- Empecemos. Hablaré sobre el registro conveniente y la infraestructura en torno al registro que puede implementar para que sea conveniente para usted vivir con su aplicación y su ciclo de vida.

qué hacemos? Construiremos una pequeña aplicación, nuestra startup. Luego implementaremos el inicio de sesión básico en él, esta es una pequeña parte del informe, lo que Python proporciona de inmediato. Y luego la mayor parte: analizaremos los problemas típicos que encontramos durante la depuración, la implementación y las herramientas para resolverlos.
Pequeño descargo de responsabilidad: usaré palabras como bolígrafo y idioma. Dejame explicar. El "lápiz" probablemente sea jerga yandex, denota su API, API http o gRPC o cualquier otra combinación de letras antes de APU. "Locale" es cuando desarrollo en una computadora portátil. Parece que le he contado todas las palabras que no controlo.
Aplicación de librería
Empecemos. Nuestra startup es "Librería". La característica principal de esta aplicación será vender libros, eso es todo lo que queremos hacer. Luego un poco de relleno. La aplicación estará escrita en Flask. Todos los fragmentos de código, todas las herramientas son genéricas y se extraen de Python, por lo que pueden integrarse en la mayoría de sus aplicaciones. Pero en nuestra charla será Flask.
Personajes: yo, el desarrollador, los gerentes y mi querido colega Erast. Cualquier coincidencia es accidental.
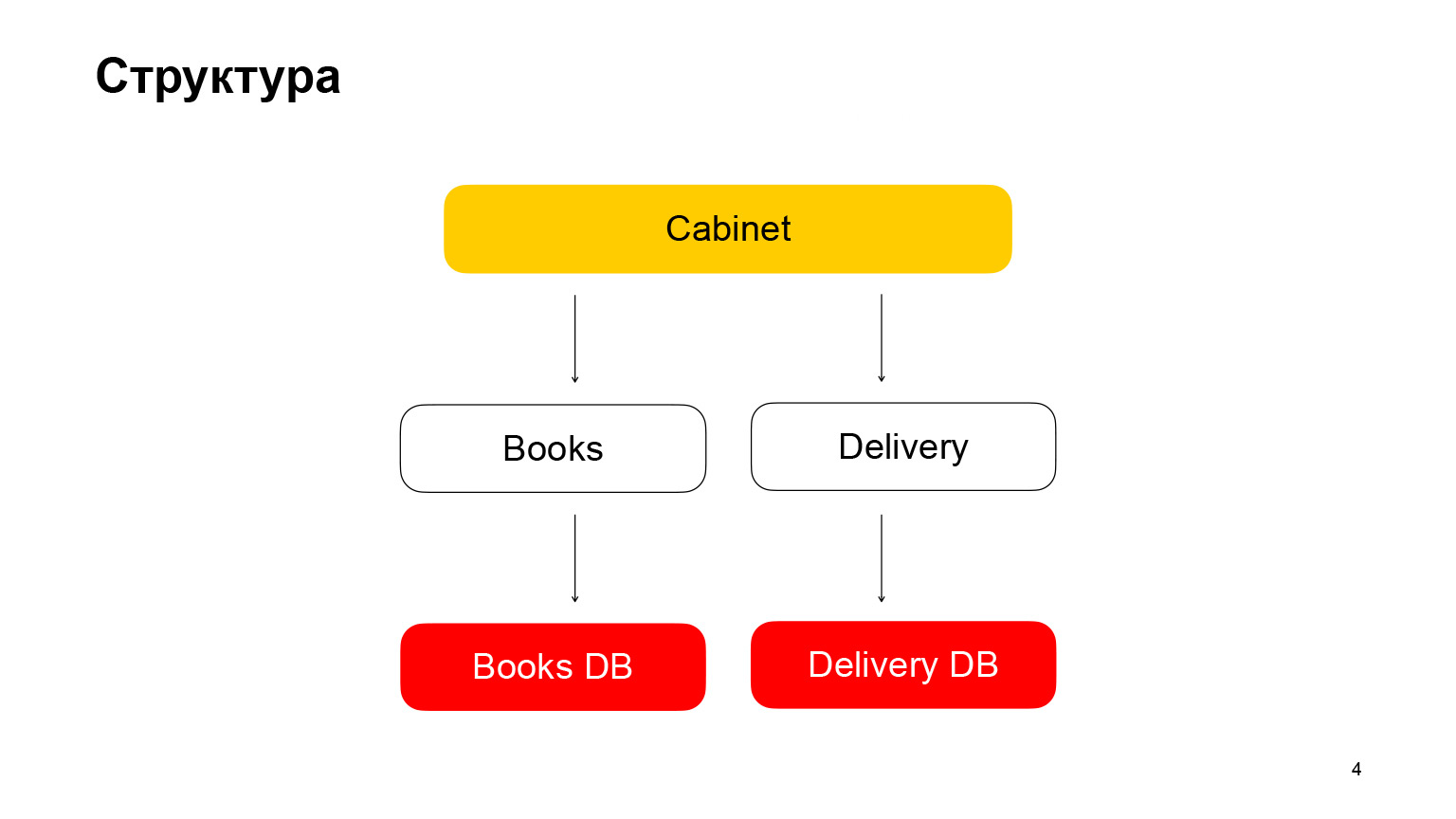
Hablemos un poco de la estructura. Es una aplicación de arquitectura de microservicios. El primer servicio es Books, un almacenamiento de libros con metadatos de libros. Utiliza la base de datos PostgreSQL. El segundo microservicio es un microservicio de entrega que almacena metadatos sobre los pedidos de los usuarios. El gabinete es el backend del gabinete. No tenemos una interfaz, no es necesaria en nuestro informe. El gabinete agrega solicitudes, datos del servicio de libros y del servicio de entrega.

Te mostraré el código para los identificadores de estos servicios, API Books. Este identificador toma datos de la base de datos, los serializa, los convierte en JSON y los devuelve.

Vayamos más lejos. Servicio de entrega. El mango es exactamente el mismo. Tomamos los datos de la base de datos, los serializamos y los enviamos.

Y la última perilla es la perilla del gabinete. Tiene un código ligeramente diferente. El gabinete maneja las solicitudes de datos del servicio de entrega y del servicio de libros, agrega las respuestas y entrega al usuario sus pedidos. Todo. Descubrimos rápidamente la estructura de la aplicación.
Registro básico en la aplicación
Ahora hablemos del registro básico, el que vimos. Comencemos con la terminología.

¿Qué nos da Python? Cuatro entidades principales básicas:
- Logger, el punto de entrada para iniciar sesión en su código. Utilizará algún tipo de Logger, escriba logging.INFO, y eso es todo. Su código ya no sabrá nada sobre dónde fue el mensaje y qué sucedió a continuación. La entidad Handler ya es responsable de esto.
- El manejador procesa su mensaje, decide dónde enviarlo: a la salida estándar, a un archivo o al correo de otra persona.
- El filtro es una de las dos entidades auxiliares. Elimina mensajes del registro. Otro caso de uso común es el relleno de datos. Por ejemplo, en tu publicación necesitas agregar un atributo. El filtro también puede ayudar con esto.
- Formatter trae su mensaje a la forma deseada.

Aquí es donde terminamos con la terminología, no volveremos a iniciar sesión directamente en Python, con clases base. Pero aquí hay un ejemplo de la configuración de nuestra aplicación, que se implementa en los tres servicios. Hay dos bloques principales e importantes para nosotros: formateadores y manejadores. Para los formateadores, hay un ejemplo, que puede ver aquí, una plantilla de cómo se mostrará el mensaje.
En los controladores, puede ver que se usa logging.StreamHandler. Es decir, volcamos todos nuestros registros a la salida estándar. Eso es todo, hemos terminado con eso.
Problema 1. Los registros están dispersos
Pasando a los problemas. Para empezar, el primer problema: los registros están dispersos.
Un poco de contexto. Hemos escrito nuestra solicitud, el caramelo ya está listo. Podemos ganar dinero con eso. Lo estamos implementando en producción. Por supuesto, hay más de un servidor. Según nuestras estimaciones conservadoras, nuestra aplicación más compleja necesita alrededor de tres o cuatro automóviles, y así sucesivamente para cada servicio.
Ahora la pregunta. El gerente viene corriendo hacia nosotros y nos pregunta: "¡Se ha descompuesto, ayuda!" Estas corriendo. Todo está registrado para ti, es genial. Vas a la primera máquina de escribir, mira, no hay nada allí para tu solicitud. Ve al segundo coche, nada. Y así. Esto es malo, debe abordarse de alguna manera.

Formalicemos el resultado que queremos ver. Quiero que los registros estén en un solo lugar. Este es un requisito simple. Un poco mejor es que quiero buscar en los registros. Es decir, sí, está en un solo lugar y sé cómo copiar, pero sería genial si hubiera algunas herramientas, características interesantes además de un simple grap.
Y no quiero escribir. Este es Erast a quien le encanta escribir código. No estoy hablando de eso, hice un producto de inmediato. Es decir, desea menos código adicional, arreglárselas con uno o dos archivos, líneas, y eso es todo.

La solución que se puede utilizar es Elasticsearch. Intentemos levantarlo. ¿Cuáles son los beneficios de Elasticsearch? Esta es una interfaz de búsqueda de registros. Hay una interfaz lista para usar, esta no es una consola para usted, sino el único lugar de almacenamiento. Es decir, hemos cumplido con el requisito principal. No necesitaremos ir a los servidores.
En nuestro caso, será una integración bastante simple, y con el lanzamiento reciente, Elasticsearch tiene un nuevo agente que se encarga de la mayoría de las integraciones. Allí ellos mismos aserraron en integración. Muy genial. Escribí una charla antes y usé filebeat, igual de fácil. Es simple para los registros.
Un poco sobre Elasticsearch. No quiero hacer publicidad, pero hay muchas funciones adicionales. Por ejemplo, lo bueno es la búsqueda de registro de texto completo lista para usar. Suena muy bien. Por ahora, estas ventajas son suficientes para nosotros. Lo abrochamos.
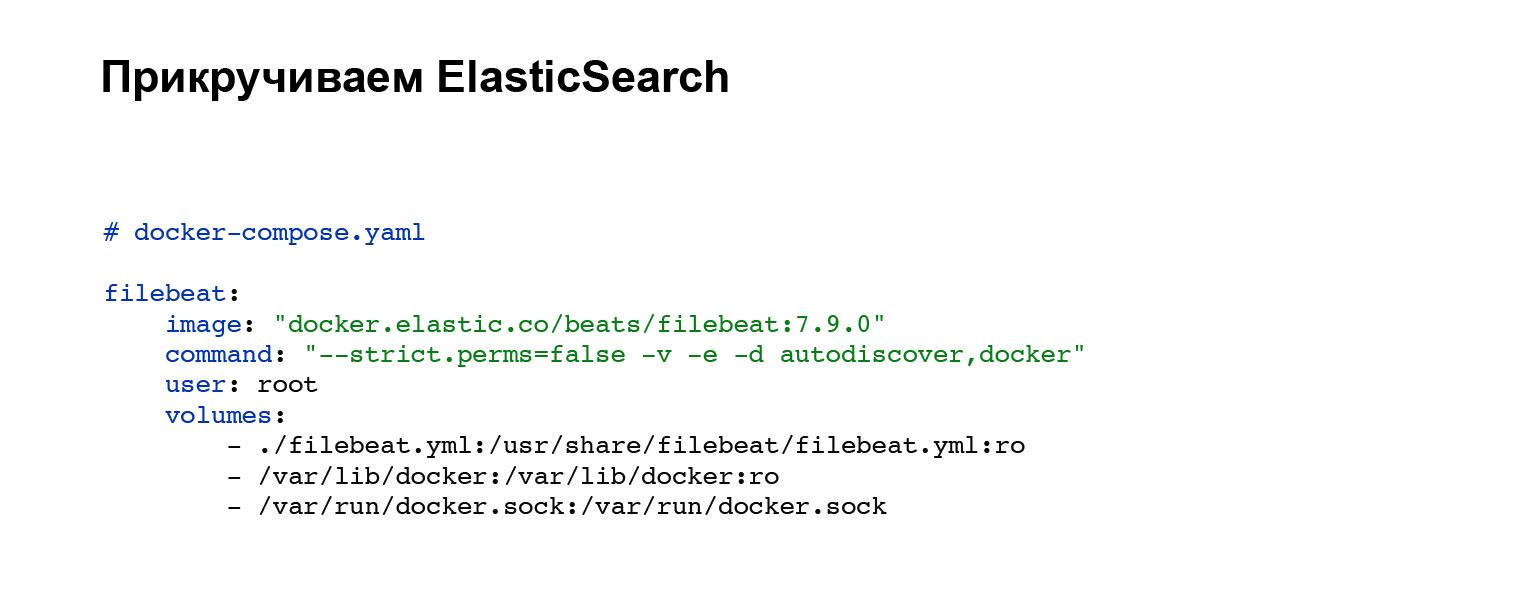
En primer lugar, necesitaremos implementar un agente que enviará nuestros registros a Elasticsearch. Registra una cuenta con Elasticsearch y luego agrega a su docker-compose. Si no tiene docker-compose, puede subir con los tiradores o en su sistema. En nuestro caso, se agrega el siguiente bloque de código, integración en docker-compose. Todo, el servicio está configurado. Y puede ver el archivo de configuración filebeat.yml en el bloque de volúmenes.

Aquí hay un ejemplo de filebeat.yml. Aquí hemos configurado una búsqueda automática de los registros de los contenedores docker que giran cerca. La elección de estos registros se ha personalizado. Por condición, puede configurar, colgar etiquetas en sus contenedores y, dependiendo de esto, sus registros se enviarán solo a ciertos contenedores. El bloque de procesadores: add_docker_metadata es simple. Agregamos un poco más de información sobre sus registros en el contexto de la ventana acoplable a los registros. Opcional, pero genial.
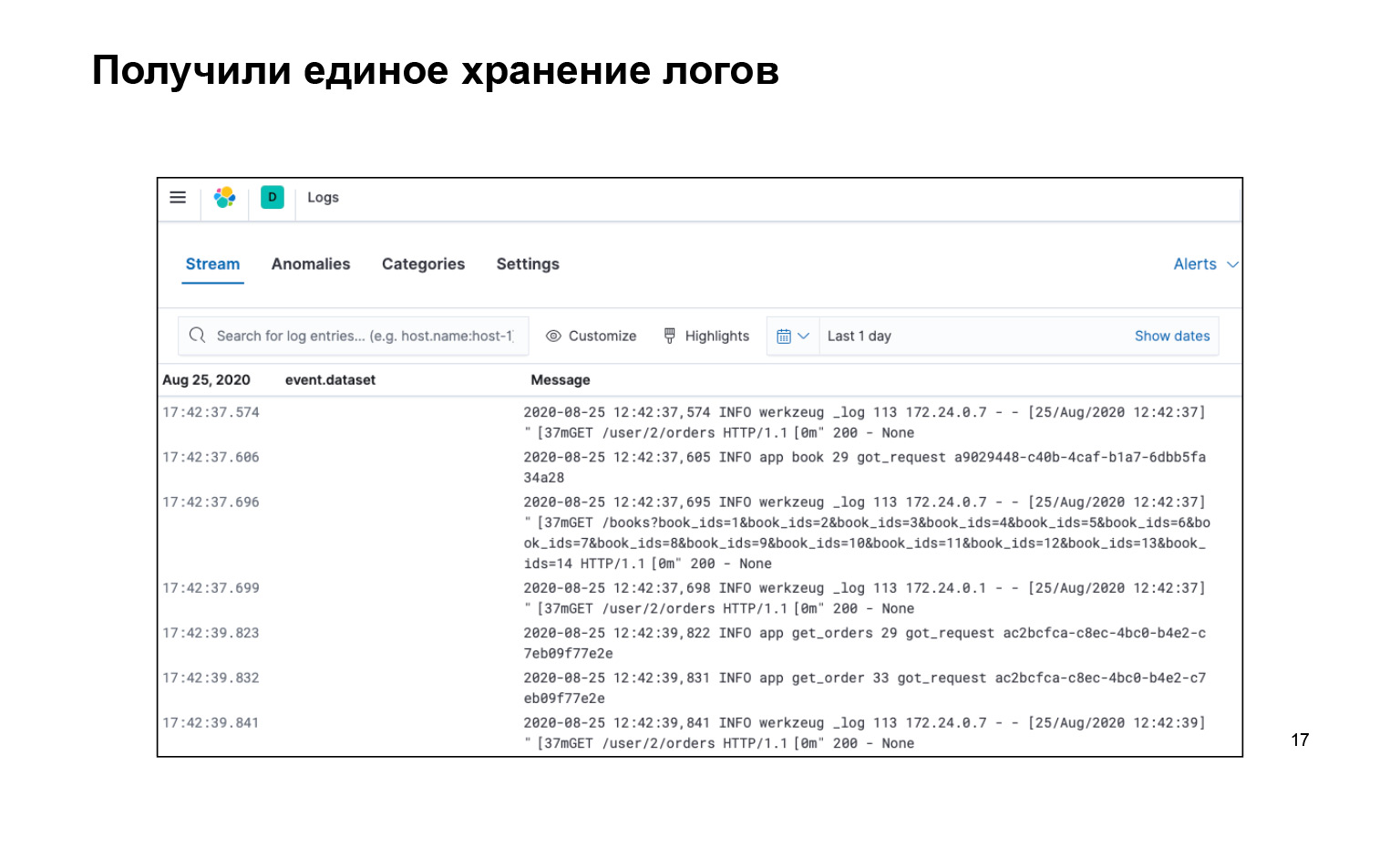
¿Qué tenemos? Eso es todo lo que escribimos, todo el código, muy bueno. Al mismo tiempo, tenemos todos los registros en un solo lugar y hay una interfaz. Podemos buscar en nuestros registros, aquí está la barra de búsqueda. Se entregan. E incluso puede encenderlo en vivo para que la transmisión vuele a nuestros registros en la interfaz, y lo vimos.

Aquí yo mismo habría preguntado: ¿por qué, cómo abrochar algo? ¿Qué es una búsqueda de registros, qué se puede hacer allí?
Sí, de forma inmediata en este enfoque, cuando tenemos registros de texto, hay una pequeña broma: podemos establecer una solicitud por el texto, por ejemplo, mensaje: usuarios. Esto nos imprimirá todos los registros que tengan la subcadena de usuarios. Puede utilizar asteriscos, la mayoría de los demás comodines de Unix. Pero parece que esto no es suficiente, quiero hacerlo más difícil para que podamos calentar antes en Nginx, como podamos.

Retrocedamos un poco de Elasticsearch y tratemos de hacerlo no con Elasticsearch, sino con un enfoque diferente. Consideremos los registros estructurales. Esto es cuando cada una de sus entradas de registro no es solo una línea de texto, sino un objeto serializado con atributos que cualquiera de sus sistemas de terceros puede serializar para obtener un objeto listo para usar.
¿Cuáles son las ventajas de esto? Es un formato de datos uniforme. Sí, los objetos pueden tener diferentes atributos, pero cualquier sistema externo puede leer JSON y obtener algún tipo de objeto.
Algún tipo de escritura. Esto simplifica la integración con otros sistemas: no es necesario escribir deserializadores. Y solo los deserializadores son otro punto. No es necesario que escriba textos prosaicos en la aplicación. Ejemplo: "El usuario vino con tal o cual especialista en identificación, con tal o cual pedido". Y todo esto debe escribirse cada vez.
Me molestó. Quiero escribir: "Ha llegado una solicitud". Además: "Fulano de tal, fulano de tal, fulano de tal", muy simple, muy al estilo de las TI.

Vamonos. Acordemos: iniciaremos sesión en formato JSON, este es un formato simple. Elasticsearch es inmediatamente compatible, filebeat, que serializamos e intentamos archivar. No es muy dificil. Primero, agrega el archivo de configuración de la biblioteca pythonjsonlogger al bloque de formateadores JSONFormatter, donde almacenamos la configuración. Este puede ser un lugar diferente en su sistema. Y luego, en el atributo de formato, pasa qué atributos desea agregar a su objeto.
El siguiente bloque es un bloque de configuración que se agrega a filebeat.yml. Aquí, lista para usar, hay una interfaz filebeat para analizar registros JSON. Muy genial. Es todo. No tienes que escribir nada más para esto. Y ahora tus registros parecen objetos.
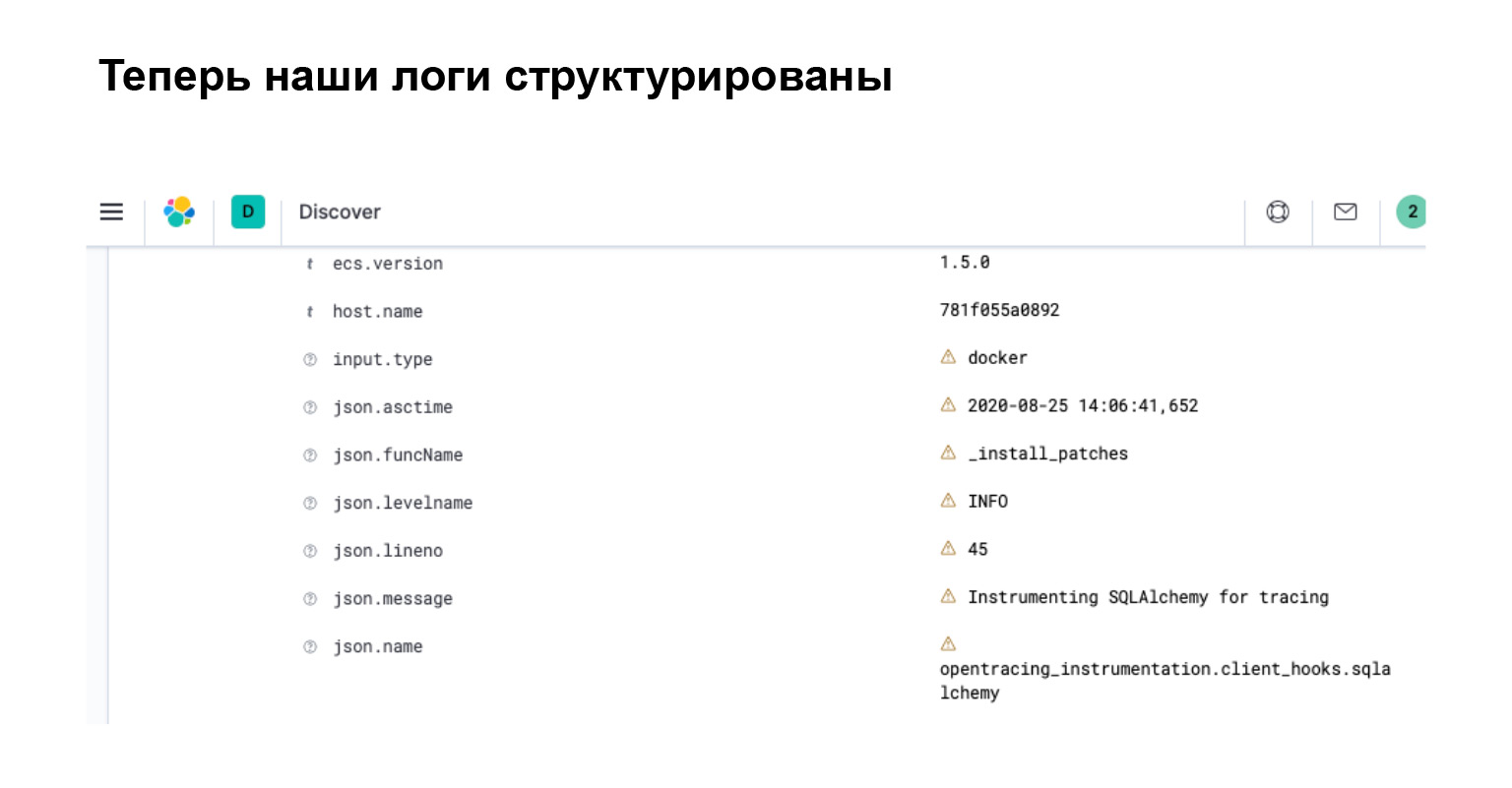
¿Qué obtuvimos en Elasticsearch? En la interfaz, inmediatamente ve que su registro se ha convertido en un objeto con atributos separados, mediante el cual puede buscar, crear filtros y realizar consultas complejas.

Resumamos. Ahora nuestros registros tienen una estructura. Son fáciles de usar y puede escribir consultas inteligentes. Elasticsearch es consciente de esta estructura ya que analizó todos estos atributos. Y en kibana, que es una interfaz para Elasticsearch, puede filtrar dichos registros utilizando un lenguaje de consulta especializado que proporciona Elasticsearch.
Y es más fácil que remar. Grep tiene un lenguaje bastante difícil y genial. Hay mucho sobre lo que escribir. Muchas cosas se pueden hacer más fáciles en kibana. Con esto resuelto.
Problema 2. Frenos
El siguiente problema son los frenos. En una arquitectura de microservicio, siempre y en todas partes hay frenos.

Aquí hay un pequeño contexto, les contaré una historia. El gerente, el personaje principal de nuestro proyecto, viene corriendo hacia mí y me dice: “¡Oye, oye, la oficina se está ralentizando! ¡Danya, salva, ayuda! "
Todavía no sabemos nada, subimos a nuestros registros en Elasticsearch. Pero déjame decirte lo que realmente sucedió.

Erast agregó una función. En los libros, ahora mostramos no la identificación del autor, sino su nombre directamente en la interfaz. Muy genial. Lo hizo con el siguiente código. Un pequeño fragmento de código, nada complicado. ¿Qué puede salir mal?
Con un ojo entrenado, puede decir que no puede hacer esto con SQLAlchemy y también con otro ORM. Necesita hacer una pre-caché o algo más para no ir a la base de datos con una pequeña subconsulta en un bucle. Un problema desagradable. Parece que tal error no debería permitirse en absoluto.
Déjame decirte. Tenía experiencia: trabajamos con Django y teníamos una pre-caché personalizada implementada en nuestro proyecto. Todo salió bien durante muchos años. En algún momento, Erast y yo decidimos: mantengamos el ritmo, actualice Django. Naturalmente, Django no sabe nada sobre nuestra caché personalizada y la interfaz ha cambiado. Prikash se cayó en silencio. Esto no quedó atrapado en las pruebas. El mismo problema, simplemente era más difícil de atrapar.
¿Cuál es el problema? ¿Cómo puedo ayudarte a resolver el problema?

Te contamos lo que hice antes de empezar a resolver el problema de encontrar frenos.
Lo primero que hago es ir a Elasticsearch, ya lo tenemos, ayuda, no hay necesidad de correr por los servidores. Voy a los troncos en busca de los troncos del armario. Encuentro consultas largas. Lo juego en una computadora portátil y veo que no es la oficina la que se está frenando. Ralentiza los libros.
Me encuentro con los registros de Libros, encuentro consultas problemáticas; de hecho, ya las tenemos. Reproduzco libros de la misma manera en una computadora portátil. Código muy complejo, no entiendo nada. Estoy empezando a depurar. Los tiempos son bastante difíciles de captar. ¿Por qué? Es bastante difícil determinar esto internamente en SQLAlchemy. Escribo registradores de tiempo personalizados, localizo y soluciono el problema.
Me dolió. Difícil, desagradable. Lloré. Me gustaría que este proceso de encontrar un problema fuera más rápido y más conveniente.
Formalicemos nuestros problemas. Es difícil buscar en los registros lo que se está ralentizando, porque nuestro registro es un registro de eventos no relacionados. Tenemos que escribir temporizadores personalizados que nos muestren cuántos bloques de código se han ejecutado. Además, no está claro cómo registrar los tiempos de sistemas externos: por ejemplo, ORM o bibliotecas de solicitudes. Necesitamos incrustar nuestros temporizadores en el interior o con algún tipo de Wrapper, pero no descubriremos por qué se ralentiza en el interior. Complicado.

Una buena solución que encontré es Jaeger. Esta es una implementación del protocolo opentracing, así que implementemos el rastreo.
¿Qué da Jaeger? Es una interfaz fácil de usar con consultas de búsqueda. Puedes filtrar consultas largas o hacerlo por etiquetas. Una representación visual del flujo de solicitudes, una imagen muy bonita, la mostraré un poco más adelante.
Los tiempos se registran fuera de la caja. No tienes que hacer nada con ellos. Si necesita verificar cuánto tiempo se está ejecutando sobre algún bloque personalizado, puede envolverlo en los temporizadores proporcionados por Jaeger. Muy cómodamente.
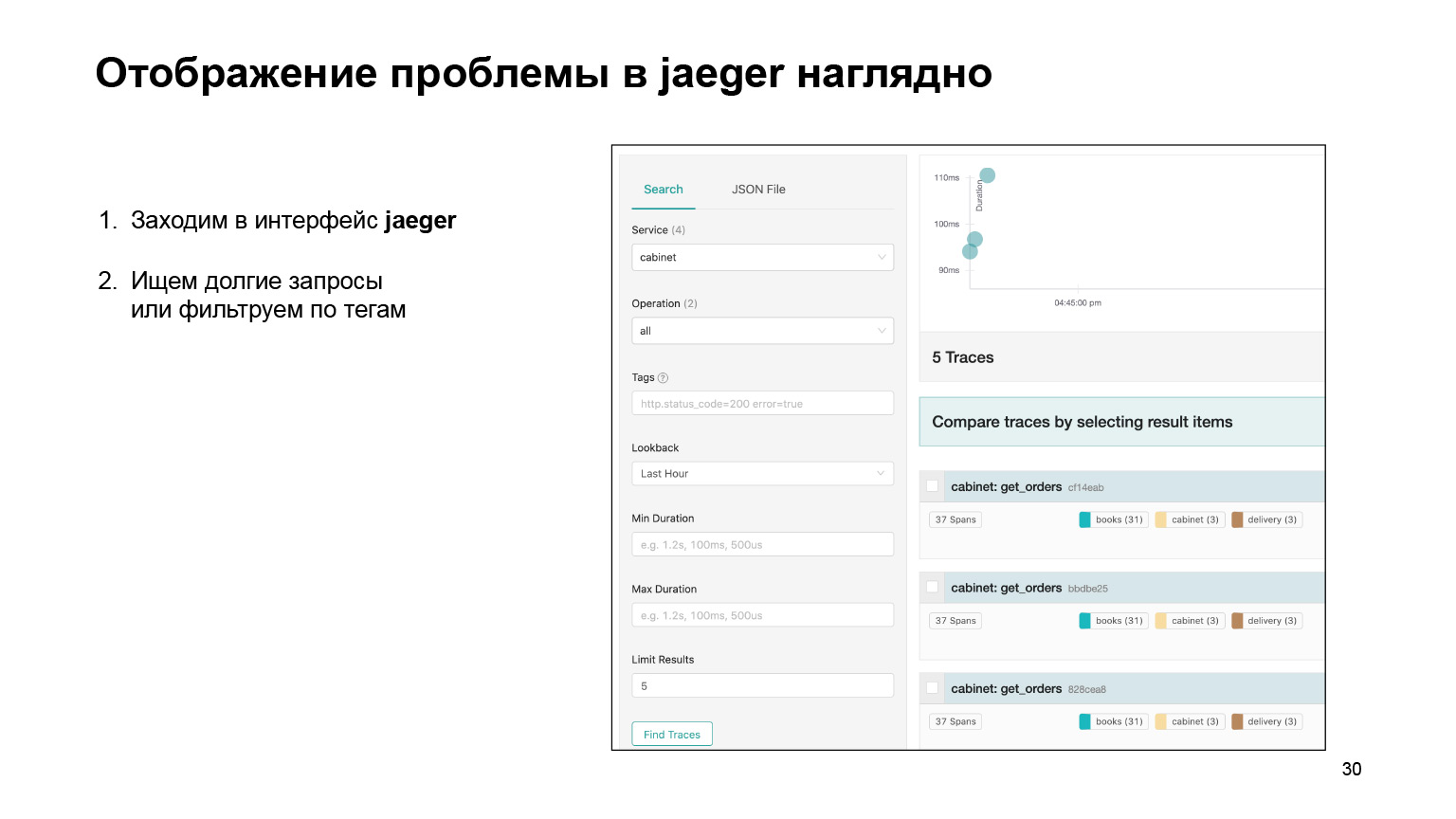
Veamos cómo fue posible encontrar el problema en la interfaz y localizarlo allí. Entramos en la interfaz de Jaeger. Así son nuestras solicitudes. Podemos buscar solicitudes de una cuenta u otro servicio. Filtramos inmediatamente las consultas largas. Nos interesan los largos, son bastante difíciles de encontrar en los registros. Obtenemos su lista.
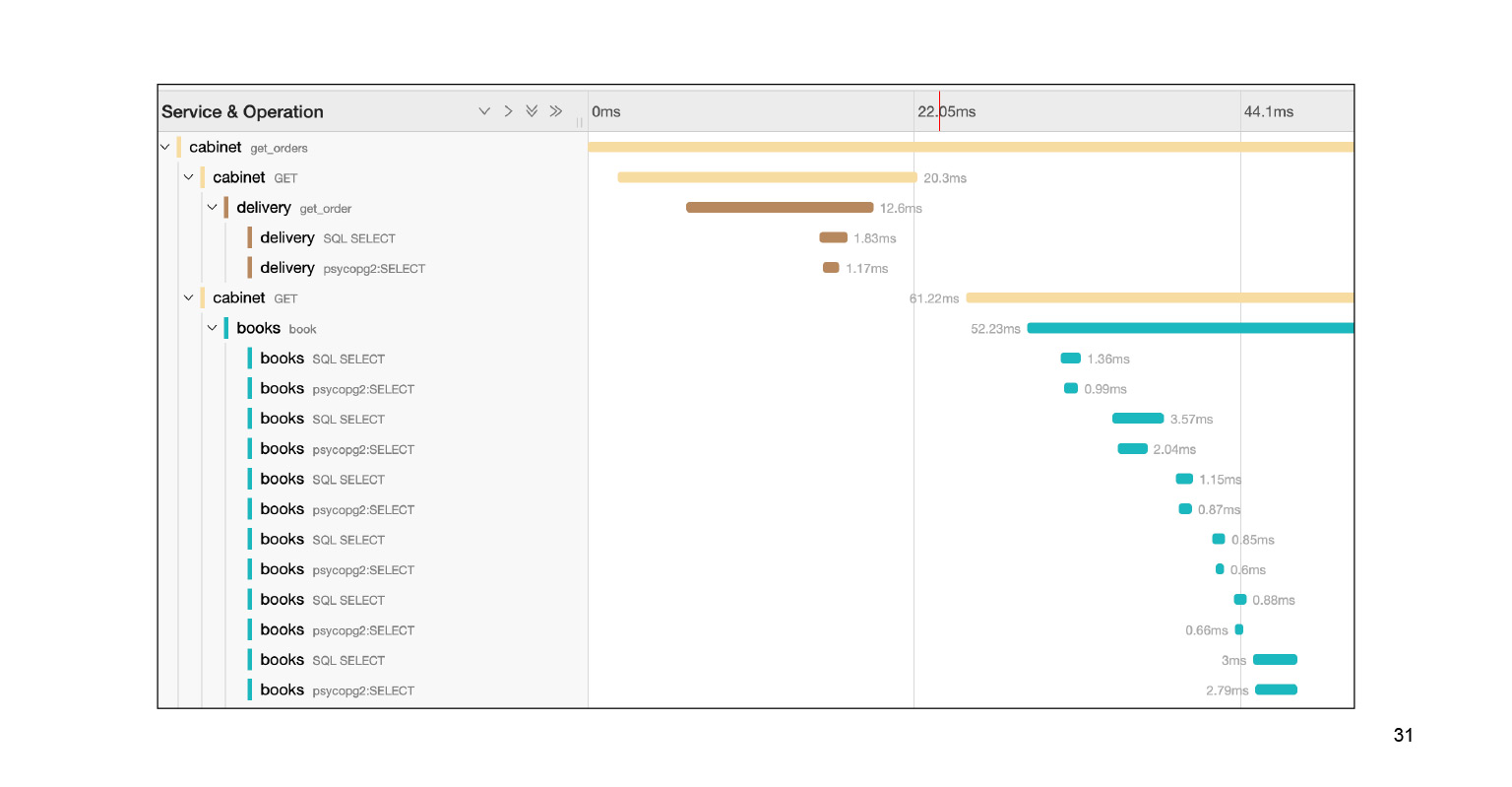
Caemos en esta consulta y vemos una gran cantidad de subconsultas SQL. Podemos ver claramente cómo se ejecutaron a tiempo, qué bloque de código fue responsable de qué. Muy genial. Además, en el contexto de nuestro problema, este no es el registro completo. Todavía hay una gran tela para los pies dos o tres deslizamientos hacia abajo. Localizamos el problema con bastante rapidez en Jaeger. Después de resolver el problema, ¿en qué nos puede ayudar el contexto que nos brinda Jaeger?
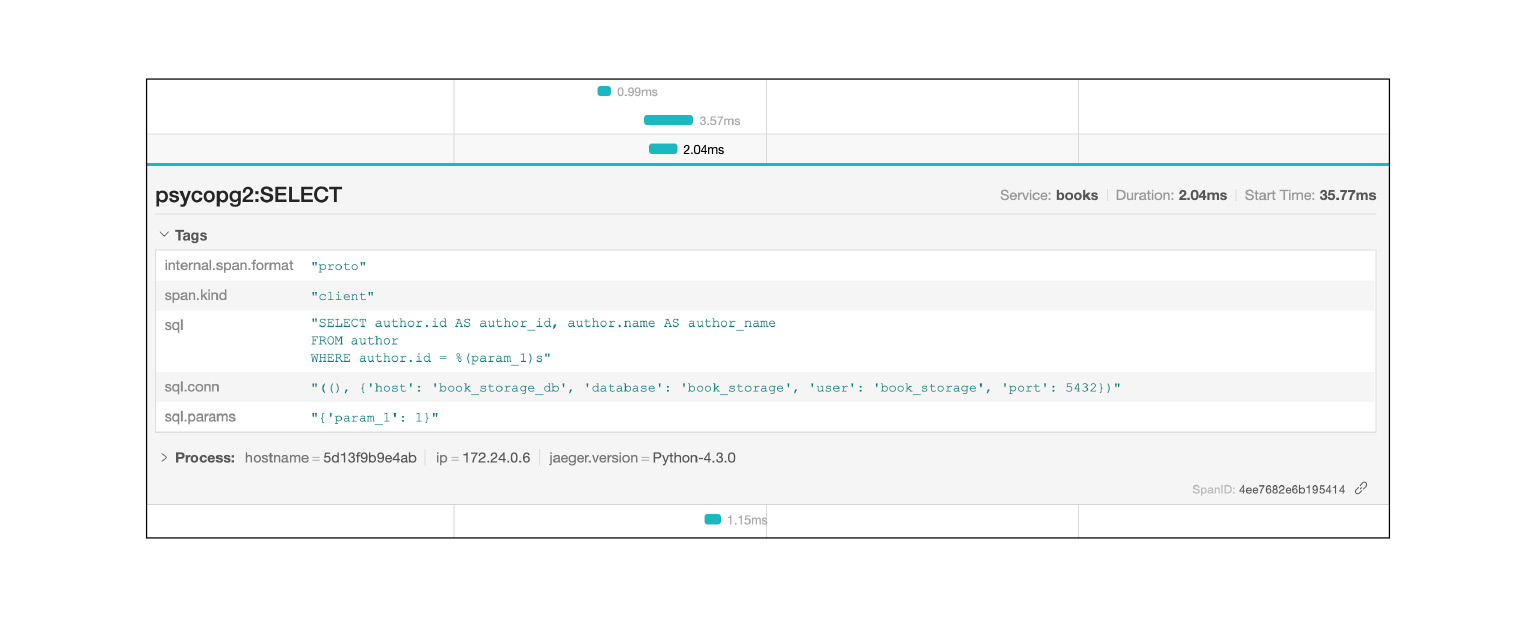
Registros de Jaeger, por ejemplo, consultas SQL: puede ver qué consultas se repiten. Muy rápido y fresco.
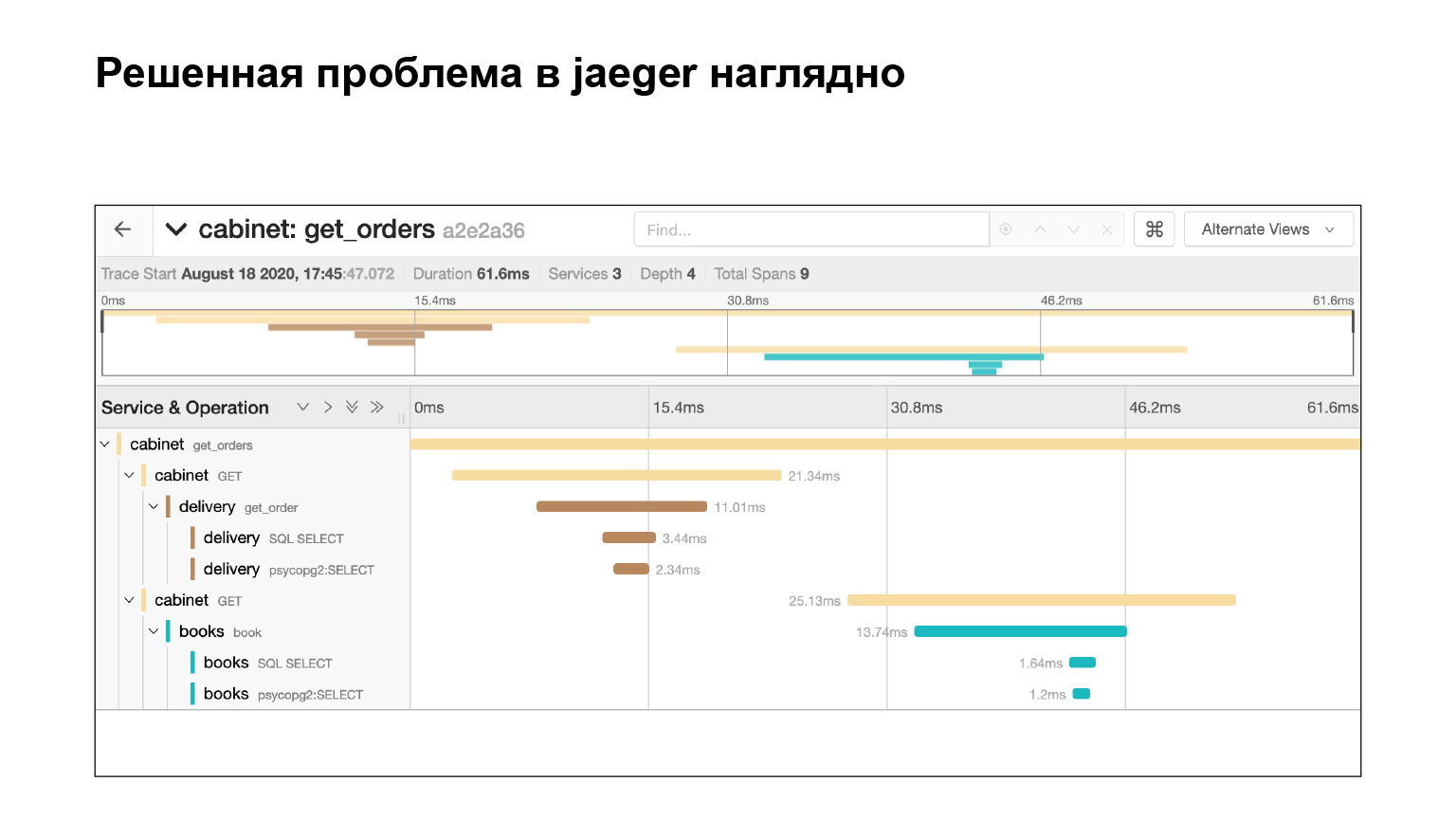
Resolvimos el problema e inmediatamente vemos en Jaeger que todo está bien. Comprobamos con la misma consulta que ahora no tenemos subconsultas. ¿Por qué? Supongamos que verificamos la misma solicitud, averiguamos el tiempo: mire en Elasticsearch cuánto tiempo se ejecutó la solicitud. Entonces veremos la hora. Pero esto no garantiza que no haya subconsultas. Y aquí lo vemos, genial.

Implementemos Jaeger. No necesitas mucho código. Agrega dependencias para opentracing, para Flask. Ahora sobre qué código estamos haciendo.
El primer bloque de código es la configuración del cliente Jaeger.
Luego configuramos la integración con Flask, Django o cualquier otro marco que tenga integración.
install_all_patches es la última línea de código y la más interesante. Parcheamos la mayoría de las integraciones externas interactuando con MySQL, Postgres, biblioteca de solicitudes. Estamos parcheando todo esto y es por eso que en la interfaz de Jaeger vemos inmediatamente todas las consultas con SQL y a cuál de los servicios se dirigió nuestro servicio requerido. Muy genial. Y no tuviste que escribir mucho. Acabamos de escribir install_all_patches. ¡Magia!
¿Qué tenemos? Ahora no es necesario recopilar eventos de los registros. Como dije, los registros son eventos dispares. En Jaeger, este es un gran evento del que ves la estructura. Jaeger le permite detectar cuellos de botella en su aplicación. Simplemente busca consultas largas y puede analizar qué está fallando.
Problema 3. Errores
El último problema son los errores. Sí, estoy siendo astuto. No te ayudaré a deshacerte de los errores en la aplicación, pero te diré qué puedes hacer a continuación.

Contexto. Puedes decir: “Danya, estamos registrando errores, tenemos alertas para quinientos, las hemos configurado. ¿Qué deseas? Iniciamos sesión, iniciamos sesión y registraremos y depuraremos.
No conoce la importancia del error de los registros. ¿Qué importancia tiene? Aquí tiene un error interesante y el error de conectarse a la base de datos. La base simplemente se derrumbó. Me gustaría ver de inmediato que este error no es tan importante, y si no hay tiempo, ignórelo, pero corrija el más importante.
La tasa de error es un contexto que puede ayudarnos a depurarlo. ¿Cómo rastrear errores? Sigamos, tuvimos un error hace un mes, y ahora vuelve a aparecer. Me gustaría encontrar una solución de inmediato y corregirla o comparar su apariencia con una de las versiones.
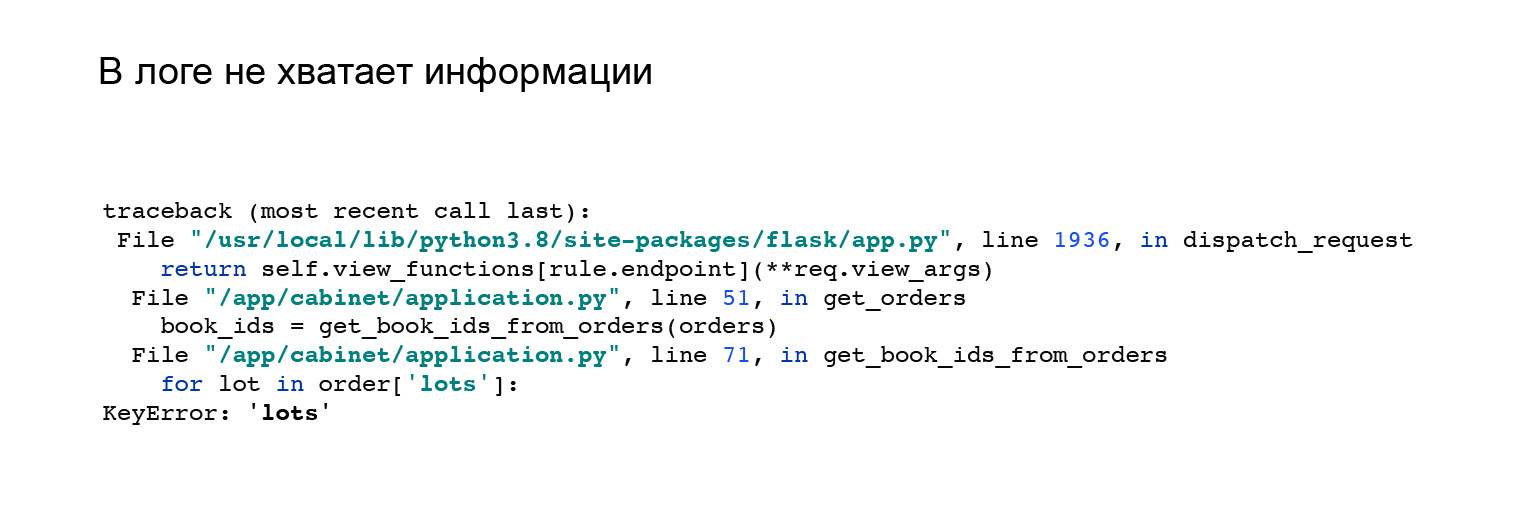
He aquí un buen ejemplo. Cuando vi la integración con Jaeger, cambié ligeramente mi API. He cambiado el formato de la respuesta de la solicitud. Recibí este error. Pero no está claro por qué no tengo una clave, lotes en el objeto de pedido y no hay nada que me ayude. Como, vea el error aquí, reprodúzcalo y descárguelo usted mismo.

Implementemos centinela. Este es un rastreador de errores que nos ayudará a resolver problemas similares y encontrar el contexto del error. Tome la biblioteca estándar mantenida por los desarrolladores centinelas. En cuatro líneas de código, lo agregamos a nuestra aplicación. Todo.
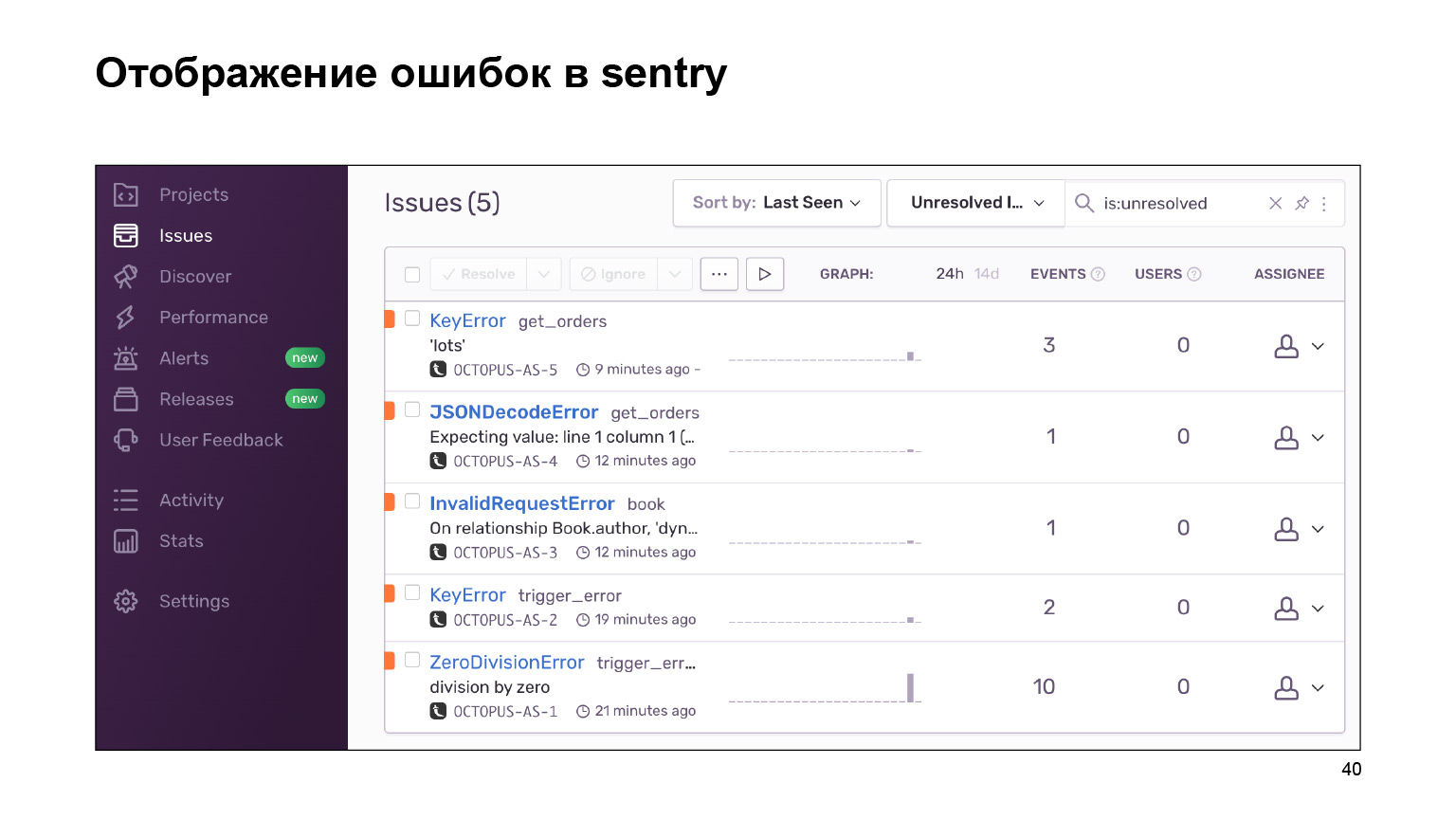
¿Qué obtuvimos al salir? Aquí hay un tablero con errores que se pueden agrupar por proyecto y que puede seguir. Un enorme tapiz de registros de errores se agrupa en otros idénticos y similares. Se proporcionan estadísticas sobre ellos. Y también puede lidiar con estos errores usando la interfaz.
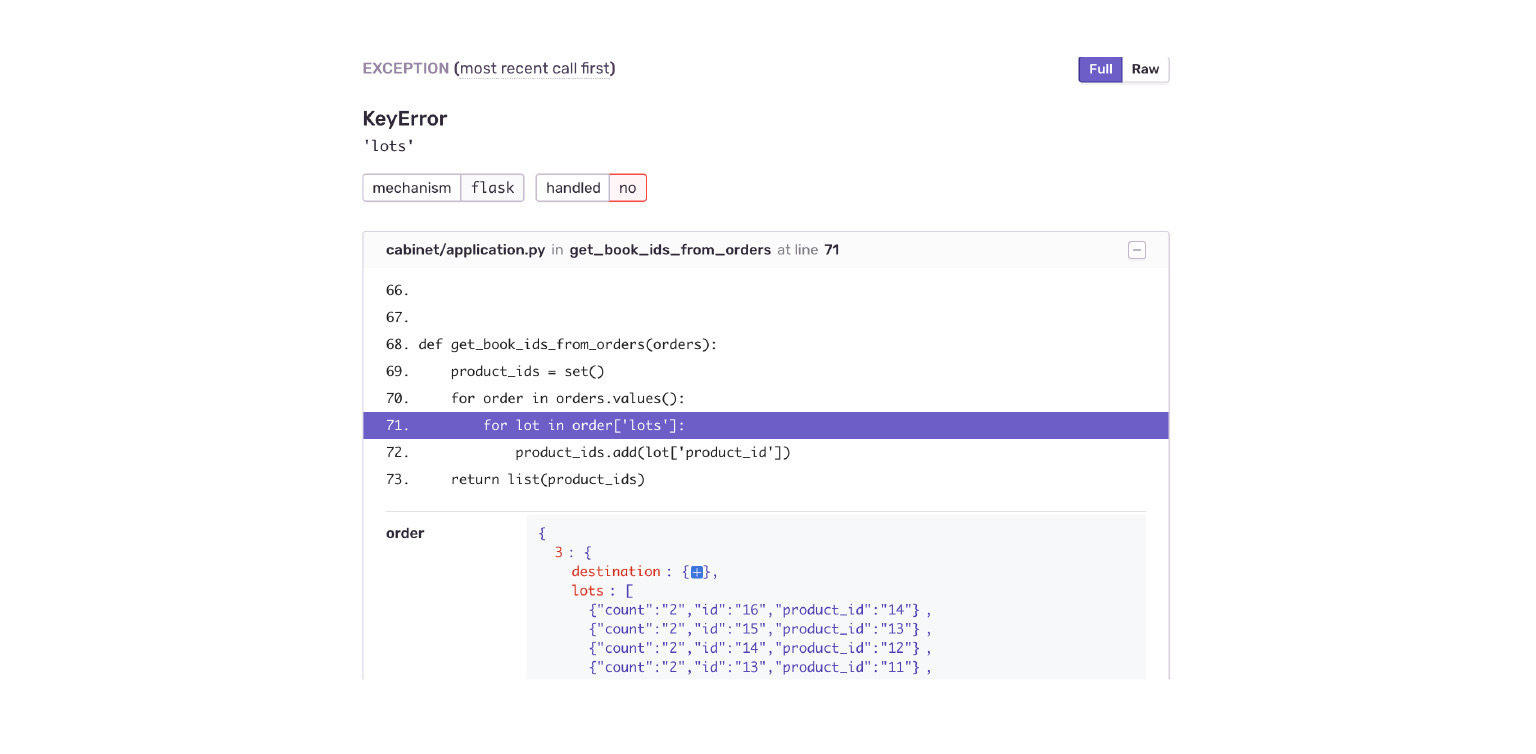
Veamos nuestro ejemplo. Caer en un KeyError. Inmediatamente vemos el contexto del error, lo que estaba en el objeto de la orden, lo que no estaba allí. Inmediatamente veo por error que la aplicación Delivery me ha proporcionado una nueva estructura de datos. El gabinete simplemente no está listo para esto.

¿Qué da el centinela además de lo que he enumerado? Formalicemos.
Esta es la tienda de errores donde puede buscarlos. Hay herramientas útiles para esto. Hay una agrupación de errores: por proyectos, por similitud. Sentry proporciona integraciones con diferentes rastreadores. Es decir, puede realizar un seguimiento de sus errores, trabajar con ellos. Simplemente puede agregar la tarea a su contexto y eso es todo. Esto ayuda en el desarrollo.
Estadísticas de errores. Nuevamente, es fácil compararlo con el lanzamiento de una versión. Sentry te ayudará con esto. Eventos similares que ocurrieron junto al error también pueden ayudarlo a encontrar y comprender qué lo provocó.

Resumamos. Hemos escrito una aplicación que es simple pero que satisface las necesidades. Te ayuda a desarrollarlo y mantenerlo en su ciclo de vida. ¿Qué hemos hecho? Hemos recopilado registros en un repositorio. Esto nos dio la oportunidad de no buscarlos en diferentes lugares. Además, ahora tenemos una búsqueda de registros y funciones de terceros, nuestras herramientas.
Rastreo integrado. Ahora podemos monitorear visualmente el flujo de datos en nuestra aplicación.
Y agregamos una herramienta útil para lidiar con errores. Estarán en nuestra aplicación, no importa cuánto lo intentemos. Pero los arreglaremos más rápido y mejor.
¿Qué más puedes agregar? La aplicación en sí está lista, hay un enlace, puedes ver cómo se hace. Allí se plantean todas las integraciones. Por ejemplo, integración con Elasticsearch o seguimiento. Entra y mira.
Otra cosa interesante que no tuve tiempo de cubrir es request_id. Casi no es diferente de trace_id, que se usa en los seguimientos. Pero somos responsables de request_id, esta es su característica más importante. El gerente puede acudir a nosotros de inmediato con request_id, no es necesario que lo busquemos. Inmediatamente comenzaremos a resolver nuestro problema. Muy genial.
Y no olvide que las herramientas que hemos implementado son generales. Estos son problemas que deben abordarse para cada aplicación. No puede implementar todas nuestras integraciones sin pensar, hacer su vida más fácil y luego pensar qué hacer con la aplicación inhibidora.
Echale un vistazo. Si no te afecta, genial. Solo tienes las ventajas y no resuelves los problemas con los frenos. No olvide esto. Gracias a todos por escuchar.