Entre los marcos que estamos considerando para el procesamiento de datos complejos en Java se encuentra Apache Flink. Nos gustaría ofrecerle una traducción de un buen artículo del blog Analytics Vidhya en el portal Medium para evaluar el interés del lector. ¡No dudes en votar!

En este artículo, analizaremos desde abajo hacia arriba cómo optimizar con Flink; en los servicios en la nube y en otras plataformas, se proporcionan soluciones de transmisión (algunas de las cuales tienen Flink integrado bajo el capó). Si desea comprender este tema desde cero, entonces ha encontrado exactamente lo que estaba buscando.
Nuestra solución monolítica no pudo hacer frente a los crecientes volúmenes de datos entrantes; por lo tanto, necesitaba ser desarrollado. Es hora de pasar a una nueva generación en la evolución de nuestro producto. Se decidió utilizar el procesamiento de transmisión. Este es un nuevo paradigma de absorción de datos que es superior al procesamiento por lotes tradicional.
Apache Flink de un vistazo
Apache Flink es un marco de subprocesamiento distribuido escalable diseñado para operaciones en flujos continuos de datos. Dentro de este marco, se utilizan conceptos como fuentes, transformaciones de flujo, procesamiento paralelo, programación, asignación de recursos. Se admiten una variedad de destinos de datos. Específicamente, Apache Flink puede conectarse a HDFS, Kafka, Amazon Kinesis, RabbitMQ y Cassandra.
Flink es conocido por su alto rendimiento y baja latencia, procesamiento consistente y estrictamente único (todos los datos se procesan una vez, sin duplicación) y alta disponibilidad. Como cualquier otro producto de código abierto exitoso, Flink tiene una gran comunidad que cultiva y expande las capacidades de este marco.
Flink puede manejar flujos de datos (el tamaño del flujo no está definido) o conjuntos de datos (el tamaño del conjunto de datos es específico). Este artículo trata específicamente sobre el procesamiento de subprocesos (manipulación de objetos
DataStream
).
Streaming y sus desafíos inherentes
En la actualidad, con la ubicuidad de los dispositivos de IoT y otros sensores, los datos fluyen continuamente desde múltiples fuentes. Este flujo interminable de datos requiere la computación por lotes tradicional para adaptarse a las nuevas condiciones.
- Transmisión de datos ilimitada; no tienen principio ni fin.
- Los nuevos datos llegan de manera impredecible, a intervalos irregulares.
- Los datos pueden llegar de forma irregular, con diferentes marcas de tiempo.
Con estas características únicas, el procesamiento de datos y las tareas de consulta no son triviales de realizar. Los resultados pueden cambiar rápidamente y es casi imposible sacar conclusiones definitivas; En ocasiones, los cálculos pueden bloquearse al intentar obtener resultados válidos. Además, los resultados no son reproducibles, ya que los datos continúan cambiando durante los cálculos. Finalmente, los retrasos son otro factor que afecta la precisión de los resultados.
Apache Flink le permite hacer frente a estos problemas de procesamiento, ya que se centra en las marcas de tiempo con las que se devuelven los datos entrantes en la fuente. Flink tiene un mecanismo para acumular eventos en función de las marcas de tiempo que se les colocan, y solo después de la acumulación, el sistema procede al procesamiento. En este caso, es posible prescindir del uso de microenvases y, en este caso, aumenta la precisión de los resultados.
Flink implementa un procesamiento consistente, estrictamente de una sola vez, que garantiza la precisión de los cálculos, y el desarrollador no necesita programar nada para esto.
De que están hechos los paquetes Flink
Normalmente, Flink absorbe flujos de datos de diferentes fuentes. El objeto base es
DataStream<T>
un flujo de elementos del mismo tipo. El tipo de elemento en dicha secuencia se determina en el momento de la compilación estableciendo un tipo genérico
T
(puede leer más sobre esto aquí ).
El objeto
DataStream
contiene muchos métodos útiles para transformar, dividir y filtrar datos. Para empezar, será útil tener una idea de lo que están haciendo
map
,
reduce
y
filter
; estos son los principales métodos de transformación:
Map
: obtiene un objetoT
y como resultado devuelve un objeto de tipoR
;MapFunction
estrictamente una vez aplicado a cada elemento del objetoDataStream
.
SingleOutputStreamOperator<R> map(MapFunction<T,R> mapper)
Reduce
: obtiene dos valores consecutivos y devuelve un objeto, combinándolos en un objeto del mismo tipo; este método se aplica a todos los valores del grupo hasta que solo queda uno de ellos.
T reduce(T value1, T value2)
Filter
: obtiene un objetoT
y devuelve un flujo de objetosT
; este método itera sobre todos los elementosDataStream
, pero devuelve solo aquellos para los que la función devuelvetrue
.
SingleOutputStreamOperator<T> filter(FilterFunction<T> filter)
Drenaje de datos
Uno de los principales objetivos de Flink, junto con la transformación de datos, es controlar los flujos y dirigirlos a determinados destinos. Estos lugares se denominan "desagües". Flink tiene cadenas integradas (texto, CSV, socket), así como mecanismos listos para usar para conectarse a otros sistemas, por ejemplo, Apache Kafka .
Etiquetas de eventos de Flink
Al procesar flujos de datos, el factor tiempo es extremadamente importante. Hay tres formas de determinar la marca de tiempo:
- ( ): , ; , . - . , .
, , . , , , ; , .
// Processing Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
- : , , , Flink. , , Flink .
Flink , , , ; « » (watermark). ; Flink.
// Event Time streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);DataStream<String> dataStream = streamEnv.readFile(auditFormat, dataDir, FileProcessingMode.PROCESS_CONTINUOUSLY, 1000). assignTimestampsAndWatermarks( new TimestampExtractor());// ... ... // public class TimestampExtractor implements AssignerWithPeriodicWatermarks<String>{ @Override public Watermark getCurrentWatermark() { return new Watermark(System.currentTimeMillis()-maxTimeFrame); } @Override public long extractTimestamp(String str, long l) { return InputData.getDataObject(str).timestamp; } }
- Tiempo de absorción: este es el momento en el que el evento entra en Flink; asignado cuando el evento está en la fuente y, por lo tanto, esta métrica se considera más estable que el tiempo de procesamiento asignado cuando el proceso comienza a ejecutarse.
El tiempo de absorción no es adecuado para manejar eventos fuera de orden o datos tardíos porque la marca de tiempo es cuando comienza la absorción; en esto se diferencia del tiempo de eventos, que brinda la capacidad de detectar eventos pendientes y procesarlos, apoyándose en el mecanismo de marca de agua.
// Ingestion Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
Puede leer más sobre las marcas de tiempo y cómo afectan la transmisión en el siguiente enlace .
Desglose de ventana
La corriente es, por definición, interminable; por lo tanto, el mecanismo de procesamiento está asociado con la definición de fragmentos (por ejemplo, períodos-ventanas). Por lo tanto, la secuencia se divide en lotes que son convenientes para la agregación y el análisis. Una definición de ventana es una operación en un objeto DataStream o algo más que hereda de él.
Hay varios tipos de ventanas dependientes del tiempo:
Ventana de volteo (configuración predeterminada):
la secuencia se divide en ventanas de tamaño equivalente que no se superponen entre sí. A medida que fluye la corriente, Flink calcula continuamente los datos en función de este guión gráfico de tiempo fijo. Implementación de

ventana
giratoria en código:
// ,
public AllWindowedStream<T,TimeWindow> timeWindowAll(Time size)
// ,
public WindowedStream<T,KEY,TimeWindow> timeWindow(Time size)
Ventana deslizante
Estas ventanas pueden superponerse entre sí, y las propiedades de la ventana deslizante están determinadas por el tamaño de esta ventana y el margen (cuándo comenzar la siguiente ventana). En este caso, los eventos relacionados con más de una ventana se pueden procesar en un momento determinado.

Ventana deslizante
Y así es como se ve en el código:
// 1 30
dataStreamObject.timeWindow(Time.minutes(1), Time.seconds(30))
Ventana de sesión
Incluye todos los eventos dentro de una sesión. La sesión finaliza si no hay actividad o si no se registran eventos después de un período de tiempo determinado. Este período puede ser fijo o dinámico, dependiendo de los eventos que se procesen. En teoría, si el intervalo entre sesiones es menor que el tamaño de la ventana, es posible que la sesión nunca termine.
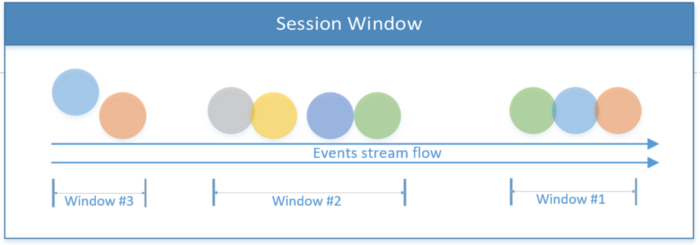
Ventana de sesión
El primer fragmento de código a continuación muestra una sesión con un valor de tiempo fijo (2 segundos). El segundo ejemplo implementa una ventana de sesión dinámica basada en eventos de hilo.
// 2
dataStreamObject.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)))
// ,
dataStreamObject.window(EventTimeSessionWindows.withDynamicGap((elem) -> {
// ,
}))
Ventana global
Todo el sistema se trata como una sola ventana.

La ventana global de
Flink también le permite implementar sus propias ventanas, cuya lógica es definida por el usuario.
Además de las ventanas dependientes del tiempo, existen otras, por ejemplo, la ventana Cuenta, donde se establece el límite para el número de eventos entrantes; cuando se alcanza el umbral X, Flink procesa X eventos.

Ventana de conteo para tres eventos
Después de una introducción teórica, analicemos con más detalle qué es un flujo de datos desde un punto de vista práctico. Para obtener más información sobre Apache Flink y subprocesos, consulte el sitio web oficial .
Descripción de la transmisión
Como resumen de la parte teórica, el siguiente diagrama de bloques muestra los principales flujos de datos implementados en los fragmentos de código de este artículo. La secuencia a continuación comienza desde la fuente (los archivos se escriben en el directorio) y continúa mientras procesa eventos que se convierten en objetos.
La implementación que se muestra a continuación tiene dos rutas de procesamiento. El que se muestra en la parte superior divide una corriente en dos corrientes laterales y luego las combina, obteniendo una corriente del tercer tipo. La secuencia de comandos que se muestra en la parte inferior del diagrama describe el procesamiento del flujo, después de lo cual los resultados del trabajo se transfieren al sumidero.

A continuación, intentaremos sentir con nuestras manos la implementación práctica de la teoría anterior; Todo el código fuente que se analiza a continuación se publica en GitHub .
Procesamiento de flujo básico (ejemplo n. ° 1)
Será más fácil comprender los conceptos de Flink si comienza con la aplicación más simple. En esta aplicación, el productor escribe archivos en un directorio, simulando así el flujo de información. Flink lee archivos de este directorio y escribe información resumida sobre ellos en el directorio de destino; esta es la acción.
A continuación, echemos un vistazo de cerca a lo que sucede durante el procesamiento:
Conversión de datos sin procesar en un objeto:
// InputData;
DataStream<InputData> inputDataObjectStream
= dataStream
.map((MapFunction<String, InputData>) inputStr -> {
System.out.println("--- Received Record : " + inputStr);
return InputData.getDataObject(inputStr);
});
El siguiente fragmento de código
InputData
convierte un objeto de flujo ( ) en una cadena y una tupla de enteros. Extrae solo ciertos campos del flujo de objetos, agrupándolos por un campo en cuantos de dos segundos.
//
DataStream<Tuple2<String, Integer>> userCounts
= inputDataObjectStream
.map(new MapFunction<InputData,Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(InputData item) {
return new Tuple2<String,Integer>(item.getName() ,item.getScore() );
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0) // KeyedStream<T, Tuple> ( 'name')
//.timeWindowAll(Time.seconds(windowInterval)) // timeWindowAll
.timeWindow(Time.seconds(2)) // WindowedStream<T, KEY, TimeWindow>
.reduce((x,y) -> new Tuple2<String,Integer>( x.f0+"-"+y.f0, x.f1+y.f1));
Crear un destino para una transmisión (implementar un receptor de datos):
//
DataStream<Tuple2<String,Integer>> inputCountSummary
= inputDataObjectStream
.map( item
-> new Tuple2<String,Integer>
(String.valueOf(System.currentTimeMillis()),1))
// (1)
.returns(Types.TUPLE(Types.STRING ,Types.INT))
.timeWindowAll(Time.seconds(windowInterval)) //
.reduce((x,y) -> // ,
(new Tuple2<String, Integer>(x.f0, x.f1 + y.f1)));
//
final StreamingFileSink<Tuple2<String,Integer>> countSink
= StreamingFileSink
.forRowFormat(new Path(outputDir),
new SimpleStringEncoder<Tuple2<String,Integer>>
("UTF-8"))
.build();
// DataStream; inputCountSummary countSink
inputCountSummary.addSink(countSink);
Código de muestra para crear un receptor de datos.
División de corrientes (ejemplo 2)
Este ejemplo demuestra cómo dividir el flujo principal usando flujos de salida laterales. Flink proporciona múltiples transmisiones laterales de la transmisión principal
DataStream
. El tipo de datos ubicados en cada lado del flujo puede ser diferente del tipo de datos del flujo principal, así como del tipo de datos de cada uno de los flujos secundarios.
Entonces, usando un flujo de salida lateral, puede matar dos pájaros de un tiro: divida el flujo y convierta el tipo de datos del flujo en muchos tipos de datos (pueden ser únicos para cada flujo de salida lateral).
El siguiente fragmento de código se denomina
ProcessFunction
dividir la secuencia en dos laterales, según la propiedad de entrada. Para obtener el mismo resultado, tendríamos que usar la función repetidamente
filter
.
Función
ProcessFunction
recopila ciertos objetos (según un criterio) y los envía al encabezado de salida principal (se encuentra en
SingleOutputStreamOperator
), y el resto de los eventos se transmiten a las salidas laterales. La transmisión se
DataStream
divide verticalmente y publica diferentes formatos para cada transmisión secundaria.
Tenga en cuenta que la definición de una salida de flujo lateral se basa en una etiqueta de salida (objeto
OutputTag
) única .
//
final OutputTag<Tuple2<String,String>> playerTag
= new OutputTag<Tuple2<String,String>>("player"){};
//
final OutputTag<Tuple2<String,Integer>> singerTag
= new OutputTag<Tuple2<String,Integer>>("singer"){};
// InputData .
SingleOutputStreamOperator<InputData> inputDataMain
= inputStream
.process(new ProcessFunction<String, InputData>() {
@Override
public void processElement(
String inputStr,
Context ctx,
Collector<InputData> collInputData) {
Utils.print(Utils.COLOR_CYAN, "Received record : " + inputStr);
// InputData
InputData inputData = InputData.getDataObject(inputStr);
switch (inputData.getType())
{
case "Singer":
//
ctx.output(singerTag,
new Tuple2<String,Integer>
(inputData.getName(), inputData.getScore()));
break;
case "Player":
// ;
// playerTag, (" ")
ctx.output(playerTag,
new Tuple2<String, String>
(inputData.getName(), inputData.getType()));
break;
default:
// InputData
collInputData.collect(inputData);
break;
}
}
});
Código de muestra que demuestra cómo dividir una transmisión
Combinar corrientes (ejemplo n. ° 3)
La última operación que se tratará en este artículo es la concatenación de subprocesos. La idea es combinar dos flujos diferentes, cuyos formatos de datos pueden diferir, de los cuales recopilar un flujo con una estructura de datos unificada. A diferencia de la operación de combinación de SQL, donde los datos se combinan horizontalmente, los flujos se combinan verticalmente, ya que el flujo de eventos continúa y no está limitado en el tiempo.
La concatenación de flujos se realiza llamando al método de conexión y luego definiendo una operación de visualización para cada elemento en cada flujo individual. El resultado es una secuencia fusionada.
//
ConnectedStreams<Tuple2<String, Integer>, Tuple2<String, String>> mergedStream
= singerStream
.connect(playerStream);
DataStream<Tuple4<String, String, String, Integer>> combinedStream
= mergedStream.map(new CoMapFunction<
Tuple2<String, Integer>, // 1
Tuple2<String, String>, // 2
Tuple4<String, String, String, Integer> //
>() {
@Override
public Tuple4<String, String, String, Integer> // 1
map1(Tuple2<String, Integer> singer) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: singer stream", singer.f0, "", singer.f1);
}
@Override
public Tuple4<String, String, String, Integer>
// 2
map2(Tuple2<String, String> player) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: player stream", player.f0, player.f1, 0);
}
});
Listado que muestra cómo obtener una transmisión combinada
Creando un proyecto de trabajo
Entonces, para recapitular: el proyecto de demostración se carga en GitHub. Describe cómo construirlo y compilarlo. Este es un buen punto de partida para practicar con Flink.
conclusiones
Este artículo describe las operaciones básicas para crear una aplicación de subprocesamiento basada en Flink que funcione. El propósito de la aplicación es proporcionar una descripción general de las llamadas críticas inherentes a la transmisión y sentar las bases para la construcción posterior de una aplicación Flink completamente funcional.
Debido a que la transmisión tiene muchas facetas y muchas complejidades, muchos de los problemas de este artículo siguen sin resolverse; en particular, la ejecución de Flink y la gestión de tareas, la marca de agua al establecer el tiempo para la transmisión de eventos, la inyección de estado en los eventos de transmisión, la ejecución de iteraciones de transmisión, la ejecución de consultas similares a SQL en las transmisiones y mucho más.
Esperamos que este artículo haya sido suficiente para que quieras probar Flink.