Melodía obsesiva (gusanos ingleses): un fenómeno conocido y, a veces, irritante. Una vez que uno de estos se atasca en la cabeza, puede ser difícil deshacerse de él. Las investigaciones han demostrado que la llamada interacción con la composición original , ya sea escuchándola o cantándola, ayuda a alejar la melodía intrusiva. Pero, ¿qué pasa si no puedes recordar el nombre de la canción, pero solo puedes tararear la melodía?
Cuando se utilizan los métodos existentes para comparar una melodía cantada con su grabación de estudio polifónica original, surgen una serie de dificultades. El sonido de una grabación en vivo o de estudio con letra, coros e instrumentos puede ser muy diferente de lo que tararea una persona. Además, por error o por diseño, es posible que nuestra versión no tenga exactamente el mismo tono, tono, tempo o ritmo. Esta es la razón por la que tantos enfoques actuales de la consulta mediante el sistema de tarareo asignan una melodía cantada a una base de datos de melodías preexistentes u otras versiones cantadas de esa canción, en lugar de identificarla directamente. Sin embargo, este tipo de enfoque a menudo se basa en una base de datos limitada que requiere una actualización manual.
Hum to Search , lanzado en octubre, es un nuevo sistema de búsqueda de Google de aprendizaje automático que permite a una persona encontrar una canción cantándola o enjuagándola. A diferencia de los métodos existentes, este enfoque crea una incrustación desde el espectrograma de la canción, sin pasar por la representación intermedia. Esto permite que el modelo compare nuestra melodía directamente con la grabación original (polifónica) sin tener que tener una melodía diferente o una versión MIDI de cada pista. Tampoco es necesario utilizar una lógica compleja hecha a mano para extraer la melodía. Este enfoque simplifica en gran medida la base de datos para Hum to Search, lo que le permite agregar constantemente incrustaciones de pistas originales de todo el mundo, incluso las versiones más recientes.
Cómo funciona
Muchos sistemas de reconocimiento de música existentes convierten la muestra de audio en un espectrograma para encontrar una coincidencia más correcta antes de procesar la muestra de audio. Sin embargo, hay un problema al reconocer una melodía cantada: a menudo contiene relativamente poca información, como en este ejemplo de la canción "Bella Ciao" . La diferencia entre la versión cantada y el mismo segmento de la grabación de estudio correspondiente se puede visualizar utilizando los espectrogramas que se muestran a continuación:

Visualización del fragmento cantado y su grabación de estudio
Dada la imagen de la izquierda, el modelo debe encontrar el audio que coincida con la imagen de la derecha en una colección de más de 50 millones de imágenes similares (correspondientes a segmentos de grabaciones de estudio de otras canciones). Para ello, el modelo debe aprender a centrarse en la melodía dominante e ignorar los coros, los instrumentos y el timbre de la voz, así como las diferencias debidas al ruido de fondo o la reverberación. Para determinar a simple vista la melodía dominante que podría usarse para comparar los dos espectrogramas, puede buscar similitudes en las líneas en la parte inferior de las imágenes de arriba.
Los intentos anteriores de implementar el reconocimiento de música, particularmente la música en cafés o clubes, han demostrado cómo se puede aplicar el aprendizaje automático a este problema. Now Playing , lanzado en 2017 para teléfonos Pixel, utiliza una red neuronal profunda incorporada para reconocer canciones sin la necesidad de una conexión de servidor, mientras que Sound Search , que más tarde desarrolló la tecnología, utiliza el reconocimiento basado en servidor para buscar de forma rápida y precisa más de 100 millones de canciones. También necesitábamos aplicar lo que aprendimos en estos lanzamientos para reconocer música de una biblioteca igualmente grande, pero ya de los pasajes cantados.
Configurar el aprendizaje automático
El primer paso en la evolución de Hum to Search fue cambiar los modelos de reconocimiento de música utilizados en Now Playing y Sound Search para que funcionaran con grabaciones de melodías. Básicamente, muchos motores de búsqueda similares (como el reconocimiento de imágenes) funcionan de manera similar. En el proceso de entrenamiento, la red neuronal recibe un par (una melodía y una grabación original) como entrada y crea sus incrustaciones, que luego se utilizarán para hacer coincidir la melodía cantada.

Configuración del entrenamiento de redes neuronales
Para asegurar el reconocimiento de lo que estamos cantando, las inserciones de pares de audio con la misma melodía deben ubicarse una al lado de la otra, incluso si tienen diferentes acompañamientos instrumentales y voces de canto. Los pares de audio que contienen diferentes melodías deben estar muy separados. En el proceso de entrenamiento, la red recibe dichos pares de audio hasta que aprende cómo crear incrustaciones con esta propiedad.
En última instancia, el modelo entrenado podrá generar incrustaciones para nuestras melodías, similares a las incrustaciones de grabaciones maestras de canciones. En este caso, encontrar la canción correcta es solo cuestión de buscar en la base de datos incrustaciones similares calculadas sobre la base de grabaciones de audio de música popular.
Datos de entrenamiento
Dado que el entrenamiento del modelo requería pares de canciones (grabadas y cantadas), el primer desafío fue obtener suficientes datos. Nuestro conjunto de datos original consistía principalmente en fragmentos cantados (muy pocos de ellos contenían solo un zumbido de un motivo sin palabras). Para hacer el modelo más confiable, durante el entrenamiento, aplicamos aumento a estos fragmentos: cambiamos el tono y el tempo en un orden aleatorio. El modelo resultante funcionó lo suficientemente bien para ejemplos en los que la canción se cantaba en lugar de tararear o silbar.
Para mejorar el rendimiento del modelo en melodías sin palabras, generamos datos de entrenamiento adicionales con "zumbidos" artificiales a partir del conjunto existente de datos de audio. Para esto usamos SPICE, un modelo de extracción de tono desarrollado por nuestro equipo ampliado como parte del proyecto FreddieMeter . SPICE extrae los valores de tono de un audio dado, que luego usamos para generar una melodía que consta de tonos de audio discretos. La primera versión de este sistema ha transformado el pasaje original aquí en esto .
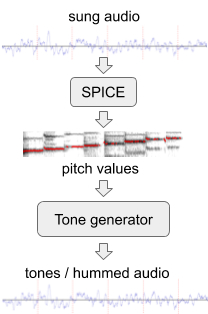
Generación de "zumbido" a partir de un fragmento de audio cantado.
Posteriormente mejoramos el enfoque reemplazando un generador de tonos simple con una red neuronal que genera un sonido que se asemeja al zumbido real de un motivo sin palabras. Por ejemplo, el fragmento anterior se puede transformar en un "zumbido" o un silbido .
En el último paso, comparamos los datos de entrenamiento mezclando y haciendo coincidir fragmentos de audio. Cuando, por ejemplo, nos encontramos con fragmentos similares de dos artistas diferentes, los alineamos con nuestros modelos preliminares y, por lo tanto, proporcionamos al modelo un par adicional de fragmentos de audio de la misma melodía.
Mejorando el modelo
Al entrenar el modelo Hum to Search, comenzamos con la pérdida de tripletes , que ha demostrado ser excelente en una variedad de tareas de clasificación, como clasificar imágenes y música grabada . Si se proporciona un par de audio que coincide con la misma melodía (los puntos R y P en el espacio de incrustación que se muestra a continuación), la función de pérdida de triplete ignora ciertas partes de los datos de entrenamiento obtenidos de la otra melodía. Esto ayuda a mejorar el comportamiento de aprendizaje cuando el modelo encuentra otra melodía que es demasiado simple y ya está lejos de R y P (ver punto E). Y también cuando es demasiado complejo para la etapa actual de entrenamiento del modelo y resulta estar demasiado cerca de R (ver punto H).

Ejemplos de segmentos de audio representados como puntos en el espacio
Hemos descubierto que podemos mejorar la precisión del modelo teniendo en cuenta datos de entrenamiento adicionales (puntos H y E), es decir, formulando el concepto general de confianza del modelo en una serie de ejemplos: ¿qué tan seguro es el modelo de que todos los datos, ¿Con quién trabajó se puede clasificar correctamente? ¿O se encontró con ejemplos que no corresponden a su comprensión actual? En base a esto, hemos agregado una función de pérdida que acerca la confianza del modelo al 100% en todas las áreas del espacio de incrustación, lo que resulta en una mejor calidad de memoria y precisión para nuestro modelo .
Los cambios antes mencionados, específicamente la combinación de datos de aumento y entrenamiento, permitieron que el modelo de red neuronal utilizado en la búsqueda de Google reconociera las melodías cantadas. El sistema actual alcanza un alto nivel de precisión basado en una base de datos de más de medio millón de canciones que actualizamos constantemente. Esta colección de pistas tiene espacio para crecer, con más música de todo el mundo por venir.
Para probar esta función, abra la última versión de la aplicación de Google, haga clic en el icono del micrófono y diga "¿Qué es esta canción?" O haga clic en "Buscar una canción". ¡Ahora puedes tararear o silbar una melodía! Esperamos que Hum to Search te ayude a deshacerte de las melodías obsesivas o simplemente a encontrar y escuchar una pista sin ingresar su nombre.