
Esta publicación puede verse como una reelaboración del material de restauración a través del aprendizaje profundo para mis amigos o novatos. He escrito más de 10 publicaciones relacionadas con enfoques para la restauración de imágenes mediante el aprendizaje profundo. Ahora es el momento de una descripción general rápida de lo que han aprendido los lectores de estos artículos, así como de escribir una introducción rápida para los novatos que quieran divertirse con nosotros.
Terminología

Figura: 1. Un ejemplo de imagen de entrada dañada (izquierda) y resultado de restauración (derecha). Imagen tomada de la página de Github del autor. La
entrada dañada que se muestra en la Figura 1 identifica típicamente: a) píxeles faltantes o huecos no válidos como píxeles ubicados en áreas a rellenar; b) píxeles reales, remanentes, correctos que podemos utilizar para rellenar los que faltan. Tenga en cuenta que podemos tomar los píxeles correctos y completar los espacios asociados correspondientes.
Introducción
La forma más fácil de completar las partes que faltan es copiando y pegando. La idea clave es buscar primero para encontrar las piezas más similares de una imagen de sus píxeles restantes, o encontrarlas en un gran conjunto de datos con millones de imágenes, luego insertar directamente las piezas en las piezas que faltan. Sin embargo, el algoritmo de búsqueda puede llevar mucho tiempo e incluye métricas de medición de distancia generadas manualmente. La generalización del algoritmo y su eficiencia aún deben mejorarse.
Con los enfoques de aprendizaje profundo en la era del big data, tenemos enfoques basados en datos para las restauraciones de aprendizaje profundo, con estos enfoques generamos píxeles eliminados con buena consistencia y texturas finas. Echemos un vistazo a 10 enfoques de aprendizaje profundo conocidos para la restauración de imágenes. Estoy seguro de que podrá comprender los otros artículos cuando comprenda estos 10. Comencemos.
Codificador de contexto (primer algoritmo de restauración basado en GAN, 2016)

Figura: 2. Arquitectura de red del codificador contextual (CE).
El codificador de contexto (CE, 2016) [1] es la primera implementación de una restauración basada en GAN. Este trabajo cubre conceptos básicos útiles de tareas de restauración. El concepto de "contexto" está asociado con la comprensión de la imagen como tal, la esencia de la idea del codificador es capas por canales completamente conectadas (la capa intermedia de la red se muestra en la Figura 2). De manera similar a una capa estándar completamente conectada, el punto principal es que todas las ubicaciones de elementos en la capa anterior contribuirán a la ubicación de cada elemento en la capa actual. Entonces, la red aprende la relación entre todos los arreglos de los elementos y obtiene una representación semántica más profunda de la imagen completa. La CE se considera una línea de base, puede leer más sobre ella en mi publicación [ aquí ].
MSNPS ( )

. 3. ( CE) (VGG-19).
(MSNPS, 2016) [3] puede verse como una versión ampliada de CE [1]. Los autores de este artículo utilizaron CE modificado para predecir las partes faltantes en una imagen y una red de textura para decorar la predicción y mejorar la calidad de las partes faltantes del modelo relleno. La idea de la red de texturas se toma de la tarea de transferir el estilo. Queríamos diseñar los píxeles existentes más similares a los píxeles generados para mejorar el detalle de la textura local. Yo diría que este trabajo es una versión inicial de una estructura de red de dos etapas de gruesa a fina. La primera red de contenido (es decir, aquí CE) es responsable de reconstruir / predecir las partes faltantes, y la segunda red (es decir, la red de texturas) es responsable de refinar las partes llenas.
Además de la pérdida típica de reconstrucción de píxeles (es decir, pérdida L1) y la pérdida adversaria estándar, el concepto de pérdida de textura propuesto en este artículo juega un papel importante en trabajos posteriores sobre restauración de imágenes. De hecho, la pérdida de textura está asociada con la pérdida de percepción y la pérdida de estilo, que se utilizan ampliamente en muchas tareas de generación de imágenes, como la transferencia de estilos neuronales. Para obtener más información sobre este artículo, puede consultar mi publicación anterior [ aquí ].
GLCIC (hito en la restauración del aprendizaje profundo, 2017)
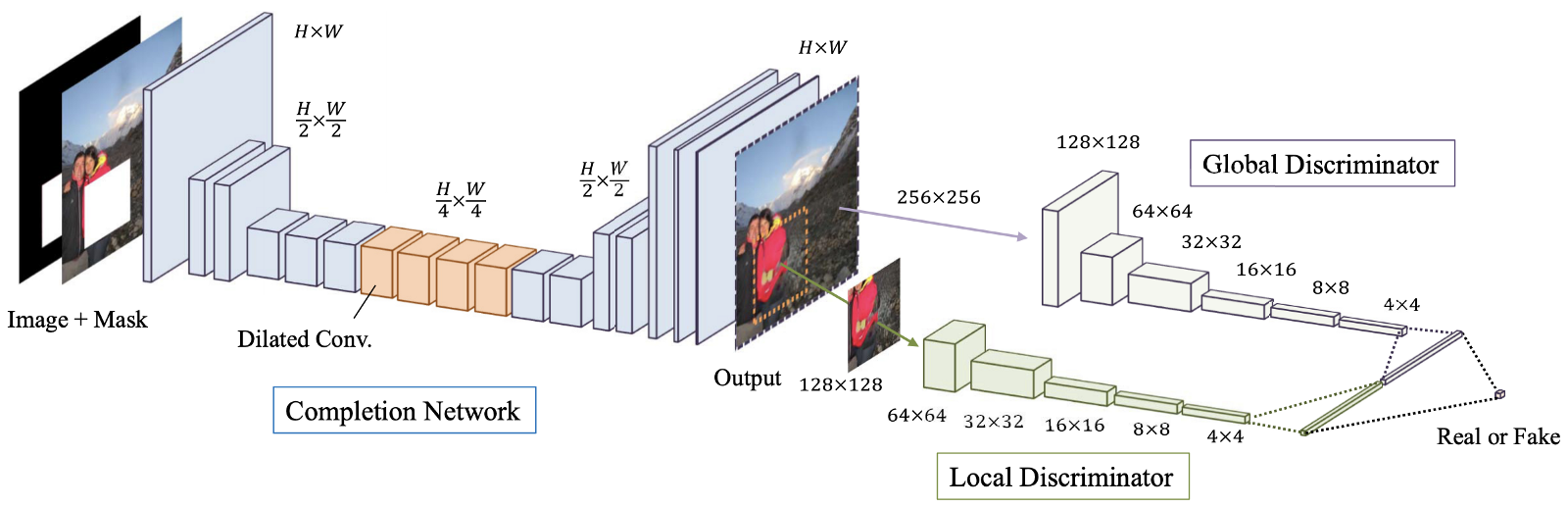
Figura: 4. Una visión general del modelo propuesto, que consiste en la red final (red “Generador”), así como discriminadores globales y locales. La
finalización de imágenes coherente global y localmente (GLCIC, 2017) [4] es un hito en la restauración de imágenes de aprendizaje profundo, ya que define una red convolucional extendida totalmente convolucional para esta área y, de hecho, es una arquitectura de red típica en la restauración de imágenes. Con convoluciones avanzadas, la red es capaz de comprender el contexto de una imagen sin el uso de costosas capas completamente conectadas y, por lo tanto, puede manejar imágenes de diferentes tamaños.
Además de la red totalmente convolucional con convoluciones extendidas, también se entrenaron dos discriminadores en dos escalas junto con la red del generador. El discriminador global mira la imagen completa, mientras que el discriminador local mira el área central que se llena. Con discriminadores tanto globales como locales, la imagen llena tiene una mejor consistencia global y local. Tenga en cuenta que muchos de los artículos más recientes sobre restauración de imágenes siguen este diseño de discriminador multiescala. Si está interesado, lea mi publicación anterior [ aquí ] para obtener más información.
Restauración basada en parche GAN (variación GLCIC, 2018)

Figura: 5. Arquitectura propuesta del discriminador generativo ResNet y PGGAN.
La restauración basada en parches que utiliza GAN [5] puede considerarse una variante de GLCIC [4]. En pocas palabras, dos conceptos avanzados, aprendizaje residual [6] y PatchGAN [7], están integrados en el GLCIC para mejorar aún más el rendimiento. Los autores de este artículo han combinado la unión residual y la convolución extendida para formar un bloque residual extendido. El discriminador GAN tradicional ha sido reemplazado por el discriminador PatchGAN para promover mejores detalles de textura local y consistencia de estructura global.
La principal diferencia entre el discriminador GAN tradicional y el discriminador PatchGAN es que el discriminador GAN tradicional proporciona solo una etiqueta predictiva (0 a 1) para indicar el realismo de la señal de entrada, mientras que el discriminador PatchGAN proporciona una matriz de etiquetas (también 0 a 1). ) para indicar el realismo de cada área local de la señal de entrada. Tenga en cuenta que cada elemento de la matriz representa un área local de la entrada. También puede consultar una descripción general del aprendizaje residual y PatchGAN [ visitando esta publicación mía ].
Shift-Net (copiar y pegar de aprendizaje profundo, 2018)

Figura: 6. Arquitectura de red Shift-Net. La capa de unión-deslizamiento se agrega a una resolución de 32x32.
Shift-Net [8] aprovecha tanto las CNN modernas basadas en datos como el método tradicional de "copiar y pegar" de reparto profundo de elementos utilizando la capa de unión por desplazamiento propuesta. Hay dos ideas principales en este artículo.
En primer lugar, los autores han propuesto una pérdida de hito que provoca que los elementos decodificados de las partes faltantes (dada la parte oculta de la imagen) estén cerca de los elementos codificados de las partes faltantes (dado el buen estado de la imagen). Como resultado, el proceso de decodificación puede llenar las partes faltantes con su estimación razonable en la imagen en buenas condiciones (es decir, la fuente de verdad de las partes faltantes).
En segundo lugar, la capa de unión-desplazamiento propuesta permite a la red tomar prestada de manera eficiente la información proporcionada por sus vecinos más cercanos fuera de las partes faltantes para refinar tanto la estructura semántica global como los detalles de textura local de las partes generadas. En pocas palabras, proporcionamos enlaces pertinentes para refinar nuestra evaluación. Creo que a los lectores interesados en la restauración de imágenes les resultará útil consolidar las ideas sugeridas en este artículo. Le recomiendo que lea la publicación anterior [ aquí ] para obtener más detalles.
DeepFill v1 (Restauración de imágenes innovadora, 2018)

Figura: 7. Arquitectura de red del marco propuesto.
La restauración generativa con atención contextual (CA, 2018), también llamada DeepFill v1 o CA [9], puede verse como una versión extendida o variante de Shift-Net [8]. Los autores desarrollan la idea de copiar y pegar y ofrecen una capa de atención contextual que es diferenciable y totalmente convolucional.
Similar a la capa de unión-desplazamiento en [8], al hacer coincidir los elementos generados dentro de los píxeles faltantes y las características fuera de los píxeles faltantes, podemos averiguar la contribución de todos los elementos fuera de los píxeles faltantes a cada ubicación dentro de los píxeles faltantes. Por lo tanto, la combinación de todos los elementos externos se puede utilizar para refinar los elementos generados dentro de los píxeles faltantes. En comparación con la capa de unión-corte, que solo busca las características más similares (es decir, una asignación dura, no diferenciable), la capa CA en este artículo usa una asignación suave y diferenciable, en la que todas las características tienen sus propios pesos para indicar su contribución a cada lugar dentro de los píxeles faltantes. Para obtener más información sobre la atención contextual, lea mi publicación anterior [ aquí], allí encontrará ejemplos más específicos.
GMCNN (CNN multicolumna para restauración de imágenes, 2018)

Figura: 8. La arquitectura de la red propuesta.
Las redes neuronales convolucionales multicolumnas generativas (GMCNN, 2018) [10] amplían la importancia de suficientes campos receptivos para la restauración de imágenes y ofrecen nuevas funciones de pérdida para mejorar aún más los detalles de textura local del contenido generado. Como se muestra en la Figura 9, hay tres ramas / columnas, y cada rama usa tres tamaños de filtro diferentes. El uso de varios campos receptivos (tamaños de filtro) se debe a que el tamaño del campo receptivo es importante para la tarea de restauración de la imagen. Dado que no hay píxeles vecinos locales, es necesario tomar prestada información de ubicaciones espacialmente distantes para completar los píxeles locales faltantes.
Para las funciones de pérdida propuestas, la idea básica detrás de la pérdida de campo aleatorio de Markov diversificado implícito (ID-MRF) es dirigir los parches generados de elementos para encontrar a sus vecinos más cercanos fuera de las áreas omitidas como referencias, y estos vecinos más cercanos deben ser lo suficientemente diversificado para que se puedan modelar más detalles de textura locales. De hecho, esta pérdida es una versión mejorada de la pérdida de textura utilizada en MSNPS [3]. Le recomiendo que lea mi publicación [ aquí ] para obtener una explicación detallada de esta pérdida.
PartialConv (empuja las limitaciones de la restauración a través del aprendizaje profundo para vacíos irregulares, 2018)

. 9. , .
(PartialConv o PConv) [11] amplía los límites del aprendizaje profundo en la restauración de imágenes al ofrecer una forma de manejar imágenes latentes con múltiples agujeros irregulares. Obviamente, la idea principal de este artículo es el plegado parcial. Al usar PConv, los resultados de la convolución dependerán solo de los píxeles permitidos, por lo que tenemos control sobre la información transmitida dentro de la red. Este es el primer trabajo de restauración de imágenes para abordar huecos irregulares. Tenga en cuenta que los modelos de restauración anteriores fueron entrenados para corregir imágenes dañadas, por lo que estos modelos no son adecuados para imágenes de restauración con vacíos incorrectos.
He proporcionado un ejemplo simple para explicar claramente cómo se realiza el plegado parcial en mi publicación anterior [ aquí]. Visite el enlace para más detalles. Espero que disfrutes.
EdgeConnect: primero los contornos, luego los colores, 2019

Figura: 10. Arquitectura de red EdgeConnect. Como puede ver, hay dos generadores y dos discriminadores.
EdgeConnect[12]: Restauración de imágenes generativas utilizando Adversarial Edge Learning (EdgeConnect) [12] presenta una forma interesante de resolver el problema de la restauración de imágenes. La idea principal de este artículo es dividir la tarea de restauración en dos pasos simplificados, a saber, predecir los bordes y completar la imagen basándose en el mapa de bordes previsto. Los bordes en las áreas faltantes se predicen primero y luego la imagen se completa de acuerdo con la predicción del borde. La mayoría de los métodos utilizados en este artículo se han cubierto en mis publicaciones anteriores. Un buen vistazo a cómo las diversas técnicas se pueden usar juntas para dar forma a un nuevo enfoque de restauración de imágenes de aprendizaje profundo Quizás desarrolle su propio modelo de restauración. Por favor, vea mi publicación anterior [aquí ] para obtener más información sobre este artículo.
DeepFill v2 (Un enfoque práctico para la restauración de imágenes generativas, 2019)

Figura: 11. Descripción general de la arquitectura de red del modelo para restauración gratuita.
Restauración de forma libre con convolución cerrada(DeepFill v2 o GConv, 2019) [13]. Este es quizás el algoritmo de restauración de imágenes más práctico que se puede utilizar directamente en sus aplicaciones. Se puede considerar como una versión mejorada de DeepFill v1 [9], convolución parcial [11] y EdgeConnect [12]. La idea principal del trabajo es Gated Convolution, una versión entrenable de convolución parcial. Al agregar una capa convolucional estándar adicional seguida de una función sigmoidea, es posible conocer la validez de la ubicación de cada píxel / objeto y, por lo tanto, también permite la entrada adicional de un boceto personalizado. Además de la convolución cerrada, SN-PatchGAN se utiliza para estabilizar aún más el entrenamiento del modelo GAN. Para obtener más información sobre la diferencia entre convolución parcial y convolución cerrada, y cómocómo la entrada adicional del boceto del usuario puede afectar los resultados de la restauración, consulte mi última publicación [aquí ].
Conclusión
Espero que ahora tenga un conocimiento básico de la restauración de imágenes. Creo que la mayoría de las técnicas comunes utilizadas en la restauración de imágenes de aprendizaje profundo se han cubierto en mis publicaciones anteriores. Si es un viejo amigo mío, creo que ahora está en condiciones de comprender otros trabajos de restauración mediante el aprendizaje profundo. Si eres principiante, me gustaría darte la bienvenida. Espero que encuentre útil esta publicación. De hecho, esta publicación le brinda la oportunidad de unirse a nosotros y aprender juntos.
En mi opinión, todavía es difícil restaurar imágenes con estructuras de escena complejas y una gran cantidad de píxeles faltantes (por ejemplo, cuando falta el 50% de los píxeles). Por supuesto, otro desafío es la restauración de imágenes de alta resolución. Todas estas tareas pueden llamarse extremas. Creo que un enfoque basado en los últimos avances en restauración puede solucionar algunos de estos problemas.
Vínculos a artículos
[1] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, “Context Encoders: Feature Learning by Inpainting,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.

- Curso avanzado "Machine Learning Pro + Deep Learning"
- Curso de aprendizaje automático
- Formación profesional en ciencia de datos
- Formación de analista de datos
- Curso de Python para desarrollo web
Más cursos
Artículos recomendados
- Cuánto gana el científico de datos: descripción general de los sueldos y trabajos en 2020
- Cuánto gana el analista de datos: una descripción general de los sueldos y trabajos en 2020
- Cómo convertirse en un científico de datos sin cursos en línea
- 450 cursos gratuitos de la Ivy League
- Machine Learning 5 9
- Machine Learning Computer Vision
- Machine Learning Computer Vision