Tomografía computarizada con áreas de vidrio esmerilado
Los pacientes con COVID-19 confirmado se someten a una tomografía computarizada de los pulmones. Si tiene suerte, una vez, si no, varias veces. Por primera vez, debe estimar el nivel de daño como porcentaje. Dependiendo del cuartil del grado de daño, se determina el régimen de tratamiento adicional, y son sorprendentemente diferentes. En abril de 2020, nos enteramos de que hay dos dificultades:
- CT es una imagen tridimensional, cada capa de dicha imagen se llama corte. Con 300-800 cortes de pulmón en CT, los médicos pasan de 1 a 15 minutos buscando zonas características para determinar la extensión de la lesión. Un minuto es "a ojo", 30 minutos es el promedio para la selección manual y el recuento de áreas de tejido dañado. En casos difíciles, el resultado se puede procesar hasta una hora.
- La precisión del diagnóstico "visual" del nivel de infección por coronavirus por parte de expertos es alta en los límites del 0-30% y del 70-100%. En el rango de 30 a 70, el error es muy alto y notamos que algunos de los radiólogos, por regla general, sobrestiman sistemáticamente el porcentaje de lesiones por ojo, mientras que otros lo subestiman.
La tarea se reduce a determinar el tejido dañado de los pulmones y calcular la proporción de su volumen al total de pulmones.
A finales de abril, en cooperación con las clínicas, preparamos un conjunto de datos de estudios anónimos de pacientes con análisis de PCR confirmado de COVID-19, proporcionamos un comité de diez excelentes radiólogos expertos y mapeamos una muestra para la formación con un profesor.
Hubo beta a finales de mayo. En julio, hubo un modelo listo para usar para varios tipos de equipos de TC utilizados en Rusia. Somos un equipo del Laboratorio de Inteligencia Artificial de Sberbank. En general, publicamos nuestros desarrollos en la literatura científica (MICCAI, AIME, BIOSIGNALS), y hablaremos de esto incluso en AI Journey.
Por qué es importante
Los radiólogos ya recibieron colas a finales de abril. Era importante:
- Aumente el rendimiento de los puntos con los exámenes de TC.
- En segundo lugar, aumente la precisión de la investigación.
- Permitir ver con precisión el cambio en el nivel de lesión entre las imágenes de un paciente (y esto puede ser un par de por ciento, es importante comprender si se ha vuelto más o menos).
Además, en la primera ola, la situación empeoró, porque radiólogos experimentados se enfermaron y abandonaron el proceso. La precisión y la velocidad disminuyeron.
La inteligencia artificial es buena para clasificar datos médicos. La correcta priorización de los pacientes salva vidas, porque cuanto más acertadamente determinamos el grado de lesión, más posibilidades hay de que una persona gravemente enferma reciba los medicamentos necesarios y (si todo va peor) ventilación mecánica a tiempo. Y que una persona cuyos pulmones no estén tan afectados no ocupará su lugar en el hospital.
Evaluar la proporción de daño es una de las tareas más difíciles y que requieren muchos recursos para una persona en el diagnóstico, porque es necesario evaluar un gran volumen de focos irregulares, divididos en muchas secciones.
La tarea en si
En la entrada, cortes axiales de cierto grosor. Por lo general, los ajustes se establecen entre 0,5 mm y 2,5 mm. La caja torácica es de 300 a 800 imágenes 2D. Se ponen en correspondencia aproximada entre sí, es decir, ya se han transformado para que, condicionalmente, se puedan construir imágenes sobre una película translúcida de un grosor dado, y se obtendría un modelo del cofre. Pero todo ha estado, por supuesto, en formato digital durante mucho tiempo.
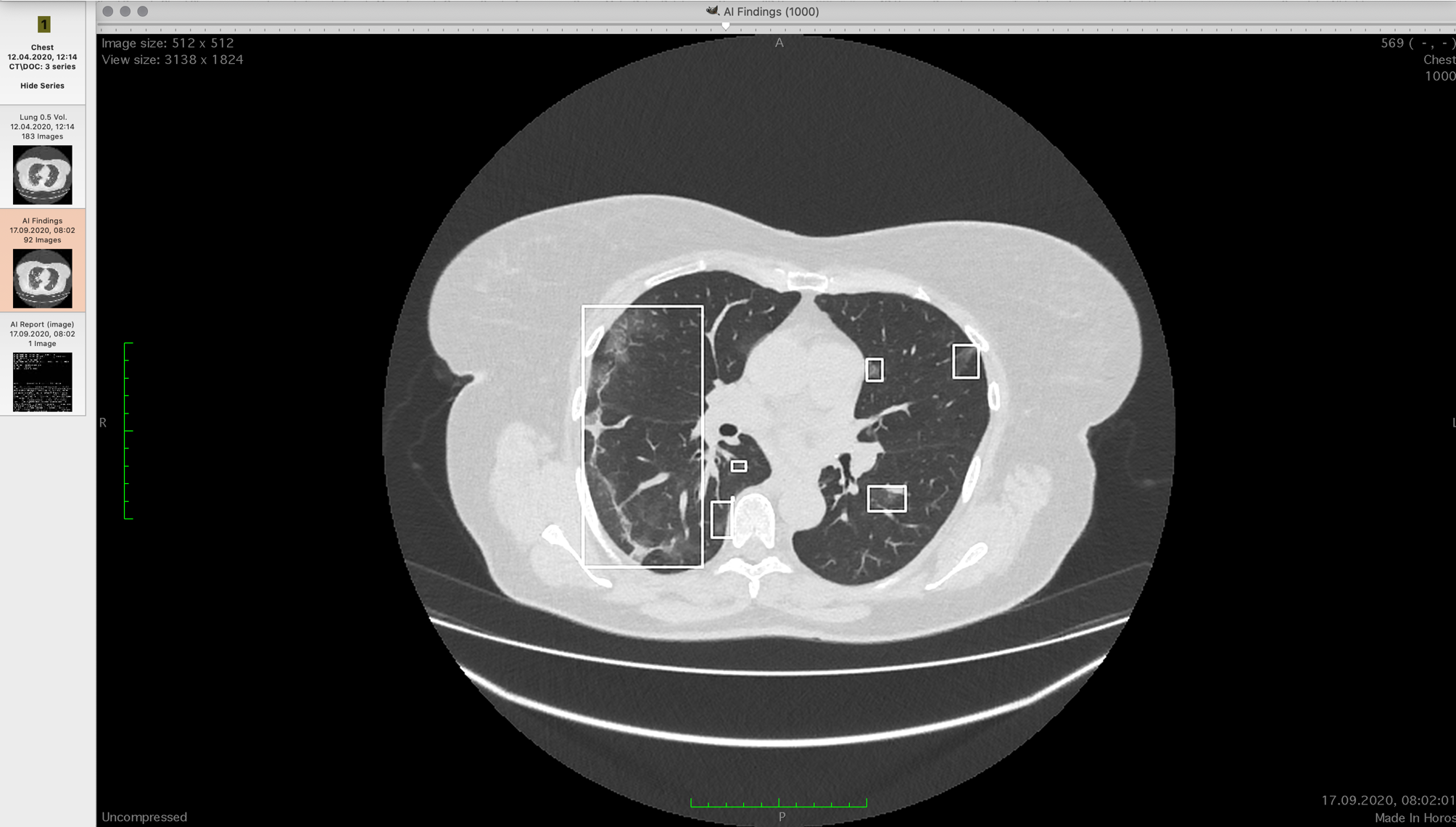
Los espectadores pueden mostrar tomografías computarizadas en capas o construir un modelo 3D. Los modelos no son muy informativos para los médicos, ya que es difícil comprender a partir de ellos la localización de focos de este tipo de lesión. Los profesionales a menudo utilizan la reconstrucción multiplanar: muestran tres proyecciones ortogonales en la pantalla: horizontal, frontal y sagital. Luego, a su vez, se escanea cada eje a lo largo de las secciones, buscando lo que se necesita. Esto sucede rápidamente en la práctica. Debe mirar 500 de estas imágenes tres veces:

diferentes médicos obtienen resultados diferentes en términos del porcentaje de daño después de esa mirada.
Necesitamos medir el volumen del pulmón en el tórax y encontrar todas las consolidaciones allí, y luego estimar su volumen. En la primera muestra, tomamos 60.000 cortes de TC reconstruidos (el dispositivo dispara en un eje, pero las proyecciones necesarias se pueden obtener mediante transformaciones).
Nuestros diez médicos no evaluaron visualmente, sino que seleccionaron todas las consolidaciones manualmente, examinando cuidadosamente cada sección. Hemos enriquecido ligeramente el conjunto de entrenamiento con aumento, una combinación de estiramientos, apretones, rotaciones y cambios en el conjunto existente.
El algoritmo determina la presencia de consolidación para cada punto. El modelo de red neuronal utilizado se basa en la arquitectura U-Net publicada en 2016... La ventaja de la arquitectura U-Net es que la red neuronal analiza las imágenes originales a diferentes escalas, y esto permite que las capas convolucionales "miren" áreas de la imagen, cuyo tamaño crece exponencialmente a medida que aumenta la profundidad de la red neuronal. En otras palabras, cada pliegue "mira" un área pequeña de 3 × 3 px. Luego, la escala se reduce dos veces, luego dos más: cada convolución siguiente mira un área de 3 × 3 píxeles, pero detrás de estos píxeles hay partes de la imagen, reducidas varias veces (6 × 6, 12 × 12, ...). El conjunto final contiene dos redes neuronales convolucionales más de una arquitectura similar basada en U-Net, con una parte de "compresión" más pesada que en el artículo original.
Dónde falla la red, pero los médicos no se equivocan
A veces, en las imágenes hay los llamados artefactos, ya sea el resultado de la respiración o el movimiento del cuerpo. En este caso, aparecen áreas con características similares a cambios en las imágenes, pero esto no es una patología. Incluso si el modelo identificó estas áreas, entonces su influencia total en el resultado es de varias décimas de porcentaje, y las decisiones se toman por cuartiles, es decir, el paciente debe ser asignado a una de cuatro categorías en términos del grado de daño. Por lo tanto, hemos descuidado esta parte de la tarea. Era mucho más importante configurar la red para cada tipo de equipo utilizado en el país.
Normalización
Los tomógrafos escriben archivos en el estándar DICOM, pero la interpretación de los formatos estándar y de grabación puede ser muy diferente, por lo que se dedicó mucho tiempo y nervios a mantener los archivos que escriben todas las máquinas de TC. Como resultado, también tenemos una herramienta para reducir todos los archivos DICOM a un solo estándar y un solo formulario, que será más útil para resolver problemas de diagnóstico, si los asumimos. Y no solo COVID-19.
Nuestro software no interfiere con el médico, sino que se instala en paralelo. Tiene sus herramientas habituales y nuestra solución, que muestra una serie adicional con un informe analítico y localización de las consolidaciones encontradas. El informe analítico se ve así:

El software es suministrado por On-premise y está incluido en el flujo de trabajo de la clínica, trabajando con máquinas de TC y estaciones de trabajo de médicos usando el protocolo DICOM, está instalado en los servidores de la clínica dentro de un circuito protegido, se necesita una GPU poderosa para que funcione la red neuronal. También existe una solución en la nube, porque no todas las clínicas regionales pueden pagarla. Hay funciones con la transferencia de datos médicos, debe tener la garantía de estar despersonalizado.
¿Por qué los fabricantes de tomógrafos no hicieron nada?
Puede parecer que somos los únicos héroes que asumimos la tarea. No, hubo otros enfoques. La mayoría de las veces, los fabricantes de tomógrafos terminaron la clasificación de acuerdo con la escala de Hounsfield (densidad del tejido) y lanzaron complementos listos para usar, uh ... con licencia por separado, o pautas sobre cómo establecer la configuración para que solo se vea un cierto tipo de tejido. Esto permitió ver mejor las consolidaciones (idealmente, solo los tejidos característicos de ellos en términos de densidad para el flujo de radiación permanecieron en el marco), pero aún así no permitió contar automáticamente. Además, desbloquear una característica de este tipo solía ser más costoso que varias de nuestras implementaciones y servidores GPU para ellos.
Dónde ver más detalles
Aquí mismo .
Más detalles .