Hace tiempo que no escribo ningún artículo y creo que es hora de escribir sobre cómo el conocimiento en ciencia de datos, obtenido durante la capacitación de la reconocida especialización de Yandex y MIPT "Machine Learning and Data Analysis", me vino bien. Es cierto que, para ser justos, debe tenerse en cuenta que el conocimiento no se ha obtenido por completo, la especialidad no está completa :) Sin embargo, ya es posible resolver problemas comerciales reales simples. ¿O es necesario? Esta pregunta se responderá en solo un par de párrafos.
Entonces, hoy en este artículo le contaré al querido lector sobre mi primera experiencia de participar en un concurso abierto. Me gustaría señalar de inmediato que mi objetivo de la competencia no era obtener ningún premio. El único deseo era probar suerte en el mundo real :) Sí, además sucedió que el tema de la competencia prácticamente no se cruzó con el material de los cursos aprobados. Esto agregó algunas complicaciones, pero con ello la competencia se volvió aún más interesante y valiosa la experiencia ganada allí.
Por tradición, designaré a quienes pueden estar interesados en el artículo. En primer lugar, si ya ha completado los dos primeros cursos de la especialización anterior y quiere probar suerte en problemas prácticos, pero es tímido y le preocupa que no funcione y se rían de usted, etc. Después de leer el artículo, espero que esos temores se disipen. En segundo lugar, quizás estés resolviendo un problema similar y no sepas en absoluto por dónde entrar. Y aquí hay un ready-made sin pretensiones, como dicen los datos reales, una línea de base :)
Aquí valdría la pena esbozar el plan de investigación, pero nos desviaremos un poco y trataremos de responder la pregunta del primer párrafo: si un principiante en la identificación de datos necesita probar suerte en tales competencias. Las opiniones difieren sobre este punto. ¡Personalmente, mi opinión es necesaria! Déjame explicarte por qué. Hay muchas razones, no enumeraré todo, señalaré las más importantes. En primer lugar, estos concursos ayudan a consolidar los conocimientos teóricos en la práctica. En segundo lugar, en mi práctica, casi siempre, la experiencia adquirida en condiciones próximas al combate, motiva muy fuertemente para futuras hazañas. En tercer lugar, y esto es lo más importante: durante la competencia tienes la oportunidad de comunicarte con otros participantes en chats especiales, ni siquiera tienes que comunicarte, solo puedes leer sobre lo que la gente escribe y esto a) a menudo conduce a pensamientos interesantes sobrequé otros cambios realizar en el estudio, yb) da confianza para validar sus propias ideas, especialmente si se expresan en el chat. Estas ventajas deben abordarse con cierta prudencia, para que no haya sentimiento de omnisciencia ...
Ahora un poco sobre cómo decidí participar. Me enteré de la competencia unos días antes de que comenzara. El primer pensamiento es “bueno, si hubiera sabido del concurso hace un mes, me habría preparado, pero habría estudiado algunos materiales adicionales que podrían ser útiles para realizar la investigación, de lo contrario, sin preparación podría no cumplir con el plazo ...”, el segundo El pensamiento “en realidad, lo que podría no funcionar si el objetivo no es un premio, sino la participación, sobre todo porque los participantes en el 95% de los casos hablan ruso, además hay charlas especiales para la discusión, habrá algún tipo de webinars por parte de los organizadores. Al final, será posible ver científicos de datos en vivo de todos los tamaños y tipos ... ". Como habrás adivinado, el segundo pensamiento ganó, y no en vano: literalmente, unos días de arduo trabajo y obtuve una experiencia valiosa, aunque simple,pero toda una tarea empresarial. Por lo tanto, si está en camino de conquistar las alturas de la ciencia de datos y ve la próxima competencia, sí en su idioma nativo, con soporte en chats y tiene tiempo libre, no lo dude por mucho tiempo, ¡intente y que la fuerza venga con usted! En una nota positiva, pasamos a la tarea y al plan de investigación.
Nombres coincidentes
No nos torturaremos ni presentaremos una descripción del problema, pero daremos el texto original del sitio web del organizador de la competencia.
Una tarea
En la búsqueda de nuevos clientes, SIBUR debe procesar información sobre millones de nuevas empresas de diversas fuentes. Al mismo tiempo, los nombres de las empresas pueden tener diferentes grafías, contener abreviaturas o errores, o estar afiliados a empresas ya conocidas por SIBUR.
Para procesar la información sobre clientes potenciales de manera más eficiente, SIBUR necesita saber si los dos nombres están relacionados (es decir, pertenecen a la misma empresa o empresas afiliadas).
En este caso, SIBUR podrá utilizar información ya conocida sobre la propia empresa o sobre empresas afiliadas, para no duplicar llamadas a la empresa o no perder tiempo en empresas irrelevantes o filiales de competidores.
La muestra de entrenamiento contiene pares de nombres de diferentes fuentes (incluidas las personalizadas) y marcado.
El marcado se obtuvo en parte a mano, en parte, mediante algoritmos. Además, el marcado puede contener errores. Vas a construir un modelo binario que predice si dos nombres están relacionados. La métrica utilizada en esta tarea es F1.
En esta tarea, puede e incluso necesita utilizar fuentes de datos abiertas para enriquecer el conjunto de datos o encontrar información adicional que sea importante para identificar empresas afiliadas.
Información adicional sobre la tarea
Descubrirme para más información
, . , : , , Sibur Digital, , Sibur international GMBH , “ International GMBH” .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source , . — . .
, - – . , , - , , , .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
, , , .. crowdsource
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source
open source , . — . .
, - – . , , - , , , .
Datos
train.csv - conjunto de entrenamiento
test.csv - conjunto de pruebas
sample_submission.csv - ejemplo de una solución en el formato correcto
Nombramiento baseline.ipynb - código
baseline_submission.csv - solución básica
Tenga en cuenta que los organizadores de la competencia se ocuparon de la generación más joven y publicaron una solución básica al problema, lo que da una calidad f1 de aproximadamente 0,1. Esta es la primera vez que participo en concursos y la primera vez que veo esto :)
Entonces, habiéndonos familiarizado con la tarea en sí y los requisitos para su solución, pasemos al plan de solución.
Plan de resolución de problemas
Configuración de instrumentos técnicos
Carguemos las bibliotecas
Escribamos funciones auxiliares
Preprocesamiento de datos
… -. !
50 & Drop it smart.
Calculemos la distancia de Levenshtein
Calcule la distancia de Levenshtein normalizada
Visualice las características
Compare las palabras del texto para cada par y genere una gran cantidad de características
Compare las palabras del texto con las palabras de los nombres de las 50 principales marcas de participación en las industrias petroquímica y de la construcción. Consigamos el segundo gran grupo de funciones. Segundo CHIT
Preparación de datos para alimentar el modelo
Configurar y entrenar el modelo
Resultados de la competencia
Fuentes de información
Ahora que nos hemos familiarizado con el plan de investigación, pasemos a su implementación.
Configuración de instrumentos técnicos
Cargando Bibliotecas
En realidad todo es simple aquí, primero instalaremos las bibliotecas que faltan
Instale la biblioteca para determinar la lista de países y luego elimínelos del texto
pip install pycountry
Instale una biblioteca para determinar la distancia de Levenshtein entre palabras de texto entre sí y con palabras de diferentes listas
pip install strsimpy
Instalaremos la biblioteca con la ayuda de la cual transliteraremos el texto ruso al latín
pip install cyrtranslit
Extraer bibliotecas
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import pycountry
import re
from tqdm import tqdm
tqdm.pandas()
from strsimpy.levenshtein import Levenshtein
from strsimpy.normalized_levenshtein import NormalizedLevenshtein
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import seaborn as sns
sns.set()
sns.set_style("whitegrid")
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit
from scipy.sparse import csr_matrix
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report, f1_score
# import googletrans
# from googletrans import Translator
import cyrtranslitEscribamos funciones auxiliares
Se considera una buena práctica especificar la función en una línea en lugar de copiar un gran fragmento de código. Lo haremos, casi siempre.
No discutiré que la calidad del código en las funciones sea excelente. En algunos lugares definitivamente debería optimizarse, pero para el propósito de una investigación rápida, solo la precisión de los cálculos será suficiente.
Entonces, la primera función convierte el texto a minúsculas
El código
# convert text to lowercase
def lower_str(data,column):
data[column] = data[column].str.lower()Las siguientes cuatro funciones ayudan a visualizar el espacio de las características en estudio y su capacidad para separar objetos por etiquetas de destino: 0 o 1.
El código
# statistic table for analyse float values (it needs to make histogramms and boxplots)
def data_statistics(data,analyse,title_print):
data0 = data[data['target']==0][analyse]
data1 = data[data['target']==1][analyse]
data_describe = pd.DataFrame()
data_describe['target_0'] = data0.describe()
data_describe['target_1'] = data1.describe()
data_describe = data_describe.T
if title_print == 'yes':
print ('\033[1m' + ' ',analyse,'\033[m')
elif title_print == 'no':
None
return data_describe
# histogramms for float values
def hist_fz(data,data_describe,analyse,size):
print ()
print ('\033[1m' + 'Information about',analyse,'\033[m')
print ()
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
min_data = data_describe['min'].min()
max_data = data_describe['max'].max()
data0_mean = data_describe.loc['target_0']['mean']
data0_median = data_describe.loc['target_0']['50%']
data0_min = data_describe.loc['target_0']['min']
data0_max = data_describe.loc['target_0']['max']
data0_count = data_describe.loc['target_0']['count']
data1_mean = data_describe.loc['target_1']['mean']
data1_median = data_describe.loc['target_1']['50%']
data1_min = data_describe.loc['target_1']['min']
data1_max = data_describe.loc['target_1']['max']
data1_count = data_describe.loc['target_1']['count']
print ('\033[4m' + 'Analyse'+ '\033[m','No duplicates')
figure(figsize=size)
sns.distplot(data_0,color='darkgreen',kde = False)
plt.scatter(data0_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data0_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data0_count,
' Min:', round(data0_min,2),
' Max:', round(data0_max,2),
' Mean:', round(data0_mean,2),
' Median:', round(data0_median,2))
print ()
print ('\033[4m' + 'Analyse'+ '\033[m','Duplicates')
figure(figsize=size)
sns.distplot(data_1,color='darkred',kde = False)
plt.scatter(data1_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data1_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data_1.count(),
' Min:', round(data1_min,2),
' Max:', round(data1_max,2),
' Mean:', round(data1_mean,2),
' Median:', round(data1_median,2))
# draw boxplot
def boxplot(data,analyse,size):
print ('\033[4m' + 'Analyse'+ '\033[m','All pairs')
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
figure(figsize=size)
sns.boxplot(x=analyse,y='target',data=data,orient='h',
showmeans=True,
meanprops={"marker":"o",
"markerfacecolor":"dimgray",
"markeredgecolor":"black",
"markersize":"14"},
palette=['palegreen', 'salmon'])
plt.ylabel('target', size=14)
plt.xlabel(analyse, size=14)
plt.show()
# draw graph for analyse two choosing features for predict traget label
def two_features(data,analyse1,analyse2,size):
fig = plt.subplots(figsize=size)
x0 = data[data['target']==0][analyse1]
y0 = data[data['target']==0][analyse2]
x1 = data[data['target']==1][analyse1]
y1 = data[data['target']==1][analyse2]
plt.scatter(x0,y0,c='green',marker='.')
plt.scatter(x1,y1,c='black',marker='+')
plt.xlabel(analyse1)
plt.ylabel(analyse2)
title = [analyse1,analyse2]
plt.title(title)
plt.show()La quinta función está diseñada para generar una tabla de conjeturas y errores del algoritmo, más conocida como tabla de conjugación.
En otras palabras, después de la formación del vector de pronósticos, necesitamos comparar el pronóstico con etiquetas objetivo. El resultado de dicha comparación debería ser una tabla de conjugación para cada par de empresas de la muestra de formación. En la tabla de conjugación para cada par, se determinará el resultado de hacer coincidir el pronóstico con la clase de la muestra de entrenamiento. La clasificación coincidente se acepta de la siguiente manera: 'Verdadero positivo', 'Falso positivo', 'Verdadero negativo' o 'Falso negativo'. Estos datos son muy importantes para analizar el funcionamiento del algoritmo y tomar decisiones sobre cómo mejorar el modelo y el espacio de características.
El código
def contingency_table(X,features,probability_level,tridx,cvidx,model):
tr_predict_proba = model.predict_proba(X.iloc[tridx][features].values)
cv_predict_proba = model.predict_proba(X.iloc[cvidx][features].values)
tr_predict_target = (tr_predict_proba[:, 1] > probability_level).astype(np.int)
cv_predict_target = (cv_predict_proba[:, 1] > probability_level).astype(np.int)
X_tr = X.iloc[tridx]
X_cv = X.iloc[cvidx]
X_tr['predict_proba'] = tr_predict_proba[:,1]
X_cv['predict_proba'] = cv_predict_proba[:,1]
X_tr['predict_target'] = tr_predict_target
X_cv['predict_target'] = cv_predict_target
# make true positive column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false positive column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make true negative column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false negative column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
return X_tr,X_cvLa sexta función se usa para formar la matriz de conjugación. No confundir con la Mesa de Acoplamiento. Aunque uno se sigue del otro. Tu mismo veras todo mas lejos
El código
def matrix_confusion(X):
list_matrix = ['True_Positive','False_Positive','True_Negative','False_Negative']
tr_pos = X[list_matrix].sum().loc['True_Positive']
f_pos = X[list_matrix].sum().loc['False_Positive']
tr_neg = X[list_matrix].sum().loc['True_Negative']
f_neg = X[list_matrix].sum().loc['False_Negative']
matrix_confusion = pd.DataFrame()
matrix_confusion['0_algorythm'] = np.array([tr_neg,f_neg]).T
matrix_confusion['1_algorythm'] = np.array([f_pos,tr_pos]).T
matrix_confusion = matrix_confusion.rename(index={0: '0_target', 1: '1_target'})
return matrix_confusionLa séptima función está diseñada para visualizar el informe sobre el funcionamiento del algoritmo, que incluye la matriz de conjugación, los valores de la métrica precisión, recuperación, f1
El código
def report_score(tr_matrix_confusion,
cv_matrix_confusion,
data,tridx,cvidx,
X_tr,X_cv):
# print some imporatant information
print ('\033[1m'+'Matrix confusion on train data'+'\033[m')
display(tr_matrix_confusion)
print ()
print(classification_report(data.iloc[tridx]["target"].values, X_tr['predict_target']))
print ('******************************************************')
print ()
print ()
print ('\033[1m'+'Matrix confusion on test(cv) data'+'\033[m')
display(cv_matrix_confusion)
print ()
print(classification_report(data.iloc[cvidx]["target"].values, X_cv['predict_target']))
print ('******************************************************')Usando las funciones octava y novena, analizaremos la utilidad de las características para el modelo utilizado de Light GBM en términos del valor del coeficiente 'Ganancia de información' para cada característica investigada
El código
def table_gain_coef(model,features,start,stop):
data_gain = pd.DataFrame()
data_gain['Features'] = features
data_gain['Gain'] = model.booster_.feature_importance(importance_type='gain')
return data_gain.sort_values('Gain', ascending=False)[start:stop]
def gain_hist(df,size,start,stop):
fig, ax = plt.subplots(figsize=(size))
x = (df.sort_values('Gain', ascending=False)['Features'][start:stop])
y = (df.sort_values('Gain', ascending=False)['Gain'][start:stop])
plt.bar(x,y)
plt.xlabel('Features')
plt.ylabel('Gain')
plt.xticks(rotation=90)
plt.show()La décima función es necesaria para formar una matriz del número de palabras coincidentes para cada par de empresas.
Esta función también se puede utilizar para formar una matriz de palabras que NO coinciden.
El código
def compair_metrics(data):
duplicate_count = []
duplicate_sum = []
for i in range(len(data)):
count=len(data[i])
duplicate_count.append(count)
if count <= 0:
duplicate_sum.append(0)
elif count > 0:
temp_sum = 0
for j in range(len(data[i])):
temp_sum +=len(data[i][j])
duplicate_sum.append(temp_sum)
return duplicate_count,duplicate_sum La undécima función transcribe el texto ruso al alfabeto latino.
El código
def transliterate(data):
text_transliterate = []
for i in range(data.shape[0]):
temp_list = list(data[i:i+1])
temp_str = ''.join(temp_list)
result = cyrtranslit.to_latin(temp_str,'ru')
text_transliterate.append(result)
.
, , , . , ,
<spoiler title="">
<source lang="python">def rename_agg_columns(id_client,data,rename):
columns = [id_client]
for lev_0 in data.columns.levels[0]:
if lev_0 != id_client:
for lev_1 in data.columns.levels[1][:-1]:
columns.append(rename % (lev_0, lev_1))
data.columns = columns
return datareturn text_transliterate Las
funciones decimotercera y decimocuarta son necesarias para ver y generar la tabla de distancias de Levenshtein y otros indicadores importantes.
¿Qué tipo de tabla es esta en general, cuáles son las métricas y cómo está formada? Veamos cómo se forma la tabla paso a paso:
- Paso 1. Definamos qué datos necesitaremos. ID de par, acabado de palabras: ambas columnas, lista de nombres de explotación (50 empresas petroquímicas y de construcción principales).
- Paso 2. En la columna 1, en cada par de cada palabra, medimos la distancia de Levenshtein a cada palabra de la lista de nombres de tenencia, así como la longitud de cada palabra y la relación entre la distancia y la longitud.
- 3. , 0.4, id , .
- 4. , 0.4, .
- 5. , ID , — . id ( id ). .
- Paso 6. Pegue la tabla resultante con la tabla de investigación.
Una característica importante: el
cálculo lleva mucho tiempo debido al código escrito apresuradamente
El código
def dist_name_to_top_list_view(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
words1 = []
words2 = []
top_words = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist1
df['levenstein_dist_w2_top_w'] = dist2
df['length_w1_top_w'] = len(word1)
df['length_w2_top_w'] = len(word2)
df['length_top_w'] = len(top_word)
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
display(data)
print ('Words:', word1,word2,top_word)
print ('Levenstein distance:',dist1,dist2)
print ('Length of word:',len(word1),len(word2),len(top_word))
print ('Ratio (distance/length word):',ratio1,ratio2)
def dist_name_to_top_list_make(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
dist_w1 = []
dist_w2 = []
length_w1 = []
length_w2 = []
length_top_w = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
dist_w1.append(dist1)
dist_w2.append(dist2)
length_w1.append(float(len(word1)))
length_w2.append(float(len(word2)))
length_top_w.append(float(len(top_word)))
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist_w1
df['levenstein_dist_w2_top_w'] = dist_w2
df['length_w1_top_w'] = length_w1
df['length_w2_top_w'] = length_w2
df['length_top_w'] = length_top_w
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
return dataPreprocesamiento de datos
Desde mi pequeña experiencia, es el preprocesamiento de datos en el sentido amplio de esta expresión lo que lleva más tiempo. Vayamos en orden.
Cargar datos
Aquí todo es muy sencillo. Carguemos los datos y reemplacemos el nombre de la columna con la etiqueta de destino "is_duplicate" por "target". Esto es para facilitar el uso de las funciones; algunas de ellas se escribieron como parte de una investigación anterior y utilizan el nombre de la columna con la etiqueta de destino como "destino".
El código
# DOWNLOAD DATA
text_train = pd.read_csv('train.csv')
text_test = pd.read_csv('test.csv')
# RENAME DATA
text_train = text_train.rename(columns={"is_duplicate": "target"})Veamos los datos
Se cargaron los datos. Veamos cuántos objetos hay en total y qué tan equilibrados están.
El código
# ANALYSE BALANCE OF DATA
target_1 = text_train[text_train['target']==1]['target'].count()
target_0 = text_train[text_train['target']==0]['target'].count()
print ('There are', text_train.shape[0], 'objects')
print ('There are', target_1, 'objects with target 1')
print ('There are', target_0, 'objects with target 0')
print ('Balance is', round(100*target_1/target_0,2),'%')Tabla №1 "Balance de marcas"

Hay muchos objetos - casi 500 mil y no están balanceados en absoluto. Es decir, de casi 500 mil objetos, menos de 4 mil en total tienen una etiqueta de destino de 1 (menos del 1%)
Echemos un vistazo a la tabla en sí. Veamos los primeros cinco objetos etiquetados como 0 y los primeros cinco objetos etiquetados como 1.
El código
display(text_train[text_train['target']==0].head(5))
display(text_train[text_train['target']==1].head(5))Tabla No. 2 "Los primeros 5 objetos de la clase 0", tabla No. 3 "Los primeros 5 objetos de la clase 1"
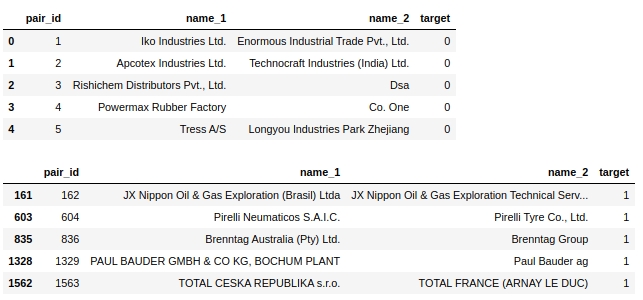
Inmediatamente se sugieren algunos pasos simples: llevar el texto a un registro, eliminar las palabras vacías, como 'ltd', eliminar países y al mismo tiempo los nombres geográficos objetos.
En realidad, algo como esto se puede resolver en este problema: realiza un procesamiento previo, se asegura de que funcione como debería, ejecuta el modelo, observa la calidad y analiza selectivamente los objetos en los que el modelo es incorrecto. Así es como hice mi investigación. Pero en el artículo en sí se da la solución final y no se comprende la calidad del algoritmo después de cada preprocesamiento, al final del artículo realizaremos un análisis final. De lo contrario, el artículo tendría un tamaño indescriptible :)
Hagamos copias
Para ser honesto, no sé por qué hago esto, pero por alguna razón siempre lo hago. Lo hare esta vez tambien
El código
baseline_train = text_train.copy()
baseline_test = text_test.copy()Convertir todos los caracteres de texto a minúsculas
El código
# convert text to lowercase
columns = ['name_1','name_2']
for column in columns:
lower_str(baseline_train,column)
for column in columns:
lower_str(baseline_test,column)Eliminar nombres de países
¡Cabe señalar que los organizadores del concurso son grandes compañeros! Junto con la tarea, entregaron una computadora portátil con una línea de base muy simple, en la que se proporcionó, incluido el código a continuación.
El código
# drop any names of countries
countries = [country.name.lower() for country in pycountry.countries]
for country in tqdm(countries):
baseline_train.replace(re.compile(country), "", inplace=True)
baseline_test.replace(re.compile(country), "", inplace=True)Eliminar letreros y caracteres especiales
El código
# drop punctuation marks
baseline_train.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_test.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_train.replace(re.compile(r"[^\w\s]"), "", inplace=True)
baseline_test.replace(re.compile(r"[^\w\s]"), "", inplace=True)Eliminar números
Eliminar los números del texto directamente en la frente, en el primer intento, estropeó en gran medida la calidad del modelo. Daré el código aquí, pero de hecho no se usó.
También tenga en cuenta que hasta este punto, hemos realizado la transformación directamente en las columnas que se nos dieron. Creemos ahora nuevas columnas para cada preprocesamiento. Habrá más columnas, pero si en alguna etapa del preprocesamiento ocurre una falla, está bien, no es necesario que haga todo desde el principio, porque tendremos columnas de cada etapa del preprocesamiento.
Código que estropea la calidad. Necesitas ser mas delicado
# # first: make dictionary of frequency every word
# list_words = baseline_train['name_1'].to_string(index=False).split() +\
# baseline_train['name_2'].to_string(index=False).split()
# freq_words = {}
# for w in list_words:
# freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame of frequency words
# df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
# df_freq.columns = ['word','frequency']
# df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
# df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
# df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
# # third: make drop list of digits
# string = df_freq_agg['word'].to_string(index=False)
# digits = [int(digit) for digit in string.split() if digit.isdigit()]
# digits = set(digits)
# digits = list(digits)
# # drop the digits
# baseline_train['name_1_no_digits'] =\
# baseline_train['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_train['name_2_no_digits'] =\
# baseline_train['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_1_no_digits'] =\
# baseline_test['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_2_no_digits'] =\
# baseline_test['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))Eliminemos ... la primera lista de palabras vacías. ¡A mano!
Ahora se sugiere definir y eliminar palabras vacías de la lista de palabras en los nombres de las empresas.
Hemos compilado la lista basada en la revisión manual de la muestra de capacitación. Lógicamente, dicha lista debería compilarse automáticamente utilizando los siguientes enfoques:
- Primero, use las 10 palabras más comunes (20,50,100).
- en segundo lugar, utilizar bibliotecas estándar de palabras vacías en diferentes idiomas. Por ejemplo, designaciones de formas organizativas y legales de organizaciones en varios idiomas (LLC, PJSC, CJSC, ltd, gmbh, inc, etc.)
- En tercer lugar, tiene sentido compilar una lista de nombres de lugares en diferentes idiomas.
Regresaremos a la primera opción para compilar automáticamente una lista de las palabras más frecuentes, pero por ahora estamos viendo el preprocesamiento manual.
El código
# drop some stop-words
drop_list = ["ltd.", "co.", "inc.", "b.v.", "s.c.r.l.", "gmbh", "pvt.",
'retail','usa','asia','ceska republika','limited','tradig','llc','group',
'international','plc','retail','tire','mills','chemical','korea','brasil',
'holding','vietnam','tyre','venezuela','polska','americas','industrial','taiwan',
'europe','america','north','czech republic','retailers','retails',
'mexicana','corporation','corp','ltd','co','toronto','nederland','shanghai','gmb','pacific',
'industries','industrias',
'inc', 'ltda', '', '', '', '', '', '', '', '', 'ceska republika', 'ltda',
'sibur', 'enterprises', 'electronics', 'products', 'distribution', 'logistics', 'development',
'technologies', 'pvt', 'technologies', 'comercio', 'industria', 'trading', 'internacionais',
'bank', 'sports',
'express','east', 'west', 'south', 'north', 'factory', 'transportes', 'trade', 'banco',
'management', 'engineering', 'investments', 'enterprise', 'city', 'national', 'express', 'tech',
'auto', 'transporte', 'technology', 'and', 'central', 'american',
'logistica','global','exportacao', 'ceska republika', 'vancouver', 'deutschland',
'sro','rus','chemicals','private','distributors','tyres','industry','services','italia','beijing',
'','company','the','und']
baseline_train['name_1_non_stop_words'] =\
baseline_train['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_non_stop_words'] =\
baseline_train['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_non_stop_words'] =\
baseline_test['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_non_stop_words'] =\
baseline_test['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))Comprobemos selectivamente que nuestras palabras vacías se hayan eliminado del texto.
El código
baseline_train[baseline_train.name_1_non_stop_words.str.contains("factory")].head(3)Tabla 4 "Verificación selectiva del código para eliminar palabras

vacías " Todo parece funcionar. Se eliminaron todas las palabras vacías que están separadas por un espacio. Lo que queríamos. Hacia adelante.
Transliteremos el texto ruso al alfabeto latino
Utilizo mi función de auto-escritura y la biblioteca cyrtranslit para esto. Parece funcionar. Comprobado manualmente.
El código
# transliteration to latin
baseline_train['name_1_transliterated'] = transliterate(baseline_train['name_1_non_stop_words'])
baseline_train['name_2_transliterated'] = transliterate(baseline_train['name_2_non_stop_words'])
baseline_test['name_1_transliterated'] = transliterate(baseline_test['name_1_non_stop_words'])
baseline_test['name_2_transliterated'] = transliterate(baseline_test['name_2_non_stop_words'])Veamos un par con id 353150. En él, la segunda columna ("name_2") tiene la palabra "Michelin", después de preprocesar la palabra ya está escrita así "mishlen" (ver la columna "name_2_transliterated"). No del todo correcto, pero claramente mejor.
El código
pair_id = 353150
baseline_train[baseline_train['pair_id']==353150]Tabla número 5 "Verificación selectiva del código para transliteración"

Comencemos la compilación automática de la lista de las 50 palabras más frecuentes y suéltelo de manera inteligente. Primer CHIT
Un título un poco complicado. Echemos un vistazo a lo que vamos a hacer aquí.
Primero, combinaremos el texto de la primera y segunda columnas en una matriz y contaremos para cada palabra única el número de veces que ocurre.
En segundo lugar, escojamos las 50 primeras de estas palabras. Y parecería que puedes borrarlos, pero no. Estas palabras pueden contener los nombres de las existencias ('total', 'knauf', 'shell', ...), pero esta es información muy importante y no se puede perder, ya que la usaremos más. Por lo tanto, apostaremos por un truco de trampa (prohibido). Para empezar, sobre la base de un estudio cuidadoso y selectivo de la muestra de formación, compilaremos una lista de los nombres de las explotaciones encontradas con frecuencia. La lista no estará completa, de lo contrario no sería nada justo :) Aunque, ya que no estamos persiguiendo un premio, ¿por qué no? Luego compararemos la matriz de las 50 palabras más comunes con la lista de nombres de existencias y eliminaremos de la lista las palabras que coincidan con los nombres de las existencias.
La segunda lista de palabras vacías ahora está completa. Puede eliminar palabras del texto.
Pero antes de eso, me gustaría insertar un pequeño comentario sobre la lista de trampas de nombres de tenencia. El hecho de que hayamos compilado una lista de los nombres de las explotaciones basándonos en observaciones nos hizo la vida mucho más fácil. Pero, de hecho, podríamos haber compilado esa lista de otra manera. Por ejemplo, puede tomar las calificaciones de las empresas más grandes de las industrias petroquímica, de construcción, automotriz y otras, combinarlas y tomar los nombres de las participaciones a partir de ahí. Pero para los propósitos de nuestra investigación, nos limitaremos a un enfoque simple. ¡Este enfoque está prohibido en la competencia! Además, los organizadores del concurso, el trabajo de los candidatos a los lugares premiados son controlados por técnicas prohibidas. ¡Ten cuidado!
El código
list_top_companies = ['arlanxeo', 'basf', 'bayer', 'bdp', 'bosch', 'brenntag', 'contitech',
'daewoo', 'dow', 'dupont', 'evonik', 'exxon', 'exxonmobil', 'freudenberg',
'goodyear', 'goter', 'henkel', 'hp', 'hyundai', 'isover', 'itochu', 'kia', 'knauf',
'kraton', 'kumho', 'lusocopla', 'michelin', 'paul bauder', 'pirelli', 'ravago',
'rehau', 'reliance', 'sabic', 'sanyo', 'shell', 'sherwinwilliams', 'sojitz',
'soprema', 'steico', 'strabag', 'sumitomo', 'synthomer', 'synthos',
'total', 'trelleborg', 'trinseo', 'yokohama']
# drop top 50 common words (NAME 1 & NAME 2) exept names of top companies
# first: make dictionary of frequency every word
list_words = baseline_train['name_1_transliterated'].to_string(index=False).split() +\
baseline_train['name_2_transliterated'].to_string(index=False).split()
freq_words = {}
for w in list_words:
freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame
df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
df_freq.columns = ['word','frequency']
df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
drop_list = list(set(df_freq_agg[0:50]['word'].to_string(index=False).split()) - set(list_top_companies))
# # check list of top 50 common words
# print (drop_list)
# drop the top 50 words
baseline_train['name_1_finish'] =\
baseline_train['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_finish'] =\
baseline_train['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_finish'] =\
baseline_test['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_finish'] =\
baseline_test['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
Aquí es donde terminamos con el preprocesamiento de datos. Comencemos a generar nuevas características y a evaluarlas visualmente para determinar la capacidad de separar objetos por 0 o 1.
Generación y análisis de características
Calculemos la distancia de Levenshtein
Usemos la biblioteca strsimpy y en cada par (después de todo el preprocesamiento) calcularemos la distancia de Levenshtein desde el nombre de la empresa desde la primera columna hasta el nombre de la empresa en la segunda columna.
El código
# create feature with LEVENSTAIN DISTANCE
levenshtein = Levenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["levenstein"] = baseline_train.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)
baseline_test["levenstein"] = baseline_test.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)Calculemos la distancia de Levenshtein normalizada
Todo es igual que arriba, solo contaremos la distancia normalizada.
Encabezado de spoiler
# create feature with NORMALIZATION LEVENSTAIN DISTANCE
normalized_levenshtein = NormalizedLevenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["norm_levenstein"] = baseline_train.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)
baseline_test["norm_levenstein"] = baseline_test.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)Contamos y ahora visualizamos
Visualización de características
Veamos la distribución del rasgo 'levenstein'
El código
data = baseline_train
analyse = 'levenstein'
size = (12,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Gráficos nº1 "Histograma y cuadro con bigote para evaluar la importancia de una característica"
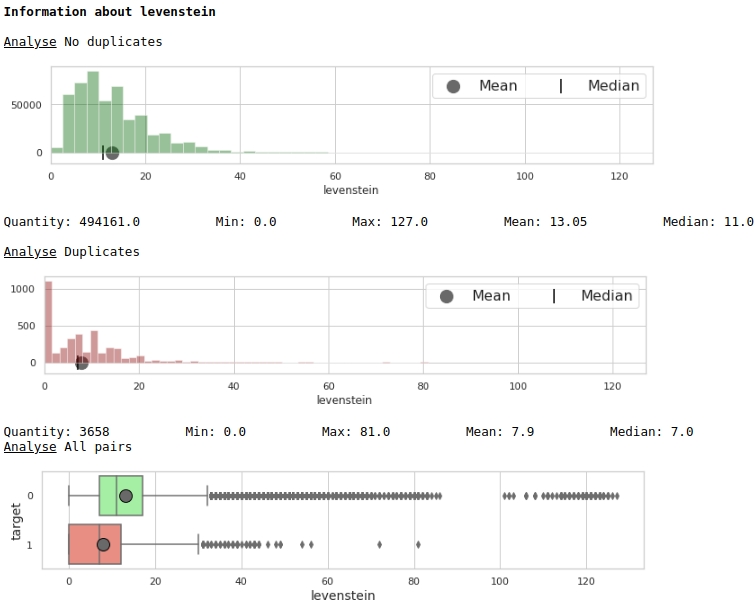
A primera vista, una métrica puede marcar datos. Obviamente no es muy bueno, pero se puede utilizar.
Veamos la distribución del rasgo 'norm_levenstein'
Encabezado de spoiler
data = baseline_train
analyse = 'norm_levenstein'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Gráficos №2 "Histograma y recuadro con bigote para valorar el significado del signo"

Ya mejor. Ahora, echemos un vistazo a cómo las dos características combinadas dividirán el espacio en los objetos 0 y 1.
El código
data = baseline_train
analyse1 = 'levenstein'
analyse2 = 'norm_levenstein'
size = (14,6)
two_features(data,analyse1,analyse2,size)Gráfico # 3 "Diagrama de dispersión"
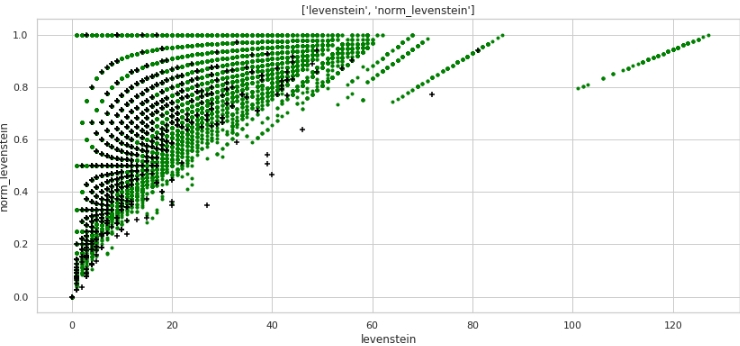
Se obtiene un marcado muy bueno. Así que no es por nada que preprocesamos tanto los datos :)
Todo el mundo entiende que horizontalmente, los valores de la métrica "levenstein" y verticalmente, los valores de la métrica "norm_levenstein", y los puntos verde y negro son los objetos 0 y 1. Sigamos adelante.
Comparemos palabras en el texto para cada par y generemos una gran cantidad de características
A continuación, compararemos las palabras en los nombres de las empresas. Creemos las siguientes características:
- una lista de palabras que están duplicadas en las columnas # 1 y # 2 de cada par
- una lista de palabras que NO están duplicadas
Basándonos en estas listas de palabras, creemos características que incorporemos al modelo entrenado:
- número de palabras duplicadas
- número de palabras NO duplicadas
- suma de caracteres, palabras duplicadas
- suma de caracteres, NO palabras duplicadas
- longitud promedio de palabras duplicadas
- longitud promedio de palabras NO duplicadas
- la relación entre el número de duplicados y el número de NO duplicados
El código aquí probablemente no sea muy amigable, ya que, nuevamente, fue escrito apresuradamente. Pero funciona, pero servirá para una investigación rápida.
El código
# make some information about duplicates and differences for TRAIN
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_train.shape[0]):
list1 = list(baseline_train[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_train[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TRAIN
baseline_train['duplicate'] = duplicates
baseline_train['difference'] = difference
baseline_train['duplicate_count'] = duplicate_count
baseline_train['duplicate_sum'] = duplicate_sum
baseline_train['duplicate_mean'] = baseline_train['duplicate_sum'] / baseline_train['duplicate_count']
baseline_train['duplicate_mean'] = baseline_train['duplicate_mean'].fillna(0)
baseline_train['dif_count'] = dif_count
baseline_train['dif_sum'] = dif_sum
baseline_train['dif_mean'] = baseline_train['dif_sum'] / baseline_train['dif_count']
baseline_train['dif_mean'] = baseline_train['dif_mean'].fillna(0)
baseline_train['ratio_duplicate/dif_count'] = baseline_train['duplicate_count'] / baseline_train['dif_count']
# make some information about duplicates and differences for TEST
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_test.shape[0]):
list1 = list(baseline_test[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_test[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TEST
baseline_test['duplicate'] = duplicates
baseline_test['difference'] = difference
baseline_test['duplicate_count'] = duplicate_count
baseline_test['duplicate_sum'] = duplicate_sum
baseline_test['duplicate_mean'] = baseline_test['duplicate_sum'] / baseline_test['duplicate_count']
baseline_test['duplicate_mean'] = baseline_test['duplicate_mean'].fillna(0)
baseline_test['dif_count'] = dif_count
baseline_test['dif_sum'] = dif_sum
baseline_test['dif_mean'] = baseline_test['dif_sum'] / baseline_test['dif_count']
baseline_test['dif_mean'] = baseline_test['dif_mean'].fillna(0)
baseline_test['ratio_duplicate/dif_count'] = baseline_test['duplicate_count'] / baseline_test['dif_count']
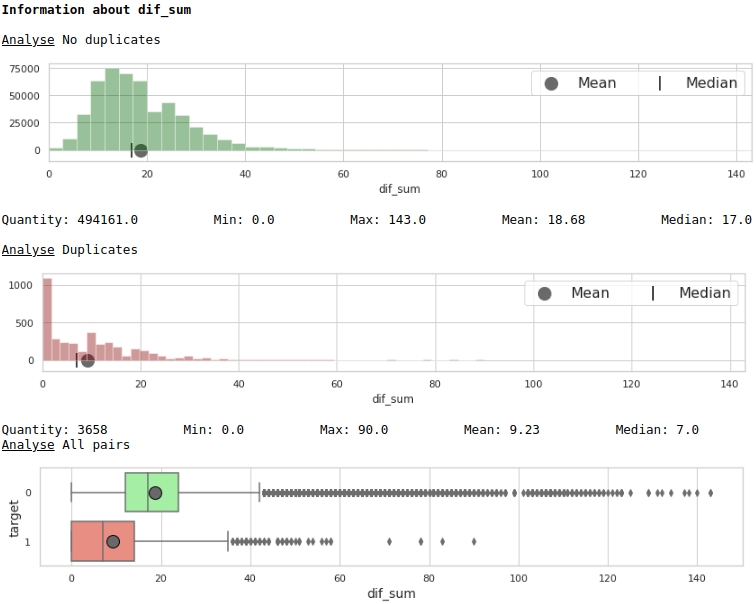
Visualizamos algunos de los signos.
El código
data = baseline_train
analyse = 'dif_sum'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)Gráficos nº 4 "Histograma y recuadro con bigote para valorar el significado del signo"
El código
data = baseline_train
analyse1 = 'duplicate_mean'
analyse2 = 'dif_mean'
size = (14,6)
two_features(data,analyse1,analyse2,size)Gráfico №5 "Diagrama de dispersión"
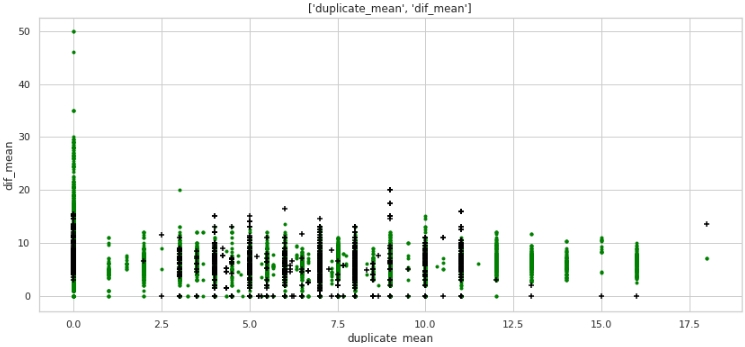
Lo que no, pero el marcado. Tenga en cuenta que muchas empresas con una etiqueta de destino de 1 tienen cero duplicados en el texto, y también muchas empresas con duplicados en sus nombres, en promedio más de 12 palabras, pertenecen a empresas con una etiqueta de destino de 0.
Echemos un vistazo a los datos tabulares, prepare una consulta para En el primer caso: no hay duplicados en el nombre de las empresas, pero las empresas son las mismas.
El código
baseline_train[
baseline_train['duplicate_mean']==0][
baseline_train['target']==1].drop(
['duplicate', 'difference',
'name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated'],axis=1)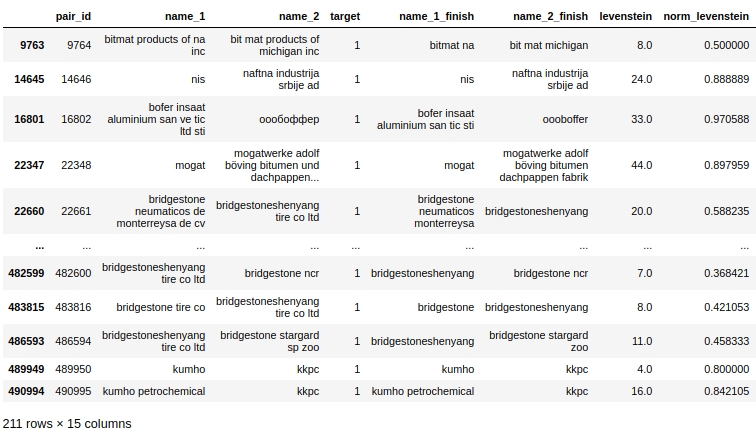
Obviamente hay un error del sistema en nuestro procesamiento. No hemos tenido en cuenta que las palabras pueden escribirse no solo con errores, sino también simplemente juntas o, por el contrario, por separado cuando no sea necesario. Por ejemplo, el par # 9764. En la primera columna 'bitmat' en la segunda 'bit mat' y ahora esto no es un doble, pero la empresa es la misma. U otro ejemplo, emparejar # 482600 'bridgestoneshenyang' y 'bridgestone'.
¿Qué se podría hacer? Lo primero que se me ocurrió fue comparar no directamente de frente, sino utilizando la métrica de Levenshtein. Pero aquí también nos espera una emboscada: la distancia entre 'bridgestoneshenyang' y 'bridgestone' no será pequeña. Quizás la lematización venga al rescate, pero nuevamente no está claro de inmediato cómo se pueden lematizar los nombres de las empresas. O puede usar el coeficiente de Tamimoto, pero dejemos este momento para camaradas más experimentados y sigamos adelante.
Comparemos las palabras del texto con las palabras de los nombres de las 50 principales marcas de holding en las industrias petroquímica, de la construcción y otras. Consigamos el segundo gran grupo de características. Segundo CHIT
De hecho, existen dos infracciones a las reglas para participar en la competencia:
- -, , «duplicate_name_company»
- -, . , .
Ambas técnicas están prohibidas por las reglas de la competencia. Puede evitar la prohibición. Para hacer esto, es necesario compilar una lista de nombres de existencias no manualmente en función de una vista selectiva de la muestra de entrenamiento, sino automáticamente de fuentes externas. Pero luego, en primer lugar, la lista de existencias resultará ser grande y la comparación de palabras propuestas en el trabajo llevará muy, bueno, solo mucho tiempo, y en segundo lugar, esta lista aún debe compilarse :) Por lo tanto, para simplificar la investigación, verificaremos cuánto mejorará la calidad del modelo con estos signos. Avanzando - ¡la calidad está creciendo increíblemente!
Con el primer método, todo parece estar claro, pero el segundo enfoque requiere explicaciones.
Entonces, determinemos la distancia de Levenshtein desde cada palabra en cada línea de la primera columna con el nombre de la empresa hasta cada palabra de la lista de las principales empresas petroquímicas (y no solo).
Si la relación entre la distancia de Levenshtein y la longitud de la palabra es menor o igual a 0,4, determinamos la relación entre la distancia de Levenshtein y la palabra seleccionada de la lista de empresas principales para cada palabra de la segunda columna: el nombre de la segunda empresa.
Si el segundo coeficiente (la relación entre la distancia y la longitud de la palabra de la lista de las principales empresas) es menor o igual a 0,4, fijamos los siguientes valores en la tabla:
- Distancia de Levenshtein de una palabra de la lista de empresas número 1 a una palabra de la lista de empresas principales
- Distancia de Levenshtein de una palabra de la lista de empresas número 2 a una palabra de la lista de empresas principales
- longitud de una palabra de la lista # 1
- longitud de una palabra de la lista # 2
- longitud de palabra de la lista de las principales empresas
- la relación entre la longitud de una palabra de la lista # 1 y la distancia
- la relación entre la longitud de una palabra de la lista No. 2 y la distancia
Puede haber más de una coincidencia en una línea, elijamos el mínimo de ellas (función de agregación).
Me gustaría llamar su atención una vez más sobre el hecho de que el método propuesto para generar características consume muchos recursos y, en caso de obtener una lista de una fuente externa, se requerirá un cambio en el código para compilar métricas.
El código
# create information about duplicate name of petrochemical companies from top list
list_top_companies = list_top_companies
dp_train = []
for i in list(baseline_train['duplicate']):
dp_train.append(''.join(list(set(i) & set(list_top_companies))))
dp_test = []
for i in list(baseline_test['duplicate']):
dp_test.append(''.join(list(set(i) & set(list_top_companies))))
baseline_train['duplicate_name_company'] = dp_train
baseline_test['duplicate_name_company'] = dp_test
# replace name duplicate to number
baseline_train['duplicate_name_company'] =\
baseline_train['duplicate_name_company'].replace('',0,regex=True)
baseline_train.loc[baseline_train['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
baseline_test['duplicate_name_company'] =\
baseline_test['duplicate_name_company'].replace('',0,regex=True)
baseline_test.loc[baseline_test['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
# create some important feature about similar words in the data and names of top companies for TRAIN
# (levenstein distance, length of word, ratio distance to length)
baseline_train = dist_name_to_top_list_make(baseline_train,
'name_1_finish','name_2_finish',list_top_companies)
# create some important feature about similar words in the data and names of top companies for TEST
# (levenstein distance, length of word, ratio distance to length)
baseline_test = dist_name_to_top_list_make(baseline_test,
'name_1_finish','name_2_finish',list_top_companies)
Veamos la utilidad de las funciones a través del prisma de los gráficos.
El código
data = baseline_train
analyse = 'levenstein_dist_w1_top_w_min'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)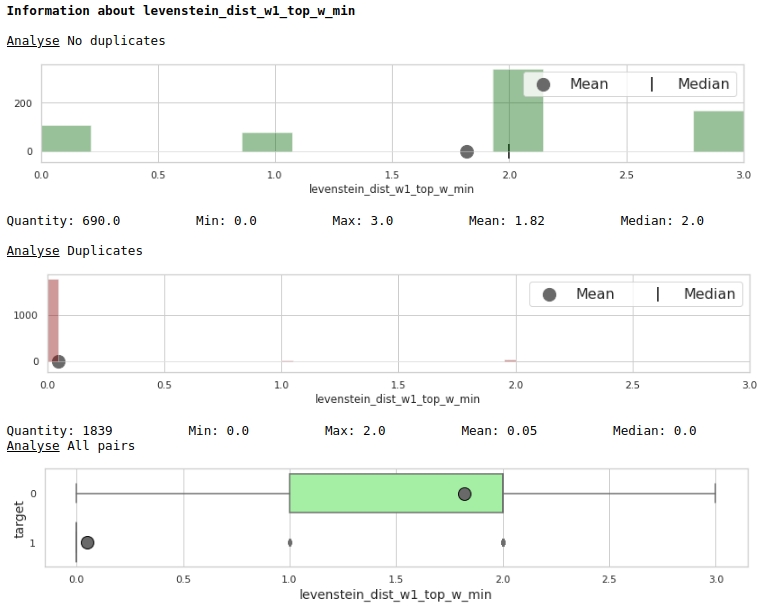
Muy bien.
Preparar datos para enviarlos al modelo
Tenemos una tabla grande y no necesitamos todos los datos para el análisis. Veamos los nombres de las columnas de la tabla.
El código
baseline_train.columns
Seleccionemos aquellas columnas que analizaremos.
Arreglemos la semilla para la reproducibilidad del resultado.
El código
# fix some parameters
features = ['levenstein','norm_levenstein',
'duplicate_count','duplicate_sum','duplicate_mean',
'dif_count','dif_sum','dif_mean','ratio_duplicate/dif_count',
'duplicate_name_company',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min'
]
seed = 42Antes de entrenar finalmente el modelo con todos los datos disponibles y enviar la solución para su verificación, tiene sentido probar el modelo. Para hacer esto, dividimos el conjunto de entrenamiento en entrenamiento condicional y prueba condicional. Mediremos la calidad en él y si nos conviene enviaremos la solución a la competencia.
El código
# provides train/test indices to split data in train/test sets
split = StratifiedShuffleSplit(n_splits=1, train_size=0.8, random_state=seed)
tridx, cvidx = list(split.split(baseline_train[features],
baseline_train["target"]))[0]
print ('Split baseline data train',baseline_train.shape[0])
print (' - new train data:',tridx.shape[0])
print (' - new test data:',cvidx.shape[0])Configurar y entrenar el modelo
Usaremos el árbol de decisiones de la biblioteca Light GBM como modelo.
No tiene sentido ajustar demasiado los parámetros. Miramos el código.
El código
# learning Light GBM Classificier
seed = 50
params = {'n_estimators': 1,
'objective': 'binary',
'max_depth': 40,
'min_child_samples': 5,
'learning_rate': 1,
# 'reg_lambda': 0.75,
# 'subsample': 0.75,
# 'colsample_bytree': 0.4,
# 'min_split_gain': 0.02,
# 'min_child_weight': 40,
'random_state': seed}
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train.iloc[tridx][features].values,
baseline_train.iloc[tridx]["target"].values)El modelo fue afinado y entrenado. Ahora veamos los resultados.
El código
# make predict proba and predict target
probability_level = 0.99
X = baseline_train
tridx = tridx
cvidx = cvidx
model = model
X_tr, X_cv = contingency_table(X,features,probability_level,tridx,cvidx,model)
train_matrix_confusion = matrix_confusion(X_tr)
cv_matrix_confusion = matrix_confusion(X_cv)
report_score(train_matrix_confusion,
cv_matrix_confusion,
baseline_train,
tridx,cvidx,
X_tr,X_cv)
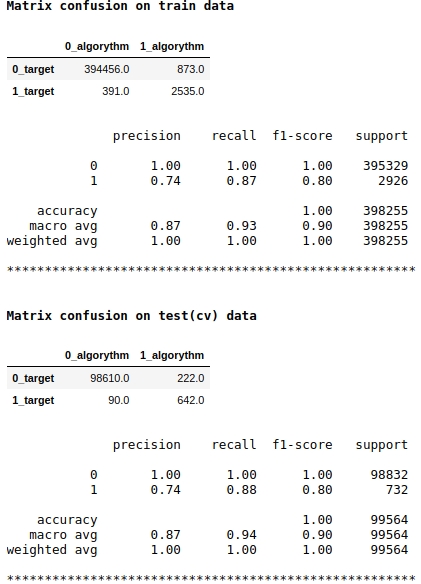
Tenga en cuenta que estamos utilizando la métrica de calidad f1 como puntuación del modelo. Esto significa que tiene sentido regular el nivel de probabilidad de asignar un objeto a la clase 1 o 0. Hemos elegido el nivel de 0,99, es decir, si la probabilidad es igual o superior a 0,99, el objeto se asignará a la clase 1, por debajo de 0,99 - a la clase 0. Este es un punto importante - puede mejorar significativamente la velocidad un truco tan simple, no complicado.
La calidad no parece mala. En una muestra de prueba condicional, el algoritmo cometió errores al definir 222 objetos de la clase 0 y en 90 objetos pertenecientes a la clase 0 cometió un error y los asignó a la clase 1 (consulte Confusión de matriz en datos de prueba (cv)).
Veamos qué signos fueron los más importantes y cuáles no.
El código
start = 0
stop = 50
size = (12,6)
tg = table_gain_coef(model,features,start,stop)
gain_hist(tg,size,start,stop)
display(tg)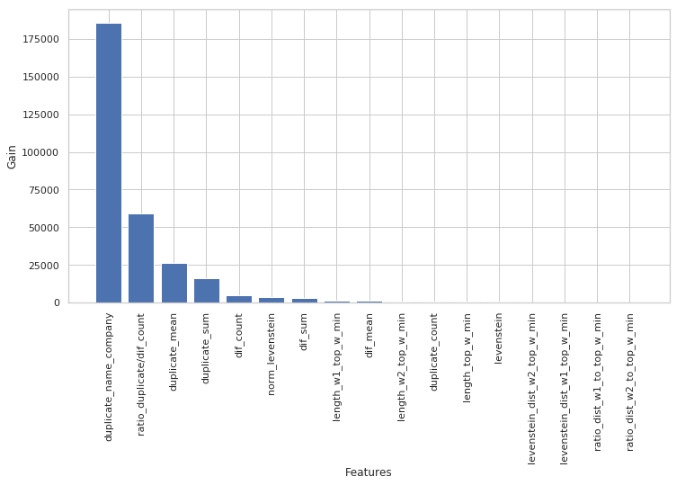
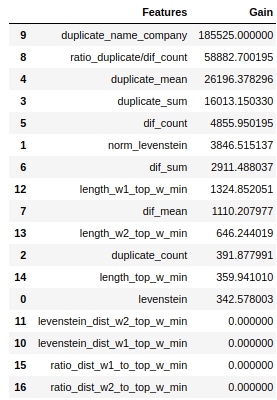
Tenga en cuenta que usamos el parámetro 'ganancia', no el parámetro 'dividir' para evaluar la importancia de las características. Esto es importante porque en una versión muy simplificada, el primer parámetro significa la contribución de la característica a la disminución de la entropía, y el segundo indica cuántas veces se usó la característica para marcar el espacio.
A primera vista, la función que hemos estado haciendo durante mucho tiempo, "levenstein_dist_w1_top_w_min", resultó no ser informativa en absoluto: su contribución es 0. Pero esto es solo a primera vista. Tiene un significado casi completamente duplicado con el atributo "duplicate_name_company". Si elimina "duplicate_name_company" y deja "levenstein_dist_w1_top_w_min", entonces la segunda característica tomará el lugar de la primera y la calidad no cambiará. ¡Comprobado!
En general, un letrero de este tipo es útil, especialmente cuando tiene cientos de características y un modelo con un montón de campanas y silbidos y 5000 iteraciones. Puede eliminar características en lotes y ver cómo crece la calidad de esta acción no astuta. En nuestro caso, la eliminación de funciones no afectará la calidad.
Echemos un vistazo a la mesa de mate. En primer lugar, veamos los objetos "Falso Positivo", es decir, aquellos que nuestro algoritmo determinó que eran iguales y los asignó a la clase 1, pero en realidad pertenecen a la clase 0.
El código
X_cv[X_cv['False_Positive']==1][0:50].drop(['name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated', 'duplicate', 'difference',
'levenstein',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min',
'True_Positive','True_Negative','False_Negative'],axis=1)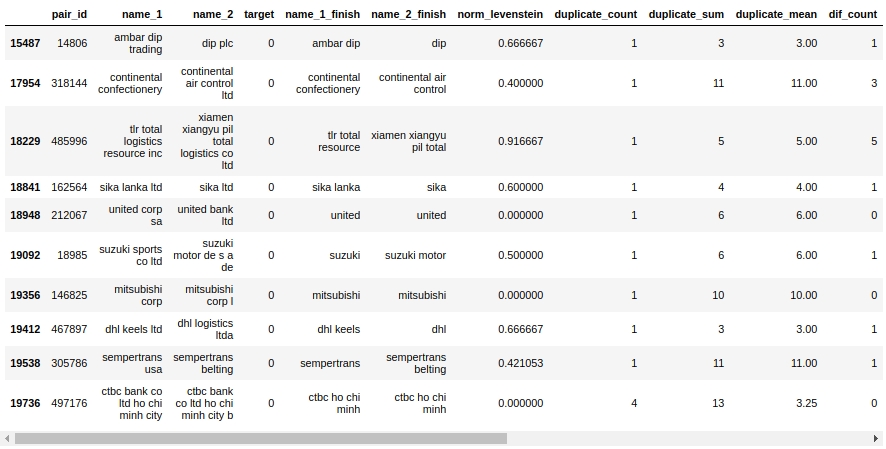
Si. Aquí, una persona no determinará inmediatamente 0 o 1. Por ejemplo, el par # 146825 "mitsubishi corp" y "mitsubishi corp l". Los ojos dicen que es lo mismo, pero la muestra dice que son empresas diferentes. ¿A quién creer?
Digamos que podrías salir de inmediato, nosotros lo hicimos. Dejaremos el resto del trabajo a camaradas experimentados :)
Carguemos los datos en el sitio web del organizador y averigüemos la valoración de la calidad del trabajo.
Resultados de la competencia
El código
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train[features].values,
baseline_train["target"].values)
sample_sub = pd.read_csv('sample_submission.csv', index_col="pair_id")
sample_sub['is_duplicate'] = (model.predict_proba(
baseline_test[features].values)[:, 1] > probability_level).astype(np.int)
sample_sub.to_csv('baseline_submission.csv')
Entonces, nuestro ayuno, teniendo en cuenta el método prohibido: 0.5999
Sin él, la calidad estaba entre 0.3 y 0.4. Necesitamos reiniciar el modelo para mayor precisión, pero soy un poco vago :)
Resumamos mejor la experiencia.
Primero, como puede ver, tenemos un código bastante reproducible y una estructura de archivos bastante adecuada. Debido a mi poca experiencia, una vez llené muchos baches precisamente porque estaba completando el trabajo a toda prisa, solo para conseguir una velocidad más o menos agradable. Como resultado, el archivo resultó ser tal que después de una semana ya daba miedo abrirlo, nada es tan claro. Por lo tanto, mi mensaje es: escriba el código de inmediato y haga que el archivo sea legible, de modo que en un año pueda volver a los datos, observe la estructura primero, comprenda qué pasos se tomaron y luego para que cada paso pueda desmontarse fácilmente. Por supuesto, si es un principiante, en el primer intento, el archivo no será hermoso, el código se romperá, habrá muletas, pero si periódicamente reescribe el código durante el proceso de investigación,luego, entre 5 y 7 veces de reescritura, usted mismo se sorprenderá de lo más limpio que es el código y tal vez incluso encuentre errores y mejore la velocidad. No te olvides de las funciones, hace que el archivo sea muy fácil de leer.
En segundo lugar, después de cada procesamiento de los datos, verifique si todo salió como se esperaba. Para hacer esto, necesita poder filtrar tablas en pandas. Hay mucho filtrado en este trabajo, úsalo para la salud :)
En tercer lugar, siempre, francamente siempre, en las tareas de clasificación, forme tanto una tabla como una matriz de conjugación. En la tabla, puede encontrar fácilmente en qué objetos el algoritmo es incorrecto. Para empezar, trate de notar esos errores que se llaman errores del sistema, requieren menos trabajo para corregirlos y dan más resultados. Luego, tan pronto como solucione los errores del sistema, vaya a casos especiales. Por la matriz de errores, verá dónde el algoritmo comete más errores: en la clase 0 o 1. A partir de aquí excavará los errores. Por ejemplo, noté que mi árbol define bien las clases 1, pero comete muchos errores en la clase 0, es decir, el árbol a menudo "dice" que este objeto es de clase 1, cuando en realidad es 0. Supuse que podría ser asociado con el nivel de probabilidad de clasificar un objeto como 0 o 1. Mi nivel se fijó en 0,9.El aumento en el nivel de probabilidad de asignar un objeto a la clase 1 a 0,99 hizo que la selección de objetos de la clase 1 fuera más difícil y listo: nuestra velocidad ha dado un aumento significativo.
Una vez más, señalaré que el propósito de participar en el concurso no era ganar un premio, sino ganar experiencia. Teniendo en cuenta que antes del inicio de la competencia, no tenía idea de cómo trabajar con textos en aprendizaje automático, y como resultado, en unos días obtuve un modelo simple, pero aún funcional, entonces podemos decir que el objetivo se logró. Además, para cualquier samurái novato en el mundo de la ciencia de datos, creo que es importante ganar experiencia, no un premio, o más bien la experiencia es el premio. Por lo tanto, no tengas miedo de participar en concursos, hazlo, ¡todos son un castor!
En el momento de la publicación del artículo, el concurso aún no ha terminado. Con base en los resultados de la finalización de la competencia, en los comentarios al artículo, escribiré sobre la velocidad máxima justa, sobre los enfoques y características que mejoran la calidad del modelo.
Y eres un querido lector, si tienes ideas sobre cómo aumentar la velocidad ahora mismo, escribe en los comentarios. Haz una buena acción :)
Fuentes de información, materiales auxiliares
- "Data Github y Jupyter Notebook"
- "Plataforma de Concursos SIBUR CHALLENGE 2020"
- "Sitio del organizador del concurso SIBUR CHALLENGE 2020"
- "Buen artículo sobre Habré" Fundamentos del procesamiento del lenguaje natural para texto ""
- "Otro buen artículo sobre Habré" Comparación de cadenas difusas: entiéndeme si puedes ""
- "Publicación de la revista APNI"
- "Un artículo sobre el coeficiente de Tanimoto" Similitud de cadenas "no se utiliza aquí"