQL y ORM). En el código, las solicitudes vienen en pares para mostrar que los resultados son idénticos en la salida de la consola.
Solicitudes y su breve descripción
print('\n1. All albums from 2018:')
query = read_query('queries/select-album-by-year.sql').format(2018)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).filter_by(year=2018):
print(item.name)
print('\n2. Longest track:')
query = read_query('queries/select-longest-track.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1):
print(f'{item.name}, {item.length}')
print('\n3. Tracks with length not less 3.5min:')
query = read_query('queries/select-tracks-over-length.sql').format(310)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc()):
print(f'{item.name}, {item.length}')
print('\n4. Collections between 2018 and 2020 years (inclusive):')
query = read_query('queries/select-collections-by-year.sql').format(2018, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).filter(2018 <= Collection.year,
Collection.year <= 2020):
print(item.name)
print('\n5. Musicians with name that contains not more 1 word:')
query = read_query('queries/select-musicians-by-name.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Musician).filter(Musician.name.notlike('%% %%')):
print(item.name)
print('\n6. Tracks that contains word "me" in name:')
query = read_query('queries/select-tracks-by-name.sql').format('me')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track).filter(Track.name.like('%%me%%')):
print(item.name)
print('Ok, let\'s start serious work')
print('\n7. How many musicians plays in each genres:')
query = read_query('queries/count-musicians-by-genres.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(
Genre.id):
print(f'{item.name}, {len(item.musicians)}')
print('\n8. How many tracks in all albums 2019-2020:')
query = read_query('queries/count-tracks-in-albums-by-year.sql').format(2019, 2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020):
print(f'{item[0].name}, {item[1].year}')
print('\n9. Average track length in each album:')
query = read_query('queries/count-average-tracks-by-album.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(
Album.id):
print(f'{item[0].name}, {item[1]}')
print('\n10. All musicians that have no albums in 2020:')
query = read_query('queries/select-musicians-by-album-year.sql').format(2020)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
for item in session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(
Musician.name.asc()):
print(f'{item}')
print('\n11. All collections with musician Steve:')
query = read_query('queries/select-collection-by-musician.sql').format('Steve')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(
Musician.name == 'Steve').order_by(Collection.name):
print(f'{item.name}')
print('\n12. Albums with musicians that play in more than 1 genre:')
query = read_query('queries/select-albums-by-genres.sql').format(1)
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
for item in session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(
Genre.name)) > 1).group_by(Album.id).order_by(Album.name):
print(f'{item.name}')
print('\n13. Tracks that not included in any collections:')
query = read_query('queries/select-absence-tracks-in-collections.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
# Important! Despite the warning, following expression does not work: "Collection.id is None"
for item in session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None):
print(f'{item.name}')
print('\n14. Musicians with shortest track length:')
query = read_query('queries/select-musicians-min-track-length.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery = session_orm.query(func.min(Track.length))
for item in session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(
Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name):
print(f'{item[0].name}, {item[1]}')
print('\n15. Albums with minimum number of tracks:')
query = read_query('queries/select-albums-with-minimum-tracks.sql')
print(f'############################\n{query}\n############################')
print('----SQL way---')
res = session_sql.execute(query)
print(*res, sep='\n')
print('----ORM way----')
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
for item in session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name):
print(f'{item.name}')
Para aquellos que no quieran sumergirse en la lectura del código, intentaré mostrar cómo se ven SQL "en bruto" y su alternativa en una expresión ORM, ¡vamos!
Hoja de trucos para hacer coincidir consultas SQL y expresiones ORM
1.título y año de lanzamiento de los álbumes de 2018:
SQL
select name
from albums
where year=2018
ORM
session_orm.query(Album).filter_by(year=2018)
2. título y duración de la pista más larga:
SQL
select name, length
from tracks
order by length DESC
limit 1
ORM
session_orm.query(Track).order_by(Track.length.desc()).slice(0, 1)
3.el nombre de las pistas, cuya duración no sea inferior a 3,5 minutos:
SQL
select name, length
from tracks
where length >= 310
order by length DESC
ORM
session_orm.query(Track).filter(310 <= Track.length).order_by(Track.length.desc())
4.Los nombres de las colecciones publicadas en el período de 2018 a 2020 inclusive:
SQL
select name
from collections
where (year >= 2018) and (year <= 2020)
ORM
session_orm.query(Collection).filter(2018 <= Collection.year, Collection.year <= 2020)
* tenga en cuenta que en lo sucesivo, el filtrado se especifica mediante filter y no mediante filter_by.
5.Ejecutores cuyo nombre consta de 1 palabra:
SQL
select name
from musicians
where not name like '%% %%'
ORM
session_orm.query(Musician).filter(Musician.name.notlike('%% %%'))
6. el nombre de las pistas que contienen la palabra "yo":
SQL
select name
from tracks
where name like '%%me%%'
ORM
session_orm.query(Track).filter(Track.name.like('%%me%%'))
7.número de artistas en cada género:
SQL
select g.name, count(m.name)
from genres as g
left join genres_musicians as gm on g.id = gm.genre_id
left join musicians as m on gm.musician_id = m.id
group by g.name
order by count(m.id) DESC
ORM
session_orm.query(Genre).join(Genre.musicians).order_by(func.count(Musician.id).desc()).group_by(Genre.id)
8.número de pistas incluidas en álbumes 2019-2020:
SQL
select t.name, a.year
from albums as a
left join tracks as t on t.album_id = a.id
where (a.year >= 2019) and (a.year <= 2020)
ORM
session_orm.query(Track, Album).join(Album).filter(2019 <= Album.year, Album.year <= 2020)
9.duración de pista promedio para cada álbum:
SQL
select a.name, AVG(t.length)
from albums as a
left join tracks as t on t.album_id = a.id
group by a.name
order by AVG(t.length)
ORM
session_orm.query(Album, func.avg(Track.length)).join(Track).order_by(func.avg(Track.length)).group_by(Album.id)
10.todos los artistas que no han lanzado álbumes en 2020:
SQL
select distinct m.name
from musicians as m
where m.name not in (
select distinct m.name
from musicians as m
left join albums_musicians as am on m.id = am.musician_id
left join albums as a on a.id = am.album_id
where a.year = 2020
)
order by m.name
ORM
subquery = session_orm.query(distinct(Musician.name)).join(Musician.albums).filter(Album.year == 2020)
session_orm.query(distinct(Musician.name)).filter(~Musician.name.in_(subquery)).order_by(Musician.name.asc())
11. los nombres de las compilaciones en las que está presente un artista específico (Steve):
SQL
select distinct c.name
from collections as c
left join collections_tracks as ct on c.id = ct.collection_id
left join tracks as t on t.id = ct.track_id
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
where m.name like '%%Steve%%'
order by c.name
ORM
session_orm.query(Collection).join(Collection.tracks).join(Album).join(Album.musicians).filter(Musician.name == 'Steve').order_by(Collection.name)
12.el nombre de los álbumes en los que están presentes artistas de más de 1 género:
SQL
select a.name
from albums as a
left join albums_musicians as am on a.id = am.album_id
left join musicians as m on m.id = am.musician_id
left join genres_musicians as gm on m.id = gm.musician_id
left join genres as g on g.id = gm.genre_id
group by a.name
having count(distinct g.name) > 1
order by a.name
ORM
session_orm.query(Album).join(Album.musicians).join(Musician.genres).having(func.count(distinct(Genre.name)) > 1).group_by(Album.id).order_by(Album.name)
13.Nombre de las pistas que no están incluidas en las colecciones:
SQL
select t.name
from tracks as t
left join collections_tracks as ct on t.id = ct.track_id
where ct.track_id is null
ORM
session_orm.query(Track).outerjoin(Track.collections).filter(Collection.id == None)
* tenga en cuenta que a pesar de la advertencia en PyCharm, la condición de filtrado debe estar compuesta de esta manera, si la escribe como sugiere el IDE ("Collection.id is None"), entonces no funcionará.
14. artista (s) que escribieron la pista más corta (en teoría, podría haber varias de estas pistas):
SQL
select m.name, t.length
from tracks as t
left join albums as a on a.id = t.album_id
left join albums_musicians as am on am.album_id = a.id
left join musicians as m on m.id = am.musician_id
group by m.name, t.length
having t.length = (select min(length) from tracks)
order by m.name
ORM
subquery = session_orm.query(func.min(Track.length)) session_orm.query(Musician, Track.length).join(Musician.albums).join(Track).group_by(Musician.id, Track.length).having(Track.length == subquery).order_by(Musician.name)
15.el nombre de los álbumes que contienen el menor número de pistas:
SQL
select distinct a.name
from albums as a
left join tracks as t on t.album_id = a.id
where t.album_id in (
select album_id
from tracks
group by album_id
having count(id) = (
select count(id)
from tracks
group by album_id
order by count
limit 1
)
)
order by a.name
ORM
subquery1 = session_orm.query(func.count(Track.id)).group_by(Track.album_id).order_by(func.count(Track.id)).limit(1)
subquery2 = session_orm.query(Track.album_id).group_by(Track.album_id).having(func.count(Track.id) == subquery1)
session_orm.query(Album).join(Track).filter(Track.album_id.in_(subquery2)).order_by(Album.name)
Como puede ver, las preguntas anteriores implican tanto una selección simple como unir tablas, así como el uso de funciones agregadas y subconsultas. Todo esto se puede hacer con SQLAlchemy tanto en modo SQL como en modo ORM. La variedad de operadores y métodos le permite ejecutar una consulta de cualquier complejidad.
Espero que este material ayude a los principiantes a comenzar a escribir consultas de manera rápida y eficiente.