Continuamos con el tema de la seguridad de la información y publicamos la traducción del artículo de Coussement Bruno.
¿Agregar ruido a los datos existentes, agregar ruido solo a los resultados de la manipulación de datos o generar datos sintéticos? ¿Confiemos en nuestra intuición?

Las empresas están creciendo y sus regulaciones de ciberseguridad se están volviendo más estrictas, los arquitectos senior están adoptando las tendencias ... Todo esto lleva al hecho de que la necesidad (u obligación) de reducir los riesgos asociados con la privacidad y la fuga de información solo se intensifica para los interesados.
En este caso, los métodos de anonimización o tokenización de datos se utilizan ampliamente, aunque también permiten la posibilidad de revelar información privada (consulte este artículo para comprender por qué sucede esto).
Generando datos sintéticos
Los datos sintéticos tienen una diferencia fundamental. El objetivo es crear un generador de datos que muestre las mismas estadísticas globales que los datos originales. Distinguir el original del resultado debería ser difícil para un modelo o una persona.
Ilustremos lo anterior generando datos sintéticos en el conjunto de datos Covertype utilizando el modelo TGAN .

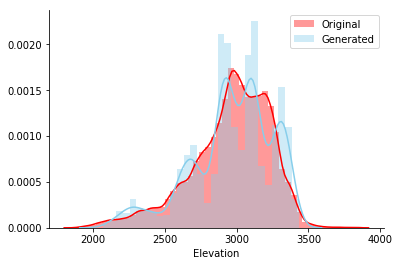
Después de entrenar el modelo en esta tabla, generé 5000 filas y tracé un histograma de la columna Elevación del conjunto original y generado. Parece que ambas líneas coinciden visualmente.
Para probar la relación entre pares de barras, se muestra un gráfico emparejado de todas las barras continuas. La forma que forman los puntos azul-verdes (generados) debe coincidir visualmente con la forma de los puntos rojos (original). Y así sucedió, ¡genial!

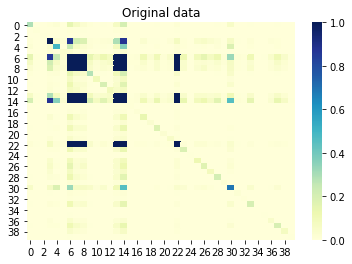
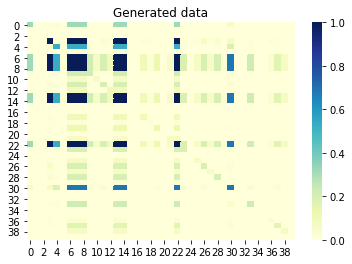
Si ahora miramos la información mutua (también conocida como correlación sin signo) entre columnas, entonces las columnas que están correlacionadas entre sí también deberían estar correlacionadas en el conjunto generado. Por el contrario, las columnas no correlacionadas del conjunto original no deben correlacionarse en el conjunto generado. Un valor cercano a 0 significa que no hay correlación y un valor cercano a 1 significa una correlación perfecta. ¡Genial, lo es!
Información mutua entre columnas del conjunto original:
Información mutua entre columnas conjunto generado:
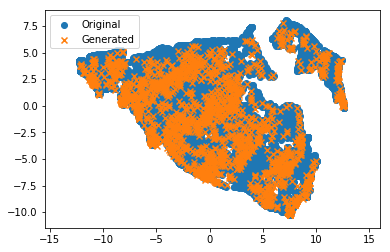
como prueba final, quería entrenar el método de reducción de dimensionalidad no lineal ( UMAP ) en el conjunto original y proyectar los puntos de origen en el espacio 2D. Entro el conjunto generado en el mismo proyector. Las cruces naranjas (generadas) deben estar en las nubes de puntos azules del conjunto de datos original. ¡Y ahí está! ¡Excelente!
Bien, ¡experimentar con datos es divertido!
Para casos más graves, hay 2 enfoques principales:
- : , . , . .
Vale la pena prestar atención a iniciativas como la bóveda de datos sintéticos , Gretel.AI , Mostly.ai , MDClone , Hazy .
Hoy, puede escribir una prueba de concepto utilizando datos sintéticos para resolver uno de los siguientes problemas comunes que enfrentan las organizaciones de TI:
- Sin carga útil en el entorno de desarrollo
Supongamos que está trabajando en un producto de datos (podría ser cualquier cosa) donde los datos que le interesan se encuentran en un entorno de producción con una política de acceso muy estricta. Desafortunadamente, solo tiene acceso al entorno de desarrollo sin datos interesantes.
- Modo Dios: derechos de acceso para ingenieros y científicos de datos
Digamos que es un científico de datos y, de repente, un oficial de seguridad de la información ha limitado sus tan necesarios privilegios para acceder a los datos de producción. ¿Cómo puede seguir funcionando bien en entornos tan difíciles y limitados?
- Transferencia de datos sensibles a un socio externo que no es de confianza
Usted es parte de la Compañía X. La organización Y le gustaría mostrar su último producto de datos interesante (podría ser cualquier cosa).
Te piden que extraigas datos para mostrarte el producto.
¿Qué tienen que ver los datos sintéticos con la privacidad diferencial?
La propiedad principal de la generación de datos sintéticos es que, independientemente del posprocesamiento o la adición de información de terceros, nadie podrá saber si un objeto está contenido en el conjunto original y tampoco podrá obtener las propiedades de este objeto. Esta propiedad es parte de un concepto más amplio llamado "privacidad diferencial" (DP).
Privacidad diferencial global y local
DP se divide en 2 tipos.
A menudo, solo el resultado de una tarea específica es de interés (por ejemplo, entrenar un modelo basado en datos no divulgados de pacientes de diferentes hospitales, calcular el número promedio de personas que alguna vez han cometido un delito, etc.), luego se debe prestar atención a la privacidad diferencial global.
En este caso, un usuario que no sea de confianza nunca verá datos confidenciales. En cambio, le dice a un curador de confianza (con mecanismos de privacidad diferencial global) que tiene acceso a datos confidenciales qué operaciones realizar.
Solo el resultado se informa al usuario que no es de confianza. Recomiendo Pysyfty OpenDP si necesita más información sobre herramientas similares.
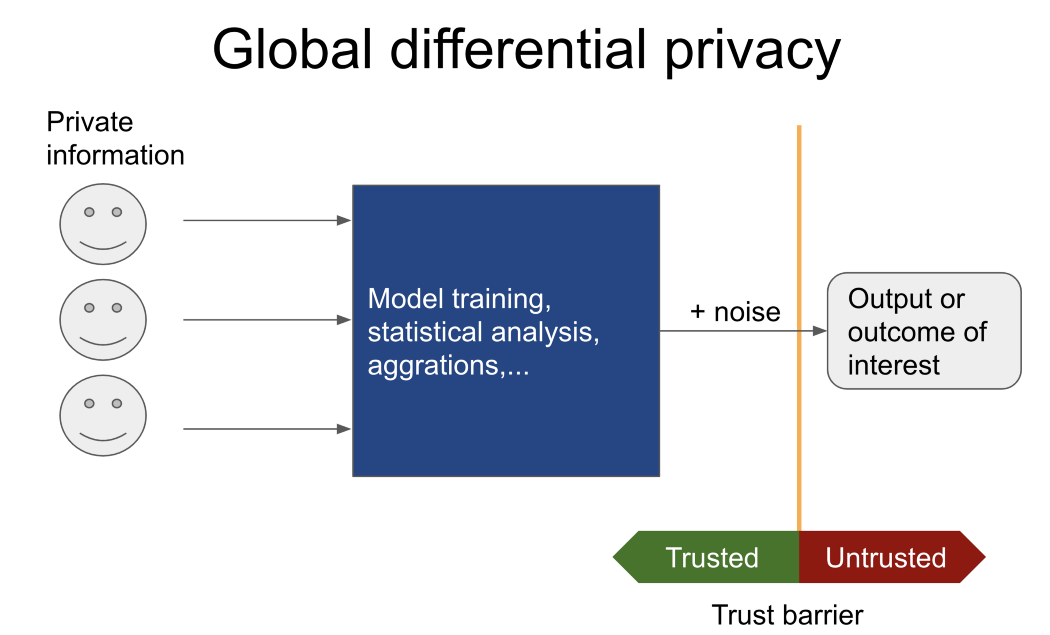
Por el contrario, si los datos se van a transferir a una parte que no es de confianza, entran en juego los principios de confidencialidad diferencial local. Tradicionalmente, esto se logra agregando ruido a cada fila de una tabla o base de datos. La cantidad de ruido agregado depende de:
- el nivel requerido de confidencialidad (el famoso épsilon en la literatura del PD),
- el tamaño del conjunto de datos (un conjunto de datos más grande requiere menos ruido para lograr el mismo nivel de confidencialidad),
- tipo de datos de columna (cuantitativo, categórico, ordinal).

En teoría, para un nivel igual de confidencialidad, el mecanismo de DP global (que agrega ruido al resultado) proporcionará resultados más precisos que el mecanismo local (ruido de nivel de línea).
Por tanto, los métodos de generación de datos sintéticos se pueden considerar como una forma de DP local.
Para obtener más información sobre estos temas, le aconsejo que consulte las siguientes fuentes:
- www.udacity.com/course/secure-and-private-ai--ud185
- medium.com/@arbidha1412/local-and-global-differential-privacy-249aaa3571
- www.openmined.org
Recomendación
Veamos ahora un ejemplo más específico. Desea compartir una hoja de cálculo que contiene información personal con una parte que no es de confianza.
En este momento, puede agregar ruido a las líneas de datos existentes (DP local), configurar y utilizar un sistema robusto (DP global) o generar datos sintéticos basados en el original.
Se debe agregar ruido a las líneas de datos existentes si
- no sabe qué operación se realizará con los datos después de la publicación,
- necesita compartir periódicamente una actualización de los datos originales (= tener este flujo de trabajo como parte de un proceso por lotes estable),
- usted y los propietarios de los datos confían en la persona / equipo / organización para agregar ruido a los datos originales.
Aquí recomiendo comenzar con las herramientas OpenDP .
El caso más famoso de privacidad diferencial se encuentra en los datos del censo de Estados Unidos (consulte databricks.com/session_na20/using-apache-spark-and-differential-privacy-for-protecting-the-privacy-of-the-2020-census-respondents ).
Estos datos se recalculan y actualizan cada tres años. Se trata principalmente de datos numéricos que se agregan y publican en múltiples niveles (condado, estado, nivel nacional).
Instale y use un sistema confiable si
- el sistema que especificó admite tareas y operaciones que se realizarán en él,
- los datos básicos se almacenan en diferentes lugares y no pueden dejarlos (por ejemplo, en diferentes hospitales),
- usted y los propietarios de los datos realmente confían en el sistema actual y en la persona / equipo / organización que lo está configurando.
Como usuario de datos confidenciales, obtendrá resultados más precisos que con el primer enfoque.
Actualmente, muchos frameworks no tienen todas las características necesarias para implementar esta bestia de una manera segura, escalable y auditable. Aquí todavía se requiere mucho trabajo de ingeniería.
Pero a medida que crece su adopción, DP puede ser una buena alternativa para grandes organizaciones y empresas. Recomiendo
comenzar aquí con OpenMined .
Es posible generar datos sintéticos si
- (<1 , <100 ),
- ad-hoc ( ),
- / / , .
Al igual que con el pequeño experimento descrito anteriormente, los resultados son prometedores. Tampoco requiere un conocimiento excelente de los sistemas de DP. Puede comenzar hoy, si es necesario, dejar que entrene durante la noche y, por así decirlo, preparar el conjunto sintético compartido para mañana por la mañana.
El mayor inconveniente es que estos modelos complejos pueden resultar costosos de entrenar y mantener si aumenta la cantidad de datos. Cada mesa también requiere su propio entrenamiento completo del modelo (el entrenamiento portátil no funcionará aquí). No podrá escalar a cientos de tablas, incluso con un presupuesto computacional significativo.
De lo contrario, no tendrás suerte.
Conclusión
Dado que la privacidad de los datos es más importante ahora que nunca, contamos con métodos excelentes para generar datos sintéticos o para agregar ruido a los datos existentes. Sin embargo, todos todavía tienen sus limitaciones. Aparte de algunos casos específicos, aún no se ha creado una herramienta escalable y flexible de nivel empresarial que permita la transferencia de datos que contienen información personal a partes no confiables.
Los propietarios de datos todavía necesitan confiar en métodos o sistemas establecidos, lo que requiere mucha confianza de ellos. ¡Este es el mayor problema!
Mientras tanto, si desea probarlo (prueba de concepto, simplemente pruébelo), abra cualquiera de los enlaces anteriores.