LightGBM amplía el algoritmo Gradient Boosting agregando un tipo de selección automática de objetos y centrándose en ejemplos de refuerzo con gradientes grandes. Esto puede conducir a una aceleración dramática del aprendizaje y un mejor desempeño predictivo. Por lo tanto, LightGBM se ha convertido en el algoritmo de facto para las competencias de aprendizaje automático cuando se trabaja con datos tabulares para problemas de modelado predictivo de regresión y clasificación. En este tutorial, aprenderá a diseñar conjuntos de máquinas mejoradas con gradiente ligero para clasificación y regresión. Después de completar este tutorial, sabrá:
- Light Gradient Boosted Machine (LightGBM) es una implementación eficiente de código abierto del conjunto de aumento de gradiente estocástico.
- Cómo desarrollar conjuntos LightGBM para clasificación y regresión usando la API scikit-learn.
- LightGBM .

- LightBLM.
- Scikit-Learn API LightGBM.
— LightGBM .
— LightGBM . - LightGBM.
— .
— .
— .
— .
LightBLM
El aumento de gradiente se refiere a una clase de algoritmos de aprendizaje automático conjuntos que se pueden usar para problemas de clasificación o modelos de regresión predictiva.
Los conjuntos se crean basándose en modelos de árboles de decisión. Los árboles se agregan uno a la vez al conjunto y se entrenan para corregir los errores de predicción cometidos por los modelos anteriores. Este es un tipo de modelo de aprendizaje automático conjunto llamado impulso.
Los modelos se entrenan utilizando cualquier función de pérdida diferenciable arbitraria y un algoritmo de optimización de descenso de gradiente. Esto le da al método su nombre "aumento de gradiente" porque el gradiente de pérdida se minimiza a medida que se entrena el modelo, como una red neuronal. Para obtener más información sobre el aumento de gradiente, consulte el tutorial:"Una suave introducción al algoritmo de aumento de gradiente ML" .
LightGBM es una implementación de código abierto de aumento de gradiente diseñada para ser eficiente, e incluso posiblemente más eficiente que otras implementaciones.
Como tal, LightGBM es un proyecto de código abierto, una biblioteca de software y un algoritmo de aprendizaje automático. Es decir, el proyecto es muy similar a la técnica Extreme Gradient Boosting o XGBoost .
LightGBM ha sido descrito por Golin, K., et al. Para obtener más información, consulte un artículo de 2017 titulado "LightGBM: un árbol de decisiones de aumento de gradientes altamente eficiente" . La implementación presenta dos ideas clave: GOSS y EFB.
El muestreo de gradiente unidireccional (GOSS) es una modificación de Gradient Boosting que se centra en los tutoriales que dan como resultado un gradiente más grande, lo que a su vez acelera el aprendizaje y reduce la complejidad computacional del método.
Con GOSS, excluimos una parte significativa de las instancias de datos con pequeños gradientes y usamos solo el resto de las instancias de datos para estimar la ganancia de información. Argumentamos que debido a que las instancias de datos con grandes gradientes juegan un papel más importante en el cálculo de la ganancia de información, GOSS puede obtener una estimación bastante precisa de la ganancia de información con un tamaño de datos mucho más pequeño.
El paquete de características exclusivas, o EFB, es un enfoque que combina características escasas (en su mayoría cero) mutuamente excluyentes, como variables de entrada categóricas codificadas con una codificación unitaria. Por tanto, es un tipo de selección automática de funciones.
... empaquetamos características mutuamente excluyentes (es decir, rara vez toman valores distintos de cero al mismo tiempo) para reducir la cantidad de características.
Juntos, estos dos cambios pueden acelerar el tiempo de entrenamiento del algoritmo hasta 20 veces. Por lo tanto, LightGBM se puede considerar como árboles de decisión mejorados por gradientes (GBDT) con la adición de GOSS y EFB.
A nuestra nueva implementación de GBDT la llamamos GOSS y EFB LightGBM. Nuestros experimentos en varios conjuntos de datos disponibles públicamente muestran que LightGBM acelera el proceso de aprendizaje de un GBDT convencional en más de 20 veces, logrando casi la misma precisión.
API de Scikit-Learn para LightGBM
LightGBM se puede instalar como una biblioteca independiente y el modelo LightGBM se puede desarrollar utilizando la API scikit-learn.
El primer paso es instalar la biblioteca LightGBM. En la mayoría de las plataformas, se puede hacer usando el administrador de paquetes pip; p.ej:
sudo pip install lightgbmPuede verificar la instalación y la versión de esta manera:
# check lightgbm version
import lightgbm
print(lightgbm.__version__)El script mostrará la versión de LightGBM instalada. Tu versión debe ser igual o superior. Si no es así, actualice LightGBM. Si necesita instrucciones específicas para su entorno de desarrollo, consulte el tutorial: Guía de instalación de LightGBM .
La biblioteca LightGBM tiene su propia API, aunque estamos usando un método a través de las clases contenedoras de scikit-learn: LGBMRegressor y LGBMClassifier . Esto permitirá que toda la biblioteca de aprendizaje automático scikit-learn se utilice para la preparación de datos y la evaluación de modelos.
Ambos modelos funcionan de la misma manera y usan los mismos argumentos para influir en cómo se crean y agregan los árboles de decisión al conjunto. El modelo usa aleatoriedad. Esto significa que cada vez que el algoritmo se ejecuta en los mismos datos, crea un modelo ligeramente diferente.
Cuando se utilizan algoritmos de aprendizaje automático con un algoritmo de aprendizaje estocástico, se recomienda evaluarlos promediando su rendimiento en varias ejecuciones o repeticiones de validación cruzada. Al ajustar el modelo final, puede ser deseable aumentar el número de árboles hasta que la varianza del modelo disminuya con estimaciones repetidas, o entrenar varios modelos finales y promediar sus predicciones. Echemos un vistazo al diseño de un conjunto LightGBM tanto para clasificación como para regresión.
Conjunto LightGBM para clasificación
En esta sección, veremos el uso de LightGBM para una tarea de clasificación. Primero, podemos usar la función make_classification () para crear un problema de clasificación binaria sintética con 1000 ejemplos y 20 características de entrada. Vea el ejemplo completo a continuación.
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# summarize the datasetLa ejecución del ejemplo crea un conjunto de datos y resume la forma de los componentes de entrada y salida.
(1000, 20) (1000,)Luego, podemos evaluar el algoritmo LightGBM en este conjunto de datos. Evaluaremos el modelo usando una validación cruzada estratificada repetida de k-veces con tres repeticiones y una k de 10. Informaremos la desviación media y estándar de la precisión del modelo en todas las repeticiones y dobleces.
# evaluate lightgbm algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))La ejecución del ejemplo muestra la precisión de la desviación estándar y media del modelo.
Nota : Sus resultados pueden diferir debido a la naturaleza estocástica del algoritmo o procedimiento de estimación, o diferencias en la precisión numérica. Pruebe el ejemplo varias veces y compare el resultado promedio.
En este caso, podemos ver que el conjunto LightGBM con hiperparámetros predeterminados logra una precisión de clasificación de alrededor del 92,5% en este conjunto de datos de prueba.
Accuracy: 0.925 (0.031)También podemos usar el modelo LightGBM como modelo final y hacer predicciones para la clasificación. Primero, el conjunto LightGBM se ajusta a todos los datos disponibles y, en segundo lugar, puede llamar a la función predict () para hacer predicciones sobre los nuevos datos. El siguiente ejemplo demuestra esto en nuestro conjunto de datos de clasificación binaria.
# make predictions using lightgbm for classification
from sklearn.datasets import make_classification
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]
yhat = model.predict([row])
print('Predicted Class: %d' % yhat[0])La ejecución del ejemplo entrena el modelo de conjunto LightGBM para todo el conjunto de datos y luego lo usa para predecir una nueva fila de datos, como lo haría si el modelo se usara en una aplicación.
Predicted Class: 1Ahora que estamos familiarizados con el uso de LightGBM para la clasificación, echemos un vistazo a la API de regresión.
Conjunto LightGBM para regresión
En esta sección, veremos el uso de LightGBM para un problema de regresión. Primero, podemos usar la función make_regression ()
para crear un problema de regresión sintética con 1000 ejemplos y 20 características de entrada. Vea el ejemplo completo a continuación.
# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# summarize the dataset
print(X.shape, y.shape)La ejecución del ejemplo crea un conjunto de datos y resume los componentes de entrada y salida.
(1000, 20) (1000,)En segundo lugar, podemos evaluar el algoritmo LightGBM en este conjunto de datos.
Como en la última sección, evaluaremos el modelo mediante la validación cruzada repetida de k veces con tres réplicas yk igual a 10. Informaremos el error absoluto medio (MAE) del modelo en todas las réplicas y grupos de validación cruzada. La biblioteca scikit-learn hace que el MAE sea negativo para que se maximice en lugar de minimizar. Esto significa que los MAE negativos grandes son mejores y el modelo ideal tiene un MAE de 0. A continuación se muestra un ejemplo completo.
# evaluate lightgbm ensemble for regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# evaluate the model
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))La ejecución del ejemplo informa la desviación estándar y media del modelo.
Nota : Sus resultados pueden variar debido a la naturaleza estocástica del algoritmo o procedimiento de estimación, o diferencias en la precisión numérica. Considere ejecutar el ejemplo varias veces y comparar el promedio. En este caso, vemos que el conjunto LightGBM con hiperparámetros predeterminados alcanza un MAE de alrededor de 60.
MAE: -60.004 (2.887)También podemos usar el modelo LightGBM como modelo final y hacer predicciones para la regresión. Primero, el conjunto LightGBM se entrena con todos los datos disponibles, luego se puede llamar a la función predict () para predecir nuevos datos. El siguiente ejemplo demuestra esto en nuestro conjunto de datos de regresión.
# gradient lightgbm for making predictions for regression
from sklearn.datasets import make_regression
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792]
yhat = model.predict([row])
print('Prediction: %d' % yhat[0]) La ejecución del ejemplo entrena un modelo de conjunto LightGBM en todo el conjunto de datos y luego lo usa para predecir una nueva fila de datos, como lo haría si se usara el modelo en una aplicación.
Prediction: 52Ahora que estamos familiarizados con el uso de la API scikit-learn para evaluar y aplicar conjuntos LightGBM, echemos un vistazo a la configuración del modelo.
Hiperparámetros LightGBM
En esta sección, analizaremos más de cerca algunos de los hiperparámetros que son importantes para el conjunto LightGBM y su impacto en el rendimiento del modelo. LightGBM tiene muchos hiperparámetros para mirar, aquí observamos la cantidad de árboles y su profundidad, la tasa de aprendizaje y el tipo de impulso. Para obtener consejos generales sobre cómo ajustar los hiperparámetros de LightGBM, consulte la documentación: Ajuste de los parámetros de LightGBM .
Examinando la cantidad de árboles
Un hiperparámetro importante para el algoritmo de conjunto LightGBM es el número de árboles de decisión utilizados en el conjunto. Recuerde que los árboles de decisión se agregan al modelo secuencialmente en un intento de corregir y mejorar las predicciones hechas por árboles anteriores. La regla a menudo funciona: más árboles es mejor. El número de árboles se puede especificar mediante el argumento n_estimators, cuyo valor predeterminado es 100. El siguiente ejemplo examina el efecto del número de árboles, de 10 a 5000.
# explore lightgbm number of trees effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
trees = [10, 50, 100, 500, 1000, 5000]
for n in trees:
models[str(n)] = LGBMClassifier(n_estimators=n)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Ejecutar el ejemplo primero muestra la precisión promedio para cada número de árboles de decisión.
Nota : Sus resultados pueden variar debido a la naturaleza estocástica del algoritmo o procedimiento de estimación, o diferencias en la precisión numérica. Considere ejecutar el ejemplo varias veces y comparar el resultado promedio.
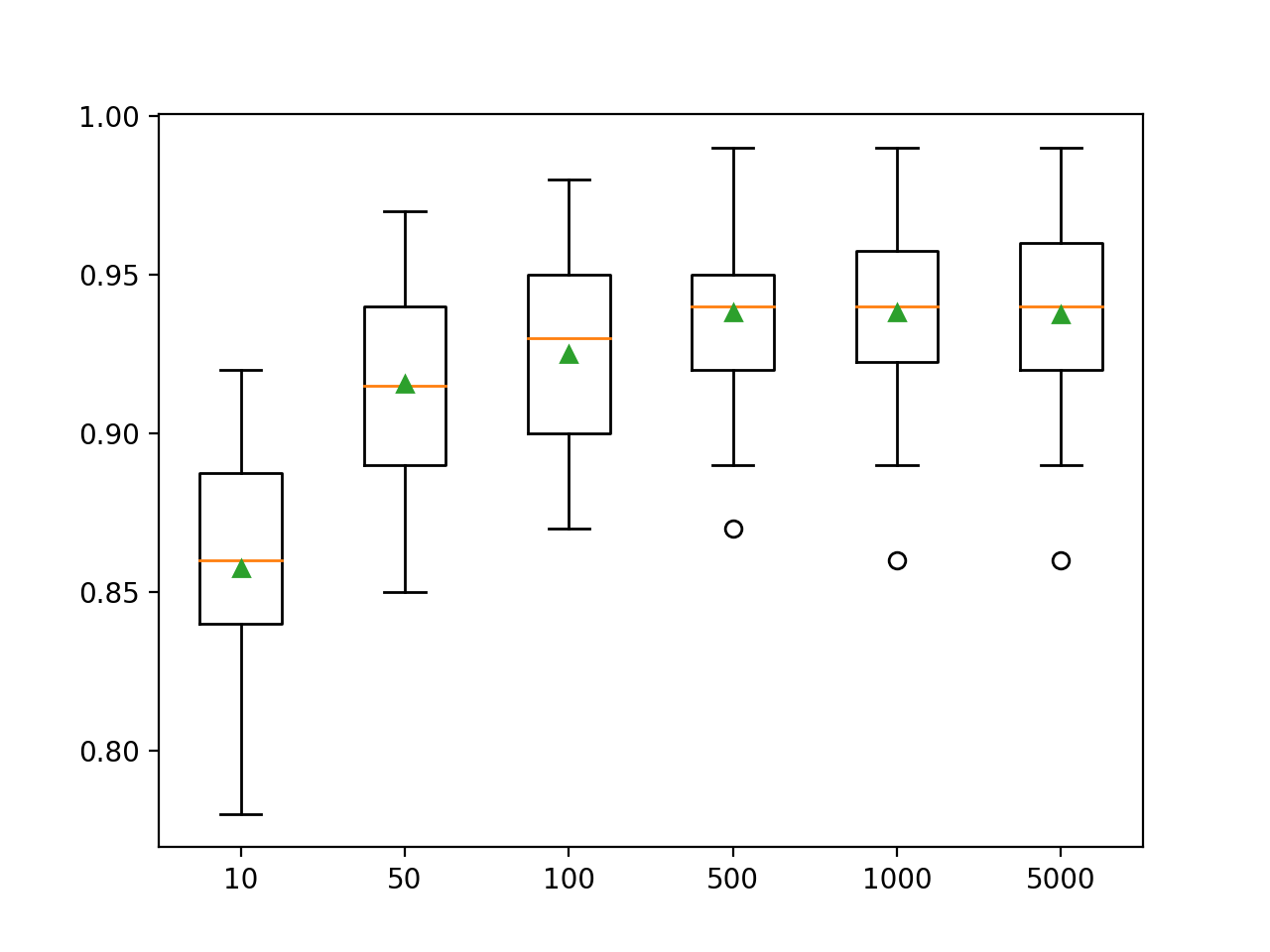
Aquí vemos que el rendimiento mejora para este conjunto de datos a unos 500 árboles, después de lo cual parece nivelarse.
>10 0.857 (0.033)
>50 0.916 (0.032)
>100 0.925 (0.031)
>500 0.938 (0.026)
>1000 0.938 (0.028)
>5000 0.937 (0.028)Se crea un diagrama de caja y bigotes para distribuir las puntuaciones de precisión para cada número configurado de árboles. Existe una tendencia general hacia un aumento en el rendimiento del modelo y el tamaño del conjunto.
Examinando la profundidad de un árbol
Cambiar la profundidad de cada árbol agregado al conjunto es otro hiperparámetro importante para aumentar el gradiente. La profundidad del árbol determina cuánto se especializa cada árbol en el conjunto de datos de entrenamiento: qué tan general o entrenado puede ser. Se prefieren los árboles que no deben ser demasiado superficiales y generales (por ejemplo, AdaBoost ) y no demasiado profundos y especializados (por ejemplo, agregación de arranque ).
El aumento de gradiente generalmente funciona bien con árboles que son de profundidad moderada, equilibrando el entrenamiento y la generalidad. La profundidad del árbol está controlada por el argumento max_depth, y el valor predeterminado es un valor indefinido, ya que el mecanismo predeterminado para administrar la complejidad de los árboles es utilizar un número finito de nodos.
Hay dos formas principales de controlar la complejidad de un árbol: a través de la profundidad máxima del árbol y el número máximo de nodos terminales (hojas) del árbol. Estamos examinando el número de hojas aquí, por lo que necesitamos aumentar el número para admitir árboles más profundos especificando el argumento num_leaves . A continuación, examinamos las profundidades de los árboles de 1 a 10 y su impacto en el rendimiento del modelo.
# explore lightgbm tree depth effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in range(1,11):
models[str(i)] = LGBMClassifier(max_depth=i, num_leaves=2**i)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Ejecutar el ejemplo primero muestra la precisión promedio para cada profundidad de árbol ajustada.
Nota : Sus resultados pueden diferir debido a la naturaleza estocástica del algoritmo o procedimiento de estimación, o diferencias en la precisión numérica. Considere ejecutar el ejemplo varias veces y comparar el promedio.
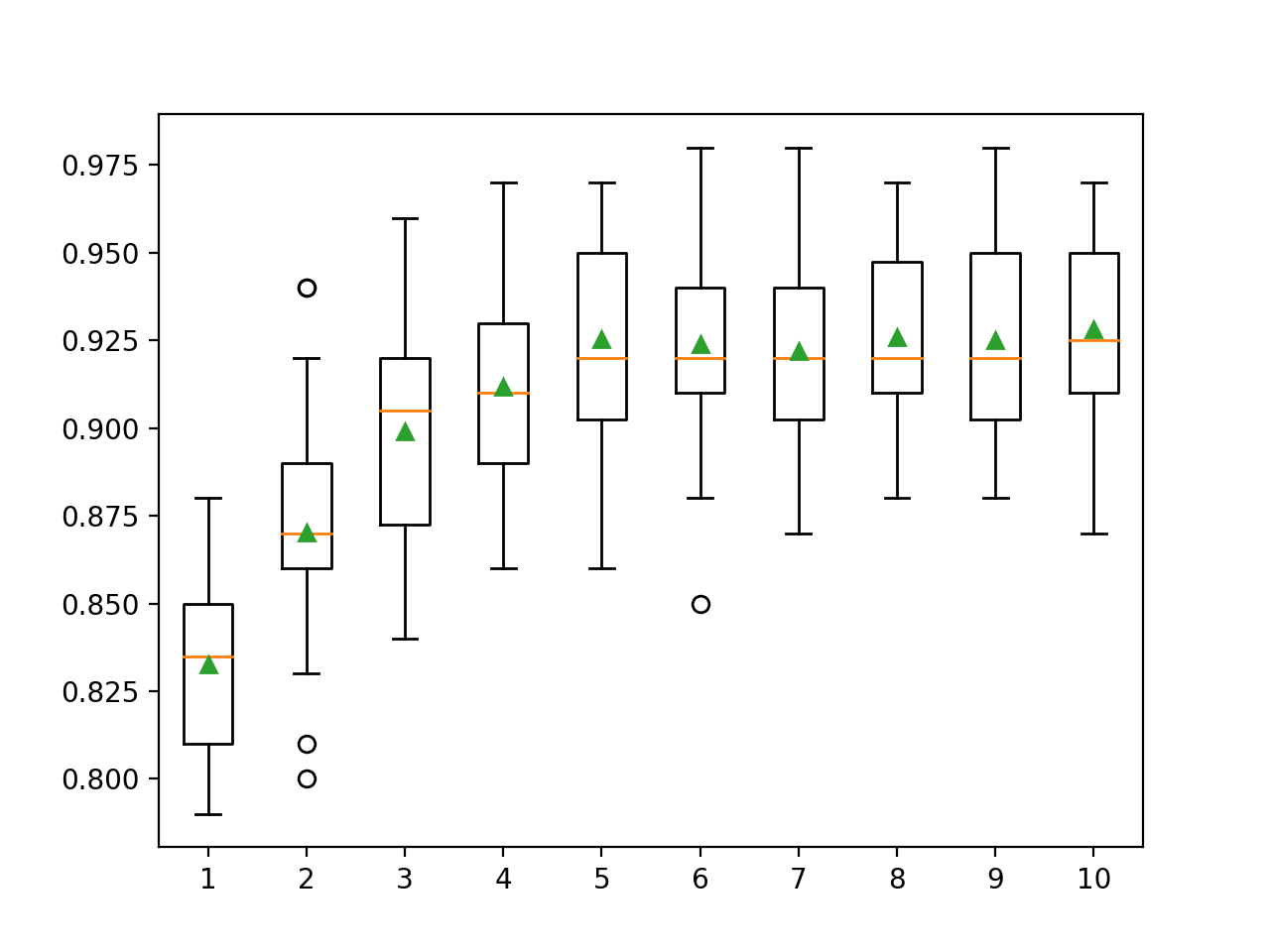
Aquí podemos ver que el rendimiento mejora al aumentar la profundidad del árbol, posiblemente hasta 10 niveles. Sería interesante explorar árboles aún más profundos.
>1 0.833 (0.028)
>2 0.870 (0.033)
>3 0.899 (0.032)
>4 0.912 (0.026)
>5 0.925 (0.031)
>6 0.924 (0.029)
>7 0.922 (0.027)
>8 0.926 (0.027)
>9 0.925 (0.028)
>10 0.928 (0.029)Se genera un diagrama de rectángulo y bigotes para distribuir las puntuaciones de precisión para cada profundidad de árbol configurada. Existe una tendencia general a que el rendimiento del modelo aumente con una profundidad de árbol de hasta cinco niveles, después de lo cual el rendimiento permanece bastante plano.
Investigación de la tasa de aprendizaje
La tasa de aprendizaje controla cuánto contribuye cada modelo a la predicción de conjuntos. Las velocidades más bajas pueden requerir más árboles de decisión en el conjunto. La tasa de aprendizaje se puede controlar con el argumento learning_rate, por defecto es 0.1. A continuación se examina la tasa de aprendizaje y se compara el efecto de los valores de 0,0001 a 1,0.
# explore lightgbm learning rate effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
rates = [0.0001, 0.001, 0.01, 0.1, 1.0]
for r in rates:
key = '%.4f' % r
models[key] = LGBMClassifier(learning_rate=r)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()Ejecutar el ejemplo primero muestra la precisión promedio para cada tasa de aprendizaje configurada.
Nota : Sus resultados pueden variar debido a la naturaleza estocástica del algoritmo o procedimiento de estimación, o diferencias en la precisión numérica. Considere ejecutar el ejemplo varias veces y comparar el promedio.
Aquí vemos que una mayor tasa de aprendizaje conduce a un mejor rendimiento en este conjunto de datos. Esperamos que agregar más árboles al conjunto para una tasa de aprendizaje más baja mejorará aún más el rendimiento.
>0.0001 0.800 (0.038)
>0.0010 0.811 (0.035)
>0.0100 0.859 (0.035)
>0.1000 0.925 (0.031)
>1.0000 0.928 (0.025)Se crea una caja de bigote para distribuir las puntuaciones de precisión para cada tasa de aprendizaje configurada. Existe una tendencia general a que el rendimiento del modelo aumente con un aumento en la tasa de aprendizaje hasta 1.0.

Impulsar la investigación de tipos
La peculiaridad de LightGBM es que admite una serie de algoritmos de impulso llamados tipos de impulso. El tipo de refuerzo se especifica mediante el argumento boosting_type y toma una cadena para determinar el tipo. Valores posibles:
- 'gbdt' : Árbol de decisión mejorado por gradiente (GDBT);
- 'dardo' : el concepto de abandono se ingresa en MART, obtenemos DART;
- 'goss' : búsqueda unidireccional de gradiente (GOSS).
El valor predeterminado es GDBT, el algoritmo clásico de aumento de gradiente.
DART se describe en un artículo de 2015 titulado " DART: los abandonos se encuentran con múltiples árboles de regresión aditiva " y, como su nombre indica, agrega el concepto de abandono del aprendizaje profundo al algoritmo de múltiples árboles de regresión aditiva (MART), un precursor de los árboles de decisión que aumentan el gradiente.
Este algoritmo es conocido por muchos nombres, incluidos Gradient TreeBoost, Boosted Trees y Multiple Additive Regression Trees and Trees (MART). Usamos el último nombre para referirnos al algoritmo.
GOSS se presenta con trabajo en LightGBM y la biblioteca lightbgm. Este enfoque tiene como objetivo usar solo aquellas instancias que resultan en un gran gradiente de error para actualizar el modelo y eliminar las instancias restantes.
... Excluimos una parte significativa de las instancias de datos con pequeños gradientes y usamos solo el resto para estimar el aumento de información.
A continuación, LightGBM está capacitado en un conjunto de datos de clasificación sintético con tres métodos clave de impulso.
# explore lightgbm boosting type effect on performance
from numpy import arange
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
types = ['gbdt', 'dart', 'goss']
for t in types:
models[t] = LGBMClassifier(boosting_type=t)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()La ejecución del ejemplo primero muestra la precisión promedio para cada tipo de impulso configurado.
Nota : Sus resultados pueden diferir debido a la naturaleza estocástica del algoritmo o procedimiento de estimación, o diferencias en la precisión numérica. Considere ejecutar el ejemplo varias veces y comparar el resultado promedio.
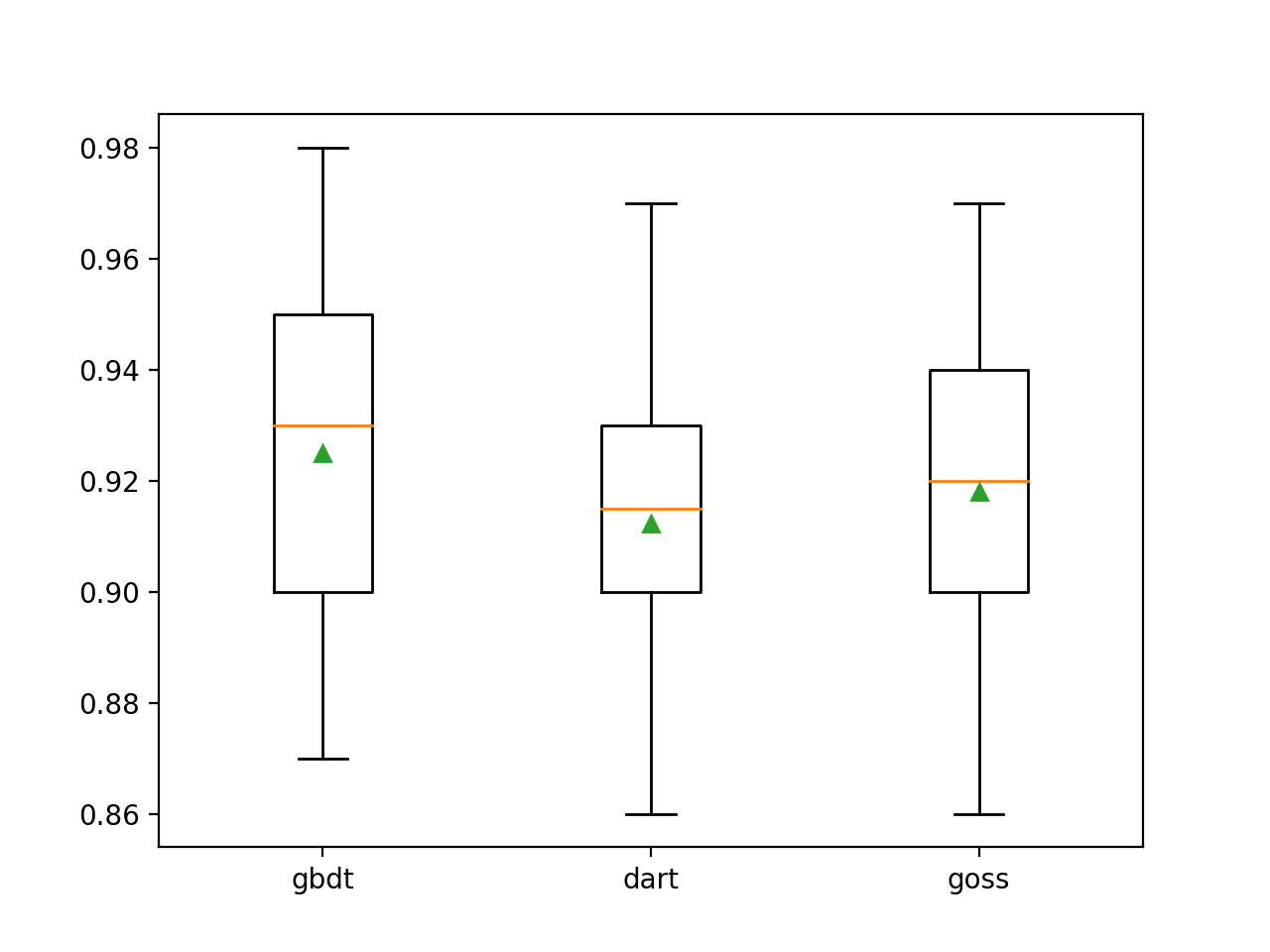
Podemos ver que el método de refuerzo predeterminado funciona mejor que los otros dos métodos evaluados.
>gbdt 0.925 (0.031)
>dart 0.912 (0.028)
>goss 0.918 (0.027)Se crea un diagrama de caja y bigotes para distribuir las estimaciones de precisión para cada método de amplificación configurado, lo que permite la comparación directa de los métodos.

- Curso de aprendizaje automático
- Formación profesional en ciencia de datos
- Formación de analista de datos
- Curso de Python para desarrollo web
Más cursos