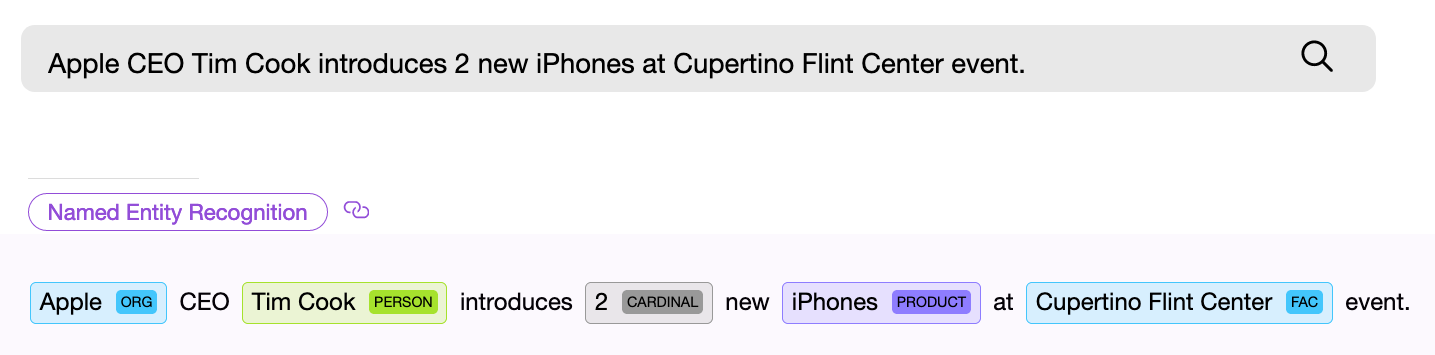
El componente NER (reconocimiento de entidad con nombre), es decir, un componente de software para buscar entidades con nombre, debe encontrar un objeto en el texto y, si es posible, obtener alguna información de él. Ejemplo: "Dame veintidós máscaras". El componente numérico NER encuentra la frase "veintidós" en el texto dado y extrae de estas palabras el valor numérico normalizado - " 22 ", ahora este valor se puede utilizar.
Los componentes de NER pueden basarse en redes neuronales o funcionar sobre la base de reglas y cualquier modelo interno. Los componentes genéricos de NER suelen utilizar el segundo método.
Consideremos varias soluciones listas para usar para encontrar entidades estándar en el texto. En este artículo nos centraremos en librerías libres o libres con restricciones, y también hablaremos de lo que se ha hecho en el proyecto Apache NlpCraft en el marco de esta edición. La lista a continuación no es una descripción general detallada y detallada, de las cuales ya hay un número suficiente en la red, sino más bien una breve descripción de las principales características, ventajas y desventajas del uso de estas bibliotecas.
Proveedores de componentes NER
Apache OpenNlp
Apache OpenNlp proporciona un conjunto bastante estándar de componentes NER para el idioma inglés, que trata sobre fechas, horas, geografía, organizaciones, porcentajes numéricos y personas. También hay un pequeño conjunto para otros idiomas (español, holandés).
Entrega:
biblioteca Java. Apache OpenNlp no envía modelos con el proyecto principal. Están disponibles para descargar por separado.
Ventajas:
licencia Apache. Los modelos se han probado en muchas implementaciones.
Desventajas:
Aparentemente, los modelos se eliminaron del proyecto principal por una razón. Uno tiene la impresión de que el trabajo en ellos se ha detenido o avanza a un ritmo deprimente y pausado, ya que hace bastante tiempo que no se ven nuevos modelos o cambios en los existentes. Dado que los usuarios de Apache OpenNlp pueden crear y entrenar sus propios modelos, es posible que esta tarea les quede completamente a ellos.
Stanford PNL
Stanford NLP es un producto vivo, en constante evolución, de excelente calidad y con una amplia gama de posibilidades. Para el idioma inglés, se agregó soporte para reconocer las siguientes entidades: persona, ubicación, organización, miscelánea, dinero, número, ordinal, porcentaje, fecha, hora, duración, conjunto. Además, el componente Regex NER incorporado le permite encontrar con un alto grado de precisión entidades tales como: correo electrónico, url, ciudad, estado_o_provincia, país, nacionalidad, religión, cargo (trabajo), ideología, cargo_delictivo, causa_de_de_de_de_una, identificador. Más detalles en el enlace . Se anuncia soporte limitado de NER para alemán, español y chino. La calidad del reconocimiento se puede probar mediante la demostración en línea .
Suministro:
Biblioteca de Java. Los modelos se pueden descargar de mavens junto con el proyecto.
No he encontrado en ninguna parte una lista y una descripción detallada de los componentes de NER para otros idiomas además del inglés. Enlaces 1 , 2 : se proporcionan ejemplos del proceso de formación de sus propios componentes NER para diferentes idiomas. En pocas palabras, se anuncia la capacidad de usar otros idiomas, pero hay que jugar.
Pros:
La sensación de trabajar con el proyecto en su conjunto y con modelos prefabricados es la más positiva, el proyecto vive y se desarrolla, la calidad del reconocimiento es buena (“bueno” es un concepto condicional, hay métricas que caracterizan la calidad del reconocimiento de los componentes NER, pero este tema está más allá del alcance del artículo).
Desventajas:
Aparte del caos con los documentos, son pequeños. Para quién es importante, preste atención a la licencia. La licencia pública general GNU es diferente de Apache , por lo que, por ejemplo, no puede agregar un producto con esta licencia a productos con licencia de Apache, etc.
API de idiomas de Google
La API de idioma de Google para inglés admite la siguiente lista de entidades: persona, ubicación, organización, evento, trabajo_de_art, consumidor_good, otro, número de teléfono, dirección, fecha, número, precio.
Plataforma:
API REST, SaaS. Hay disponibles bibliotecas cliente listas para usar sobre REST (Java, C #, Python, Go, etc.).
Ventajas:
El conocido gigante de Internet proporciona un gran conjunto de componentes, desarrollo y calidad de NER.
Contras:
A partir de ciertos volúmenes, el uso se paga .
Spacy
Esta biblioteca proporciona uno de los conjuntos más amplios de entidades admitidas para el reconocimiento; consulte el enlace para obtener una lista de las admitidas.
Plataforma:
Python.
Desafortunadamente, la falta de experiencia personal en el uso industrial no me permite agregar una descripción real de los pros y los contras de esta biblioteca. Además, ya se ha publicado en habr una descripción detallada de las soluciones Python NLP .
Todas las bibliotecas anteriores le permiten entrenar sus propios modelos. Además, todos ellos (excepto Apache OpenNlp) permiten extraer valores normalizados de las entidades encontradas, es decir, por ejemplo, obtener el número “173” de la entidad numérica “ciento setenta y tres” que se encuentra en la consulta.
Como podemos ver, hay muchas opciones para resolver el problema de encontrar entidades con nombre, la dirección de su desarrollo es obvia: expandir la lista de lenguajes compatibles y un conjunto de entidades reconocidas, mejorando la calidad del reconocimiento.
A continuación se muestra un resumen de lo que el proyecto Apache NlpCraft ha aportado a esta área ya altamente desarrollada.
Funciones adicionales proporcionadas por NlpCraft
- Componentes propios de NER para nuevas entidades, soluciones mejoradas para algunas existentes.
- Integración de componentes NER de todas las bibliotecas anteriores dentro del marco de uso del producto.
- Soporte para "entidades compuestas", lo que brinda a los usuarios una manera fácil de crear nuevos componentes personalizados a partir de los existentes.
Ahora sobre todo esto con un poco más de detalle.
Componentes patentados de NER
Los componentes nativos de NER de Apache NlpCraft son componentes para reconocer fechas, números, geografía, coordenadas, ordenar y hacer coincidir diferentes entidades. Algunos de ellos son únicos, otros son solo una implementación mejorada de las soluciones existentes (se ha aumentado la precisión del reconocimiento, se han agregado campos de valor adicionales, etc.).
Integración de soluciones existentes
Todas las soluciones anteriores están integradas para su uso con Apache NlpCraft.
Cuando se trabaja con un proyecto, el usuario solo necesita conectar el módulo requerido y especificar en la configuración qué componentes NER deben usarse al buscar entidades de un modelo en particular.
A continuación, se muestra un ejemplo de una configuración que utiliza cuatro componentes NER diferentes de dos proveedores al buscar en el texto:
"enabledBuiltInTokens": [
"nlpcraft:num",
"nlpcraft:coordinate",
"google:organization",
"google:phone_number"
]
Lea más sobre el uso de Apache NlpCraft aquí . Se requiere una cuenta de desarrollador de Google válida para utilizar la API de idiomas de Google.
Soporte de entidad compuesta
El soporte para entidades compuestas es la más interesante de las características anteriores, vamos a detenernos en ella con un poco más de detalle.
Una entidad compuesta es una entidad definida sobre la base de otra. Veamos un ejemplo. Suponga que está desarrollando un sistema de control de PNL basado en la intención (consulte Alexa , Google Dialogflow , Alice , Apache Nlpraft , etc.) y su modelo funciona con geografía, pero solo para los Estados Unidos. Puede tomar cualquier componente de búsqueda geográfica como " nlpcraft: city " y usarlo directamente.
Además, cuando se activa la intención, en la función correspondiente (devolución de llamada), debe verificar el valor del campo " país " y, si no cumple con las condiciones requeridas, finalizar la función, evitando la activación falsa. A continuación, debe volver a emparejar e intentar elegir otra función más adecuada.
¿Qué hay de malo en este enfoque?
- Hace que sea mucho más difícil trabajar con funciones llamadas transfiriendo el control de ellas al hilo de trabajo principal y viceversa. Además, vale la pena considerar que no todos los sistemas de diálogo tienen dicha funcionalidad de transferencia de control.
- Manchas la lógica de coincidencia entre la intención y el código del método ejecutable.
Ok ... Puedes crear tu propio componente NER desde cero para encontrar ciudades americanas, pero esta tarea no se resuelve en cinco minutos.
Intentémoslo de otra manera. Puede complicar la intención (en esos sistemas cuando sea posible) y buscar ciudades filtradas adicionalmente por país. Pero, repito, no todos los sistemas brindan la posibilidad de filtrado complejo por campos de elementos, además, se complican los intents, que deben ser lo más claros y sencillos posibles, sobre todo si hay muchos de ellos en el proyecto.
Apache NlpCraft proporciona un mecanismo para definir componentes nativos de NER basados en los existentes. A continuación se muestra un ejemplo de configuración (la sintaxis DSL completa está disponible aquí , un ejemplo de creación de elementos está aquí):
"elements": [
{
"id": "custom:city:usa",
"description": "Wrapper for USA cities",
"synonyms": [
"^^id == 'nlpcraft:city' && lowercase(~city:country) == 'usa')^^"
]
}
]
En este ejemplo, describimos una nueva entidad denominada "American city" - " custom: city: usa ", basada en el " nlpcraft: city " ya existente filtrado por un determinado criterio.
Ahora puede crear intenciones basadas en el nuevo elemento creado, y las ciudades fuera de los Estados Unidos que se encuentran en el texto no provocarán que sus intenciones se activen de forma no deseada.
Otro ejemplo:
"macros": [
{
"name": "<AIRPORT>",
"macro": "{airport|aerodrome|airdrome|air station}"
}
],
"elements": [
{
"id": "custom:airport:usa",
"description": "Wrapper for USA airports",
"synonyms": [
"<AIRPORT> {of|for|*} ^^id == 'nlpcraft:city' &&
lowercase(~city:country) == 'usa')^^"
]
}
]
En este ejemplo, hemos definido la entidad denominada "ciudad aeropuerto en los EE. UU." - " personalizado: aeropuerto: EE. UU .". Al definir este elemento, no solo filtramos las ciudades según su afiliación estatal, sino que también establecemos una regla adicional según la cual el nombre de la ciudad debe ir precedido de cualquier sinónimo que defina el concepto de “aeropuerto”. (Lea más sobre la creación de sinónimos de elementos a través de macros, aquí ).
Los elementos compuestos se pueden definir con cualquier nivel de anidamiento, es decir, si es necesario, se pueden diseñar nuevos elementos basados en el recién creado “ custom: airport: usa”. También tenga en cuenta que todos los valores normalizados de las entidades principales, en este caso el elemento base nlpcraft: city , también están disponibles en el elemento custom: airport: usa , y se pueden usar en el cuerpo de la función de la intención activada.
Por supuesto, los "bloques de construcción" se pueden definir no solo para todos los componentes estándar compatibles de OpenNlp, Stanford, Google, Spacy y NlpCraft, sino también para componentes NER personalizados, ampliando sus capacidades y permitiéndole reutilizar desarrollos de software existentes.
Tenga en cuenta que, de hecho, no produce nuevos componentes para cada nueva tarea, sino que simplemente los configura o "mezcla" su funcionalidad en sus propios elementos.
Por lo tanto, utilizando "entidades compuestas", un desarrollador puede:
- Simplifique significativamente la lógica para construir intents transfiriéndola parcialmente a bloques de construcción reutilizables.
- Obtenga componentes NER con un nuevo comportamiento mediante cambios de configuración sin entrenamiento ni codificación de modelos.
- Reutilice soluciones listas para usar con la calidad esperada, basándose en pruebas o métricas existentes.
Conclusión
Espero que una breve descripción de los pros y los contras de los componentes NER existentes sea útil para los lectores, y comprender cómo Apache NlpCraft puede expandir significativamente sus capacidades y adaptar las soluciones existentes para nuevas tareas acelerará el desarrollo de sus proyectos.